Czyszczenie danych jest wstępnym krokiem do analizy statystycznej, w której zestaw danych jest edytowany w celu poprawienia błędów i nadania mu formy odpowiedniej do przetwarzania przez oprogramowanie statystyczne. Techniki analizy danych eksploracyjnych są często stosowane w celu identyfikacji problemu.
PYTANIE: Jak mogę przekształcić nazwy w poufny zestaw danych, aby uczynić go anonimowym, ale zachować niektóre cechy tych nazw?
Pracuję z zestawami danych, które zawierają dane osobowe (PII) i czasami muszę udostępniać część zbioru danych stronom trzecim w sposób, który nie naraża PII i nie naraża mojego pracodawcy na odpowiedzialność. Nasze zwykłe podejście polega tutaj na całkowitym wstrzymaniu danych, a w niektórych przypadkach na zmniejszeniu ich rozdzielczości; np. zastąpienie dokładnego adresu ulicy odpowiednim okręgiem lub spisem spisowym. Oznacza to, że niektóre rodzaje analiz i przetwarzania muszą być wykonywane wewnętrznie, nawet jeśli strona trzecia ma zasoby i wiedzę bardziej dostosowane do tego zadania. Ponieważ dane źródłowe nie są ujawniane, sposób, w jaki podchodzimy do tej analizy i przetwarzania, nie jest przejrzysty. W rezultacie zdolność jakiejkolwiek strony trzeciej do przeprowadzania kontroli jakości / kontroli jakości, dostosowywania parametrów lub wprowadzania udoskonaleń może być bardzo ograniczona.
Anonimizacja poufnych danych
Jedno z zadań obejmuje identyfikację osób według ich nazw, w danych przesłanych przez użytkownika, z uwzględnieniem błędów i niespójności. Osoba prywatna może być zapisana w jednym miejscu jako „Dave”, a w innym jako „David”, podmioty komercyjne mogą mieć wiele różnych skrótów i zawsze są jakieś literówki. Opracowałem skrypty oparte na wielu kryteriach, które określają, kiedy dwa rekordy o nieidentycznych nazwach reprezentują tę samą osobę, i przypisują im wspólny identyfikator. W tym momencie możemy uczynić zestaw danych anonimowym, ukrywając nazwy i zastępując je tym osobistym numerem identyfikacyjnym. Ale to oznacza, że odbiorca prawie nie ma informacji o np. siła meczu. Wolelibyśmy móc przekazywać jak najwięcej informacji bez ujawniania tożsamości.
Co nie działa
Na przykład byłoby wspaniale móc szyfrować ciągi przy zachowaniu odległości edycji. W ten sposób osoby trzecie mogą wykonać niektóre z własnej kontroli jakości / kontroli jakości lub zdecydować się na dalsze przetwarzanie samodzielnie, bez uzyskiwania dostępu (lub możliwości potencjalnej zmiany) danych osobowych. Być może dopasowujemy ciągi wewnętrznie z odległością edycji <= 2, a odbiorca chce przyjrzeć się implikacjom zaostrzenia tej tolerancji na odległość edycji <= 1. Ale jedyną znaną mi metodą jest ROT13 (bardziej ogólnie , każdy szyfr szyfrujący), który nawet nie liczy się jako szyfrowanie; to tak, jakby napisać nazwiska do góry nogami i powiedzieć: „Obiecujesz, że nie przewrócisz papieru?” Innym złym rozwiązaniem byłoby skrócenie wszystkiego. „Ellen Roberts” zmienia się w „ER” i tak dalej. To kiepskie rozwiązanie, ponieważ w niektórych przypadkach inicjały, w połączeniu z danymi publicznymi, ujawnią tożsamość osoby, aw innych przypadkach są zbyt niejednoznaczne; „Benjamin Othello Ames” i „Bank of America” będą miały takie same inicjały, ale ich nazwy są inaczej różne. Więc nie robi żadnej z rzeczy, których chcemy. Nieelegancką alternatywą jest wprowadzenie dodatkowych pól w celu śledzenia niektórych atrybutów nazwy, np .:

Nazywam to „nieeleganckim”, ponieważ wymaga przewidywania, które cechy mogą być interesujące i jest stosunkowo szorstkie. Jeśli nazwy zostaną usunięte, niewiele można rozsądnie wnioskować o sile dopasowania między rzędami 2 i 3 lub o odległości między rzędami 2 i 4 (tj. O tym, jak blisko są dopasowania).
Wniosek
Celem jest transformacja ciągów w taki sposób, aby zachować jak najwięcej użytecznych właściwości oryginalnego ciągu, jednocześnie zasłaniając oryginalny ciąg. Odszyfrowanie powinno być niemożliwe lub tak niepraktyczne, aby było faktycznie niemożliwe, bez względu na rozmiar zestawu danych. W szczególności bardzo przydatna byłaby metoda, która zachowuje odległość edycji między dowolnymi ciągami.
ODPOWIEDŹ: Jedno z odniesień, które wspomniałem w PO, doprowadziło mnie do potencjalnego rozwiązania, które wydaje się dość potężne, opisane w „Zachowującym prywatność powiązaniu rekordów za pomocą filtrów Bloom” (doi: 10.1186 / 1472-6947-9-41):
Opracowano nowy protokół służący do zachowania poufności powiązania rekordów z zaszyfrowanymi identyfikatorami, pozwalający na błędy w identyfikatorach. Protokół oparty jest na filtrach Blooma na q-gramach identyfikatorów. Artykuł szczegółowo opisuje metodę, którą streszczę tutaj najlepiej jak potrafię. Filtr Blooma to seria bitów o stałej długości, przechowująca wyniki ustalonego zestawu niezależnych funkcji skrótu, z których każdy jest obliczany na tej samej wartości wejściowej. Wyjściem każdej funkcji skrótu powinna być wartość indeksu spośród możliwych indeksów w filtrze; tzn. jeśli masz serię 10 bitów z indeksowaniem 0, funkcje skrótu powinny zwracać (lub być odwzorowane na) wartości od 0 do 9. Filtr rozpoczyna się od każdego bitu ustawionego na 0. Po zaszyfrowaniu wartości wejściowej każdą funkcją z zestaw funkcji skrótu, każdy bit odpowiadający wartości indeksu zwracanej przez dowolną funkcję skrótu jest ustawiony na 1. Jeśli ten sam indeks jest zwracany przez więcej niż jedną funkcję skrótu, bit o tym indeksie jest ustawiany tylko raz. Można uznać filtr Bloom za superpozycję zbioru skrótów na ustalony zakres bitów. Protokół opisany w powyższym artykule dzieli łańcuchy na n-gram, które są w tym przypadku zestawami znaków. Na przykład „cześć” może dać następujący zestaw 2 gramów:

Wypełnianie przodu i tyłu spacjami wydaje się być ogólnie opcjonalne przy konstruowaniu n-gramów; przykłady podane w artykule, który proponuje tę metodę, wykorzystują takie wypełnienie. Każdy n-gram można haszować, aby uzyskać filtr Bloom, a ten zestaw filtrów Bloom może nakłada się na siebie (bitowa operacja LUB), aby utworzyć filtr Bloom dla łańcucha. Jeśli filtr zawiera o wiele więcej bitów niż w przypadku funkcji skrótu lub n-gramów, stosunkowo mało prawdopodobne jest, aby arbitralne łańcuchy tworzyły dokładnie ten sam filtr. Jednak im więcej ngramów mają dwa ciągi, tym więcej bitów ich filtry będą ostatecznie dzielić. Następnie możesz porównać dowolne dwa filtry A, B za pomocą współczynnika Dicei:
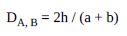
Gdzie h jest liczbą bitów ustawionych na 1 w obu filtrach, a jest liczbą bitów ustawioną na 1 tylko w filtrze A, a b jest liczbą bitów ustawioną na 1 w samym filtrze B. Jeśli łańcuchy są dokładnie to samo, współczynnik kości wyniesie 1; im bardziej się różnią, tym bliższy współczynnik będzie 0. Ponieważ funkcje mieszające odwzorowują nieokreśloną liczbę unikalnych danych wejściowych na niewielką liczbę możliwych indeksów bitowych, różne dane wejściowe mogą generować ten sam filtr, więc współczynnik wskazuje tylko prawdopodobieństwo że łańcuchy są takie same lub podobne. Liczba różnych funkcji skrótu i liczba bitów w filtrze są ważnymi parametrami do określania prawdopodobieństwa fałszywych trafień – pary danych wejściowych, które są znacznie mniej podobne niż współczynnik kostki wytwarzany tą metodą. Istnieje pewna elastyczność we wdrażaniu tej metody; zobacz także ten artykuł z 2010 r. (również link na końcu pytania), aby uzyskać pewne wskazówki na temat jego skuteczności w stosunku do innych metod i różnych parametrów.
ODPOWIEDŹ: Jeśli to możliwe, powiążę powiązane rekordy (np. Dave, David itp.) I zastąpię je numerem sekwencyjnym (1,2,3 itd.) Lub solonym hashem ciągu, który jest używany do reprezentowania wszystkich powiązanych rekordy (np. David zamiast Dave). Zakładam, że osoby trzecie nie muszą mieć pojęcia, jak naprawdę się nazywa, w przeciwnym razie równie dobrze możesz im je podać. edycja: Musisz zdefiniować i uzasadnić, jakie operacje musi wykonywać osoba trzecia. Na przykład, co jest złego w używaniu inicjałów, po których następuje liczba (np. BOA-1, BOA-2 itd.), Aby ujednoznacznić Bank of America od Benjamina Othello Amesa? Jeśli to zbyt odkrywcze, możesz skasować niektóre litery lub nazwiska; np. [AE] -> 1, [FJ] -> 2 itd., więc BOA zmieni się w 1OA, lub [„Bank”, „Barry”, „Bruce” itp.] -> 1, więc Bank of America ponownie 1OA.
ODPOWIEDŹ: Jedną z opcji (w zależności od rozmiaru zestawu danych) jest podanie odległości edycji (lub innych miar podobieństwa, których używasz) jako dodatkowego zestawu danych.
Na przykład.:
- Wygeneruj zestaw unikalnych nazw w zbiorze danych
- Dla każdej nazwy oblicz odległość edycji względem siebie
- Wygeneruj identyfikator lub nieodwracalny skrót dla każdej nazwy
- Zastąp nazwy w oryginalnym zestawie danych tym identyfikatorem
- Podaj macierz odległości edycji między numerami ID jako nowy zestaw danych
Chociaż można jeszcze wiele zrobić, aby nawet zdeanonimizować dane z tych danych.
Na przykład. jeśli wiadomo, że „Tim” jest najpopularniejszym imieniem dla chłopca, liczenie częstotliwości identyfikatorów, które ściśle pasują do znanego odsetka Timi w całej populacji, może to dać. Następnie możesz poszukać imion z odległością edycji 1 i dojść do wniosku, że te identyfikatory mogą odnosić się do „Toma” lub „Jima” (w połączeniu z innymi informacjami).