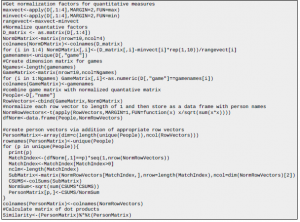
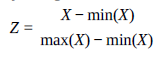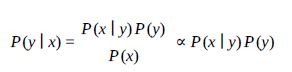Wkład każdej cechy w klasyfikacji?
Mam kilka funkcji i używam Weka do klasyfikowania moich instancji
Na przykład mam: Liczba adj liczba przysłówków liczba znaków interpunkcyjnych w moim zestawie funkcji, ale chcę poznać udział każdej funkcji w zestawie funkcji, więc jakie metryki lub parametry są pomocne w uzyskaniu wkładu funkcji?
Nazywa się to rankingiem cech, który jest ściśle powiązany z wyborem cech.
ranking cech = określanie ważności każdej indywidualnej cechy
wybór cech = wybór podzbioru odpowiednich cech do wykorzystania w konstrukcji modelu. Jeśli więc możesz klasyfikować funkcje, możesz ich używać do wybierania funkcji, a jeśli możesz wybrać podzbiór przydatnych funkcji, dokonałeś przynajmniej częściowego rankingu, usuwając bezużyteczne jedynki. Ta strona Wikipedii i ten post w Quorze powinny dać kilka pomysłów. Najpopularniejsze jest rozróżnienie między metodami filtrującymi a metodami opartymi na opakowaniach i metodami osadzonymi. Jednym prostym, przybliżonym sposobem jest użycie znaczenia cech w lasach drzew
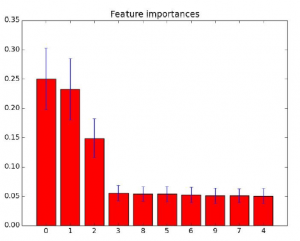
Inne popularne sposoby:
* rekurencyjna eliminacja funkcji.
* regresja krokowa (lub LARS Lasso).
Jeśli używasz scikit-learn, sprawdź module-sklearn.feature_selection. Domyślam się, że Weka ma kilka podobnych funkcji.
P: Kiedy używać Random Forest zamiast SVM i odwrotnie?
Tagi: uczenie maszynowe (poprzednie Q) (następne Q), svm (poprzednie Q) (następne Q)
Kiedy można używać Random Forest zamiast SVM i odwrotnie?
Rozumiem, że walidacja krzyżowa i porównanie modeli są ważnym aspektem wyboru modelu, ale tutaj chciałbym dowiedzieć się więcej o praktycznych zasadach i heurystyce tych dwóch metod. Czy ktoś mógłby wyjaśnić subtelności, mocne i słabe strony klasyfikatorów oraz problemy, które najlepiej pasują do każdego z nich? Dzięki za pomoc!
Powiedziałbym, że wybór zależy w dużej mierze od tego, jakie masz dane i jaki jest Twój cel. Kilka praktycznych zasad. Random Forest jest wewnętrznie przystosowany do problemów z wieloma klasami, podczas gdy SVM jest z natury rzeczy dwuklasowy. W przypadku problemu z wieloma klasami należy go zredukować do wielu problemów z klasyfikacją binarną. Random Forest działa dobrze w połączeniu z funkcjami liczbowymi i kategorialnymi. Kiedy funkcje są w różnych skalach, to też jest w porządku. Z grubsza rzecz biorąc, w Random Forest możesz używać danych w takiej postaci, w jakiej są. SVM maksymalizuje „margines”, a zatem opiera się na koncepcji „odległości” między różnymi punktami. Do Ciebie należy decyzja, czy „odległość” ma znaczenie. W konsekwencji kodowanie typu one-hot dla cech kategorialnych jest koniecznością. Ponadto zdecydowanie zaleca się skalowanie min-max lub inne na etapie przetwarzania wstępnego. Jeśli masz dane z n punktami i cechami, krokiem pośrednim w SVM jest skonstruowanie macierzy nxn (pomyśl o wymaganiach pamięci do przechowywania) poprzez obliczenie n2 iloczynów skalarnych (złożoność obliczeniowa). Dlatego z reguły SVM jest trudny do skalowania powyżej 10 ^ 5 punktów. Duża liczba cech (jednorodne cechy ze znaczną odległością, piksel obrazu byłby idealnym przykładem) generalnie nie stanowi problemu. W przypadku problemu klasyfikacyjnego Random Forest podaje prawdopodobieństwo przynależności do klasy. S SVM podaje „wektory pomocnicze”, czyli punkty w każdej klasie najbliżej granicy między klasami. Mogą być sami zainteresowani interpretacją.
Połączenie między regularyzacją a opadaniem gradientowym
Chciałbym zrozumieć regularyzację / kurczenie się w świetle MLE / Gradient Descent. Znam oba pojęcia, ale nie wiem / nie rozumiem, czy oba służą do wyznaczania współczynników modelu liniowego. Jeśli tak, jakie kroki należy wykonać? Aby bardziej szczegółowo rozwinąć, zastosowano regularyzację w celu zmniejszenia wariancji, co jest osiągane poprzez ukaranie współczynników modelu liniowego. Parametr dostrajania, lambda, jest określany przez weryfikację krzyżową. Po określeniu lambdy współczynniki są wyznaczane automatycznie, prawda? Dlaczego więc musimy minimalizować (RSS + termin regularyzacji), aby znaleźć współczynniki? Czy kroki są następujące:
- Znajdź lambdę poprzez walidację krzyżową
- Minimalizuj (RSS + regularyzacja) przez MLE lub GD
- Znajdź współczynniki
- Karać współczynniki, aby zmniejszyć wariancję
- Pozostaje nam niewielki podzbiór współczynników
Procedura dopasowania to ta, która faktycznie znajduje współczynniki modelu. Termin regularyzacyjny jest używany do pośredniego znajdowania współczynników poprzez karanie dużych współczynników podczas procedury dopasowania. Prosty (choć nieco stronniczy / naiwny) przykład może pomóc zilustrować tę różnicę między regularyzacją a zejściem gradientowym:
X, y <- odczytaj dane wejściowe
dla różnych wartości lambda L.
dla każdego fałdu walidacji krzyżowej przy użyciu X, y, L
theta <- minimalizuj (RSS + regularyzacja za pomocą L) przez MLE / GD
score <- oblicz wydajność modelu przy użyciu theta na zbiorze walidacyjnym
jeśli średni wynik w fałdach dla L jest lepszy niż aktualny najlepszy średni wynik
L_best <- L
Jak widać, procedura dopasowania (w naszym przypadku MLE lub GD) wyszukuje najlepsze współczynniki przy określonej wartości lambda. Na marginesie, spojrzałbym tutaj na tę odpowiedź dotyczącą dostrajania parametru regularyzacji, ponieważ jest ona nieco mętna pod względem odchylenia.
W jaki sposób naukowcy wymyślili prawidłowy model ukrytego Markowa?
Rozumiem, w jaki sposób ukryty model Markowa jest używany w sekwencjach genomowych, takich jak znajdowanie genu. Ale nie rozumiem, w jaki sposób wymyślili konkretny model Markowa. Mam na myśli, ile stanów powinien mieć model? Ile możliwych przejść? Czy model powinien mieć pętlę? Skąd mieliby wiedzieć, że ich model jest optymalny? Czy wyobrażają sobie, powiedzmy 10 różnych modeli, porównują te 10 modeli i publikują najlepszy?
Znam trzy główne podejścia:
- A priori. Możesz wiedzieć, że są cztery pary zasad do wyboru, więc pozwól HMM mieć cztery stany. Albo możesz wiedzieć, że angielski ma 44 fonemy, a więc 44 stany dla warstwy ukrytych fonemów w modelu rozpoznawania głosu.
- Szacowanie. Liczbę stanów można często oszacować z góry, być może poprzez proste grupowanie obserwowanych cech HMM. Jeśli macierz przejść HMM jest trójkątna (co często ma miejsce w przewidywaniu awarii), liczba stanów determinuje kształt rozkładu całkowitego czasu od stanu początkowego do stanu końcowego.
- Optymalizacja. Jak sugerujesz, albo utworzono wiele modeli i dopasowano je, a najlepszy model został wybrany. Można również dostosować metodologię, która uczy się HMM, aby umożliwić modelowi dodawanie lub odrzucanie stanów w razie potrzeby.
Samouczek dotyczący analizy nastrojów
Próbuję zrozumieć analizę sentymentów i jak ją zastosować w dowolnym języku (R, Python itp.). Chciałbym wiedzieć, czy w internecie jest dobre miejsce na tutorial, który mogę śledzić. Poszukałem w Google, ale nie byłem zbyt zadowolony, ponieważ nie były to samouczki, a raczej teoria. Chcę teorii i praktycznych przykładów.
Książka NLTK jest zdecydowanie najlepszym samouczkiem na temat podstawowego NLP, jaki widziałem (w Pythonie). Kurs Coursera dotyczący NLP jest również dość dobry. Rozpoczyna się od podstaw i przenosi ucznia na poziom nowicjusza.
Przewidywanie nowych danych z naiwnym Bayesem
Powiedzmy, że miałem następujący zestaw treningowy dla algorytmu Naive Bayes.
Outlook Person gra w golfa?
——- —— ———-
Sunny Joe Tak
Sunny Mary Tak
Raining Joe Tak
Raining Mary No
Pada Harry Tak
Jeśli spróbuję przewidzieć, czy Harry będzie grał w golfa w słoneczny dzień (na który nie mam danych). Czy poprawne byłoby wykluczenie atrybutu osoby i wykorzystanie pozostałego atrybutu perspektywy do obliczenia prawdopodobieństwa takiego zdarzenia? A może może to potencjalnie powodować problemy z większym zestawem danych, którego nie znam?
Wśród założeń Naive Bayes głównym z nich jest to, że cechy są warunkowo niezależne. W przypadku naszego problemu mielibyśmy:
Aby odpowiedzieć na pytanie, czy Harry będzie grał w słoneczny dzień ?, musisz obliczyć:
P (P lay | Outlook, Person) ∝ P (Play) P (Outlook | Play) P (Name | Play)
Aby odpowiedzieć na pytanie, czy Harry będzie grał w słoneczny dzień ?, musisz obliczyć:
P (Y es|Sunny, Harry) = P (Y es)P (Sunny|Y es)P (Harry|Y es)
P (No|Sunny, Harry) = P (No)P (Sunny|No)P (Harry|No)
i wybierz prawdopodobieństwo o większej wartości
Tak mówi teoria. Aby odpowiedzieć na twoje pytanie, przeformułuję główne założenie Naive Bayes. Założenie, że cechy są niezależne, biorąc pod uwagę wynik, oznacza w zasadzie, że informacje podane przez wspólną dystrybucję można uzyskać poprzez iloczyn marginesów. Mówiąc prostym językiem: załóżmy, że możesz dowiedzieć się, czy Harry gra w słoneczne dni, jeśli wiesz tylko, ile Harry gra w ogóle i ile ktoś gra w słoneczne dni. Jak widać, po prostu nie wykorzystałbyś faktu, że Harry gra w słoneczne dni, nawet gdybyś miał ten rekord w swoich danych. Po prostu dlatego, że Naive Bayes zakłada, że nie ma użytecznych informacji w interakcji między cechami, i jest to dokładne znaczenie warunkowej niezależności, na której opiera się Naive Bayes. To powiedziawszy, jeśli chcesz korzystać z interakcji funkcji, musisz albo użyć innego modelu, albo po prostu dodać nową połączoną funkcję, taką jak połączenie czynników nazw i perspektyw. Podsumowując, jeśli nie uwzględnisz nazw w swoich funkcjach wejściowych, będziesz mieć ogólny klasyfikator mądrości, tak jak wszyscy grają bez względu na perspektywę, ponieważ większość instancji ma play = yes. Jeśli umieścisz nazwę w swoich zmiennych wejściowych, pozwolisz zmienić tę ogólną mądrość za pomocą czegoś konkretnego dla gracza. Więc twoja mądrość klasyfikatora wyglądałaby tak, jakby gracze ogólnie woleli grać, bez względu na perspektywy, ale poślubiaj mniej, aby grać mniej w Rainy. Istnieje jednak potencjalny problem z Naive Bayes w Twoim zestawie danych. Ten problem jest związany z potencjalną dużą liczbą poziomów dla zmiennej Nazwa. W celu przybliżenia prawdopodobieństwa dzieje się jedna rzecz: więcej danych, lepsze szacunki. Prawdopodobnie miałoby to miejsce w przypadku zmiennej Outlook, ponieważ są dwa poziomy i dodanie większej ilości danych prawdopodobnie nie zwiększyłoby liczby poziomów. Więc szacunki dla Outlooka byłyby prawdopodobnie lepsze przy większej ilości danych. Jednak dla nazwy nie będziesz miał takiej samej sytuacji. Dodanie większej liczby instancji byłoby możliwe tylko poprzez dodanie większej liczby nazw. Oznacza to, że średnio liczba wystąpień dla każdej nazwy byłaby stosunkowo stabilna. A jeśli miałbyś jedną instancję, tak jak w przypadku Harry’ego, nie masz wystarczających danych, aby oszacować P (Harry | Nie). Tak się składa, że problem ten można załagodzić stosując wygładzanie. Być może wygładzanie Laplace’a (lub bardziej ogólne jak Lindstone) jest bardzo pomocne. Powodem jest to, że szacunki oparte na maksymalnym prawdopodobieństwie mają duże problemy z takimi przypadkami. Mam nadzieję, że odpowiada przynajmniej częściowo na Twoje pytanie.
Bagging vs Dropout w głębokich sieciach neuronowych
Pakowanie to generowanie wielu predyktorów, które działają tak samo, jak pojedynczy predyktor. Dropout to technika, która uczy sieci neuronowe uśredniania wszystkich możliwych podsieci. Patrząc na najważniejsze zawody Kaggle’a wydaje się, że te dwie techniki są często używane razem. Nie widzę żadnej teoretycznej różnicy poza faktyczną implementacją. Kto może mi wyjaśnić, dlaczego powinniśmy używać ich obu w każdej rzeczywistej aplikacji? i dlaczego wydajność poprawia się, gdy używamy ich obu?
Bagging i dropout nie dają tego samego, chociaż oba są typami uśredniania modelu. Pakowanie to operacja obejmująca cały zbiór danych, która trenuje modele na podzbiorze danych uczących. Dlatego niektóre przykłady treningowe nie są pokazane dla danego modelu.
Z kolei rezygnacja jest stosowana do funkcji w każdym przykładzie szkoleniowym. Prawdą jest, że wynik jest funkcjonalnie równoważny do trenowania wykładniczo wielu sieci (ze wspólnymi wagami!), A następnie równego ważenia ich wyników. Ale porzucanie działa w przestrzeni funkcji, powodując, że niektóre funkcje są niedostępne w sieci, a nie pełne przykłady. Ponieważ każdy neuron nie może całkowicie polegać na jednym wejściu, reprezentacje w tych sieciach są zwykle bardziej rozproszone, a sieć jest mniej podatna na przepełnienie.
Kiedy muszę używać aucPR zamiast auROC? (i wzajemnie)
Zastanawiam się, czy czasami do walidacji modelu nie lepiej jest użyć aucPR zamiast aucROC? Czy te przypadki zależą tylko od „zrozumienia domeny i biznesu”? Szczególnie myślę o „problemie z niezrównoważoną klasą”, w którym bardziej logiczne wydaje się użycie aucPR, ponieważ przypominanie i precyzja są dobrze używanymi miernikami do tego problem. Tak, masz rację, że dominująca różnica między obszarem pod krzywą krzywej charakterystycznej operatora odbiornika (ROC-AUC) a obszarem pod krzywą precyzyjnej krzywej przypomnienia (PR-AUC) polega na jej przyczepności dla klas niezrównoważonych . Są bardzo podobne i wykazano, że zawierają zasadniczo te same informacje, jednak krzywe PR są nieco bardziej skomplikowane, ale dobrze narysowana krzywa daje pełniejszy obraz. Problem z PR-AUC polega na tym, że trudno jest interpolować między punktami na krzywej PR, a zatem integracja numeryczna w celu uzyskania obszaru pod krzywą staje się trudniejsza. Sprawdź tę dyskusję na temat różnic i podobieństw.
Cytując streszczenie Davisa z 2006 r .:
Krzywe charakterystyki operatora odbiornika (ROC) są powszechnie używane do przedstawiania wyników binarnych problemów decyzyjnych w uczeniu maszynowym. Jednak w przypadku wysoce wypaczonych zestawów danych krzywe Precision-Recall (PR) dają bardziej pouczający obraz wydajności algorytmu. Pokazujemy, że istnieje głęboki związek między przestrzenią ROC a przestrzenią PR, tak że krzywa dominuje w przestrzeni ROC wtedy i tylko wtedy, gdy dominuje w przestrzeni PR. Następstwem jest koncepcja możliwej do osiągnięcia krzywej PR, która ma właściwości podobne do wypukłego kadłuba w przestrzeni ROC; pokazujemy wydajny algorytm obliczania tej krzywej. Na koniec zauważamy również, że różnice w dwóch typach krzywych są istotne dla projektowania algorytmów. Na przykład w przestrzeni PR niepoprawna jest liniowa interpolacja między punktami. Ponadto algorytmy optymalizujące obszar pod krzywą ROC nie gwarantują optymalizacji obszaru pod krzywą PR.
Cel wizualizacji danych wielowymiarowych?
Istnieje wiele technik wizualizacji zbiorów danych o dużych wymiarach, takich jak T-SNE, izomapa, PCA, nadzorowany PCA itp. Przechodzimy przez ruchy rzutowania danych w dół do przestrzeni 2D lub 3D, więc mamy „ładne obrazy ”. Ale czy ten „ładny obrazek” ma znaczenie? Jakie możliwe spostrzeżenia może ktoś uchwycić, próbując wizualizować tę osadzoną przestrzeń? Pytam, ponieważ projekcja w dół do tej osadzonej przestrzeni jest zwykle bez znaczenia. Na przykład, jeśli projektujesz swoje dane na główne komponenty generowane przez PCA, te główne komponenty (wektory eigan) nie odpowiadają cechom w zbiorze danych; to ich własna przestrzeń fabularna. Podobnie, t-SNE rzutuje dane w dół do przestrzeni, w której elementy są blisko siebie, jeśli minimalizują jakąś rozbieżność KL. To już nie jest oryginalna przestrzeń funkcji. (Popraw mnie, jeśli się mylę, ale nie sądzę, aby społeczność ML podjęła duży wysiłek, aby użyć t-SNE do pomocy w klasyfikacji; to jednak inny problem niż wizualizacja danych.) Jestem po prostu w dużej mierze zdezorientowani, dlaczego ludzie robią tak wielką sprawę z niektórymi z tych wizualizacji.
Przede wszystkim twoje wyjaśnienie dotyczące metod jest prawidłowe. Chodzi o to, że algorytmy osadzania mają nie tylko wizualizować, ale zasadniczo zmniejszać wymiarowość, aby poradzić sobie z dwoma głównymi problemami w statystycznej analizie danych, a mianowicie Curse of Dimentionaliy i Low-Sample Size Problem, tak aby nie miały przedstawiać fizycznie zrozumiałych cech i one są nie tylko znaczące, ale także niezbędne do analizy danych! W rzeczywistości wizualizacja jest prawie ostatnim zastosowaniem metod osadzania. Projekcja wielowymiarowa danych w przestrzeni o niższych wymiarach pomagają zachować rzeczywiste odległości parami (głównie dystans euklidesowy), które ulegają zniekształceniu w dużych wymiarach lub przechwytują większość informacji osadzonych w wariancji różnych cech.
Świetne pytanie. W rozdziale 4 książki „Oświetlanie ścieżki, plan badań i rozwoju w zakresie analityki wizualnej” Jamesa J. Thomasa i Kristin A. Cooka znajduje się dyskusja na temat reprezentacji danych i transformacji danych. W swoich badaniach podchodziłem do tego pytania w kontekście PCA i analizy czynnikowej. Moja krótka odpowiedź jest taka, że wizualizacje są przydatne, jeśli ktoś ma transformację danych, aby przejść z przestrzeni wizualizacji do pierwotnej przestrzeni danych. Byłoby to dodatkowo prowadzone w ramach analizy wizualnej.
Opierając się na oświadczeniach i dyskusjach, myślę, że należy wyróżnić ważną kwestię. Transformacja do niższej przestrzeni wymiarowej może zredukować informacje, co różni się od uczynienia ich bezsensownymi. Pozwólcie, że użyję następującego
Analogia: Obserwowanie (2D) obrazów naszego świata (3D) jest zwykłą praktyką. Metoda wizualizacji zapewnia tylko różne „okulary” do oglądania wysokowymiarowej przestrzeni. Dobrze jest „zaufać” metodzie wizualizacji, aby zrozumieć jej elementy wewnętrzne. Moim ulubionym przykładem jest MDS. Metodę tę można łatwo wdrożyć samodzielnie, korzystając z narzędzia optymalizacyjnego (np. R optim). Możesz więc zobaczyć, jak słowa metody, możesz zmierzyć błąd wyniku itp. Na koniec otrzymasz obraz zachowujący podobieństwo oryginalnych danych z pewnym stopniem precyzji. Nie więcej, ale nie mniej.
Pylearn2 vs TensorFlow
Mam zamiar zagłębić się w długi projekt badawczy NN i chciałem pchnąć w kierunku Pylearn2 lub TensorFlow? Czy od grudnia 2015 r. Społeczność zaczęła zmieniać kierunek? Możesz wziąć pod uwagę, że Pylearn2 nie ma już programisty i teraz wskazuje na inne biblioteki oparte na Theano: istnieją inne struktury uczenia maszynowego zbudowane na bazie Theano, które mogą Cię zainteresować, takie jak: Blocks, Keras i Lasagne.
TensorFlow dopiero się zaczyna, warto jednak zauważyć, że liczba pytań w TensorFlow (244) na temat Stack Overflow już przewyższa Torch (166) i prawdopodobnie dogoni Theano (672) w 2016 roku.
O ile wiem, istniejące (prawie wszystkie) biblioteki w Pythonie mogą obsługiwać bardzo złożone modele sieci neuronowych. Jednak TensorFlow nie jest obecnie dopracowany. Wciąż ma długą drogę do rozwoju, zanim zostanie zaakceptowana jako biblioteka głównego nurtu dla ML. Tak więc, kontynuując istniejące biblioteki, takie jak PyLearn / Keras / Torch, et ma sens, ponieważ od teraz (również ponieważ mają już szerokie i oddane społeczności), ponieważ musisz skoncentrować się na badaniach, a nie martwić się błędami i problemami technicznymi biblioteki.
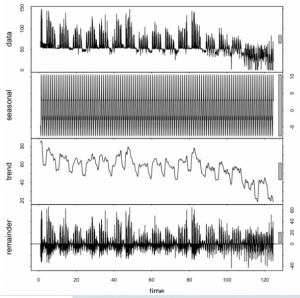
Przewidywanie użycia aplikacji na telefonie komórkowym
Obecnie tworzę aplikację, która stara się przewidzieć, w jaki sposób użytkownicy używają różnych aplikacji, i podpowiadać mu, z jakich aplikacji będzie aktualnie korzystać (lista rankingowa oparta na aktualnych warunkach użytkownika). W ciągu ostatniego tygodnia zbieram dane i nie wiem, jakie podejście przyjąć. Zastanawiałem się nad zastosowaniem wielu sezonowości (popraw mnie, jeśli używam złej terminologii), takich jak pora dnia, dzień tygodnia, tydzień miesiąca, miesiąc i kwartał. Chcę również użyć lokalizacji i innych danych z czujników (takich jak stan użytkownika „chodzenie” lub „siedzenie” później). Podsumowałem użycie w ciągu ostatniego tygodnia na poziomie godzinowym dla niektórych aplikacji. Kraty reprezentują każde otwarcie aplikacji w tym czasie, a zielona linia to ważona średnia krocząca, która ma wagę 0,5 w odniesieniu do najbliższych sąsiadów. Teraz widzę przed sobą kilka wyzwań i byłbym bardzo wdzięczny za wkład innych osób lub dobre zasoby, aby znaleźć dalsze informacje.
* Czy uważasz, że mój model jest dobry do tego problemu
* Jak uwzględnić starzenie się danych?
* Jak zsumować różne sezonowości / stany / lokalizacje? Pomnóż je?
* Czy ma sens wygładzanie krzywej tak jak ja?
Więc zebrałeś dane pokazujące, która aplikacja jest używana w dowolnym momencie, podzielone na godziny w ciągu dnia. Masz kilka aplikacji. Wspominasz o innych wymiarach, takich jak stan użytkownika podczas korzystania z aplikacji (chodzenie, brak chodzenia), (aktywny, nieaktywny – wydaje mi się, że nie zbierasz dużego wykorzystania 2-6. Dzieje się tak dlatego, że użycie pochodzi z samokierowany ping z aplikacji, gdy użytkownik jest naprawdę nieobecny?), lokalizacja (czy będą to wszystkie możliwe wartości, czy też użyjesz czegoś w rodzaju faktu, że ta lokalizacja była często wcześniej widziana?). Innym interesującym związkiem może być parowanie aplikacji, tj. Wyszukiwanie relacji między aplikacją A używaną po użyciu aplikacji B lub przed aplikacją B. Niezależnie od tego na pewno będziesz mieć wiele różnych wymiarów, na podstawie których można zmierzyć charakterystykę użytkowania dla dowolnego konkretnego pomiaru użytkowania i tak jesteś z pewnością będzie miał problem wielowymiarowy. Możesz spróbować wizualizować to jako problem przestrzeni N, z osią pomiaru dla każdej z twoich cech. Każdy z poprzednich pomiarów reprezentuje wektory, a następnym pomiarem tworzony jest nowy wektor. Na tej podstawie chcesz przewidzieć przyszłe zachowanie na podstawie pomiaru charakterystyk wejściowych z przestrzeni użytkowania. Możesz wybrać coś, co klasyfikuje się jako najbliższy sąsiad i prawdopodobnie chcesz to zrobić przy pierwszym podejściu do problemu. Możesz chcieć uczynić model predykcyjny bardziej zaawansowanym, dodając prawdopodobieństwa do klasyfikatora i działając na tym. Oznacza to uzyskiwanie szacunków prawdopodobieństwa przynależności do klasy, a nie tylko zwykłych klasyfikacji. Ale budowałbym całość stopniowo. Zacznij od prostego i zwiększaj złożoność, gdy tego potrzebujesz. Zwiększona złożoność będzie miała również wpływ na wydajność, więc dlaczego nie bazować na czymś. Czy w przypadku starzenia się danych chcesz zmniejszyć moc predykcyjną charakterystyk które są za długie w zębie? Jeśli tak, powiedz sobie jasno, co to oznacza, ilościowo. Czy ufam mniejszym danym o użytkowaniu z ostatniego miesiąca niż wczorajszym? Może tak, ale w takim razie dlaczego? czy moje użycie jest inne, ponieważ jestem inny lub ponieważ ostatni miesiąc był wyjątkowy w porównaniu z wczorajszym, lub odwrotnie? Ponownie, korzystne może być zignorowanie tego na początku, a następnie próba wyszukania charakterystyk „sezonowości” lub okresowości na podstawie danych. Po ustaleniu, czy / jak to się zmienia, możesz zważyć ten wkład w porównaniu z bezpośrednim użyciem na różne sposoby. Być może chcesz zwiększyć udział w podobnym okresie (ta sama pora dnia i ta sama lokalizacja oraz poprzednie użycie aplikacji). Być może chcesz zapewnić wykładnicze tłumienie danych historycznych, ponieważ użycie zawsze się dostosowuje i zmienia, a ostatnie użycie wydaje się znacznie lepszym predyktorem niż 3xcurrent. W tym wszystkim właściwą perspektywą nauki o danych jest pozwolenie, aby dane Cię prowadziły.