(Dlaczego) funkcje aktywacji muszą być monotoniczne?
Obecnie przygotowuję się do egzaminu z sieci neuronowych. W kilku protokołach z poprzednich badań przeczytałem, że funkcje aktywacji neuronów (w perceptronach wielowarstwowych) muszą być monotoniczne. Rozumiem, że funkcje aktywacji powinny być różniczkowalne, mieć pochodną różną od 0 w większości punktów i nieliniowe. Nie rozumiem, dlaczego monotonność jest ważna / pomocna. Znam następujące funkcje aktywacji i że są one monotoniczne:
* ReLU
* Sigmoid
* Tanh
* Softmax
* Softplus
*(Tożsamość)
Jednak na przykład nadal nie widzę żadnego powodu. (Dlaczego) czy funkcje aktywacji muszą być monotoniczne? (Powiązane pytanie poboczne: Czy istnieje jakikolwiek powód, dla którego funkcja logarytmiczna / wykładnicza nie jest używana jako funkcja aktywacji?)
Kryterium monotoniczności pomaga sieci neuronowej w łatwiejszym konwergencji w dokładniejszy klasyfikator. Więcej szczegółów i powodów znajdziesz w tej odpowiedzi na stackexchange i w artykule na Wikipedii. Jednak kryterium monotoniczności nie jest obowiązkowe dla funkcji aktywacji – możliwe jest również trenowanie sieci neuronowych z niemonotonicznymi funkcjami aktywacji. Po prostu coraz trudniej jest zoptymalizować sieć neuronową.
Jak sztuczna inteligencja uczy się działać, gdy przestrzeń problemowa jest zbyt duża
Najlepiej uczę się poprzez eksperymentowanie i przykład. Uczę się o sieciach neuronowych i mam (wydaje mi się) całkiem dobre zrozumienie klasyfikacji i regresji, a także uczenia się pod nadzorem i bez nadzoru, ale natknąłem się na coś, czego nie mogę po cichu zrozumieć; Gdybym chciał wyszkolić AI do grania w skomplikowaną grę; Myślę o czymś takim jak RTS (np. Age of Empires, Empire Earth itp.). W tego typu grach zazwyczaj występuje wiele jednostek kontrolowanych przez gracza (jednostki, budynki), z których każda ma inne możliwości. Wydaje się, że problemem związanym z tym, że sztuczna inteligencja robi, byłaby klasyfikacja (np. Wybór tej jednostki i tej akcji), jednak skoro liczba jednostek jest zmienną, jak można w ten sposób rozwiązać problem klasyfikacji? Jedyne, co przychodzi mi do głowy, to wiele sieci, które wykonują różne etapy (jeden dla ogólnej strategii, jeden dla kontrolowania tego typu jednostek, jeden dla tego typu budynku itp.); ale wygląda na to, że komplikuję problem. Czy jest jakiś dobry przykład uczenia maszynowego / sieci neuronowych uczących się złożonych gier (nie konkretnie RTS, ale bardziej skomplikowany Mario)?
To dobre pytanie i wielu naukowców na całym świecie zadaje to samo. Cóż, po pierwsze, uważa się, że gra taka jak Age of Empires nie ma naprawdę dużej przestrzeni na rozwiązania, nie można zrobić zbyt wiele rzeczy. Tak samo jest w grach takich jak Mario Bros. Problem uczenia się w prostych grach, takich jak gry na Atari, został rozwiązany przez ludzi z DeepMind (tutaj artykuł), który został przejęty przez Google. Użyli implementacji uczenia się ze wzmocnieniem z uczeniem głębokim. Wracając do twojego pytania. Naprawdę dużym problemem jest to, jak naśladować ilość decyzji, które człowiek podejmuje każdego dnia. Obudź się, zjedz śniadanie, weź prysznic, wyjdź z domu… Wszystkie te działania wymagają naprawdę dużej inteligencji i wielu działań, aby się rozwijać.
Wiele osób pracuje nad tym problemem, ja jestem jedną z nich. Nie znam rozwiązania, ale mogę powiedzieć, w jaki sposób szukam. Podążam za teoriami Marvina Minsky’ego, jest jednym z ojców AI. Ta książka, Maszyna emocji, przedstawia bardzo dobry obraz problemu. Zasugerował, że sposobem na stworzenie maszyny imitującej ludzkie zachowanie nie jest skonstruowanie jednolitej zwartej teorii sztucznej inteligencji. Wręcz przeciwnie, argumentuje, że nasz mózg zawiera zasoby, które konkurują między sobą, aby w tym samym momencie osiągnąć różne cele. Nazwali ten sposób myślenia.
Czy sieci neuronowe są z natury algorytmem online?
Od jakiegoś czasu zajmuję się uczeniem maszynowym, ale kawałki i fragmenty łączą się ze sobą nawet po pewnym czasie ćwiczeń. W sieciach neuronowych dostosowujesz wagi wykonując jeden przejazd (przejście do przodu), a następnie obliczanie pochodnych cząstkowych dla wag (przebieg wstecz) po każdym przykładzie szkoleniowym – i odejmowanie tych pochodnych cząstkowych od wag początkowych. z kolei obliczenie nowych wag jest matematycznie skomplikowane (trzeba obliczyć pochodną cząstkową wag, dla których obliczamy błąd w każdej warstwie sieci neuronowej – ale w warstwie wejściowej). Czy z definicji nie jest to algorytm online, w którym koszt i nowe wagi są obliczane po każdym przykładzie szkolenia
Istnieją trzy tryby uczenia sieci neuronowych
* stochastyczne zejście w gradiencie: dostosuj wagi po każdym przykładzie treningu
* szkolenie wsadowe: dostosuj wagi po przejrzeniu wszystkich danych (epoka)
* Trening mini-wsadowy: dostosuj ciężary po przejściu przez mini-wsad. Zwykle jest to 128 przykładów szkoleniowych.
W większości przypadków wydaje się, że używane jest szkolenie mini-wsadowe. Odpowiedź brzmi: nie, algorytm uczenia sieci neuronowej nie jest algorytmem online.
Jakie rodzaje problemów z uczeniem się są odpowiednie dla maszyn wektorów wsparcia?
Jakie są cechy lub właściwości, które wskazują, że określony problem uczenia się można rozwiązać za pomocą maszyn wektorów nośnych? Innymi słowy, co takiego sprawia, że kiedy widzisz problem z uczeniem się, mówisz „och, zdecydowanie powinienem używać do tego maszyn SVM” zamiast sieci neuronowych, drzew decyzyjnych czy czegokolwiek innego?
SVM można wykorzystać do klasyfikacji (rozróżnienia kilku grup lub klas) i regresji (uzyskania modelu matematycznego, aby coś przewidzieć). Można je stosować zarówno do problemów liniowych, jak i nieliniowych. Do 2006 roku były najlepszym algorytmem ogólnego przeznaczenia do uczenia maszynowego. Próbowałem znaleźć artykuł, w którym porównano wiele implementacji najbardziej znanych algorytmów: svm, sieci neuronowe, drzewa itp. Nie mogłem tego znaleźć, przykro mi (musisz mi uwierzyć, źle). W artykule algorytmem, który uzyskał najlepszą wydajność, był svm z biblioteką libsvm. W 2006 roku Hinton wynalazł głębokie uczenie się i sieci neuronowe. Poprawił obecny stan techniki o co najmniej 30%, co jest ogromnym postępem. Jednak uczenie głębokie zapewnia dobrą wydajność tylko w przypadku dużych zestawów treningowych. Jeśli masz mały zestaw treningowy, sugerowałbym użycie svm. Ponadto możesz znaleźć tutaj przydatną infografikę o tym, kiedy używać różnych algorytmów uczenia maszynowego przez scikit-learn. Jednak, zgodnie z moją najlepszą wiedzą, w środowisku naukowym nie ma zgody co do tego, że jeśli problem ma cechy X, Y i Z, lepiej jest użyć svm. Sugerowałbym wypróbowanie różnych metod. Nie zapominaj również, że svm lub sieci neuronowe to tylko metoda obliczania modelu. Bardzo ważne jest również to, z jakich funkcji korzystasz.
Załóżmy, że jesteśmy w ustawieniu klasyfikacyjnym. lub inżynieria funkcji svm jest kamieniem węgielnym: zestawy muszą być rozdzielane liniowo. W przeciwnym razie dane muszą zostać przekształcone (np. Przy użyciu jądra). Nie jest to wykonywane przez sam algorytm i może wydmuchać liczbę cechy. Powiedziałbym, że wydajność svm cierpi, ponieważ zwiększamy liczbę wymiarów szybciej niż inne metodologie (zespół drzewa). Wynika to z ograniczonego problemu optymalizacji, który stoi za svms. Czasami redukcja funkcji jest możliwa, czasami nie, i wtedy nie możemy naprawdę utorować drogi do efektywnego wykorzystania svm svm prawdopodobnie będzie miał problemy ze zbiorem danych, w którym liczba funkcji jest znacznie większa niż liczba obserwacji. Można to również zrozumieć, patrząc na problem z ograniczoną optymalizacją. Zmienne kategorialne nie są obsługiwane po wyjęciu z pudełka przez algorytm svm.
P: Czy jest jakaś domena, w której sieci bayesowskie przewyższają sieci neuronowe?
Sieci neuronowe uzyskują najlepsze wyniki w zadaniach widzenia komputerowego (patrz MNIST, ILSVRC, Kaggle Galaxy Challenge). Wydaje się, że przewyższają wszystkie inne podejście w wizji komputerowej. Ale są też inne zadania:
* Wyzwanie Kaggle Molecular Activity Challenge
* Regresja: prognoza Kaggle Rain, również 2. miejsce
* Chwyć i podnieś 2. także trzecie miejsce – Zidentyfikuj ruchy dłoni na podstawie zapisów EEG
Nie jestem pewien co do ASR (automatycznego rozpoznawania mowy) i tłumaczenia maszynowego, ale myślę, że słyszałem również, że (powtarzające się) sieci neuronowe (zaczynają) przewyższać inne podejścia. Obecnie uczę się o sieciach bayesowskich i zastanawiam się, w jakich przypadkach te modele są zwykle stosowane. Więc moje pytanie brzmi: czy jest jakaś konkurencja typu challenge / (Kaggle), w której najnowocześniejsze są sieci bayesowskie lub przynajmniej bardzo podobne modele? (Uwaga dodatkowa: widziałem także drzewa decyzyjne, 2, 3, 4, 5, 6, 7 zwycięstwa w kilku ostatnich wyzwaniach Kaggle)
Jednym z obszarów, w których często stosuje się podejście bayesowskie, jest potrzeba interpretacji systemu prognozowania. Nie chcesz dawać lekarzom sieci neuronowej i twierdzić, że jest dokładna w 95%. Raczej chcesz wyjaśnić założenia, które przyjmuje Twoja metoda, a także proces decyzyjny, z którego korzysta metoda. Podobny obszar ma miejsce, gdy masz silną wcześniejszą wiedzę domenową i chcesz ją wykorzystać w systemie.
Sieci bayesowskie i sieci neuronowe nie wykluczają się wzajemnie. W rzeczywistości sieci bayesowskie to tylko kolejny termin określający „ukierunkowany model graficzny”. Mogą być bardzo przydatne w projektowaniu funkcji obiektywnych sieci neuronowych. Zwrócił na to uwagę Yann Lecun:
https://plus.google.com/+YannLeCunPhD/posts/gWE7Jca3Zoq.
Jeden przykład. Wariacyjny automatyczny koder i pochodne są ukierunkowanymi graficznymi modelami formularza
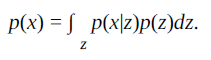
Sieć neuronowa służy do zaimplementowania p (x | z) i przybliżenia do jego odwrotności: q(z|x) ≈ p(z|x)
Już doskonałe odpowiedzi. Domeną, o której przychodzi mi do głowy i nad którą intensywnie pracuję, jest domena analizy klientów. Muszę rozumieć i przewidywać ruchy i motywy klientów, aby informować i ostrzegać zarówno obsługę klienta, marketing, jak i zespoły zajmujące się rozwojem. Więc tutaj sieci neuronowe wykonują naprawdę dobrą robotę w przewidywaniu rezygnacji itp. Ale znalazłem i preferuję styl sieci bayesowskich, a oto powody, dla których preferuję ten styl:
- Klienci zawsze mają wzór. Zawsze mają powód do działania. I byłby to powód, który mój zespół zrobił dla nich lub sami się nauczyli. Tak więc wszystko ma tu swój poprzednik i faktycznie ten powód jest bardzo ważny, ponieważ napędza większość decyzji podjętej przez klienta.
- Każdy ruch klienta i zespołów rozwojowych w lejku marketingowo-sprzedażowym ma skutek przyczynowo-skutkowy. Tak więc wcześniejsza wiedza jest niezbędna, jeśli chodzi o przekształcenie potencjalnego potencjalnego klienta w klienta.
Tak więc koncepcja wcześniejszych jest bardzo ważna, jeśli chodzi o analitykę klientów, co sprawia, że koncepcja sieci Bayesa jest bardzo ważna dla tej domeny
Sieci neuronowe: jakiej funkcji kosztu użyć?
Używam TensorFlow do eksperymentów głównie z sieciami neuronowymi. Chociaż przeprowadziłem teraz sporo eksperymentów (problem XOR, MNIST, trochę rzeczy związanych z regresją…), mam problem z wyborem „prawidłowej” funkcji kosztu dla określonych problemów, ponieważ ogólnie mogę być uważany za początkującego. Przed przejściem do TensorFlow samodzielnie zakodowałem kilka w pełni połączonych MLP i niektóre powtarzające się sieci za pomocą Pythona i NumPy, ale głównie miałem problemy, w których wystarczył prosty kwadratowy błąd i prosty opis gradientu. Ponieważ jednak TensorFlow oferuje całkiem sporo funkcji kosztowych, a także tworzenie niestandardowych funkcji kosztów, chciałbym wiedzieć, czy istnieje jakiś poradnik, być może dotyczący funkcji kosztów w sieciach neuronowych? (Skończyłem już prawie połowę oficjalnych samouczków TensorFlow, ale tak naprawdę nie wyjaśniają one, dlaczego określone funkcje kosztów lub uczniowie są wykorzystywani do konkretnych problemów – przynajmniej nie dla początkujących)
Aby podać kilka przykładów:
koszt = tf.reduce_mean (tf.nn.softmax_cross_entropy_with_logits (y_output, y_train))
Wydaje mi się, że stosuje funkcję softmax na obu wejściach, tak że suma jednego wektora jest równa
- Ale czym właściwie jest entropia krzyżowa z logitami? Myślałem, że sumuje wartości i oblicza entropię krzyża… więc jakiś pomiar metryczny ?! Czy nie wyglądałoby to tak samo, gdybym znormalizował wynik, zsumował i wziął kwadratowy błąd? Dodatkowo, dlaczego , czy to jest używane np. dla MNIST (a nawet znacznie trudniejszych problemów)? Kiedy chcę sklasyfikować jako 10, a może nawet 1000 klas, czy sumowanie wartości nie niszczy całkowicie informacji o tym, która klasa faktycznie była wynikiem?
cost = tf.nn.l2_loss (wektor)
Po co to? Myślałem, że strata L2 jest w zasadzie błędem do kwadratu, ale API TensorFlow mówi, że dane wejściowe to tylko jeden tensor. W ogóle nie rozumiesz ?! Poza tym dość często widziałem to dla krzyżowej entropii:
cross_entropy = -tf.reduce_sum (y_train * tf.log (y_output))
… Ale dlaczego to jest używane? Czy utrata entropii krzyżowej nie jest matematycznie taka:
-1 / n * suma (y_train * log (y_output) + (1 – y_train) * log (1 – y_output))
Gdzie znajduje się część (1 – y_train) * log (1 – y_output) w większości przykładów TensorFlow?
Czy tego nie brakuje?
Odpowiedzi: Wiem, że to pytanie jest dość otwarte, ale nie spodziewam się, że otrzymam około 10 stron z każdym szczegółowym opisem problemu / kosztu. Potrzebuję tylko krótkiego podsumowania, kiedy użyć której funkcji kosztu (ogólnie lub w TensorFlow, nie ma to dla mnie większego znaczenia) i wyjaśnienia na ten temat. I / lub jakieś źródło (a) dla początkujących;)
Ta odpowiedź dotyczy ogólnej strony funkcji kosztów, niezwiązanej z TensorFlow, i w większości dotyczy części Twojego pytania zawierającej „pewne wyjaśnienia na ten temat”. W większości przykładów / samouczków, do których się stosowałem, użyta funkcja kosztu była nieco arbitralna. Chodziło raczej o wprowadzenie czytelnika w konkretną metodę, a nie funkcję kosztu konkretnie. Nie powinno Cię to powstrzymywać przed skorzystaniem z samouczka, aby zapoznać się z narzędziami, ale moja odpowiedź powinna pomóc Ci w wyborze funkcji kosztu dla własnych problemów. Jeśli chcesz uzyskać odpowiedzi dotyczące Cross-Entropy, Logit, norm L2 lub czegokolwiek konkretnego, radzę zadać wiele bardziej szczegółowych pytań. Zwiększy to prawdopodobieństwo, że ktoś z określoną wiedzą zobaczy Twoje pytanie.
Wybór odpowiedniej funkcji kosztu w celu osiągnięcia pożądanego rezultatu jest krytycznym punktem problemów z uczeniem maszynowym. Podstawowym podejściem, jeśli nie wiesz dokładnie, czego oczekujesz od swojej metody, jest użycie średniokwadratowego błędu (Wikipedia) w przypadku problemów z regresją i wartości procentowej błędu w przypadku problemów klasyfikacyjnych. Jeśli jednak chcesz uzyskać dobre wyniki swojej metody, musisz zdefiniować dobre, a tym samym zdefiniować odpowiednią funkcję kosztu. Wynika to zarówno ze znajomości domeny (jakie są Twoje dane, co próbujesz osiągnąć), jak i wiedzy o narzędziach, którymi dysponujesz. Nie sądzę, żebym mógł przeprowadzić Cię przez funkcje kosztów już zaimplementowane w TensorFlow, ponieważ mam bardzo małą wiedzę na temat tego narzędzia, ale mogę podać przykład, jak pisać i oceniać różne funkcje kosztów.
Aby zilustrować różne różnice między funkcjami kosztów, posłużmy się przykładem problemu klasyfikacji binarnej, gdzie chcemy, aby dla każdej próbki xn klasa f(xn) {0,1}
Począwszy od właściwości obliczeniowych; jak dwie funkcje mierzące „tę samą rzecz” mogą prowadzić do różnych wyników. Weźmy następującą, prostą funkcję kosztu; procent błędu. Jeśli masz N próbek, f(yn)to przewidywana klasa a yn prawdziwa klasa, którą chcesz zminimalizować
Ta funkcja kosztu ma tę zaletę, że jest łatwa do interpretacji. Jednak nie jest to gładkie; jeśli masz tylko dwie próbki, funkcja „przeskakuje” od 0, do 0,5, do 1. Doprowadzi to do niespójności, jeśli spróbujesz użyć gradientu spadku w tej funkcji. Jednym ze sposobów uniknięcia tego jest zmiana funkcji kosztu w celu wykorzystania prawdopodobieństw przypisania; p(yn =1|xn) . Funkcja staje się
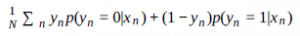
Ta funkcja jest bardziej płynna i będzie działać lepiej w przypadku podejścia gradientowego. Otrzymasz „lepszy” model. Jednak ma inny problem; jeśli masz próbkę, która jest niejednoznaczna, powiedzmy, że nie masz wystarczających informacji, aby powiedzieć coś lepszego niż p(yn =1|xn) = 0,5
Następnie użycie gradientu spadku dla tej funkcji kosztu doprowadzi do modelu, który zwiększy to prawdopodobieństwo tak bardzo, jak to możliwe, a tym samym, być może, przekroczy dopasowanie. Innym problemem związanym z tą funkcją jest to, że jeśli p(yn =1|xn) = 1 podczas gdy yn = 0
na pewno masz rację, ale się mylisz. Aby uniknąć tego problemu, możesz wziąć logarytm prawdopodobieństwa, log p(yn |xn ) . Jeśli log(0) = ∞ i log(1) = 0 Następująca funkcja nie ma problemu opisanego w poprzednim akapicie
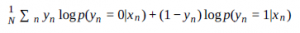
Powinno to pokazać, że aby zoptymalizować to samo, procent błędu, różne definicje mogą dawać różne wyniki, jeśli są łatwiejsze do zrozumienia i obliczeniowe. Funkcje kosztu A i B mogą mierzyć tę samą koncepcję, ale A może prowadzić twoją metodę do lepszych wyników niż B.
Zobaczmy teraz, jak różne funkcje kosztów mogą mierzyć różne koncepcje. W kontekście wyszukiwania informacji, jak w wyszukiwarce Google (jeśli zignorujemy ranking), chcemy, aby zwracane wyniki
* mają wysoką precyzję, nie zwracają nieistotnych informacji
* mają wysoką rozpoznawalność, zwracają jak najwięcej trafnych wyników
* Precyzja i przywołanie (Wikipedia)
Zwróć uwagę, że jeśli algorytm zwróci wszystko, zwróci każdy możliwy odpowiedni wynik, a zatem będzie miał wysoką pamięć, ale ma bardzo niską precyzję. Z drugiej strony, jeśli zwróci tylko jeden element, ten, który jest najbardziej pewny, jest odpowiedni, będzie miał wysoką precyzję ale mało przypominam. Aby ocenić takie algorytmy, wspólną funkcją kosztu jest wynik F (Wikipedia). Typowym przypadkiem jest wynik F1, który nadaje równą wagę precyzji i przypominam sobie, ale w ogólnym przypadku jest to wynik Fβ -score i możesz dostosować wersję beta, aby uzyskać
* Wyższe zapamiętanie, jeśli używasz wersji β> 1
* Wyższa precyzja, jeśli używasz. β <1
W takim scenariuszu wybranie funkcji kosztu jest wyborem kompromisu, jaki powinien zrobić twój algorytm. Innym często przytaczanym przykładem jest przypadek diagnozy medycznej, możesz wybrać funkcję kosztu, która karze więcej fałszywie negatywnych lub fałszywie pozytywnych wyników w zależności od tego, co jest preferowane:
* Więcej zdrowych osób klasyfikuje się jako chorych (ale wtedy możemy leczyć zdrowych ludzi, co jest kosztowne i może im zaszkodzić, jeśli faktycznie nie są chorzy)
* Więcej chorych osób jest klasyfikowanych jako zdrowych (ale wtedy mogą umrzeć bez leczenia).
Podsumowując, zdefiniowanie funkcji kosztu jest zdefiniowaniem celu algorytmu. Algorytm definiuje, jak się tam dostać
Jaki jest dobry algorytm uczenia maszynowego do handlu z niską częstotliwością?
Próbuję wytrenować algorytm, aby kopiował najlepszych inwestorów z różnych portali społecznościowych forex. Problem polega na tym, że traderzy handlują tylko około, powiedzmy, 10 razy w miesiącu, więc nawet jeśli spojrzę tylko na wartości minutowe, to 0,02% czasu [10 / (60 * 24 * 30) * 100].
Próbowałem użyć losowego lasu i daje to wskaźnik błędów około 2%, co jest nie do przyjęcia, a z tego, co przeczytałem, większość algorytmów uczenia maszynowego ma podobne wskaźniki błędów. Czy ktoś zna lepsze podejście?
Losowe lasy, GBM czy nawet nowszy i bardziej wyszukany xgboost nie są najlepszymi kandydatami do binarnej klasyfikacji (przewidywania wzrostów i spadków) prognoz akcji lub handlu na rynku Forex, a przynajmniej nie jako główny algorytm. Powodem jest to, że w przypadku tego konkretnego problemu one wymagają ogromnej ilości drzew (i głębokości drzew w przypadku GBM lub xgboost), aby uzyskać rozsądną dokładność (Breiman sugerował użycie co najmniej 5000 drzew i „nie skąpić”, a w rzeczywistości jego główny artykuł ML na temat RF użył 50 000 drzew na biegać). Jednak niektóre kwanty używają losowych lasów jako selektorów funkcji, podczas gdy inne używają ich do generowania nowych funkcji. Wszystko zależy od charakterystyki danych. Sugerowałbym przeczytanie tego pytania i odpowiedzi na stronie quant.stackexchange, gdzie ludzie dyskutują, jakie metody są najlepsze i kiedy ich używać, między innymi ISOMAP, Laplacian eigenmaps, ANN, optymalizacja roju. Sprawdź tag uczenia maszynowego w tej samej witrynie, gdzie możesz znaleźć informacje związane z określonym zbiorem danych.
Zaimplementuj MLP w tensorflow
W sieci jest wiele zasobów o tym, jak wdrożyć MLP w tensorflow, a większość przykładów działa 🙂 Ale interesuje mnie konkretny, o którym dowiedziałem się z https://www.coursera.org/learn/machine-learning . W którym używa funkcji kosztu zdefiniowanej w następujący sposób:
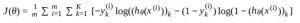
hθ jest funkcją sigmoidalną. A oto moja implementacja:
# one hidden layer MLP
x = tf.placeholder(tf.float32, shape=[None, 784])
y = tf.placeholder(tf.float32, shape=[None, 10])
W_h1 = tf.Variable(tf.random_normal([784, 512]))
h1 = tf.nn.sigmoid(tf.matmul(x, W_h1))
W_out = tf.Variable(tf.random_normal([512, 10]))
y_ = tf.matmul(h1, W_out)
# cross_entropy = tf.nn.sigmoid_cross_entropy_with_logits(y_, y)
cross_entropy = tf.reduce_sum(- y * tf.log(y_) – (1 – y) * tf.log(1 – y_), 1)
loss = tf.reduce_mean(cross_entropy)
train_step = tf.train.GradientDescentOptimizer(0.05).minimize(loss)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# train
with tf.Session() as s:
s.run(tf.initialize_all_variables())
for i in range(10000):
batch_x, batch_y = mnist.train.next_batch(100)
s.run(train_step, feed_dict={x: batch_x, y: batch_y})
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch_x, y: batch_y})
print(‘step {0}, training accuracy {1}’.format(i, train_accuracy))
Myślę, że definicja warstw jest poprawna, ale problem tkwi w cross_entropy. Jeśli użyję pierwszego, który został wykomentowany, model szybko się zbiegnie; ale jeśli użyję drugiego, który moim zdaniem / mam nadzieję jest tłumaczeniem poprzedniego równania, model nie będzie zbieżny.
Myślę, że definicja warstw jest poprawna, ale problem tkwi w cross_entropy. Jeśli użyję pierwszego, który został wykomentowany, model szybko się zbiegnie; ale jeśli użyję drugiego, który moim zdaniem / mam nadzieję jest tłumaczeniem poprzedniego równania, model nie będzie zbieżny.
Popełniłeś trzy błędy:
- Pominięto składniki przesunięcia przed przekształceniami nieliniowymi (zmienne b_1 i b_out). Zwiększa to reprezentatywną moc sieci neuronowej.
- Pominąłeś transformację softmax w górnej warstwie. To sprawia, że dane wyjściowe są rozkładami prawdopodobieństwa, więc można obliczyć entropię krzyżową, która jest zwykłą funkcją kosztu do klasyfikacji.
- Użyłeś formy binarnej entropii krzyżowej, podczas gdy powinieneś był użyć formy wieloklasowej.
Po uruchomieniu tego uzyskuję dokładność powyżej 90%:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(‘/tmp/MNIST_data’, one_hot=True)
x = tf.placeholder(tf.float32, shape=[None, 784])
y = tf.placeholder(tf.float32, shape=[None, 10])
W_h1 = tf.Variable(tf.random_normal([784, 512]))
b_1 = tf.Variable(tf.random_normal([512]))
h1 = tf.nn.sigmoid(tf.matmul(x, W_h1) + b_1)
W_out = tf.Variable(tf.random_normal([512, 10]))
b_out = tf.Variable(tf.random_normal([10]))
y_ = tf.nn.softmax(tf.matmul(h1, W_out) + b_out)
# cross_entropy = tf.nn.sigmoid_cross_entropy_with_logits(y_, y)
cross_entropy = tf.reduce_sum(- y * tf.log(y_), 1)
loss = tf.reduce_mean(cross_entropy)
train_step = tf.train.GradientDescentOptimizer(0.05).minimize(loss)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# train
with tf.Session() as s:
s.run(tf.initialize_all_variables())
for i in range(10000):
batch_x, batch_y = mnist.train.next_batch(100)
s.run(train_step, feed_dict={x: batch_x, y: batch_y})
if i % 1000 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch_x, y: batch_y})
print(‘step {0}, training accuracy {1}’.format(i, train_accuracy))
Kroki uczenia maszynowego
Która z poniższych opcji kroków jest właściwa podczas tworzenia modelu predykcyjnego?
Opcja 1: Najpierw wyeliminuj najbardziej ewidentnie złe predyktory i przetwórz wstępnie pozostałe, jeśli to konieczne, a następnie wytrenuj różne modele z walidacją krzyżową, wybierz kilka najlepszych, zidentyfikuj najlepsze predyktory, z których każdy z nich korzystał, a następnie przetrenuj te modele tylko z tymi predyktorami i ponownie oceń dokładność za pomocą walidacji krzyżowej, a następnie wybierz najlepszy z nich i przećwicz go na pełnym zestawie uczącym przy użyciu jego kluczowych predyktorów, a następnie użyj go do przewidzenia zestawu testowego.
Opcja 2: Najpierw wyeliminuj najbardziej ewidentnie złe predyktory, następnie w razie potrzeby przetwórz wstępnie pozostałe, a następnie użyj techniki wyboru cech, takiej jak rekurencyjna selekcja cech (np. RFE z rf) z walidacją krzyżową, na przykład w celu zidentyfikowania idealnej liczby kluczowych predyktorów i czym są te predyktory, a następnie wytrenuj różne typy modeli z weryfikacją krzyżową i zobacz, który z nich zapewnia największą dokładność z najlepszymi predyktorami zidentyfikowanymi wcześniej. Następnie wytrenuj ponownie najlepszy z tych modeli z tymi predyktorami w pełnym zestawie uczącym, a następnie użyj go do przewidywania zestawu testowego.
Okazało się, że obie opcje są nieco wadliwe. Tak więc ogólnie (bardzo ogólnie) jest to modelowanie predykcyjne:
Czyszczenie danych: zajmuje najwięcej czasu, ale każda spędzona tutaj sekunda jest tego warta. Im czystsze dane przejdą przez ten krok, tym mniejszy będzie całkowity czas spędzony.
Dzielenie zbioru danych: zbiór danych zostałby podzielony na zbiory uczące i testowe, które byłyby wykorzystywane odpowiednio do celów modelowania i prognozowania. Ponadto należałoby również przeprowadzić dodatkowy podział jako zestaw do weryfikacji krzyżowej. Transformacja i redukcja: obejmuje procesy takie jak transformacje, średnie i mediana skalowania itp.
Wybór funkcji: można to zrobić na wiele sposobów, takich jak wybór progu, wybór podzbioru itp.
Projektowanie modelu predykcyjnego: Zaprojektuj model predykcyjny na podstawie danych szkoleniowych w zależności od dostępnych funkcji.
Cross Validation: Final Prediction, Validation
Zrozumienie uczenia się ze wzmocnieniem za pomocą sieci neuronowej (Qlearning)
Próbuję zrozumieć uczenie się przez wzmacnianie i procesy decyzyjne markowa (MDP) w przypadku, gdy sieć neuronowa jest wykorzystywana jako aproksymator funkcji. Mam trudności ze związkiem między MDP, w którym środowisko jest badane w sposób probabilistyczny, w jaki sposób jest to odwzorowywane z powrotem na parametry uczenia się i w jaki sposób znajduje się ostateczne rozwiązanie / zasady. Czy mam rację, zakładając, że w przypadku Q-learning, sieć neuronowa zasadniczo działa jako aproksymator funkcji dla samej wartości q, tak wiele kroków w przyszłości? Jak to się ma do aktualizacji parametrów za pomocą wstecznej propagacji lub innych metod? Ponadto, kiedy sieć nauczyła się przewidywać przyszłą nagrodę, jak to pasuje do systemu pod względem faktycznego podejmowania decyzji? Zakładam, że ostateczny system prawdopodobnie nie dokonałby przejść między stanami.
W Q-Learning na każdym kroku będziesz korzystać z obserwacji i nagród, aby zaktualizować swoją funkcję Qvalue:
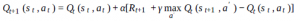
Masz rację mówiąc, że sieć neuronowa jest tylko przybliżeniem funkcji dla funkcji wartości q. Ogólnie rzecz biorąc, część aproksymacyjna to tylko standardowy nadzorowany problem uczenia się. Twoja sieć wykorzystuje (s, a) jako dane wejściowe, a wyjście to wartość q. W miarę dostosowywania wartości q należy wyszkolić te nowe próbki w sieci. Mimo to napotkasz pewne problemy, ponieważ używasz skorelowanych próbek, a SGD ucierpi. Jeśli patrzysz na artykuł DQN, sprawy mają się nieco inaczej. W takim przypadku to, co robią, to umieszczanie próbek w wektorze (odtwarzanie doświadczenia). Aby nauczyć sieć, próbkują krotki z wektora, ładują się za pomocą tych informacji, aby uzyskać nową wartość q, która jest przekazywana do sieci. Kiedy mówię o nauczaniu, mam na myśli dostosowanie parametrów sieci za pomocą stochastycznego zejścia gradientowego lub ulubionego podejścia optymalizacyjnego. Nie ucząc próbek w kolejności, w jakiej są zbierane przez politykę, dekorelujesz je, co pomaga w szkoleniu. Na koniec, aby podjąć decyzję o stanie, wybierasz akcję, która zapewnia najwyższą wartość q:
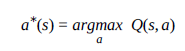
Jeśli Twoja funkcja wartości Q została całkowicie wyuczona, a środowisko jest nieruchome, w tym momencie dobrze jest być chciwym. Jednak podczas nauki oczekuje się, że będziesz eksplorować. Istnieje kilka podejść, które są jednym z najłatwiejszych i najpowszechniejszych sposobów.
P: Regresja liniowa z niesymetryczną funkcją kosztu?
Chcę przewidzieć jakąś wartość Y(x) i próbuję uzyskać prognozy , które optymalizują się między możliwie najniższym poziomem, ale nadal większym niż Y(x). Innymi słowy:
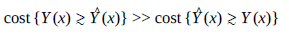
Myślę, że prosta regresja liniowa powinna wystarczyć. Więc trochę wiem, jak zaimplementować to ręcznie, ale myślę, że nie jestem pierwszą osobą, która ma tego rodzaju problem. Czy są jakieś pakiety / biblioteki (najlepiej Python), które robią to, co chcę? Jakiego słowa kluczowego muszę szukać? A co gdybym znał funkcję Y0(x) > 0 gdzie Y(x) > Y0(x) . Jaki jest najlepszy sposób wprowadzenia tych ograniczeń?
Jeśli dobrze cię rozumiem, chcesz się mylić i przeceniać. Jeśli tak, potrzebujesz odpowiedniej, asymetrycznej funkcji kosztu. Jednym prostym kandydatem jest poprawienie kwadratowej straty:
L : (x,α) -> x2(sgnx + α) 2
gdzie -1 < α < 1 jest parametrem, którego można użyć, aby wymienić karę za niedoszacowanie na przeszacowanie. Dodatnie wartości α penalizują przeszacowanie, więc będziesz chciał ustawić wartość ujemną. W Pythonie wygląda to następująco: def loss (x, a): return x ** 2 * (numpy.sign (x) + a) ** 2
Następnie wygenerujmy dane:
import numpy
x = numpy.arange (-10, 10, 0,1)
y = -0,1 * x ** 2 + x + numpy.sin (x) + 0,1 * numpy.random.randn (len (x))
Na koniec zrobimy naszą regresję w tensorflow, bibliotece uczenia maszynowego od Google, która obsługuje automatyczne różnicowanie (dzięki czemu optymalizacja oparta na gradientach takich problemów jest prostsza). Posłużę się tym przykładem jako punktem wyjścia
import tensorflow as tf
X = tf.placeholder(“float”) # create symbolic variables
Y = tf.placeholder(“float”)
w = tf.Variable(0.0, name=”coeff”)
b = tf.Variable(0.0, name=”offset”)
y_model = tf.mul(X, w) + b
cost = tf.pow(y_model-Y, 2) # use sqr error for cost function
def acost(a): return tf.pow(y_model-Y, 2) * tf.pow(tf.sign(y_model-Y) + a, 2)
train_op = tf.train.AdamOptimizer().minimize(cost)
train_op2 = tf.train.AdamOptimizer().minimize(acost(-0.5))
sess = tf.Session()
init = tf.initialize_all_variables()
sess.run(init)
for i in range(100):
for (xi, yi) in zip(x, y):
# sess.run(train_op, feed_dict={X: xi, Y: yi})
sess.run(train_op2, feed_dict={X: xi, Y: yi})
print(sess.run(w), sess.run(b))
cost to zwykły błąd kwadratowy, podczas gdy acost to wspomniana wcześniej asymetryczna funkcja straty.
Jeśli korzystasz z kosztu, który otrzymasz
1,00764 -3,32445
Jeśli używasz acost, otrzymasz
1,02604 -1,07742
acost wyraźnie stara się nie lekceważyć. Nie sprawdzałem zbieżności, ale masz pomysł.