

Przemysł 4.0 to strategiczna inicjatywa wprowadzona przez rząd niemiecki na początku 2010 roku w celu przekształcenia produkcji przemysłowej poprzez cyfryzację i wykorzystanie potencjału nowych technologii. Jest to próba zwiększenia produktywności i efektywności głównie w sektorze produkcyjnym. System produkcyjny Przemysłu 4.0 ma być wysoce elastyczny i powinien być w stanie wytwarzać zindywidualizowane i niestandardowe produkty. W rzeczywistości jest to ekscytujące zastosowanie automatyzacji w produkcji, obejmujące wykorzystanie robotyki, zarządzanie danymi, przetwarzanie w chmurze i Internet rzeczy (IoT). Zaczęto pokazywać, że sztuczna inteligencja, robotyka, inteligentne czujniki i zintegrowane systemy są ważną częścią normalnego procesu produkcyjnego. We współpracy z maszynami wymaga integracji poziomej na każdym etapie procesu produkcyjnego. Amerykanie mają tę samą koncepcję dla Przemysłu 4.0, ale wolą nazywać to Smart Factory. Przemysł 4.0 dostarczył wiele emocji i wiele osób z różnych branż decyduje się obecnie na to, jak się zaangażować. Wiele osób uważa, że Przemysł 4.0 to w rzeczywistości przepakowywanie i łączenie różnych kluczowych technologii i technologii, które już istniały. Odświeżono akceptację, dostarczając całościową owijkę, która zapewnia pełną funkcjonalność, która zasadniczo obejmuje zadania związane z gromadzeniem dużych zbiorów danych, przetwarzaniem i analizowaniem danych oraz ulepszaniem procesu dzięki pozytywnym informacjom zwrotnym w celu zwiększenia funkcjonalności i wydajności. W pierwszej rewolucji przemysłowej nastąpiło drastyczne przejście od pracy fizycznej do silnika parowego. Była to epoka, w której wykorzystano mechaniczną przewagę maszyn parowych, aby zmniejszyć zależność od wykorzystania ludzkiej pracy. Po niej nastąpiła druga rewolucja przemysłowa, która wykorzystała moc elektryczności. Silniki parowe zostały wycofane przez wprowadzenie silników elektrycznych i systemów analogowych. W tym okresie wszechobecnie budowano linie montażowe do produkcji masowej. Tymczasem Trzecia Rewolucja Przemysłowa skupiła się na automatyzacji pracy. Komputery i systemy elektroniczne były szeroko stosowane w fabrykach i poza nimi. Czwarta rewolucja przemysłowa, powszechnie nazywana IR 4.0, opiera się głównie na integracji danych, sztucznej inteligencji, maszynach przemysłowych i komunikacji w celu stworzenia wysoce wydajnego, zautomatyzowanego i inteligentnego ekosystemu przemysłowego. Industry 4.0 jest podzbiorem IR4.0, który obejmuje przyszły stan przemysłu charakteryzujący się całkowitą cyfryzacją przepływów produkcyjnych. Przemysł 4.0 obejmuje sześć głównych zasad, tj. interoperacyjność, wirtualizację, decentralizację, możliwości w czasie rzeczywistym, orientację na usługi i modułowość. Interoperacyjność umożliwia systemom cyberfizycznym, ludziom i fabrykom skuteczne łączenie się i komunikowanie się ze sobą za pośrednictwem Internetu Rzeczy i Internetu usług (IoS). Wirtualizacja zapewnia wirtualną kopię fabryki, która powstaje poprzez połączenie danych z czujników z wirtualnymi modelami zakładów i modelami symulacyjnymi. Decentralizacja to zdolność systemów cyberfizycznych z fabrykami do samodzielnego podejmowania optymalnych decyzji. Możliwości w czasie rzeczywistym są niezwykle istotne, ponieważ pomagają zbierać i analizować zebrane dane oraz natychmiast generować spostrzeżenia. Poza tym, aby spełnić zasadę zorientowania na usługi, musi oferować usługi systemów cyber-fizycznych, człowieka i fabryk za pośrednictwem IoS. Dzięki zasadzie modułowości posiada elastyczność w dostosowywaniu inteligentnych fabryk do zmieniających się wymagań poszczególnych modułów. Industry 4.0 to przełomowa koncepcja, która rewolucjonizuje sposób wydajnej produkcji produktów i tworzy nową generację przemysłowych systemów produkcyjnych, które będą całkowicie różne od istniejących. Wdrożenie wszystkich tych możliwości w fabrykach to dopiero początek. Muszą być w stanie bezproblemowo i wzajemnie współpracować w środowisku produkcyjnym, aby można je było zaliczyć do Przemysłu 4.0. Co ważne, Przemysł 4.0 determinuje przyszły stan przemysłu charakteryzujący się cyfryzacją przepływów produkcji i jest ekscytującym przełomem, ponieważ innowacje towarzyszą zrównoważonym procesom. Ponieważ produkcja przemysłowa jest silnie napędzana przez globalną konkurencję i szybko zmieniające się wymagania rynku, ekstremalne postępy w obecnych technologiach produkcyjnych mogą je tylko spełnić. Wprowadzenie Przemysłu 4.0 jest zatem aktualne i ważne dla zapewnienia zrównoważonego rozwoju działalności produkcyjnej. Jest to obiecująca koncepcja oparta na integracji procesów produkcyjnych i biznesowych oraz integracji wszystkich interesariuszy biznesowych w łańcuchu wartości, czyli dostawców i klientów.
Przemysł 4.0
Przemysł 4.0: kolejna granica i jej wpływ technologiczny, rola globalnej normalizacji i zrównoważonego rozwoju
Czwarta rewolucja przemysłowa lub Przemysł 4.0 obejmuje branże oparte na produkcji, łączące zaawansowane techniki produkcji z transformacją cyfrową, napędzane przez technologie połączone w celu stworzenia inteligentnych systemów produkcyjnych, które nie tylko są ze sobą połączone, ale także mają zdolność komunikowania się, analizowania, prognozowania i wykorzystywania te informacje w celu prowadzenia dalszych inteligentnych działań. Nowe modele biznesowe i technologie, takie jak internet rzeczy (IoT), big data, sztuczna inteligencja (AI) (dokładna diagnoza w systemach opieki zdrowotnej, analiza danych rynkowych i finansowych, autonomiczne samochody itp.) oraz produkcja addytywna (lotnictwo i produkcja komponentów motoryzacyjnych, biokompatybilne materiały do niestandardowych implantów, urządzenia ratujące życie w sektorze medycznym, wydajna i przyjazna dla środowiska produkcja komponentów dla sektora energetycznego i energetycznego itp.) napędzają zmiany obecnych modeli biznesowych oraz zmiany globalnej ekonomii i struktur rynkowych. Według McKinsey, Industry 4.0: Reinvigorating ASEANManufacturing for the Future, Industry 4.0 ma przynieść globalnie od 1,2 do 3,7 bln USD zysków. Z tego Stowarzyszenie Narodów Azji Południowo-Wschodniej (ASEAN), którego gospodarki członkowskie spośród 10 krajów mają znaczące gospodarki oparte na produkcji, ma potencjał do wykorzystania dużych możliwości i wzrostu wydajności o wartości od 216 do 627 mld USD.
Globalna standaryzacja w Przemyśle 4.0
Przemysł 4.0 otwiera drzwi do łączności, innowacyjności i siły ekonomicznej, pozwalając firmom być bardziej elastycznym, wydajnym i oszczędzającym zasoby . Kluczowym składnikiem tej cyfrowej rewolucji są dane. Wydajne wykorzystanie przetwarzania surowych danych w znaczące informacje jest niezbędnym czynnikiem umożliwiającym przyszłe biznesy. Aby nadążyć za postępem Przemysłu 4.0 i przejściem do tej nowej ery, sektor produkcyjny musi na przykład przejść transformację cyfrową z wbudowanymi czujnikami w sprzęcie produkcyjnym i komponentach produktów, automatyzacją, wszechobecnymi systemami cyberfizycznymi i analizą wszystkich odpowiednie dane i informacje. Transformacje te są napędzane przez cztery główne klastry przełomowych technologii i czynników, a mianowicie dane, moc obliczeniowa i łączność; analityka i sztuczna inteligencja; interakcja człowiek-maszyna zarządzana przez interfejsy dotykowe i rzeczywistość rozszerzoną (AR) oraz konwersję cyfrowo-fizyczną, w której pojawia się zaawansowana robotyka i druk 3D . Tymczasem sektor energetyczny musi skoncentrować się na nadchodzących technologiach energetycznych, standaryzacji technologii wysokiego poziomu i szybkich prędkości z fuzją i konwergencją technologii informacyjno-komunikacyjnych (ICT), inteligentnymi i inteligentnymi sieciami energetycznymi, systemami magazynowania energii, dużymi danymi, sztuczną inteligencją i cyberbezpieczeństwo. Sektor energetyczny jest infrastrukturą krytyczną. Dlatego niezbędne jest zapewnienie sprawnego i ciągłego zasilania.
Szerokie zastosowanie nowych i zaawansowanych technologii wymaga inteligentnego systemu integracji, który można osiągnąć tylko wtedy, gdy odpowiednie technologie, interfejsy, ramy i formaty są zgodne z ogólnie przyjętymi standardami. Warunkiem interoperacyjności w środowisku Przemysłu 4.0 są międzynarodowe i akceptowane normy i standardy. Dlatego Przemysł 4.0 i standaryzacja muszą iść w parze.
Przemysł 4.0 wiąże się z globalną transformacją gospodarczą. Dlatego też krajowe działania normalizacyjne muszą być zharmonizowane z poziomem międzynarodowym, aby skoncentrować się na określeniu mechanizmów współpracy międzynarodowej i współpracy oraz wymiany informacji. Skupienie się na Przemyśle 4.0 wymaga skoordynowanych i skoordynowanych działań wszystkich odpowiednich interesariuszy oraz ministerstw i agencji rządowych, aby poprowadzić krajową transformację do Przemysłu 4.0 poprzez finansowanie i zachęty, talenty i kapitał ludzki, technologię i standardy oraz infrastrukturę cyfrową i ekosystem.
Technologiczny wpływ Przemysłu 4.0
Zbliżające się pojawienie się technologii bezprzewodowej 5G lub piątej generacji oferuje błyskawiczną prędkość, wyjątkowo niezawodne połączenia, niskie opóźnienia i jednocześnie umożliwia ogromną łączność. Oczekuje się, że sieci 5G doładują ekosystem IoT, zapewniając infrastrukturę sieciową niezbędną do przenoszenia ogromnej ilości danych i zaspokajając potrzeby komunikacyjne miliardów urządzeń podłączonych do IoT. Ta bezprzewodowa technologia otwiera szereg nowych możliwości, takich jak robotyka i systemy autonomiczne, technologie chmurowe, zdalna chirurgia i zdalne aplikacje medyczne, AR i pojazdy autonomiczne. Komitet techniczny (TC) 106 Międzynarodowej Komisji Elektrotechnicznej (IEC) otrzymał zadanie opracowania standardów testowania bezpieczeństwa dla urządzeń mobilnych, stacji bazowych i systemów komunikacji bezprzewodowej w celu wsparcia wdrażania i rozwoju sieci 5G. IoT to system powiązanych ze sobą urządzeń komputerowych, maszyn mechanicznych i cyfrowych, obiektów osadzonych w czujnikach, oprogramowania i technologii w celu łączenia i wymiany danych z innymi urządzeniami i systemami przez Internet. Te urządzenia połączone z Internetem Rzeczy obejmują zarówno przedmioty gospodarstwa domowego, takie jak urządzenia kuchenne i elektroniczne nianie, jak i zaawansowane narzędzia przemysłowe, takie jak inteligentne sieci energetyczne, inteligentna produkcja, połączona i inteligentna logistyka oraz konserwacja zapobiegawcza i predykcyjna. Firmy będą wdrażać tysiące lub miliony przewodowych i bezprzewodowych czujników, które wytwarzają duże ilości nieprzetworzonych danych, które są przekształcane w przydatne informacje zapewniające wartość dla użytkownika. Według IEC, roli IEC w IoT, szacuje się, że do 2020 r. zostanie połączonych 50 miliardów obiektów. ISO/IEC JTC 1/SC 41 zapewnia standaryzację w obszarze IoT i powiązanych technologii, w tym sieci czujników i technologii ubieralnych aby zapewnić, że połączone systemy są płynne, bezpieczne i odporne. Robotyka i systemy autonomiczne to obszary, które stale rozwijają się w branży rynkowej na całym świecie. Ze względu na nieograniczone możliwości przechowywania informacji, wraz z wdrażaniem sztucznej inteligencji i ulepszonymi interakcjami człowiek-komputer, robotyka i systemy autonomiczne są odczuwalne we wszystkich dziedzinach i mają niezliczone zastosowania. Technologie chmury są częścią czynnika umożliwiającego przełomowe innowacje, które integrują usługi i demokratyzują dostęp do informacji, uczenia się i komunikacji. Big data i analityka zostały uznane na całym świecie za towary cenniejsze niż ropa, ponieważ dane królują w dzisiejszej gospodarce cyfrowej. Dzisiejsze możliwości gromadzenia i przechowywania ogromnej ilości danych, szybsze i inteligentniejsze analizowanie danych, big data i analityka umożliwiają przekształcenie danych historycznych i danych czasu rzeczywistego w cenne informacje umożliwiające zrozumienie, produkcję, sprzedaż, przewidywanie i tak dalej. AR to integracja informacji cyfrowych ze środowiskiem użytkownika w czasie rzeczywistym, zapewniając interaktywne, oparte na rzeczywistości środowisko wyświetlania, które tworzy pomost między wirtualną rzeczywistością a danymi. Zastosowania AR są nieograniczone. Branże przyjmują technologie AR, aby umożliwić wirtualną produkcję, w której inżynierowie mogą projektować i oceniać nowe części do zastosowań przemysłowych w środowisku 3D; specjalistyczne i rozszerzone szkolenia i symulacje; inteligentne funkcje sterowania i konserwacji oraz wiele innych. Blockchain to zdecentralizowana baza danych, która jest zaszyfrowana, niezmienna, obopólna, weryfikowalna, przejrzysta i trwała. Istnieje niezliczona ilość potencjalnych zastosowań technologii blockchain, a jednym z nich jest "Bitcoin". W branży logistycznej blockchain jest używany do ustanawiania zaufanych informacji, takich jak: gdzie produkt został wyprodukowany, kiedy produkt został wyprodukowany, kiedy produkt został wysłany, gdzie produkt się znajduje i kiedy produkt dotrze. Technologia Blockchain została również wdrożona w sektorze energetycznym, takim jak handel energią odnawialną (RE) typu peer-to-peer (P2P) oraz infrastruktura ładowania pojazdów elektrycznych. Grupa robocza ISO/IEC JTC 1/SC 27 (WG) nadzoruje standardy rozwoju technologii blockchain i rozproszonej księgi rachunkowej. Główne filary lub napędy technologiczne Przemysłu 4.0 obejmują autonomię i sztuczną inteligencję, w których procesy produkcyjne lub produkcyjne będą coraz bardziej zdigitalizowane i połączone ze sobą cyberfizycznymi systemami. Uznanie branży i szerokie zastosowanie sztucznej inteligencji i automatyzacji na nowo zdefiniują sposób działania firm i branż. W związku z tym oczekuje się, że sztuczna inteligencja będzie jednym z najważniejszych czynników wspomagających i cyfrowej granicy w ewolucji technologii informacyjnej (IT). AI to nie tylko pojedyncza technologia, ale także różnorodne technologie oprogramowania i sprzętu wykorzystywane w aplikacjach. Sztuczna inteligencja jest ogólnie rozumiana jako odnosząca się do maszyny, która ma zdolność replikowania ludzkich funkcji poznawczych w celu uczenia się i rozwiązywania problemów. Komponenty sztucznej inteligencji, takie jak sieci neuronowe, przetwarzanie języka naturalnego, biometria, rozpoznawanie twarzy, rozpoznawanie gestów, miniboty i analityka wideo umożliwiają cyfrową transformację. Niedawny artykuł Forbesa "Sztuczna inteligencja pokona szum szumu oszałamiającym wzrostem" sugeruje, że inwestycje w sztuczną inteligencję rosną bardzo szybko. Firma ze Stamford w stanie Connecticut stwierdziła, że wdrożenia sztucznej inteligencji wzrosły o 37% w 2018 r. i 270% w ciągu ostatnich 4 lat. IDC Corp., międzynarodowa firma inwestycyjna, prognozuje, że wydatki na systemy kognitywne i sztucznej inteligencji wyniosą 77,6 mld USD do 2022 r. i zauważa, że 60% światowego PKB powinno zostać zdigitalizowane do 2022 r., co przyniesie prawie 7 bilionów USD wydatków na IT. Obecnie wszystkie sektory w dużym stopniu polegają na sztucznej inteligencji, od finansów, produkcji i robotyki po opiekę zdrowotną, transport, sprzęt AGD, a nawet smartfony, które nosimy wszędzie! Sztuczna inteligencja ewoluuje i rozszerza się znacznie szybciej, niż kiedykolwiek sobie wyobrażaliśmy. Dlatego ważne jest, aby standaryzacja technologii sztucznej inteligencji była potrzebna do osiągnięcia i przyspieszenia globalnego przyjęcia i transformacji cyfrowej.
Jakie decyzje moralne powinny być wykonane przez sztuczną inteligencję w autonomicznych samochodach w sytuacjach życia i śmierci? Na przykład, jeśli nagle zawodzą hamulce, czy samochód powinien skręcić w lewo i prawdopodobnie spowodować śmierć jednego człowieka, czy też powinien skręcić w prawo i spowodować obrażenia u 20 osób? Systemy sztucznej inteligencji muszą być przejrzyste, aby umożliwić użytkownikom zrozumienie, w jaki sposób podejmowane są decyzje związane z SI. Kluczowymi barierami we wdrażaniu sztucznej inteligencji są wiarygodność i względy etyczne systemu, ponieważ ludzie ufają maszynom. Ekosystem sztucznej inteligencji można podzielić na trzy kluczowe obszary obejmujące względy techniczne, społeczne i etyczne. Kwestia techniczna obejmuje podstawowe standardy i metody obliczeniowe, techniki, architektury i charakterystyki systemów sztucznej inteligencji. Względy społeczne i etyczne dotyczą tego, w jaki sposób przyjęcie sztucznej inteligencji wpływa i wpływa na życie ludzkie na siłę roboczą, prywatność, podsłuchiwanie, stronniczość algorytmiczną i bezpieczeństwo. IEC rozpoczęła opracowywanie norm inteligentnej produkcji z Międzynarodową Organizacją Normalizacyjną (ISO), takich jak udział wspólnego komitetu technicznego, ISO/IEC JTC 1 - środowisko opracowywania norm dla ICT w celu utworzenia grup roboczych w celu zbadania harmonizacji istniejących odniesień modeli i nadzoruje rozwój podstawowej architektury dla inteligentnej produkcji. Wspólny komitet techniczny IEC i ISO ds. sztucznej inteligencji, ISO/IEC JTC 1/SC 42, został powołany w celu opracowania międzynarodowych standardów obejmujących obszary obejmujące sztuczną inteligencję, duże zbiory danych, przypadki użycia, implikacje zarządzania, podejścia obliczeniowe sztucznej inteligencji oraz kwestie etyczne i społeczne. obawy. Grupy oceny standaryzacji IEC (SEG) są tworzone w celu identyfikacji nowych obszarów technicznych i przewidywania pojawiających się rynków lub technologii, takich jak inteligentna produkcja, technologie komunikacyjne i inteligentne systemy domu/biura. IEC SEG 10 - Etyka w zastosowaniach autonomicznych i sztucznej inteligencji - ma na celu ocenę prac obejmujących szeroki obszar nowych technologii w celu identyfikacji problemów etycznych i problemów społecznych w całej swojej pracy oraz współpracy z szerszymi komisjami technicznymi w ramach IEC opracowanie szeroko stosowanych wytycznych dla komitetów IEC dotyczących aspektów etycznych związanych z zastosowaniami autonomicznymi i sztuczną inteligencją. Stowarzyszenie Normalizacyjne Instytutu Inżynierów Elektryków i Elektroników (IEEE) (SA) pracowało nad projektami, które koncentrują się na dobrostanie człowieka w tworzeniu autonomicznych i inteligentnych technologii. IEEE-SA wydało wytyczne etyczne dla automatyzacji i inteligentnych systemów, zatytułowane "Ethically Aligned Design (EAD)". Niniejsze wytyczne skupiają się na ogólnych zasadach i zaleceniach dotyczących etycznego wdrażania autonomicznych i inteligentnych systemów, które są ujęte w ośmiu ogólnych zasadach: prawa człowieka, dobrostan, agencja danych, skuteczność, przejrzystość, odpowiedzialność, świadomość nadużyć i kompetencje. Sztuczna inteligencja pomaga usprawnić wydajność firm zajmujących się inteligentną produkcją, ponieważ może zapewnić wgląd w to, gdzie można wprowadzić ulepszenia i, co ważniejsze, gdzie firmy mogą pójść dalej w zakresie planowania produkcji. Standaryzacja ma kluczowe znaczenie dla Przemysłu 4.0, który wymaga bezprecedensowego stopnia integracji systemu ponad granicami domen, granicami hierarchicznymi i fazami cyklu życia. Międzynarodowe organizacje zajmujące się opracowywaniem standardów odgrywają kluczową rolę w przejściu na Przemysł 4.0. Centra danych są podstawą Przemysłu 4.0, ponieważ torują drogę aplikacjom Przemysłu 4.0. Ponieważ przetwarzanie w chmurze i ekosystemy wciąż stają się jedną z kluczowych strategii cyfrowej transformacji, hiperskalowe centra danych zwiększają swoją pojemność, aby sprostać wykładniczemu wzrostowi ilości danych. Centra danych są obecnie domem dla silników AI, rozległych ekosystemów chmurowych, technologii blockchain, zaawansowanych architektur łączności, wysokowydajnych platform obliczeniowych i wielu innych. ISO/IEC JTC 1/SC 38 służy jako jednostka skupiająca, proponująca i integrująca systemy w chmurze obliczeniowej i platformach rozproszonych. Aby przygotować się na kolejną granicę transformacji cyfrowej, centra danych muszą wdrożyć zaawansowaną infrastrukturę sieciową, aby ich sieci były szybsze, bardziej elastyczne, solidniejsze i bardziej niezawodne oraz bardziej odporne i bezpieczne. Centra danych o dużej skali są dużymi konsumentami energii elektrycznej. Niezbędne jest uczynienie centrów danych bardziej energooszczędnymi i mniej energochłonnymi, aby walczyć z rosnącą globalną emisją dwutlenku węgla. Norma ISO/IEC JTC 1/SC 39 została ustanowiona w celu opracowania nowej metryki, która mierzy i porównuje wydajność energetyczną i trwałość centrów danych. Aby to uchwycić, globalna standaryzacja wnosi istotny wkład w zapewnienie płynnej ekspansji transformacji cyfrowej i Przemysłu 4.0 oraz umożliwia łączenie i współdziałanie systemów różnych producentów bez potrzeby specjalnych wysiłków integracyjnych, a także łagodzenie zmian klimatycznych i ograniczanie globalnego poziomu emisji dwutlenku węgla. emisji, które są zgodne z celami zrównoważonego rozwoju Organizacji Narodów Zjednoczonych (ONZ)
Przemysł 4.0 i zrównoważony rozwój
Państwa członkowskie ONZ przyjęły agendę 2030 na rzecz zrównoważonego rozwoju, która stanowi wspólny plan dla pokoju i dobrobytu, obejmujący 17 celów zrównoważonego rozwoju, w ramach których wszystkie kraje rozwinięte i rozwijające się będą współpracować ze strategiami na rzecz poprawy zdrowia i edukacji, pobudzenia wzrostu gospodarczego, zmniejszenia nierówności , przeciwdziałanie zmianom klimatu i ochrona naszego środowiska.Badanie przeprowadzone przez Organizację Narodów Zjednoczonych ds. Rozwoju Przemysłowego (UNIDO) i partnerów wykazało, że Przemysł 4.0 może sprostać globalnym wyzwaniom dzięki zwiększonemu wykorzystaniu technologii informacyjnych i komunikacyjnych, ale ostrzega, że jego ograniczenia i zagrożenia dla zrównoważonego rozwoju muszą być lepiej zrozumiane. Zasada przewodnia Przemysłu 4.0 koncentruje się na zwiększeniu wydajności, wzrostu przychodów i konkurencyjności oraz musi przezwyciężyć wyzwania związane ze standaryzacją systemów, platform, protokołów, zmianami w organizacji pracy, cyberbezpieczeństwem, dostępnością i jakością wykwalifikowanych pracowników, badaniami i inwestycjami oraz przyjęciem odpowiednich ram prawnych, aby odnieść sukces. Przemysł 4.0 musi radzić sobie z produkcją w ramach ograniczeń środowiskowych, aby napędzać zrównoważony rozwój. Tempo eksploatacji zasobów naturalnych nie może przekraczać tempa regeneracji; wyczerpywanie się zasobów nieodnawialnych musi wymagać porównywalnych alternatyw i tak dalej. Rosnący trend zapotrzebowania na energię wynikający z postępu transformacji cyfrowej wymaga pilnego przyjęcia niskoemisyjnych systemów energetycznych. SDG 7 promuje niedrogą i czystą energię. Energia odnawialna i efektywność energetyczna to dwa główne elementy systemów zrównoważonej energii. SDG 7 ma na celu zwiększenie udziału odnawialnych źródeł energii w globalnym miksie energetycznym i znaczne podwojenie globalnego tempa poprawy efektywności energetycznej. Połączenie Przemysłu 4.0 i zrównoważonej energii kierowanej przez cele zrównoważonego rozwoju poprzez transformację sektora energetycznego z transformacją cyfrową znacząco zmieni sposób, w jaki ludzie żyją, konsumują, produkują i handlują. Rozwój technologii ICT, sieci 5G i technologii blockchain otwiera nowe możliwości i zapewnia rozwiązania integrujące odnawialne źródła energii, od wiatru po energię słoneczną, do małych i dużych sieci energetycznych. Technologie cyfrowe zapewniają możliwość monitorowania i efektywnego zarządzania wytwarzaniem, dostawą i zużyciem energii w celu zaspokojenia różnych wymagań użytkowników końcowych. Przemysł 4.0 ma również możliwość wspomagania sektora produkcyjnego w oszczędzaniu energii poprzez przekształcanie procesów biznesowych. Niektóre z podejść, takie jak magazynowanie energii, oferują korzyści związane z bezpieczeństwem dostaw, elastycznością sieci i redukcją obciążeń szczytowych oraz optymalizacją określonej technologii, w której zachowanie dużej liczby połączonych ze sobą robotów jest kontrolowane przez algorytm w celu zmniejszenia ich zużycia energii. Cel zrównoważonego rozwoju nr 9 promuje przemysł, innowacje i infrastrukturę poprzez budowanie silnej infrastruktury, promowanie inkluzywnej i zrównoważonej industrializacji oraz wspieranie innowacji. Wdrożenie technologii 5G i rozwój Internetu Rzeczy pobudzą wzrost inwestycji w infrastrukturę ICT i pojawienie się nowych innowacyjnych podejść. Strategiczna polityka przemysłowa zapewnia podstawową infrastrukturę niezbędną do wspierania innowacji. Bezrobocie jest również najczęściej omawianym zagrożeniem, ponieważ coraz powszechniejsze stosowanie robotyki i systemów automatyzacji zastępuje miejsca pracy, które w przeszłości były motorem produkcji. Jednak to samo portfolio technologii oferuje również możliwość tworzenia nowych miejsc pracy dla wykwalifikowanych pracowników, a integracja inteligencji w maszynach produkcyjnych przyczynia się do zrównoważonego uprzemysłowienia. Przyjęcie Przemysłu 4.0 wymaga od nas przezwyciężenia nie tylko barier technologicznych, ale także, co ważniejsze, barier psychologiczno-ludzkich, które określają sposoby, w jakie ludzie wchodzą w interakcje i wykorzystują te technologie cyfrowe. Obecnie technologie cyfrowe są coraz bardziej humanizowane wraz z dojrzewaniem takich elementów, jak rzeczywistość wirtualna i rzeczywistość rozszerzona. W związku z tym firmy muszą zintensyfikować swoje wysiłki związane z transformacją cyfrową poprzez podejście skoncentrowane na człowieku, aby przejść do pomyślnego wdrożenia.
Rewolucja przemysłowa 4.0 - big data i analityka big data dla inteligentnej produkcji
Inteligentna produkcja i system cyber-fizyczny
Producenci na całym świecie konkurują na globalnym i dynamicznym rynku wymagającym produktów o najwyższej jakości i najniższej cenie. Pod dalszym wpływem czasu do wprowadzenia na rynek i innowacyjności, procesy produkcyjne były stopniowo przesuwane w kierunku swoich granic granicznych, a wywołując znaczną niepewność produkcji, jeśli nie jest kontrolowana, może skutkować katastrofalną awarią. Ten scenariusz wskazuje na znaczenie dostosowania inteligentnych rozwiązań w produkcji w celu efektywnego i wydajnego zarządzania zasobami, zmniejszenia niepewności produkcji, aby zachować konkurencyjność i utrzymać rentowne marże zarówno lokalnie, jak i globalnie. Przemysł 4.0 (I4.0) obejmuje różne technologie, ale koncentruje się na wysoce zautomatyzowanych, zdigitalizowanych procesach produkcyjnych i zaawansowanej technologii komunikacji informacyjnej. I4.0 jest zakorzeniony w koncepcji smartmanufacturing (SM), inteligentnej koncepcji produkcji, w której linie produkcyjne mogą samooptymalizować się i dostosowywać w odpowiedzi na zmieniające się procesy i warunki produkcyjne. SM ułatwia wysoką elastyczność produkcji i zdolność do wytwarzania produktów o większej złożoności i dostosowywania na dużą skalę, podniesienia jakości produktu i osiągnięcia lepszego zużycia zasobów. SM można zdefiniować jako nowy poziom modelu produkcyjnego z kombinacją różnych technologii w celu zintegrowania możliwości cyberfizycznych umożliwiających gromadzenie ogromnych danych z wielu źródeł w połączonym sieciowo środowisku współdzielenia zasobów, wykorzystującym zaawansowane techniki analityczne do opracowywania strategicznych informacji dla systemu doskonalenie i podejmowanie decyzji w celu zwiększenia elastyczności produkcji i zdolności adaptacyjnych. Jest to wzmocnione i wszechobecne zastosowanie sieciowych technologii informatycznych w całej domenie produkcyjnej w celu osiągnięcia optymalnych zdolności produkcyjnych. SM wymaga kilku podstawowych technologii do nawiązania komunikacji różnych podmiotów w obszarze produkcyjnym. Komunikacja i wymiana informacji pozwalają na zmianę zachowania każdego obiektu i adaptację do różnych sytuacji w oparciu o sygnały wytworzone przez przeszłe doświadczenia i zdolności uczenia się wzmocnione przez te technologie, które były dla nich sprzężeniem zwrotnym. Wpływ ten prowadzi do ustanowienia systemów komunikacyjnych między człowiekiem a człowiekiem i człowiekiem z maszynami, znanych jako system cyber-fizyczny (CPS). CPS to koncepcja wywodząca się z funkcjonalności systemów, które umożliwiają dostęp i interoperacyjność człowiek-maszyna. Shafiq i inni stwierdzają, że CPS jest ustanowieniem globalnej sieci wszystkich podmiotów produkcyjnych, od maszyn produkcyjnych po procesy i zarządzanie łańcuchem dostaw (SCM) z konwergencją świata fizycznego i cyfrowego. Monostori i inni stwierdzają, że CPS są podmiotami zdolnymi do współpracy obliczeniowej z otaczającym światem fizycznym poprzez rozległe połączenie, w ciągłej formie dostarczania i wykorzystywania, a także jednoczesnego dostępu i przetwarzania danych z usług dostępnych w sieci. Lee i inni przedstawił dokładny opis CPS w architekturze 5C podsumowujący podstawowe poziomy projektowe CPS: (1) Połączenie, (2) Konwersja, (3) Cyber, (4) Poznanie i (5) Konfiguracja. Poziom połączenia służy jako interfejs między środowiskiem fizycznym a obliczeniowym światem cybernetycznym. Do gromadzenia informacji wykorzystano różne media komunikacyjne, takie jak czujniki, siłowniki, terminale systemów wbudowanych i sieć bezprzewodowa do wymiany danych. Aby dostosować się do różnych typów akwizycji danych, potrzebny jest odpowiedni protokół i konstrukcja urządzenia. Poziom konwersji pełni funkcję agenta przetwarzania danych, który przekształca zebrane dane w użyteczne informacje specyficzne dla każdego procesu w celu podjęcia odpowiednich działań w celu poprawy wydajności. Ponieważ dane z każdego z podmiotów reprezentują jego stan, opracowane informacje mogą służyć jako monitor samoświadomości maszyny. Poziom cyber pełni centralną rolę w tej architekturze. Zbiera wszystkie dane ze wszystkich komponentów w systemach i tworzy cybersymbole właściwości fizycznych. Replikacja tych symboli umożliwia budowanie rosnącej bazy wiedzy dla każdej maszyny lub podsystemów. Właściwe wykorzystanie bazy wiedzy stworzonej do działań doskonalących system może dać bardziej wiarygodne i efektywne rezultaty. Poziom poznania działa jak mózg architektury. Symulacja i synteza wszystkich dostępnych informacji zapewnia dogłębną wiedzę o systemach. Uzyskane w ten sposób wnioski i wyniki mogą być następnie wykorzystywane przez ekspertów do wspierania metod podejmowania decyzji i rozumowania. Ostatnim poziomem jest poziom konfiguracji, elastyczny system sterowania łączący polecenia, sugestie lub decyzje opracowane do realizacji w systemach fizycznych. Dynamiczna wymiana informacji w czasie rzeczywistym pomiędzy zintegrowanym systemem CPS umożliwia komunikację pionową i poziomą w celu podejmowania trafnych decyzji biznesowych, współpracy wielostronnej, wydajnego i efektywnego ulepszania i konserwacji systemu w obrębie całej domeny SM. Ogólnie rzecz biorąc, w kontekście SM, CPS ustanowiło innowacyjne podejście do integracji funkcjonalności systemów automatyki przemysłowej wszystkich podmiotów w domenie systemu produkcyjnego poprzez połączenie sieciowe z całą otaczającą rzeczywistością fizyczną, umożliwiając współpracę obliczeniową i infrastrukturę komunikacyjną w celu zapewnienia interoperacyjności. Systemy są połączone w rozproszonej strukturze modułowej, w przeciwieństwie do połączenia jednokierunkowego w konwencjonalnych zakładach produkcyjnych, co pozwala na interakcję danych z wielu źródeł i integrację wiedzy w sieciach. Zapewnia to całkowitą widoczność i kontrolę nad procesami produkcyjnymi, umożliwiając szybkie rozwiązywanie problemów i podejmowanie decyzji. Informacje są dostępne i przepływają w dowolnym miejscu i czasie we wszystkich obszarach procesów produkcyjnych. Chociaż CPS ustanowił model komunikacji między systemem fizycznym a światem cybernetycznym, to połączenie kilku podstawowych technologii ożywia system SM. Na przykład Internet rzeczy (IoT) umożliwia podłączenie wszystkich fizycznych urządzeń lub sprzętu do scentralizowanej platformy w celu gromadzenia i wymiany danych. Big data (BD) produkowane przez każdy z podmiotów zawiera bezcenne informacje o domenie, które następnie są analizowane za pomocą zaawansowanych technik analityki BD (BDA). Jak wyjaśniono wcześniej, wynik analizy tworzy sygnały, które mają być informacją zwrotną dla systemów w celu dostosowania. Przetwarzanie w chmurze (CC) pozwala na dostęp do informacji i sygnału przez każdą ze stron w systemie SM w czasie rzeczywistym, w dowolnej części świata, o ile jest ona podłączona do sieci. Ostatecznie każda z technologii bazowych wspólnie tworzy podstawową architekturę SM. W niniejszym omówieniu skupimy się na wyjaśnieniu BD i BDA, a następnie na studium przypadku dotyczącym propozycji BDA do pomiaru optycznego w produkcji ogniw słonecznych.
Przegląd dużych zbiorów danych
Cyfryzacja procesów produkcyjnych umożliwiła połączenie różnych urządzeń i podprocesów w zakładach produkcyjnych w dużą platformę cyfrową. Powszechna integracja technologii informacyjno-komunikacyjnych generuje ogromną pojemność heterogenicznych danych pochodzących z różnych obiektów w domenie. Ta ogromna ilość ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych danych jest znana jako BD. Rozważając pozyskanie danych korespondencyjnych, ze względu na ich ogromną pojemność, uzyskanie, przechowywanie i analizowanie tych danych jest dużym wyzwaniem zarówno pod względem czasu, jak i pieniędzy. W związku z tym wykorzystanie nowatorskich technologii z dzisiejszej ery Internetu ma kluczowe znaczenie dla zapewnienia wartości dla przemysłu. Liczne publikacje dotyczące składników i definicji BD oraz opis szybko ewoluowały i do pewnego stopnia wywołały pewne zamieszanie. BD często rozumie przez wielu, w zależności od objętości i rozmiaru danych. Chociaż ilość i rozmiar danych są nieuchronnie niezbędne, nie jest to jednak jedyny kluczowy aspekt. Zarówno Cemernek i inni jak Gandomi i Haider stwierdzili dwie wersje definicji BD, które najdokładniej opisują BD, zebrane najpierw z definicji przez TechAmerica Foundation:
Big data to termin, który opisuje duże ilości złożonych i zmiennych danych o dużej prędkości, które wymagają zaawansowanych technik i technologii umożliwiających przechwytywanie, przechowywanie, dystrybucję, zarządzanie i analizę informacji.
Inna bardziej powszechna definicja, dostosowana do I4.0 przez Gartner IT Group, jest następująca:
Big data to zasoby informacyjne o dużej objętości, dużej szybkości i dużej różnorodności, które wymagają opłacalnych, innowacyjnych form przetwarzania informacji w celu lepszego wglądu i podejmowania decyzji.
Z obu definicji wyraźnie wynika, że BD zawiera kilka cech ze standardowymi wspólnymi cechami Objętości (Volume) , Różnorodności (Variety) i Prędkości (Velocity), znanych jako trzy V. V są opisane poniżej. Objętość odnosi się do rozmiaru i skali danych. Rozmiary dysków BD zwykle mieszczą się w zakresie wielu terabajtów i petabajtów. Nie było określonego progu pojemności dla klasyfikacji objętości BD. Jest względna i zależy od różnych czynników, takich jak typ danych, technologia kompresji danych, zarządzanie danymi i pojemność pamięci. Na przykład zwiększenie pojemności pamięci zwiększy próg charakterystyki objętości BD, umożliwiając przechowywanie większej ilości danych. Oprócz technologii kompresji danych w celu zmniejszenia rozmiaru danych bez utraty informacji, różne typy danych, takie jak dane tekstowe w stosunku do danych wideo, które mają różną gęstość danych, oraz technologia zarządzania danymi do manipulowania danymi, są możliwymi czynnikami zmiany definicji objętości, ponieważ 'duża'. Różnorodność odnosi się do różnorodności struktury danych i wielowymiarowości zawartości danych. Dane BD istnieją w trzech kategoriach: (1) Dane strukturalne - ten typ danych znajduje się w stałych polach w ramach predefiniowanych ram wejściowych lub modelu danych, takich jak rekord w relacyjnej bazie danych i wpis w arkuszach kalkulacyjnych. Nie wymaga stosowania wstępnego przetwarzania lub wstępnego kondycjonowania danych do jednoznacznej interpretacji lub analizy w celu uzyskania znaczących informacji. (2) Dane nieustrukturyzowane - rodzaj niezorganizowanego, niespójnego formatu, który nie jest zgodny z żadnym wstępnie zdefiniowanym modelem danych ani sposobem. Dane mają zazwyczaj dużą zawartość tekstową i graficzną, często nie nadają się do analizy bez wstępnego przetworzenia lub wstępnego kondycjonowania w celu spełnienia wymagań organizacji strukturalnych technik analitycznych. Dane obrazu, dźwięku i obrazu to przykład danych nieustrukturyzowanych. (3) Dane częściowo ustrukturyzowane - typ danych, który nie jest ściśle zgodny z żadnym formalnym standardem danych, ale zawiera określone identyfikatory umożliwiające rozróżnienie między elementami semantycznymi a elementem instruktażowym w danych. Przykładem danych częściowo ustrukturyzowanych jest język Hypertext Markup Language, w którym informacje o przetwarzaniu zostały zawarte w znacznikach zdefiniowanych przez użytkownika, co umożliwia ich interpretację przez przeglądarkę w celu uzyskania informacji wyjściowych. Prędkość to szybkość generowania danych i szybkość przetwarzania danych w celu uzyskania praktycznych wyników mierzonych częstotliwością. Szybkość generowania danych jest ściśle powiązana z konstrukcją i rozmieszczeniem systemów produkcyjnych. Kiedy cykl produkcyjny czas jest krótki, generowanie danych będzie szybsze i na odwrót. W obu przypadkach CPS kontroluje generowanie danych i ruch. Dlatego projekt CPS powinien mieć odpowiednią zdolność do obsługi scenariusza. Rozprzestrzenianie się urządzeń cyfrowych przyczyniło się do szybkości danych zarówno podczas generowania, jak i przetwarzania. Urządzenia połączone pojedynczo lub grupowo przetwarzały dalej informacje produkcyjne udostępniane na maszynach; pozwala to na uzyskanie bardziej odpowiednich i dogłębnych informacji o konkretnym zadaniu lub scenariuszu, umożliwienie kolejnych działań w zakresie analizy w czasie rzeczywistym i planowania opartego na dowodach. Wielopoziomowe generowanie i przesyłanie nowych danych między urządzeniami przyspiesza bezprecedensową szybkość tworzenia danych. Tradycyjny system zarządzania danymi nie był w stanie obsłużyć ogromnego strumienia danych natychmiast dzięki tej nowej formie szybkości przesyłania danych. To wprowadza nowe technologie BD na scenę, aby manipulować tymi dużymi ilościami danych w "nietrwały" sposób, aby tworzyć inteligencję w czasie rzeczywistym. Oprócz trzech ogólnych wymiarów BD, kilka kluczowych korporacji rozszerzyło wymiar BD na Wiarygodność (Veracity), zmienność(Variability) i wartość(Value). Każdy z rozszerzonych Vs jest opisany poniżej: Wiarygodność reprezentuje zawodność zawartą w niektórych źródłach danych, znaną również jako jakość danych. IBM to wymyślił. Wiarygodność uznano za najważniejszy czynnik utrudniający szerokie przyjęcie BDA w branży. Niektóre zidentyfikowane obszary wpływające na wiarygodność danych, takie jak dokładność, integralność i niepewność danych, wymagają poprawy, zanim możliwe będzie niezawodne wdrożenie . Na przykład popyt rynkowy na takie produkty, jak luksusowe samochody, w dużej mierze zależy od nastrojów klientów, np. preferencji określonych marek, wcześniejszych doświadczeń i statusu społecznego. Wszystko to wiąże się z osądem człowieka, co powoduje znaczną niepewność. Dane te zawierają jednak cenne informacje o rynku. Ten inny aspekt BD należy rozwiązać za pomocą zaawansowanych technik analitycznych, aby uzyskać konkretne i istotne informacje. Zmienność i złożoność to dwa aspekty BD wprowadzone po raz pierwszy przez SAS. W transmisji danych o dużej objętości i prędkości, przepływ danych często wykazuje charakterystykę okresowych szczytów i rowów. Ta niespójność i zmienność nazywana jest zmiennością. Dostępność danych w dzisiejszej erze cyfryzacji pochodzi z niezliczonych źródeł, wytwarzających dane różnych typów i formatów. To wieloźródłowe generowanie danych jest określane jako złożoność i stanowi krytyczne wyzwanie w aplikacji BDA. Dane muszą być wstępnie przetworzone w celu dopasowania i połączenia w celu przekształcenia w znaczące informacje. Wartość została wprowadzona przez Oracle, definiując wartości w BD zebrane na początku wykazują stosunkowo niski koszt w stosunku do pozyskanego wolumenu, określanego jako "gęstość niskowartościowa". Jednak wartość danych wzrasta, gdy są analizowane w dużej ilości w dalszej części rurociągu, ujawniając początkowo ukryte, ekonomicznie uzasadnione spostrzeżenia i informacje o wysokiej wartości. Innymi słowy, wartość reprezentuje szczegółowe informacje uzyskane dzięki zastosowaniu BDA w oparciu o stale dużą ilość analizowanych danych, gdzie informacje te były niewidoczne na początkowym etapie ze względu na stosunkowo małą ilość danych. Wartość danych to najbardziej krytyczny wymiar BD. Nie było uniwersalnego wzorca 3 V, który charakteryzowałby BD. Objętość jako podstawa BD odnosi się do wszystkich innych wymiarów; różnorodność jest związana z jej wartością i tak dalej. Każdy z wymiarów BD był w taki czy inny sposób zależny od siebie. Próg charakterystyki BD zależy od wielkości, obszaru i lokalizacji wdrożenia, a te ograniczenia ewoluują w czasie. Istnieje podstawa do radzenia sobie z BD, w zależności od charakteru i zdolności każdej domeny produkcyjnej. To właśnie tam tradycyjne systemy i technologie zarządzania danymi nie mogą już generować zadowalającej inteligencji w celu utrzymania wydajności produkcji, kontroli kosztów i konkurencyjności. W takiej sytuacji należy dokonać kompromisu między przyszłymi wartościami oczekiwanymi przez wdrożenie technologii BD a kosztami jej wdrożenia. Potencjalne korzyści, jakie można osiągnąć dzięki wdrożeniu BD, będą w dłuższej perspektywie bardziej korzystne w porównaniu z tradycyjnymi systemami i technologiami. Korzystanie z usług BD zapewni przewagę biznesową dzięki zidentyfikowanym możliwościom o wartości dodanej. Dzięki dokładnym analizom może dać systematyczne wskazówki dotyczące odpowiednich działań produkcyjnych, które należy podjąć zgodnie z zachowaniem systemu. Spośród działań podejmowanych w całym cyklu życia produktu pozwala to na uzyskanie efektywnych kosztowo i bezawaryjnych procesów operacyjnych. Pomaga również powiązanemu personelowi w podejmowaniu właściwych decyzji i rozwiązywaniu problemów związanych z operacjami. Jednym z głównych celów SM jest stworzenie inteligentnego systemu produkcyjnego z dokładnym i terminowym podejmowaniem decyzji dzięki wsparciu danych uzyskanych w czasie rzeczywistym. Niewykluczone, że firma BD będzie kolejnym ważnym wkładem w przyszłą transformację i udoskonalenie SM.
Inteligentna produkcja oparta na danych
SM to nowy paradygmat produkcji, w którym wszystkie podmioty w domenie produkcyjnej są w pełni połączone w takiej czy innej formie z siecią. Połączenia sieciowe obejmują czujniki, siłowniki i systemy wbudowane. Wykorzystując podstawowe technologie, takie jak CPS, IoT i CC, można zbierać dane na wszystkich różnych etapach produkcji. Dzięki zaawansowanym algorytmom obliczeniowym dane te można przekształcić w znaczące informacje i spostrzeżenia dotyczące procesów produkcyjnych, tworząc produkcję opartą na danych, zapewniając inteligencję w kontroli jakości, zwiększanie elastyczności i zdolności adaptacyjnych, obniżanie kosztów i nie tylko. Podejście oparte na danych umożliwia wyprowadzenie złożonego, wielowymiarowego nieliniowego modelu charakterystyki danych dla różnych jednostek w domenie bez konieczności dokładnego zrozumienia zachowania systemu. Modelowanie bezpośrednie zapobiega czasochłonnemu i podatnemu na błędy podejściu ręcznemu. Postęp w technologiach sztucznej inteligencji (AI) dodatkowo uzupełnia przyjęcie BD dla SM opartego na danych. Istotnym czynnikiem umożliwiającym ustalenie produkcji inteligencji są dane. Obecne zaawansowane systemy produkcyjne w erze cyfrowej generują wiele rodzajów danych z ogromną pojemnością. W epoce BD dostępność i możliwość gromadzenia dużej puli danych stały się oczywiste i prostsze. Wraz z nowymi technologiami ICT znacznie poprawiło się również gromadzenie, przetwarzanie i przechowywanie danych. Zakłady produkcyjne mogą teraz skorzystać z tych ulepszeń, aby uzyskać korzyści z wartości danych. Następujące kategorie klasyfikują niejednorodne dane przestrzenne z procesów produkcyjnych i urządzeń:
1. Dane zarządcze z podstawową funkcją związaną z podejmowaniem decyzji zarządczych dotyczących kontroli przedprodukcyjnej, takich jak planowanie finansowe, gospodarka materiałowa, logistyka, planowanie produkcji; w kontroli produkcji, takiej jak przepływ materiałów, przepływ produktów, konserwacja; oraz kontrola poprodukcyjna, taka jak sprzedaż i marketing, logistyka i dystrybucja, wysyłka zamówień i obsługa klienta. Dane są zbierane z informacji produkcyjnych, które zawierają różnorodne dane, takie jak system realizacji produkcji (MES), planowanie zasobów przedsiębiorstwa (ERP), zarządzanie relacjami z klientami, SCM i zarządzanie danymi produktu.
2. Dane dotyczące sprzętu są gromadzone za pośrednictwem CPS, który obejmuje dane dotyczące wydajności w czasie rzeczywistym, warunków pracy i historii konserwacji sprzętu produkcyjnego. Dane pochodzące z maszyny zostały zestawione w scentralizowany system informacyjny, który został zaprojektowany i opracowany zgodnie z zakładem produkcyjnym utworzonym za pośrednictwem szkieletowego kanału komunikacyjnego, takiego jak MES. Te zebrane dane można następnie wykorzystać do przekształcenia w systemy podinformacyjne w celu wyświetlania informacji specyficznych dla zadania lub stanu.
3. Dane użytkownika są zbierane ze źródeł internetowych i służą jako dane wejściowe do specjalnych wymagań produkcyjnych, takich jak lokalizacja klientów, dane demograficzne, profile, historia zamówień, preferencje produktowe i inne. Dane te są generowane głównie z głównych zakładów produkcyjnych na zewnętrznych serwerach, które zawierają informacje o klientach, wykorzystywane głównie do celów marketingowych i informacji zwrotnych. Wraz z rozwojem CPS dane te mogą być dalej wykorzystywane po wstępnym przetworzeniu i filtrowaniu w celu integracji z centralnym systemem planowania produkcji. Planowanie produkcji może następnie dostosować się do najnowszych wymagań rynku i przekazać informacje zwrotne na temat najnowszych wymagań produkcyjnych w procesach produkcyjnych. Ta aplikacja zapewnia wysoką elastyczność produkcji i adaptacyjność.
4. Dane produktowe są zbierane z systemów produktowych i produktowo-usługowych za pośrednictwem internetowej bazy danych klientów, technologii IoT, które wytwarzają i informują w czasie rzeczywistym. Dane odzwierciedlają wydajność produktu, kontekst użytkowania, taki jak obszar i czas, oraz wszelkie inne wskaźniki związane z produktem/usługą, takie jak wilgotność, temperatura i wydajność. Dane te służą jako źródło informacji do uzyskania informacji o produkcie w aktualnym obszarze zastosowania. Dane te dostarczają bezcennych informacji na temat faktycznego wykorzystania produktu do przyszłych udoskonaleń.
5. Dane publiczne są zbierane z systemów rządowych lub otwartych baz danych. Przykładami źródeł informacji są protokoły rządowe, zasady i przepisy, własność intelektualna, rozwój naukowy, demografia, ochrona środowiska, opieka zdrowotna, standardy branżowe i inne. Te powiązane dane rządowe są niezbędne do zagwarantowania ścisłej zgodności procesów produkcyjnych i wytwarzanych produktów ze wszystkimi przepisami.
Cykl życia danych
W środowisku produkcyjnym na pełną skalę różne źródła będą generować różne dane. Surowe dane wyodrębnione w oryginalnym stanie nie są w stanie dostarczyć użytkownikom żadnych przydatnych informacji. Klasyfikacja tych danych musi być przeprowadzona w celu odkrycia wiedzy w celu przekształcenia w treść interpretowaną przez użytkownika w celu wyodrębnienia znaczących informacji (IE). Rozważając BD z perspektywy całego cyklu życia produktu produkcyjnego, przekształcenie surowych danych w użyteczne informacje obejmuje wiele etapów. Cała podróż rozciąga się od generowania danych, gromadzenia, przechowywania, przetwarzania, wizualizacji do ostatecznej aplikacji, znanej jako cykl życia danych. Dane produkcyjne wytworzone w całym cyklu życia danych były wykorzystywane w różnych punktach do sortowania według kryteriów danych. Takie sortowanie może podkreślić jego wartość dla zainteresowania użytkowników, np. jakie dane są potrzebne i gdzie jest to istotne w różnych fazach cyklu życia.
1. Źródła danych: Wcześniej wyjaśniono typowy typ danych produkcyjnych i ich pochodzenie. Zarządzanie i wyposażenie to dwa podstawowe typy danych związanych z produkcją. Podstawowe ramy systemu informacyjnego, takie jak MES, łączą wszystkie wytworzone dane dotyczące zarządzania. Systemy te zostały dostosowane i opracowane zgodnie z wymaganiami zakładu produkcyjnego. Dodatkowe podsystemy zapewniające informacje niższego poziomu ukierunkowane na każdą określoną grupę procesów można również wygenerować poprzez integrację z podstawową strukturą. Dane dotyczące zarządzania są zazwyczaj danymi ustrukturyzowanymi, chociaż forma danych podczas transmisji między systemami do schematu była częściowo ustrukturyzowana. Czujniki sprzętu, siłowniki i systemy wbudowane generują dane o sprzęcie. Typ danych różni się w zależności od projektu systemu i zastosowania i jest nieustrukturyzowany. Większość nowoczesnych urządzeń zgodnych z I4.0 zawiera wewnętrzny interfejs systemowy do wstępnego przetwarzania większości danych sprzętowych do postaci częściowo ustrukturyzowanej przed wysłaniem do szkieletu podstawowego.
2. Zbieranie danych: Do zbierania danych produkcyjnych wykorzystano kilka sposobów ze względu na ich powszechną dostępność w różnych jednostkach danych. CPS pozwala na wprowadzenie użytecznych danych fizycznych do świata cybernetycznego. Gromadzenie danych produkcyjnych lub zarządczych odbywa się za pośrednictwem podstawowych systemów komunikacji i zarządzania informacjami, takich jak MES. Generowanie danych dla poszczególnych podmiotów odbywa się za pośrednictwem standardowego interfejsu protokołu przemysłowego, takiego jak SECS/GEM i jest przesyłane do scentralizowanego serwera MES. Dane te mogą być następnie wykorzystane do dalszych zastosowań w czasie pół rzeczywistym lub w czasie rzeczywistym za pośrednictwem technologii bazodanowych. Dane są głównie częściowo ustrukturyzowanymi i nieustrukturyzowanymi danymi maszynowymi. Okres przechowywania danych zależy od pojemności pamięci serwera. IoT to kolejna forma standardowej technologii gromadzenia danych w SM. Dane dotyczące sprzętu i produktów były zbierane natychmiast w celu monitorowania stanu w czasie rzeczywistym za pomocą czujników, inteligentnych czujników i innych systemów wbudowanych podłączonych do sieci. Od powstającej technologii mobilnej gromadzenie danych było możliwe za pośrednictwem terminali, takich jak komputery PC, telefony komórkowe, tablety i laptopy. Gromadzenie danych w oparciu o IoT to na ogół bezpośrednie zastosowanie danych w skali indywidualnej jednostki. Dane te można następnie wykorzystać do tworzenia konkretnych aplikacji, głównie do monitorowania wydajności systemu za pomocą zestawów programistycznych lub interfejsów programowania aplikacji. Dane użytkowników i publiczne wykorzystywały metodę web scrapingu do gromadzenia danych. Web scraping odnosi się do ekstrakcji danych ze stron internetowych w celu uzyskania pożądanych informacji za pomocą bota lub robotów indeksujących. Jest to zazwyczaj zautomatyzowany proces polegający na przeszukiwaniu i kopiowaniu przeszukiwanych witryn internetowych i gromadzonych w bazie danych w celu późniejszego zastosowania. Web scraping jest zwykle stosowany razem ze sztuczną inteligencją, umożliwiając wydajne zbieranie danych.
3. Przechowywanie danych: Cyfryzacja systemów produkcyjnych generuje ogromne ilości danych. Te dane, od surowego sprzętu we/wy po dane systemu zarządzania, muszą być bezpiecznie przechowywane i integrowane, aby umożliwić dostęp i wykorzystanie do kolejnych działań. Pojemność i szybkość przechowywania to dwa krytyczne czynniki określające żywotność danych, okres przechowywania i funkcjonalność danych. Wydajne i bezpieczne przechowywanie danych ułatwi szybkość i dostępność do wykorzystania. Istnieją trzy standardowe klasyfikacje typów danych: (1) Strukturalne, takie jak liczby, zarządzane ciągi, tabele, którymi można zarządzać bezpośrednio w oparciu o bazę danych. (2) Częściowo ustrukturyzowane, takie jak wykresy i XML. Te typy danych nie są bezpośrednio wyodrębniane w celu uzyskania informacji dla użytkownika końcowego. Funkcjonuje głównie jako pośrednie medium pośredniczące w systemach i oprogramowaniu. (3) Niestrukturalne, takie jak pliki dziennika, audio i obrazy. Dane te wymagają specjalistycznego i zaawansowanego podejścia do przetwarzania i pozyskiwania wymaganych informacji specyficznych dla zadania. Ze względu na charakter bezpośredniego IE dla ustrukturyzowanego typu danych, większość firm skupiła się i zainwestowała w nośnik pamięci i dostępność dla tego typu danych. Nowa technologia pamięci masowej opartej na obiektach otwiera okno na wydajne przechowywanie danych częściowo ustrukturyzowanych i nieustrukturyzowanych. Dane są przechowywane i zarządzane jako obiekt, co zapewnia elastyczność w integracji pamięci masowej i ściąganiu do użytku. Kolejną istotną technologią pamięci masowej jest przechowywanie w chmurze. Ma zastosowanie do wszystkich form struktury danych, przechowywanie w chmurze umożliwia energooszczędne, opłacalne, bezpieczne i elastyczne rozwiązanie pamięci masowej. Dane są przechowywane w wirtualnym miejscu przechowywania i z wieloma możliwościami dostępu w dowolnym miejscu i czasie z połączeniem internetowym przez różne podmioty. Dostawca usług przechowywania w chmurze często oferuje funkcje o wartości dodanej, takie jak automatyczne tworzenie kopii zapasowych, gwarantowany czas pracy i funkcje dostępu do wielu urządzeń. Może też współpracować z systemem dostawcy usług w zakresie funkcji analitycznych danych, takich jak głębokie uczenie się, przetwarzanie danych i inne. Wszystkie te funkcje sprawiły, że przechowywanie w chmurze jest wysoce skalowalnym i udostępnianym trybem przechowywania danych.
4. Przetwarzanie danych: można je nazwać serią działań lub operacji mających na celu ujawnienie przydatnych i ukrytych informacji w dużych ilościach danych do odkrywania wiedzy. Surowe dane w ich naturalnej postaci są zazwyczaj rozproszone, nieczytelne i pozbawione znaczenia. Różne procedury przetwarzania danych są zaangażowane w przekształcanie nieprzetworzonych danych w znaczące informacje. Wyodrębnione informacje są przydatne do prowadzenia działań doskonalących, takich jak kontrola jakości, konserwacja predykcyjna i poprawa wydajności w dziedzinie produkcji. Po pierwsze, czyszczenie danych usuwa zbędne, zduplikowane brakujące wartości i niespójne informacje. Następnie procedura redukcji danych służy do przekształcenia dużych zbiorów danych do uproszczonego, uporządkowanego i kompatybilnego formatu zgodnie z wymaganiami zadania dotyczącymi przetwarzania. Wstępnie przetworzone dane są następnie gotowe do wykorzystania poprzez analizę i eksplorację danych w celu opracowania nowych informacji. Wydajność nowej generacji informacji zależy od analizy i szerokiego zakresu dostępnych technik wydobywczych. Ze względu na dużą ilość danych konwencjonalne techniki statystyczne nie są już najlepszą opcją. Zastępuje je nowoczesne uczenie maszynowe (ML), modele prognozowania obliczeń na dużą skalę i zaawansowane techniki eksploracji danych, takie jak klastrowanie, regresja i wiele innych. Optymalne wykorzystanie BD z atrakcyjnymi analizami danych, dogłębną wiedzą i spostrzeżeniami na temat jednostek produkcyjnych. To napędza osiągnięcie wysokich kompetencji i inteligentnej produkcji.
5. Wizualizacja danych: Prezentacja wyniku przetwarzania danych w bardziej wyraźnej formie, aby ułatwić użytkownikom zrozumienie i interpretację. Dostarczanie informacji jest bardziej efektywne w formie wizualizowanej, takiej jak wykresy, diagramy, figury i wirtualna rzeczywistość. Dane w czasie rzeczywistym można wyobrazić sobie online za pośrednictwem dedykowanych kanałów lub platform użytkowników, umożliwiając natychmiastowe udostępnianie informacji. Ponadto dane statyczne przetworzone na formę wizualną i udostępniane przez każdy podmiot promują bardziej bezpośrednią percepcję, dostępność i przyjazność dla użytkownika. Zaawansowane oprogramowanie analityczne zawiera funkcję tworzenia wizualizacji danych, ułatwiającą zadania użytkownikom.
6. Transmisja danych: Nowoczesna zdigitalizowana SM generuje duże ilości danych, a wygenerowane dane przepływają w sposób ciągły przez różne platformy, takie jak sprzęt, CPS i ludzie, przez różne media w trybie rozproszonym. Transmisja tych danych ma kluczowe znaczenie dla zapewnienia skutecznej komunikacji, udostępniania informacji i interakcji między wszystkimi podmiotami w domenie. Obecne postępy w technologiach komunikacyjnych w znacznym stopniu scentralizowały infrastrukturę bezpiecznej i niezawodnej transmisji w czasie rzeczywistym wszelkiego rodzaju danych. W związku z tym rozproszone zasoby produkcyjne w SM można zunifikować praktycznie w dowolnym miejscu i czasie, aby osiągnąć wysoką elastyczność i kompetencje produkcyjne, zachowując konkurencyjność na rynku globalnym.
7. Aplikacja danych: Dane generowane i istniejące w prawie każdym aspekcie nowoczesnej produkcji. Stał się głównym katalizatorem kontroli trzech najważniejszych kryteriów produkcji, a mianowicie wydajności, jakości i kosztów. W utrzymaniu kompetencji dane mają zastosowanie od początku etapu projektowania produktu do końcowego etapu dostawy. Na etapie projektowania można wykorzystać analitykę danych do uzyskania informacji i zrozumienia produktu, który ma być wytwarzany, takich jak popyt rynkowy, konkurencja oferta i ograniczenia technologiczne. Te spostrzeżenia pozwalają na opracowanie unikalnego i zorientowanego na klienta produktu. Następnie, na etapie produkcji, do optymalizacji produkcji można wykorzystać inną formę danych podmiotów produkcyjnych. Dane o sprzęcie w czasie rzeczywistym są śledzone w celu monitorowania ogólnej efektywności sprzętu. Można je dalej analizować na podstawie danych długoterminowych pod kątem konserwacji predykcyjnej, aby wyeliminować nieplanowane przestoje maszyny, które wpłyną na wydajność i koszty. Dane procesowe są wykorzystywane do kontrolowania każdego etapu produkcji, zapewniając zoptymalizowany proces pod kątem jakości produktu i kontroli kosztów produkcji. Analiza danych procesowych może dostarczyć wczesnych ostrzeżeń o tendencji zmian procesu wpływających na jakość produktu, nienormalnie wysokie wykorzystanie surowców i niską wydajność produktu. Pozwala również na diagnozę pierwotnych przyczyn problemów do usunięcia oraz ograniczenie bieżących procesów do dalszego doskonalenia. Dane operacyjne mogą być wykorzystywane do monitorowania wydajności online, aby natychmiast zwrócić uwagę odpowiedniego sprzętu i personelu procesowego. Dane wyjściowe produkcji można analizować, aby sprostać zapotrzebowaniu rynku i planowaniu produkcji. Na końcowym etapie dostawy przeanalizowano dane produkcyjne, zarządcze i rynkowe w celu określenia optymalnego planowania logistycznego, czasu marketingu, wydajności produkcji i innych elementów SCM. Łącznie, dogłębna analiza danych umożliwia wykonanie działań na wczesnym etapie i działań zapobiegawczych, konserwacji zapobiegawczej i predykcyjnej, przewidywania usterek i usprawnień operacyjnych. Krótko mówiąc, dane napędzają nową, nowoczesną produkcję.
Wartość BD for SM nie zależy wyłącznie od dużej ilości danych. Zdolność do efektywnego wykorzystania danych w celu opracowania znaczących informacji jest kluczem do osiągnięcia optymalnych wyników w SM. Standardowe konwencjonalne technologie dostarczane przez twórców oprogramowania i sprzętu skupiały się głównie na ustrukturyzowanych danych do analizy predykcyjnej, które stanowią jedynie niewielki składnik BD. Przedsięwzięcie w nieustrukturyzowane obszary danych, takie jak audio, wideo i nieustrukturyzowane teksty, było ogólnie ignorowane. Jednak trend ulega zmianie wraz z niedawnym wzrostem sztucznej inteligencji. Ten rosnący trend obserwuje więcej wysiłków badawczych i praktycznych podejść przemysłowych wykorzystujących zaawansowane techniki sztucznej inteligencji, takie jak ML, w celu zebrania nowej wymiarowości i przenikliwości nieustrukturyzowanych danych. W ten sposób jest krytyczne podejście do wykorzystania prawdziwego potencjału BD. Istotne dowody wykazały moc i ulepszenia osiągnięte dzięki podejściom AI do danych nieustrukturyzowanych. W następnej sekcji omówiono dokładniej koncepcje analityczne BD, implementację, techniki eksploracji danych i kilka innych aspektów.
Analiza dużych zbiorów danych
Analityka danych jest uważana za gałąź naukowego i inżynieryjnego podejścia do odkrywania ukrytych wzorców, anonimowych informacji i korelacji w systemach. BDfurther pogłębia zapotrzebowanie na możliwości analityczne dzięki swoim cechom definiującym, które powodują niewystarczalność konwencjonalnego zarządzania danymi i analizami w celu zebrania pełnego potencjału BD dla SMapplications. Ograniczenia w podejściu konwencjonalnym, wraz z postępem w zakresie technologii obliczeniowych, doprowadziły do powstania nowej gałęzi technik analitycznych, znanej jako BDA. BDA zyskało ostatnio dużą popularność i trakcję dzięki postępowi i uogólnieniu sztucznej inteligencji. Możliwość analizowania dużych zbiorów danych będzie jednym z głównych czynników utrzymania konkurencyjności biznesu, wzrostu i innowacyjności . BD w swoim surowym formacie nie ma dużej wartości; bez odpowiedniej analizy gromadzenie wartości w celu przekształcenia informacji w użyteczną wiedzę nie ma sensu. Dobra umiejętność analizy danych może zapewnić znaczący wgląd w procesy, zapewnić kilka istotnych korzyści, takich jak śledzenie w czasie rzeczywistym, konserwacja predykcyjna i wiele innych działań mających na celu poprawę systemów i podejmowanie decyzji przez kierownictwo. Promuje autonomiczną interoperacyjność, elastyczność, poprawę systemu i redukcję kosztów. Zjawisko to powoduje przejście w konwencjonalnym paradygmacie produkcji scentralizowanych aplikacji produkcyjnych na koncepcję rozproszonego klastra SM, kluczową w SM. Przewiduje się, że BDA, które dostarcza inteligencję do procesów produkcyjnych, przyczyni się do znacznej poprawy SM. Proces analityczny służący do wydobywania informacji z różnych źródeł i typów danych w ramach BD można podzielić na pięć klas, a mianowicie analizę tekstu, analizę dźwięku, analizę wideo, analizę społecznościową i analizę predykcyjną. Dwa główne podprocesy zaangażowane w proces analityczny, którymi są zarządzanie danymi i analityka danych
Analiza tekstu
Analiza tekstu jest również znana jako eksploracja tekstu. Odnosi się do technik uzyskiwania informacji z danych opartych na teksturach znakowych i liczbowych. Przykładami danych tekstowych są e-maile, gazety, dokumenty, książki i inne. Dane tekstowe dostępne na każdym poziomie każdej organizacji, a także ludzkiego życia są podstawowym źródłem tworzenia nowej wiedzy. Wydajna i efektywna analiza i interpretacja tych danych ujawni wiele ukrytych informacji, dając ogromne możliwości ulepszeń. Analiza statystyczna, lingwistyka komputerowa i ML to trzy główne dziedziny zaangażowane w analizy danych tekstowych. Wynik tych analiz dostarczy wskazówek, wskazówek i potwierdzeń wspierających podejmowanie decyzji dowodami. Przykładem użytecznej aplikacji do analizy tekstu jest obszar Business Intelligence (BI), wydobywający informacje z wiadomości finansowych w celu przewidywania wyników giełdowych. Analiza tekstu składa się z czterech głównych technik opisanych pokrótce poniżej. IE to technika używana do uzyskiwania uporządkowanych danych z nieustrukturyzowanego tekstu. Algorytm IE został zaprojektowany do rozpoznawania jednostki tekstowej i relacji ze źródła tekstowego, tworząc uporządkowane informacje. Najbardziej typowym przykładem IE jest algorytm aplikacji kalendarza do tworzenia nowego wpisu, w tym istotne informacje, takie jak data i miejsce, automatycznie wyodrębniane z wiadomości e-mail. Dwa podzadania wykonywane w IE to rozpoznawanie jednostek (ER) i wyodrębnianie relacji (RE). ER lokuje i organizuje określoną i wstępnie określoną nazwaną jednostkę, która istnieje w nieustrukturyzowanym tekście, w wyznaczonych kategoriach, takich jak lokalizacja, wartości, nazwy i inne. RE bada i wyodrębnia relacje semantyczne między bytami w tekście. Wyodrębniona relacja występowała zwykle między bytami określonych typów i pogrupowana w określone kategorie semantyczne. Na przykład w "Steven mieszka w Malezji" wyodrębnioną relacją może być Osoba [Steven], Lokalizacja [Malezja]. Podsumowanie tekstu to technika, która automatycznie skraca długie fragmenty tekstów do czytelnego i zwięzłego podsumowania, określającego tylko główne punkty. Przykładami zastosowania są nagłówki wiadomości, streszczenia książek, protokoły ze spotkań i inne - dwa konwencjonalne podejścia stosowane w tej technice, a mianowicie podejście ekstrakcyjne i podejście abstrakcyjne. Wyodrębnianie podsumowania tworzy podsumowanie z oryginalnych jednostek tekstowych, co daje podzbiór oryginalnego dokumentu w skróconym formacie. Ekstrakcyjna technika podsumowania nie "rozumie" tekstu. Podsumowanie zostało sformułowane poprzez określenie wyróżniających się jednostek tekstowych i połączenie ich ze sobą. Wyeksponowanie jednostek zdaniowych ocenia się na podstawie ich częstotliwości występowania i lokalizacji w tekście. W tej technice często stosuje się wyszkolone modele ML, aby filtrować przydatne informacje w tekstach i przedstawiać je w podsumowaniu, przekazując najważniejsze informacje. W przeciwieństwie do tego, streszczenie abstrakcyjne wyodrębnia informacje językowe z tekstu i generuje podsumowanie za pomocą nowych zdań utworzonych przez nowe jednostki tekstu lub przeformułowanie, zamiast destylować krytyczne zdanie. Do przetwarzania tekstów i generowania streszczenia wykorzystywane są zaawansowane techniki przetwarzania języka naturalnego (NLP). Odpowiednio, można tworzyć bardziej spójne podsumowania. Jednak ze względu na ich złożoność i trudniejsze przyjęcie, podsumowania ekstrakcyjne są częściej stosowane w przypadku BDA. Odpowiedzi na pytania (QA) to technika odpowiadania na pytania zadawane w języku naturalnym w zdigitalizowanym systemie. Siri firmy Apple, Alexa firmy Amazon, asystent Google i Cortana firmy Microsoft to tylko niektóre przykłady wybitnych systemów kontroli jakości. Z systemów zapewniania jakości korzystało wiele dziedzin, takich jak opieka zdrowotna, bankowość i edukacja. Inteligencja tych systemów polega na zastosowaniu wyrafinowanych technik NLP. Metody systemu QA można dalej podzielić na trzy podejścia, a mianowicie oparte na wyszukiwaniu informacji (IR), oparte na wiedzy i hybrydowe. System zapewniania jakości oparty na podczerwieni zazwyczaj składa się z trzech podkomponentów. (1) Komponent przetwarzania pytań do identyfikacji szczegółów użytych do skonstruowania zapytania, takich jak przypadek i cel pytań oraz typ odpowiedzi. (2) Element przetwarzania dokumentów do wyszukiwania odpowiednich tekstów wstępnie napisanych z zestawu o dużej objętości istniejących dokumentów, przy użyciu informacji wyszukiwania opracowanych na podstawie zapytania wykonanego w trakcie przetwarzania zapytania. (3) Komponent przetwarzania odpowiedzi do filtrowania odpowiedzi kandydatów wejściowych z komponentu przetwarzania dokumentów. Odpowiedzi są następnie klasyfikowane zgodnie z ich trafnością, a następnie zwracają najwyżej ocenioną odpowiedź jako wynik. Systemy kontroli jakości oparte na IR są powszechnie stosowane w obszarach o ogromnym zbiorze gotowych tekstów, takich jak prawo i edukacja. Oparte na wiedzy systemy zapewniania jakości sprawdzają informacje zawarte w zorganizowanym źródle za pomocą opisu semantycznego opracowanego na podstawie pytań wejściowych. System ten składa się z dwóch głównych komponentów: (1) Bazy wiedzy, która zawiera obszerny zbiór informacji o zaprojektowanym polu, zwykle generowanych na podstawie ludzkich opinii eksperckich, używanych jako źródło odniesienia podczas procesu wnioskowania. (2) Silnik wnioskowania, który funkcjonował w celu wnioskowania osądu na podstawie informacji w bazie wiedzy na podstawie wprowadzonych pytań w celu uzyskania poprawnych odpowiedzi. Systemy zapewniania jakości oparte na wiedzy są przydatne w kontrolowanej domenie ze względu na brak dużej ilości wstępnie napisanego tekstu wejściowego; jego informacje w bazie wiedzy są specjalnie zaprojektowane zgodnie z daną dziedziną. Hybrydowe systemy zapewniania jakości to połączenie obu połówek systemów zapewniania jakości opartych na podczerwieni i wiedzy. Pytania są oceniane semantycznie jak w systemie opartym na wiedzy, natomiast odpowiedzi generowane są w podejściu IR. Analiza nastrojów (eksploracja opinii) to technika analizy obliczeniowej danych tekstowych, które zawierają subiektywne informacje, takie jak opinie i myśli. Analiza polega na identyfikacji, filtrowaniu, uzyskiwaniu i kwantyfikacji analitycznej, przy użyciu NLP, analizy tekstu i technik lingwistyki obliczeniowej na danych dla głosów klientów. Firmy stopniowo angażują się w pozyskiwanie większej ilości danych, aby zrozumieć zachowanie swoich klientów, w szczególności w odniesieniu do ich produktów lub usług. Tylko dzięki zrozumieniu klientów firma może przynosić zyski poprzez sprzedaż produktów lub świadczenie usług spełniających wymagania klientów. Takie zachowanie biznesowe doprowadziło do rozpowszechnienia analizy sentymentu. Ze względu na analityczny charakter danych subiektywnych, analiza sentymentu ma większe zastosowanie w marketingu, naukach politycznych i społecznych. Ale ma również zastosowanie w środowiskach produkcyjnych do analizy wydajności pracowników i informacji zwrotnych. Technika analizy nastrojów jest dalej podzielona na trzy podgrupy: (1) Analiza na poziomie dokumentu opiera się na całym dokumencie pod kątem ogólnej klasyfikacji nastrojów jako pozytywne, neutralne lub negatywne. Zakłada się, że dokument reprezentuje lub opisuje jeden podmiot. (2) Analiza na poziomie zdania jest bardziej złożona w porównaniu z analizą dokumentów. Musi najpierw zidentyfikować pojedyncze zdanie ich subiektywnego i obiektywnego, a następnie określić schizmę sentymentalną nad elementami opisanymi w zdaniu. (3) Analiza aspektowa rozróżnia wszystkie poglądy w całym dokumencie i klasyfikuje cechy podmiotu zgodnie z poglądami, umożliwia uzyskanie szerszych i całościowych informacji na temat analizowanego tematu, w przeciwieństwie do pojedynczego podmiotu lub polaryzacji. Pozwala to analizatorowi uzyskać szczegółowe informacje na dany temat z wielu perspektyw.
Analiza dźwięku
Analiza dźwięku to rodzaj analizy przeprowadzanej na nieustrukturyzowanych danych dźwiękowych w celu wyodrębnienia istotnych informacji w celu usprawnienia działalności. Tego typu analiza jest szczególnie istotna w sektorze usług biznesowych. Analiza ludzkiego języka mówionego jest uważana za część analizy dźwięku, zwanej analizą mowy. Wraz ze wzrostem orientacji biznesowej na klienta, analizy audio mogą być stosowane w środowisku produkcyjnym w celu uzyskiwania konstruktywnych danych wejściowych z informacji zwrotnych od klientów opartych na dźwięku w celu poprawy. Istnieją dwa ogólne rodzaje technik analizy dźwięku, a mianowicie analiza fonetyczna i ciągłe rozpoznawanie mowy z dużym słownictwem (LVCSR). Analiza oparta na fonetyce wykorzystuje sekwencję dźwięków w dźwięku lub zdaniu, znaną jako fonem, jako podstawową jednostkę analizy. Fonemy są jednostką różnicującą słowa w medium analitycznym według wymowy. Ta technika obejmuje fazę indeksowania i wyszukiwania. W fazie indeksowania medium jest tłumaczone na sekwencję fonemów. Następnie, w fazie wyszukiwania, algorytm wyszukuje fonetyczną reprezentację wejściowych terminów wyszukiwania. Podejście to koduje fonemy w matrycę możliwości, do której następnie odwołuje się dopasowywanie wyszukiwanych terminów w procesie analizy. Zaletą tej techniki jest możliwość wyszukiwania słów, które nie są z góry określone, jeśli fonemy są identyfikowalne. Przetwarzanie jest również szybsze w porównaniu z LVCSR. Wadą tej techniki jest wolniejszy proces wyszukiwania, ponieważ fonemy nie mogą być zindeksowane, tak jak słowo, i zajmują więcej miejsca w pamięci. Technika LVCSR sprawdza prawdopodobieństwo różnych sekwencji słów przy użyciu podejścia statystycznego, umożliwiając wyższą dokładność w porównaniu z podejściem wyszukiwania fonetycznego. Podobnie jak w przypadku podejścia opartego na fonetyce, zaangażowane są dwie fazy indeksowania i wyszukiwania. W pierwszej fazie indeksowania zaimplementowano specjalny algorytm automatycznego rozpoznawania mowy w celu transliteracji dźwięku lub mowy na pasujące słowa. Słowa zostały wstępnie zdefiniowane w liście słowników. Rozpoznawane jest każde słowo, a najbliższe pasujące słowo zostanie użyte, jeśli nie zostanie znalezione rzeczywiste słowo, w celu utworzenia pełnej transkrypcji mowy z przeszukiwalnym plikiem indeksu. Druga faza wyszukiwania, standardowy algorytm wyszukiwania tekstu, została wykorzystana do przetworzenia wyszukiwanego terminu w transkrypcji. Chociaż technika ta wymaga większych zasobów przetwarzania niż techniki oparte na fonetyce, wygenerowany transkrypcja mowy umożliwia bardziej efektywne i wydajne wykorzystanie zebranych informacji.
Analiza wideo
Postęp technologii komputerowych i obrazowania cyfrowego napędza wdrożenie analizy treści wideo (VCA) w celu uzyskania ważnych informacji z treści wideo. Wraz ze zwiększoną mocą obliczeniową można wdrożyć VCA w celu niemal natychmiastowego generowania znaczących informacji i spostrzeżeń. Nowoczesne zakłady produkcyjne wyposażone w dużą liczbę systemów CCTV i kamer do monitorowania procesów produkcyjnych, stanu urządzeń i przepływów materiałów na hali produkcyjnej. Dzięki takim urządzeniom do obrazowania, kontrolerzy produkcji będą mogli monitorować wszystkie ważne procesy w scentralizowanej sterowni. Dysk BD wygenerowany z kanałów wideo może być dalej analizowany w celu uzyskania lepszego BI i praktycznych spostrzeżeń. Przykładami insightów generowanych z VCA są formy wzorców, cech, atrybutów i konkretnych zdarzeń, pozwalające na podejmowanie skutecznych decyzji i sprawne wdrażanie przez właściwe osoby w odpowiednim czasie. Oprócz uzyskiwanych informacji monitorujących, kolejnym ważnym obszarem zastosowania VCA jest automatyczne indeksowanie i wyszukiwanie wideo. Wraz z rozwojem wielu form treści wideo i źródeł indeksowanie nośników treści przeszukiwalnych dla IE ma kluczowe znaczenie. Proces indeksowania odbywa się na podstawie różnych poziomów danych zawartych w filmie, takich jak teksty, audio, metadane i treści wizualne. Różne techniki analityczne można łączyć w celu analizy zawartości do indeksowania; na przykład analiza tekstu może być używana do indeksowania wideo w transkrypcjach i analizy dźwięku w ścieżkach dźwiękowych zawartych w wideo. W architekturze systemowej VCA były dwie główne techniki: serwerowa i brzegowa. W przypadku konfiguracji opartej na serwerze skonfigurowano scentralizowany i dedykowany serwer, aby odbierać wszystkie filmy zarejestrowane przez każdą kamerę. VCA zostały wykonane bezpośrednio na tym serwerze przy użyciu wszystkich odebranych filmów.Głównym aspektem tej konfiguracji jest ograniczenie przepustowości transmisji danych wideo. Aby sprostać temu ograniczeniu, dane wideo ze źródła są często kompresowane. Ta kompresja powoduje utratę informacji w filmie, co wpłynie na dokładność analizy. Jednak konfiguracja oparta na serwerze umożliwia łatwiejszą konserwację i, co najważniejsze, ekonomię skali, przezwyciężając ograniczenia przepustowości. W przeciwieństwie do tego, konfiguracja oparta na krawędziach zapewnia bezpośrednie VCA stosowane lokalnie w systemie obrazowania przy użyciu nieprzetworzonych danych przechwyconych przez kamerę. Taka konfiguracja nie powoduje utraty informacji, ponieważ użyto nieprzetworzonych danych wideo. Cała zawartość wideo jest dostępna do analizy, co przyczynia się do zwiększenia dokładności analizy. Jednak koszty konfiguracji i konserwacji są wyższe w przypadku tej konfiguracji, a wydajność przetwarzania systemu jest również niższa w porównaniu z systemami opartymi na serwerze.
Analiza wideo
Postęp technologii komputerowych i obrazowania cyfrowego napędza wdrożenie analizy treści wideo (VCA) w celu uzyskania ważnych informacji z treści wideo. Wraz ze zwiększoną mocą obliczeniową można wdrożyć VCA w celu niemal natychmiastowego generowania znaczących informacji i spostrzeżeń. Nowoczesne zakłady produkcyjne wyposażone w dużą liczbę systemów CCTV i kamer do monitorowania procesów produkcyjnych, stanu urządzeń i przepływów materiałów na hali produkcyjnej. Dzięki takim urządzeniom do obrazowania, kontrolerzy produkcji będą mogli monitorować wszystkie ważne procesy w scentralizowanej sterowni. Dysk BD wygenerowany z kanałów wideo może być dalej analizowany w celu uzyskania lepszego BI i praktycznych spostrzeżeń. Przykładami insightów generowanych z VCA są formy wzorców, cech, atrybutów i konkretnych zdarzeń, pozwalające na podejmowanie skutecznych decyzji i sprawne wdrażanie przez właściwe osoby we właściwym czasie. Oprócz uzyskiwanych informacji monitorujących, kolejnym ważnym obszarem zastosowania VCA jest automatyczne indeksowanie i wyszukiwanie wideo. Wraz z rozwojem wielu form treści wideo i źródeł indeksowanie nośników treści przeszukiwalnych dla IE ma kluczowe znaczenie. Proces indeksowania odbywa się na podstawie różnych poziomów danych zawartych w filmie, takich jak teksty, audio, metadane i treści wizualne. Różne techniki analityczne można łączyć w celu analizy zawartości do indeksowania; na przykład analiza tekstu może być używana do indeksowania wideo w transkrypcjach i analizy dźwięku w ścieżkach dźwiękowych zawartych w wideo. W architekturze systemowej VCA były dwie główne techniki: serwerowa i brzegowa. W przypadku konfiguracji opartej na serwerze skonfigurowano scentralizowany i dedykowany serwer, aby odbierać wszystkie filmy zarejestrowane przez każdą kamerę. VCA zostały wykonane bezpośrednio na tym serwerze przy użyciu wszystkich odebranych filmów.Głównym aspektem tej konfiguracji jest ograniczenie przepustowości transmisji danych wideo. Aby sprostać temu ograniczeniu, dane wideo ze źródła są często kompresowane. Ta kompresja powoduje utratę informacji w filmie, co wpłynie na dokładność analizy. Jednak konfiguracja oparta na serwerze umożliwia łatwiejszą konserwację i, co najważniejsze, ekonomię skali, przezwyciężając ograniczenia przepustowości. W przeciwieństwie do tego, konfiguracja oparta na krawędziach zapewnia bezpośrednie VCA stosowane lokalnie w systemie obrazowania przy użyciu nieprzetworzonych danych przechwyconych przez kamerę. Taka konfiguracja nie powoduje utraty informacji, ponieważ użyto nieprzetworzonych danych wideo. Cała zawartość wideo jest dostępna do analizy, co przyczynia się do zwiększenia dokładności analizy. Jednak koszty konfiguracji i konserwacji są wyższe w przypadku tej konfiguracji, a wydajność przetwarzania systemu jest również niższa w porównaniu z systemami opartymi na serwerze.
Analityka społeczna
W zrozumieniu wymagań klientów w zakresie opracowywania strategii biznesowej i doskonalenia procesów, korporacje wykorzystują wiele podejść, aby zbliżyć się do obecnych klientów i jednocześnie przyciągnąć potencjalnych klientów. Na podstawie tego podejścia front-end, analitycy społecznościowi opracowują informacje z pierwszej ręki, które następnie przekształcają się w strategię biznesową, a następnie rozprzestrzeniają się w produkcji w celu wytworzenia wymaganych produktów. Analityka społeczna obejmowała analizy różnych mediów społecznościowych, które zawierają zarówno dane ustrukturyzowane, jak i nieustrukturyzowane. Wymiana treści za pośrednictwem platformy mediów społecznościowych obejmuje wielopoziomowe społeczności i portale, zawierające ogromne ilości danych różnego typu. Ze względu na ogromną bazę użytkowników i różnorodność udostępnianych informacji, media społecznościowe są jednym z największych generatorów danych. Platformy mediów społecznościowych można podzielić na sieci społecznościowe, takie jak Facebook i LinkedIn, blogi piszące treści, takie jak Wordpress i Blogger, platformy udostępniania multimediów, takie jak YouTube i Instagram, wiki do udostępniania wiedzy, takie jak Wikipedia i Wikihow, witryny z recenzjami treści, takie jak Trustpilot i Testfreaks , witryny z pytaniami i odpowiedziami, takie jak Ask.com, zakładki społecznościowe, takie jak Pinterest i StumbleUpon, oraz mikroblogi, takie jak Twitter i Tumblr. Głównym źródłem informacji z analityki mediów społecznościowych są treści generowane przez użytkowników, takie jak obrazy, filmy i nastroje, powiązane z ich relacjami i interakcjami między obiektami sieciowymi, takimi jak produkty, firmy, ludzie i miejsca. W odniesieniu do tego grupowania klasyfikuje się dwa podejścia analityczne, a następnie omówiono poniżej.
Analityka strukturalna
Jest to podejście analityczne do syntezy i oceny cech organizacyjnych sieci społecznościowych w celu wydobycia znaczących spostrzeżeń i inteligencji z relacji ustanowionych między zaangażowanymi podmiotami. Proces analityczny wykorzystuje sieci i teorię grafów, reprezentując osoby lub podmioty w sieci jako węzły i łącząc je więzami na podstawie ustanowionej relacji lub interakcji. Węzły są reprezentowane jako punkty, a powiązania są reprezentowane jako linie w tych sieciach i zwykle wizualizowane za pomocą socjogramów. Wizualizacja węzłów i linii odzwierciedla interesujące cechy wśród podmiotów, zapewniając jakościowe oceny sieci. Ta technika jest również znana jako analityka sieci społecznościowych.`
Analiza treści
To analityczne podejście koncentruje się na treściach publikowanych przez użytkowników na różnych platformach społecznościowych i analizowaniu ich w celu zebrania wymaganych informacji i wykorzystania ich do celów biznesowych. Ponieważ dane te zostały opublikowane z różnych źródeł i osób, często są one generowane w dużych ilościach, nieustrukturyzowane, stochastyczne i dynamiczne. Różne techniki analityczne, jak omówiono wcześniej, są wykorzystywane do przetwarzania tych danych w celu uzyskania informacji. Proces analityczny można sprowadzić do identyfikacji danych, analizy danych i interpretacji informacji. Identyfikacja danych polega na podzieleniu i zidentyfikowaniu dostępnych danych na podzbiory, aby położyć nacisk na ułatwienie analiz. Analiza danych to działanie polegające na przekształceniu surowych danych w informacje, które mogą prowadzić do nowej wiedzy i wartości biznesowej. Interpretacja informacji jest ostatnim krokiem do wyciągnięcia wniosków i wydobycia ważnej spostrzegawczości pytań, na które należy odpowiedzieć na podstawie analizowanych danych. Dane lub informacje są często przedstawiane w łatwych do zrozumienia wizualizacjach, takich jak wykresy lub wykresy, dzięki czemu ostateczny odbiorca informacji, który na ogół nie jest osobą techniczną, jest w stanie zrozumieć i podjąć decyzje biznesowe. Techniki wykorzystywane do wydobywania informacji z sieci społecznościowych są ogólnie podzielone na trzy główne metody: (1) wykrywanie społeczności; (2) analiza wpływu społecznego; oraz (3) przewidywania linków.
Wykrywanie społeczności to jeden z najpopularniejszych tematów we współczesnej nauce o sieciach. Jest to sposób na zidentyfikowanie niejawnego powiązania na węzłach w sieci, które są gęściej połączone niż z innymi, tworzącymi określoną społeczność. Społeczność w sieciach społecznościowych to grupa użytkowników, którzy w większym stopniu wchodzą w interakcję z wzorcem ograniczającym się do podsieci, w porównaniu z resztą sieci. Te nieprawidłowości połączeń sugerują, że w sieci istnieje naturalny podział. Rozmiar sieci społecznościowej jest ogromny i zawiera miliony węzłów i linii. Zidentyfikowanie tych podstawowych struktur społeczności pomaga skompilować sieć, umożliwiając odkrycie obecnych wzorców zachowań i przewidywanie właściwości sieci. Może to zapewnić wgląd w zachowanie społeczności, a także w jaki sposób topologia sieci wpływa na siebie nawzajem. Przykładem korzyści z wykrywania społeczności jest umożliwienie firmie dostarczania bardziej odpowiednich produktów zgodnie z wymaganiami i preferencjami poszczególnych społeczności.
Analiza wpływu społecznego to technika pomiaru wpływu każdej osoby w obrębie sieci społecznościowej oraz zidentyfikować najbardziej wpływową osobę. Modeluje i ocenia zmianę behawioralną spowodowaną przez kluczową osobę wpływającą, a także każdą połączoną osobę w sieci. Ta technika odkrywa wpływowe wzorce, a także dyfuzję wpływów w sieci, ułatwiając przykłady zastosowań proliferacji świadomości marki i adopcji wśród docelowych odbiorców.
Przewidywanie łączy to technika przewidywania przyszłych możliwych powiązań między węzłami w sieci. Służy również do przewidywania brakujących połączeń między niekompletnymi danymi. Sieci społecznościowe są dynamiczną strukturą i ewoluują w czasie. Rośnie w sposób ciągły, tworząc nowe węzły i wierzchołki. Dzięki zrozumieniu powiązania między węzłami - na przykład, jak zmienia się charakterystyka powiązania w czasie i jakie są czynniki wpływające na powiązania oraz w jaki sposób inne węzły wpływają na powiązanie - zapewni to użyteczną prognozę zachowania podmiotów. Ta technika zapewnia przydatne zastosowanie w prognozowaniu przyszłych wymagań produktowych.
Analityka predykcyjna
Analityka predykcyjna wykorzystywała zróżnicowane techniki statystyczne, od eksploracji danych po ML, do analizowania bieżących i historycznych danych w celu przewidywania możliwych przyszłych zdarzeń i wyników. Analityka predykcyjna odgrywa główną rolę w SM. Dzięki skutecznemu wdrożeniu przyniesie istotną zmianę w obecnym horyzoncie produkcyjnym z bezprecedensową poprawą wydajności produkcji we wszystkich aspektach kosztów, wydajności i jakości. Zasadniczo, techniki analizy predykcyjnej są wykorzystywane do wykrywania wzorców i zależności w danych, aby umożliwić analitykom zrozumienie wydajności i wygenerowanie skorelowanych prognoz, takich jak wymagania materiałowe, wydajność sprzętu i wpływ na jakość produktu. Podejście do analityki predykcyjnej można podzielić na dwie grupy:
(1) Odkrywanie wzorców, gdzie techniki statystyczne, takie jak średnie ruchome, zostały użyte do ujawnienia historycznych wzorców w danych, a następnie wykorzystuje wynik do ekstrapolacji do prognozowania przyszłego zachowania; (2) uchwycenie współzależności poprzez wykorzystanie technik statystycznych, takich jak regresja liniowa, w celu uzyskania współzależności między danymi wejściowymi analitycznymi a zmiennymi wynikowymi i wykorzystanie ich do tworzenia prognoz dotyczących zdarzeń.
Techniki analizy predykcyjnej w dużej mierze opierają się na metodach statystycznych do analizowania i wydobywania informacji z danych. Ogromna ilość danych, rozmiar i wysoka wymiarowość BD prowadzi do unikalnych wyzwań obliczeniowych i statystycznych w zakresie analizy. Kilka czynników wskazuje, że konwencjonalna metoda statystyczna nie jest odpowiednia dla BDA i wymagane jest nowe podejście analityczne. Po pierwsze, główna różnica między BD a konwencjonalnymi danymi procesu produkcyjnego polega na tym, że BD zawiera wszystkie dane dotyczące populacji w procesach. Konwencjonalne metody statystyczne oparto na badaniach istotności na podstawie danych pobranych z populacji, a opracowane informacje uogólniono, aby wywnioskować zachowanie populacji. Podejście to zastosowano ze względu na brak możliwości uzyskania pełnych danych o populacji przed cyfryzacją procesów produkcyjnych. W przeciwieństwie do tego, nowoczesne zdigitalizowane procesy produkcyjne są w stanie generować pełne dane dotyczące populacji w każdym procesie. Konwencjonalne podejścia statystyczne oparte na istotności pobranych danych spowodują, że dane będą niewykorzystane. Analiza danych o małej liczebności próby w metodzie konwencjonalnej ograniczy również dokładność analizy w wielowymiarowości danych, powodując ograniczenie lub utratę informacji. W rezultacie istotność statystyczna interpretowana w konwencjonalnych technikach statystycznych nie była odpowiednia dla ChAD. Po drugie, wydajność obliczeniowa metod konwencjonalnych nie była odpowiednia dla analizy dużych ilości danych. Nacisk konwencjonalnych technik statystycznych na leżące u podstaw modele prawdopodobieństwa, zakorzenione w istotności statystycznej, określone na podstawie losowych danych z próby na reprezentowanych niepewnościach populacji. Zastosowanie pełnych danych populacyjnych do wnioskowej analizy statystycznej w podejściu konwencjonalnym nie przyniesie znaczącego wyniku ze względu na mały błąd standardowy wywodzący się z prawie znanych niepewności populacji. Trzeci czynnik wiąże się z istotnymi cechami BD: niejednorodnością, fałszywymi korelacjami, przypadkową endogennością i akumulacją szumu. Niejednorodność w BD była spowodowana pozyskiwaniem danych z różnych źródeł, reprezentujących różne informacje o różnych populacjach obiektów. Dane były często niejasne, zawierały brakujące wartości, nadmiarowość i zakłamania, co powodowało trudności w bezpośrednim zastosowaniu. Niespójność danych spowoduje również, że dane subpopulacji o niskiej częstotliwości zostaną uznane za wartości odstające w dużych danych dotyczących populacji o wysokiej częstotliwości. Jednak stromy stosunek danych o dużej częstotliwości do wartości odstających przyćmi wpływ wartości odstających za pomocą zaawansowanych technik analitycznych (AA).
Pozorna korelacja. Wysoka wymiarowość BD wynikająca z ogromnej ilości danych może powodować fałszywą korelację. Jest to zjawisko, w którym wysoka wymiarowość danych powoduje fałszywe powiązania rzeczywistych nieskorelowanych zmiennych losowych, które następnie stają się skorelowane. Ten błąd spowoduje błędne wnioskowanie statystyczne prowadzące do fałszywych przewidywań lub prognoz uzyskanych z modelu. Przypadkowa endogenność. To kolejne zjawisko wywołane dużą wymiarowością BD. W przeciwieństwie do korelacji pozornej, endogeniczność incydentalna to rzeczywiste istnienie niezamierzonej korelacji między zmiennymi losowymi ze względu na dużą wymiarowość danych, zwłaszcza zmiennych objaśniających z błędami. Symptom ten pojawia się w wyniku pominięcia zmiennych, błędów pomiarowych i błędów selekcji. Często pojawia się w BD ze względu na (1) cyfryzację metodologii pomiaru, która skutkuje łatwością zbierania danych, a analitycy mają tendencję do zbierania jak największej ilości danych. Większa pojemność danych zwiększa prawdopodobieństwo przypadkowej korelacji z szumem resztkowym. (2) Wiele różnych źródeł generowania danych dla BD zwiększa prawdopodobieństwo błędów pomiarowych i błędu selekcji danych, co również prowadzi do przypadkowej endogeniczności.
Akumulacja hałasu. Analiza BD w celu wyodrębnienia informacji do przewidywania i prognozowania modelu wymaga równoczesnych oszacowań lub testów z wieloma różnymi parametrami. Ta duża liczba parametrów powoduje błędy szacowania obliczeń i kumuluje się, gdy model predykcyjny lub decyzyjny wykorzystuje te parametry. Te akumulacje hałasu będą miały znaczący wpływ na generowane modele, zwłaszcza w przypadku danych wielowymiarowych. Szum osiągnie stopień, w którym dominuje nad prawdziwymi sygnałami w modelu, powodując fałszywą lub niedokładną decyzję lub prognozę z modelu. Innymi słowy, prawdziwie znaczące zmienne z sygnałami opisowymi mogą pozostać niezauważone z powodu nagromadzenia szumu. Wewnętrzne cechy BD skutkują unikalnymi cechami, które ograniczają konwencjonalne techniki statystyczne w analizie danych. Firma BD stawiała również krytyczne wyzwania dla wydajności obliczeniowej. Biorąc pod uwagę omówione i podkreślone czynniki, pewne jest, że potrzebne są nowe techniki analityczne, aby uzyskać znaczący wgląd z modeli predykcyjnych generowanych przy użyciu BD.
Zaawansowana analityka Big Data dla inteligentnej produkcji
Współczesne wyzwanie SM dla złożonego podejmowania decyzji odpowiada czterem głównym aspektom: (1) Zdolność do realistycznego modelowania rzeczywistych systemów produkcyjnych w celu gromadzenia informacji i danych; (2) zdolność do integracji spójnych, wiarygodnych i aktualnych danych dotyczących zakładu produkcyjnego; (3) zdolność do przetwarzania zebranych danych w celu uzyskania wymaganych informacji w ramach racjonalnych nakładów obliczeniowych; oraz (4) zdolność do włączenia systemów informacji zwrotnej do procesu produkcyjnego w celu ciągłego doskonalenia i ułatwiania ciągłych procedur podejmowania decyzji w czasie. BD i zaawansowana analityka do przewidywania, przepisywania i wykrywania to podstawa potrzebna do osiągnięcia powyższych czterech aspektów. Rozszerzenie dostępności BD w jej unikalnych cechach objętości, różnorodności, szybkości, prawdziwości, zmienności i wartości, wraz z postępem coraz większych technologii obliczeniowych i komunikacyjnych, było katalizatorem, który skłonił firmy produkcyjne do wdrożenia kombinacji technik różnorodnych i AA do wprowadzić usprawnienia procesów i wydajności do kontekstu SM. Te techniki AA można opisać jako:
• Analityka opisowa: wstępny etap tworzenia podsumowania danych historycznych w celu wydobycia przydatnych informacji o przeszłych zdarzeniach, a także przygotowania danych do dalszej analizy pod kątem przyszłych zdarzeń. Do wykorzystania w retrospektywnych praktykach i prognozowaniu przyszłych wymagań biznesowych.
• Analityka predykcyjna: zastosowanie podejścia analitycznego z dostępnymi danymi, zazwyczaj heterogenicznymi i dużymi ilościami danych, w celu przewidywania możliwych przyszłych zdarzeń, takich jak trendy, ruchy, zachowania i skłonności.
• Analityka nakazowa: Odnosząc zarówno analitykę opisową, która dostarcza informacji o przeszłych zdarzeniach, jak i analizę predykcyjną, która przewiduje przyszłe zdarzenia, analiza nakazowa określa najlepsze rozwiązanie lub wynik z dostępnych opcji na podstawie znanych parametrów. Znajduje najlepsze opcje wyjścia procesu na podstawie informacji wejściowych.
• Analityka detektywistyczna: Podejście do badania przyczyn i źródeł incydentów lub wariacji, które ograniczają zdolność procesów lub systemów do osiągania optymalnych wyników dzięki zebranym danym w celu wyeliminowania i skorygowania niewłaściwych wartości wykorzystywanych w analityce predykcyjnej i nakazowej.
• Analityka poznawcza: Analiza generowania interpretacji na podstawie istniejących danych lub wzorców oraz wyciągania wniosków na podstawie istniejącej dostępnej wiedzy i danych wejściowych z powrotem do bazy wiedzy jako nowej wyuczonej funkcji. Automatyzuje wszystkie techniki analityczne w celu podejmowania trafniejszych decyzji w czasie poprzez samouczącą się pętlę informacji zwrotnych.
Wdrożenie AA for SM wymaga zaangażowania od najwyższego kierownictwa po halę produkcyjną w celu zapewnienia wydajności i skuteczności systemu. AA dla BD będzie w stanie udzielić odpowiedzi na pytania zadawane firmie dotyczące przeszłych zdarzeń (analityka opisowa), potencjalnych przewidywanych przyszłych zdarzeń (analityka predykcyjna) oraz opartych na dowodach decyzji dotyczących sposobu kapitalizacji przez firmę krótko-, średnio- i długo- plany terminowe (analityka nakazowa). SM wydajnie wzajemna produkcja jako centralny proces do poziomego SCM po obu stronach dostawcy w celu optymalizacji wprowadzania surowców i terminowego dostarczania produktów do klientów, a także pionowej komunikacji zarządzania w celu uzyskania efektywnych decyzji biznesowych. AA zapewni najlepszą kontrolowaną moc w modelu SM. Istnieje wiele zastosowań BDA w przemyśle wytwórczym, zarówno konwencjonalnym, jak i SM. Obszary wdrożenia obejmują kontrolę jakości, optymalizację procesów, wykrywanie usterek, diagnostykę sprzętu i konserwację predykcyjną. Wraz z zalewem BD we współczesnym zdigitalizowanym świecie, wydajne i efektywne wykorzystanie tych danych może zapewnić dogłębny wgląd i informacje na interesujący temat. Dzięki BDA można dokonać wszystkich powiązań podmiotów, prognozować zapotrzebowanie na produkt, ukierunkować marketing i możliwe wyniki zdarzeń, a powiązane działania można zaplanować z wyprzedzeniem. Takie podejście umożliwia obniżenie kosztów produkcji i utrzymania, a także konkurencyjność biznesową.
Rzeczywistość wirtualna i rozszerzona w Przemyśle 4.0
Był taki okres w naszej historii, kiedy prace przemysłowe wykonywano ręcznie przez roboty w ich domach. Później zaczęło się to dziać w przemyśle za pomocą maszyn. Proces przenoszenia gospodarki rolnej opartej na pracy do opartej na maszynach nazywa się rewolucją przemysłową. Ta transformacja rozpoczęła się początkowo w Wielkiej Brytanii w XVIII wieku, a następnie w krajach europejskich, takich jak Belgia, Niemcy i Francja, i powoli zaczęła rozprzestrzeniać się na cały świat. Rewolucja przemysłowa była wynikiem rozwoju wiedzy, urządzeń, maszyn, technologii i narzędzi, a zwłaszcza akceptacji społecznej i kulturowej ze strony ludzi oraz wynikających z niej korzyści. Wcześniej żelazo, stal i drewno były podstawowymi surowcami szeroko stosowanymi. W tym czasie dostępny był silnik parowy, silnik spalinowy i prąd. Później, w związku z rewolucją przemysłową, opracowano parowiec, lokomotywę, telegraf i radio. Idea wykorzystania nauki do rozwoju ludzkości w imię przemysłu czy fabryki zaczęła się zapuszczać. Transformację gospodarczą, która miała miejsce w krajach zachodnich w latach 1780-1850, nazwano pierwszą rewolucją przemysłową. Zdając sobie sprawę ze znaczenia nauki i technologii, wraz z większą liczbą badań, miała miejsce druga i trzecia rewolucja przemysłowa. Czas trwania każdej rewolucji przemysłowej wynosił około pięćdziesięciu lat. Był to okres masowej produkcji.
Przemysł 4.0
Istnieje powszechne przekonanie, że pierwsza rewolucja przemysłowa dotyczyła pary i wody, druga rewolucja przemysłowa dotyczyła stali, a trzecia rewolucja przemysłowa dotyczyła elektryczności, internetu i samochodów. Natomiast czwarta rewolucja przemysłowa dopiero się rozpoczęła. Termin Przemysł 4.0 został przedstawiony przez rząd niemiecki w 2011 r. na targach w Hanowerze Termin Przemysł 4.0 jest również nazywany "Internetem przemysłowym", "Fabryką cyfrową", "Inteligentną fabryką", "Fabryką przyszłości" i "Inteligentną produkcją". przez profesjonalistów. Przemysł 4.0 lub czwarta rewolucja przemysłowa opiera się na Internecie rzeczy (IoT), Internecie usług (IoS), systemach cyberfizycznych (CPS) oraz interakcji i wymianie danych między ludźmi (C2C), maszynami (M2M) oraz między ludźmi i maszyny (C2M). Ponieważ Przemysł 4.0 jest wciąż na wczesnym etapie, kilka organizacji badawczych, uniwersytetów i firm próbuje rozwinąć w pełni zautomatyzowany przemysł lub fabrykę opartą na Internecie, taką jak fabryka Siemens Amberg w Niemczech, gdzie fabryka o powierzchni 108 000 stóp kwadratowych może działać i montować komponenty bez udziału człowieka . Przemysł 4.0 ma kilka komponentów, takich jak przetwarzanie w chmurze, CPS, IoT, integracja systemów, produkcja addytywna (AM), rzeczywistość rozszerzona (AR), rzeczywistość wirtualna (VR), analiza danych, roboty AI itp.
Cloud computing - dane związane z produkcją będą przesyłane i udostępniane w technologii cloud, gdzie czas odbioru i reakcji wyniesie kilka milisekund. CPS - zaawansowane narzędzie informatyczne, które posiada dużą pojemność i dużą prędkość transmisji. CPS dostarcza rozwiązania oparte na aplikacjach programowych przy jednoczesnym ograniczeniu roli sprzętu czy urządzeń mechanicznych [8]. Inteligentne produkty są składnikami CPS. Może łączyć zarówno świat rzeczywisty, jak i wirtualny.
IoT - modernmanufactures zastanawiali się, jak przekształcić swój produkt w długoterminową usługę przynoszącą przychody. Doprowadziło ich do IoT. IoT to podstawowa integracja inteligentnych urządzeń, które są częścią inteligentnych projektów. Na przykład w inteligentnym domu telewizor, konsola do gier i klimatyzator, które mają adres IP, mogą być podłączone do IoT i uzyskać do nich dostęp z dowolnego miejsca. Otis dostarcza społeczeństwu windy z czujnikami, które przesyłają dane do chmury. Dane te są analizowane, a Otis oferuje pakiety serwisowe, co ponownie generuje dodatkowe przychody.
Integracja systemu - w Przemyśle 4.0 kilka działów w fabryce lub kilka fabryk w tej samej firmie zostaje zorganizowanych i połączonych za pomocą uniwersalnej integracji danych.
Produkcja przyrostowa (AM) - dzięki Industry 4.0 drukowanie 3D będzie szeroko stosowane do wytwarzania niestandardowych produktów. AR, VR - Usługi oparte na AR i VR oferują pracownikom i operatorom usprawnienie procesu decyzyjnego i ograniczenie procedur pracy.
Analiza danych - zbieranie i indeksowanie danych z różnych źródeł stanie się standardem w branżach, aby wspierać podejmowanie decyzji w czasie rzeczywistym.
Roboty AI - roboty zaczną bezpiecznie ze sobą współpracować z lub bez interwencji człowieka.
Rzeczywistość rozszerzona i rzeczywistość wirtualna
Ingerencja w pracę ludzi i maszyn w przemyśle powinna być elastyczna i adaptacyjna. Z tego powodu kilka branż zaczęło stosować AR i VR do szkolenia swoich pracowników. Dzięki temu szkoleniu mogą (i) przyspieszyć pracę lub zmienić konfigurację pracy, (ii) wspierać operatorów, (iii) wykonywać rozszerzoną wirtualność (AV ) szkolenie w zakresie kompilacji lub konstruowania części, (iv) efektywne administrowanie składem lub magazynem, (v) wspieranie diagnostyki podczas montażu oraz (vi) minimalizowanie ryzyka w środowisku pracy. Kluczowe technologie AV stosowane w branży to interakcja wyświetlania, śledzenie pozycjonowania i rejestracji, interakcja człowiek-komputer, wykrywanie i rozpoznawanie obiektów, kalibracja, renderowanie modeli, analiza przestrzeni 3D i wykrywanie kolizji . Próby symulacji 3D datuje się na rok 1930, kiedy Stanley G. Weinbaum użył pary gogli, aby obejrzeć swój film "Okulary Pigmaliona", aby poddać się holograficznemu doświadczeniu. Ten ostatni AR został po raz pierwszy wprowadzony przez pioniera komputerowego Ivana Sutherlanda w 1968 roku. Użył wyświetlacza montowanego na głowie (HMD), który był podłączony do stereoskopowego wyświetlacza z komputera. AR to technologia, która nakłada wirtualny obraz lub informacje w świecie rzeczywistym. Na przykład dodanie obrazu lub tekstu do wyświetlania użytkownika wirtualnie w środowisku rzeczywistym (RE). Tutaj RE reprezentuje otoczenie użytkownika. Niedawna gra Pokemon GO jest dobrym przykładem wykorzystania AR. Natomiast środowisko wirtualne (VE) to otoczenie całkowicie generowane przez komputer, na którym użytkownik nie będzie miał żadnego kontaktu z RE. VR to świat syntetyczny, który może, ale nie musi wyglądać jak świat rzeczywisty. Początkowo VR zawładnęło światem w latach 90. dzięki sprzętom takim jak Saga VR i Nintendo Virtual Boy. W XXI wieku, korzystając z VR, ludzie zaczęli tworzyć wirtualną reprezentację siebie zwaną "Avatary".
Biblioteki programistyczne
Istnieje kilka bibliotek programistycznych AV używanych w przemyśle. Wśród nich powszechnie stosowane są ARToolKit, ARTag, osgART i Vuforia. ARToolKit to biblioteka śledząca typu open source. Jest to najczęściej używane narzędzie do tworzenia AR. Hirokazu Kato opracował go po raz pierwszy w 1999 roku. ARToolKit był dalej rozwijany za pomocą ARTag. ARTag służy do uproszczenia wirtualnych obiektów w świecie rzeczywistym. OsgART to wieloplatformowa biblioteka C++. Kompiluje bibliotekę śledzenia z biblioteką 3D. Vuforia to zestaw do tworzenia oprogramowania AR dla telefonów komórkowych. Kompiluje wizję komputerową, zmiany planarne i obiekty 3D w czasie rzeczywistym. Wraz z niedawnym rozwojem rzeczywistości mieszanej (MR), AR i VR są coraz częściej wykorzystywane w branżach w celu skrócenia czasu przetwarzania, szkolenia i podejmowania decyzji. Mając to na uwadze, w tej części dokonano przeglądu osiągnięć AR i VR, narzędzi służących do konstruowania rzeczywistości oraz pola ich zastosowania w ostatnich czasach.
AR i VR w Przemyśle 4.0
AR i VR są bardzo powszechnie stosowane w przemyśle produkcyjnym w celu kontroli jakości produktu, szkolenia lub nauczania nowych rekrutów, projektowania przestrzeni roboczej, dostosowywania do potrzeb klienta, utrzymania fabryki, wytwarzania elementów i marketingu. Ocena jakości, która odbywa się metodą tradycyjną, zajmuje dużo czasu. Koncepcja koncepcyjna zaproponowana i zwalidowana przez Federicę Ferraguti i wspólników. wykazała, że AR można stosować w kontroli jakości. Dzięki takiemu podejściu operator może bezpośrednio zobaczyć produkt, jeśli osiągnął on specyfikacje jakościowe lub dalej wymagane udoskonalenia. Fabryki są prowadzone nie tylko przez ludzi, ale także przez maszyny, takie jak roboty. Nowa teoria głosi, że rzeczywistość wirtualna może być wykorzystywana do współpracy człowiek-maszyna w celu adaptacyjnej inżynierii produktów. Nie tylko w projektowaniu, produkcji i kontroli jakości produktu, ale także w marketingu produktu można zastosować AR i VR. W badaniu z 2013 r. dotyczącym marketingu obuwia wykorzystano technologie AR i VR w marketingu. Morenilla i in. opracował stereoskopowy system wizyjny oparty na oprogramowaniu 3D+ i projektowaniu obuwia. Komputer stacjonarny z systemem Windows 7 z procesorem i5, 4 GB RAM, nVidia. Do obejrzenia obuwia wykorzystano kartę graficzną Quadro 600, pakiet 3dVision, dwuczęstotliwościowy monitor LED 3D BENQ oraz CodeGear C++ RAD Studio 2007. Do interakcji z obuwiem użyto rękawicy VR od 5DT. Miał pięć czujników na zgięcie i dwa na obrót. Ta pojedyncza rękawica zastępuje pracę wykonywaną przez klawiaturę i mysz. Różne ułożenie gestów palców odpowiada różnym widokom. Do uchwycenia użytkownika lub konsumenta i obejrzenia go w AR wykorzystano kamerę LG Webpro 2 do przechwytywania scen. Do zlokalizowania pozycji stopy wykorzystano kamerę IR z konsoli Nintendo oraz urządzenie emitujące składające się z czterech diod LED . Po kalibracji i przetworzeniu końcowy wynik jest wyświetlany na monitorze w czasie rzeczywistym, gdzie konsument jest rzeczywisty, a but jest wirtualnie rozwinięty . Korzystając z tej metody, konsument może wirtualnie zobaczyć siebie noszącego buty. Za pomocą AR i VR można skonfigurować ergonomiczne miejsce pracy lub znaleźć ergonomię istniejącego miejsca pracy. Aplikacja do analizy ergonomicznej Ceit (CERAA) jest używana w mobilnym lub z automatycznym wirtualnym środowiskiem jaskini (CAVE), markerami, pilotami Wii i formularzami oceny, takimi jak szybka ocena całego ciała (REBA) i szybka ocena kończyn górnych (RULA) w celu znalezienia ergonomia biura. AR służy do dostosowywania przemysłu lub fabryki do potrzeb. Korzystanie z instrukcji lub opisów produktów w formacie PDF jest przestarzałe. Ostatnie badania z 2019 r. obejmowały AR, wykorzystując Unity 3D, Vuforia, HMD i HoloLens do konwersji papierowych podręczników na cyfrowe teksty, znaki i reprezentacje graficzne, pomagając operatorowi w łatwym zrozumieniu i korzystaniu z instrukcji. AR i VR są wykorzystywane do projektowania wirtualnego środowiska pracy, w którym operator lub mechanik może zrozumieć, w jaki sposób składane są części. Korzystając z AR i VR, możliwa jest również zdalna konserwacja. VR jest szczególnie używany do szkolenia aplikacji przemysłowych. Zamiast wizyty na miejscu i pochłaniania godzin pracy, wirtualna reprezentacja branży, magazynu i jego komponentów jest korzystna i cenna w szkoleniu nowicjusza. Badanie z 2019 roku przeprowadzone przez Pereza i innych opracowało VR branży, naśladując to samo środowisko wraz z robotami do szkolenia operatorów. Ogólnie rzecz biorąc, robot jest strukturą mechaniczną z elektroniką, silnikami, sterownikami i interfejsem człowiek-maszyna (HMI). Perez i in. zastąpiono ten interfejs HMI VR, który jest podłączony do robota. Zaproponowany przez nich system składa się z dwóch robotów: rzeczywistego i wirtualnego, oba sterowane przez ten sam kontroler, który został sparowany z VR . Czujniki zostały połączone z prawdziwym robotem, aby uzyskać pozę i dokładność. Aby wirtualnie stworzyć identyczne środowisko pracy, środowisko pracy zostało wstępnie zeskanowane za pomocą FARO Focus3D HDR. Otrzymana chmura punktów 3D została przetworzona za pomocą CloudCompare, wymodelowana za pomocą Blendera, a następnie przetworzona za pomocą Unity3D w celu wdrożenia HMI. Korzystając z Oculus Rift i HTC Vive, opracowany wirtualny został przesłany operatorom do szkolenia robotów symulowanych i obsługiwanych przez VR. Dwanaście osób przeszło szkolenie, a ich opinie zostały zarejestrowane za pomocą kwestionariusza. Uważali, że szkolenia VR podniosą efektywność środowiska pracy. AR, VR i produkcja addytywna są obecnie najcenniejszymi aspektami przemysłu lotniczego, ponieważ odgrywają ważną rolę w konserwacji, wykrywaniu błędów i bezpieczeństwie w samolotach oraz produkcji małych części do małych samolotów . Technologie AR i VR znajdują zastosowanie w budowie i projektowaniu budynków, maszyn i robotów. W szczególności AR jest używany w modelowaniu informacji o budynku (BIM). Informacje BIM zawarte w oprogramowaniu można wykorzystać podczas wizyty na miejscu. Może być również używany jako ostatni do celów konserwacyjnych. To z kolei przyczynia się do optymalizacji i zapobiegania defektom. AR i VR zrewolucjonizowały medycynę. Są wykorzystywane w analizie, rehabilitacji, chirurgii i leczeniu fobii. Wykorzystując czujnik ruchu skokowego, kamerę IR, diodę LED i Unity 3D, przeprowadzono analizy ruchu dłoni. Za pomocą Microsoft Kinect, Myo Armband i Unity 3D zapewniana jest rehabilitacja pacjentów po udarze. Gra, taka jak wirtualne środowisko, jest rozwijana przy użyciu Unity 3D, w której pacjenci mają grać, na przykład rzucać piłką lub owocem do kosza. Badanie z 2018 r. przeprowadzone przez Esfahlaniego. opracowało grę opartą na VR o nazwie "ReHabGame", aby leczyć pacjentów po udarze. Gra została opracowana przy użyciu silnika gry Unity, który integruje przechwytywanie ruchu / gestów, przetwarzanie obrazu, śledzenie szkieletu i emiter podczerwieni. W skład sprzętu wchodzą wyłącznie opaski na ramię Microsoft Kinect i Thalmic Labs Mayo. Śledzono kontrolę postawy, gesty, zakres ruchu. ReHabGame obejmuje trzy główne projekty gier: (i) osiągnij uchwycenie uwolnienia, (ii) osiągnij trzymanie prasy i (iii) osiągnij naciśnij. Gracze sięgają, chwytają, trzymają i wypuszczają wirtualne owoce w wirtualnym koszu. Ta gra obejmuje zginanie, rozciąganie, odwodzenie, przywodzenie, rotacja wewnętrzna/zewnętrzna oraz odwodzenie/przywodzenie poziome. W badaniu wzięło udział dwudziestu pacjentów z udarem. Większości pacjentów podobała się gra rehabilitacyjna i pozytywna informacja zwrotna. Edukacja jest najważniejsza dla wszystkich. AR i VR przechytrzają tradycyjne prezentacje na czarnych tablicach i w Power Point. Niezależnie od wieku, AR i VR mogą być wykorzystywane do nauczania i szkolenia młodych i starszych. AR jest pomocny w osiąganiu wyników w nauce uczniów. VR jest wykorzystywany w szkoleniach z bankomatów dla osób starszych. Szkolenia wirtualne są również oferowane operatorom przemysłowym. W niedawnym badaniu opracowano VR procesu wydobywczego. Pracownicy byli szkoleni i oceniani za pomocą kwestionariusza. W badaniu 2020 wykorzystano technikę nawigacji wspomaganej komputerowo (CAN) z wykorzystaniem AR Roadmap, Tap to Place i HoloLens Cursor do przeprowadzenia operacji kręgosłupa. W badaniu opartym na VR wykorzystano Oculus Rift, nVisor MH60, EON Studio do leczenia akrofobii - lęku przed wzrostem. Terapia polega na opracowaniu wirtualnego scenariusza wysokościowego, takiego jak wzgórze, wysoki budynek, i poproszeniu pacjentów o chodzenie i przekraczanie dużej wysokości z jednego punktu do drugiego . Poza przemysłem, edukacją i medycyną AR i VR znajdują zastosowanie również w innych dziedzinach. Turystyka, gry, choreografia i satysfakcja klienta to tylko niektóre z nich
Wniosek
Dokonaliśmy oceny i przeglądu wdrożenia AR i VR w Przemyśle 4.0. Badacze wymyślili raczej tanie urządzenia i własne algorytmy niż tradycyjne komercyjne oprogramowanie, takie jak CAVE, które kosztuje więcej. Niektóre artykuły proponowały teorię pojęciową, podczas gdy inne przedstawiały ilościową i jakościową oceny. Ich wyniki sugerują, że AR i VR odgrywają ważną rolę w minimalizowaniu czasu podejmowania decyzji i przetwarzania w czasie rzeczywistym. W środowisku branżowym wykorzystanie AR i VR jest bardziej widoczne. Jednak poza przemysłem korzenie AR i VR nie są głębokie. Inne dziedziny, takie jak edukacja, turystyka i marketing klienta, zaczęły stopniowo wykorzystywać AR i VR i można się spodziewać, że w końcu korzenie mogą się pogłębiać.
Cyberbezpieczeństwo: trendy i wyzwania w kierunku Przemysłu 4.0
W dzisiejszych czasach branża deweloperska stoi w obliczu wyrafinowanego popytu pośród rosnącej konkurencji. Szybki postęp technologiczny doprowadził do powstania rewolucji przemysłowej 4.0. Integracja technologii informatycznych i operacji biznesowych wiąże się z kilkoma wyzwaniami, z których cyberbezpieczeństwo ma pierwszorzędne znaczenie. Cyberbezpieczeństwo odnosi się do aspektów technologii, które dotyczą poufności, dostępności i integralności danych w cyberprzestrzeni i są uważane za powiązane z innymi aspektami bezpieczeństwa. Niektóre branże uważają cyberbezpieczeństwo za kluczowe, ponieważ ten aspekt pomaga chronić poufne informacje specyficzne dla ludzi lub systemów przed nadużyciami, atakami, kradzieżą i niewłaściwym wykorzystaniem w przestrzeni cyfrowej. Łączność sieciowa stale rośnie; w związku z tym istnieje szansa, że dane będą bardziej podatne na cyberataki, w których dane mogą zostać wykorzystane w celu uzyskania korzyści finansowych lub strategicznych. Większość organizacji traktuje cyberbezpieczeństwo jako część domeny technologicznej. Mimo że organizacje znają potencjalne zagrożenia i sposób, w jaki te zagrożenia mogą wpłynąć na działalność biznesową, typową skłonnością nie jest wskazywanie luk w zabezpieczeniach . Ostatnio wiele dużych firm wzmocniło swoją infrastrukturę cyberbezpieczeństwa. Potrzebny jest znaczny kapitał, aby sformułować nowe strategie w celu ułatwienia postępu technologicznego w zakresie bezpieczeństwa w technologii informacyjnej (IT), aby ograniczyć ryzyko i wpływ cyberataków. Bezpieczeństwo cybernetyczne jest uważane przez większość organizacji przede wszystkim za problem technologiczny. Chociaż są one wyczulone na zagrożenia i skutki dla ich działalności/działania, organizacje zwykle nie ujawniają żadnych luk w zabezpieczeniach . Większość dużych firm znacznie wzmocniła swoje możliwości w zakresie cyberbezpieczeństwa w ostatnich latach. Ogromne inwestycje są przeznaczane na rozwój nowych strategii wraz z rozwojem technologicznym w zakresie bezpieczeństwa technologii informatycznych (IT), aby zmniejszyć ryzyko cyberataku. Według financesonline.com, sektor rządowy ma najwyższe wydatki na cyberbezpieczeństwo z 11,9% w 2019 r. Za nim plasuje się firma telekomunikacyjna z 11,8% i branże z 11,0%. Na podstawie analizy przeprowadzonej przez roadbandsearch.net szacuje się, że światowy rynek cyberbezpieczeństwa osiągnie w 2019 r. 167 miliardów dolarów. Wraz z zaawansowaną erą cyfrową i wpływem cyberataków przewiduje się, że rynek cyberbezpieczeństwa będzie jedną z lukratywnych branż w nadchodzących latach .
Wstęp
Przemysł 4.0 to szeroki parasol technologii, w których szeroko wykorzystuje się automatyzację, robotykę, sztuczną inteligencję, Internet rzeczy (IoT), systemy gromadzenia danych, czujniki, zaawansowaną inżynierię i precyzyjne sterowanie komputerowe. Wykorzystując jeden lub więcej systemów, produkcja przemysłowa może zostać przekształcona za pomocą technologii cyfrowej zapewniającej lepszą wydajność i zrównoważony rozwój. Niemniej jednak transformacja cyfrowa niesie ze sobą znaczne narażenie na zagrożenia bezpieczeństwa cybernetycznego. W następnej sekcji znajduje się krótka dyskusja na temat dominujących wyzwań wpływających na bezpieczeństwo. Ponadto omawiane są przyszłe wyzwania i rozwój technologiczny.
Najnowsze trendy
Serwery WWW
Duża część ataków cybernetycznych jest wymierzana w organizacyjne serwery internetowe, ponieważ maszyny te przechowują i hostują poufne dane. Cyberprzestępcy bardzo często atakują serwery, ponieważ dane mogą zostać skradzione lub złośliwy kod może zostać wstrzyknięty do sieci. Zazwyczaj złośliwy kod dostaje się do serwera organizacji za pomocą legalnych serwerów internetowych, które przejęli przestępcy. Kradzież danych to bardzo istotny problem, ponieważ media szybko angażują się w sprawy związane z kradzieżą danych. Z tych powodów należy zwrócić szczególną uwagę na opracowanie bezpieczniejszych narzędzi i systemów wykrywania ataków, które mogą chronić serwery i zapobiegać potencjalnym atakom.
Przetwarzanie w chmurze
Zastosowanie chmury obliczeniowej znacznie wzrosło. Coraz więcej firm migruje do chmury, aby świadczyć usługi lub przechowywać dane. Istnieje wyraźna tendencja do pojawiania się chmury obliczeniowej. Ten najnowszy trend stanowi kolejne ogromne wyzwanie dla bezpieczeństwa cybernetycznego, ponieważ ruch może omijać tradycyjne punkty kontroli. Dodatkowo, wraz ze wzrostem liczby aplikacji dostępnych w chmurze, kontrola zasad dla aplikacji internetowych i usług w chmurze również będzie musiała ewoluować, aby zapobiec utracie cennych informacji. Ponieważ technologia i usługi w chmurze mogą zapewniać ogromne możliwości, ważne jest skuteczne radzenie sobie z zagrożeniami cybernetycznymi, które w coraz większym stopniu dotyczą środowiska chmury.
Zaawansowane trwałe zagrożenie
Wśród kilku typów ataków, zaawansowane trwałe zagrożenie (APT) odnosi się do ataku, w którym jedna lub więcej osób tworzy długotrwałą, ale nielegalną obecność w celu wydobycia poufnych informacji z tej sieci . Osoby atakujące muszą pozostać niepozorne lub niewykrywalne przez dłuższy czas, aby atakować systemy za pomocą APT. Chociaż jednym z aspektów ataku jest natychmiastowy zysk pieniężny, APT wykraczają poza początkowe cele i przez długi czas zagrażają systemom. Cyberprzestępcy stosują coraz bardziej niejasne i wyrafinowane techniki w celu skompromitowania sieci; w związku z tym usługi bezpieczeństwa muszą nadążyć lub wyprzedzić atakujących, aby wykryć obecne i potencjalne przyszłe zagrożenia.
Inteligentne telefony komórkowe
Technologia mobilna znacznie się rozwinęła, a smartfon jest obecnie platformą, która zapewnia wygodny dostęp do informacji i usług. Niemniej jednak zwiększona dostępność informacji w ekosystemie smartfonów sprawiła, że sieć ta stała się celem cyberataków. Ryzyko narażenia na cyber-zagrożenia są większe, ponieważ smartfon jest używany do zadań osobistych, takich jak przeglądanie mediów społecznościowych, komunikacja e-mail i transakcje finansowe za pośrednictwem telefonu. Rosnąca popularność smartfona doprowadziła do tego, że liczni napastnicy atakują ten system. Ze względu na bardzo dynamiczny charakter technologii bezpieczeństwo w domenie mobilnej powinno być również egzekwowane jako kultura.
Nowy protokół internetowy
Protokół internetowy (IP) to zestaw reguł, który umożliwia urządzeniom identyfikowanie innych urządzeń i łączenie się z nimi. IPv6 to najnowsza wersja protokołu, stanowiąca szkielet sieci komercyjnych i dużej części Internetu. IPv6 zastępuje poprzednią wersję IPv4 i ostatecznie zastąpi IPv4, aby stać się domyślnym protokołem w warstwie sieci. IPv6 ułatwia przekazywanie ruchu typu end-to-end przez interfejsy sieciowe. Adopcja IPv6 jest następstwem zwiększonego zapotrzebowania na przestrzeń adresową do łączenia masowego napływu urządzeń. Ponadto IPv6 oferuje zaawansowane zabezpieczenia, zmniejsza obciążenie routerów i oferuje przepisy dotyczące egzekwowania jakości usług (QoS).
Szyfrowanie kodu
Szyfrowanie to proces stosowany do bezpieczeństwa danych, w którym informacje są przekształcane za pomocą tajnego klucza do nieczytelnego formatu. Szyfrowanie jest jednym z najlepszych sposobów zapewnienia bezpieczeństwa danych. Szyfrowanie wymaga algorytmu do transformacji danych, który zazwyczaj jest zasilany kluczem szyfrowania definiującym sposób transformacji danych. Szyfrowanie zasadniczo chroni integralność danych i prywatność; jednak wysoce złożone szyfrowanie może powodować problemy dotyczące bezpieczeństwa cybernetycznego. Dane są również szyfrowane podczas przesyłania z jednego końca sieci na drugi (np. internet, mikrofon bezprzewodowy, telefony komórkowe, domofon). Szyfrowanie może pomóc w identyfikacji wycieku.
Inżynieria społeczna
Cyberprzestępcy mogą wykorzystywać socjotechnikę do oszukańczego manipulowania osobami i wydobywania poufnych informacji. Inżynieria społeczna opiera się bardziej na hakowaniu ludzkiej psychologii niż technologii. Ataki oparte na technologii wykorzystują złośliwe oprogramowanie, aby bezprawnie uzyskać dostęp do danych, systemów i całych budynków. Jedną z form ataku socjotechnicznego może być osoba podszywająca się pod legalnego pracownika firmy (np. banków, klubów, e-commerce) i nakłonić użytkownika do podania przez telefon poufnych danych, takich jak hasło lub numer karty kredytowej. Podobnie osoby atakujące mogą wykorzystać podszywanie się pod inne osoby, aby ułatwić wejście do budynków zabezpieczonych elektronicznymi systemami wejściowymi. Takiego wpisu można dokonać za pomocą skradzionych haseł, kodów dostępu itp.
Exploity w mediach społecznościowych
W odniesieniu do wcześniejszej sekcji rosnące wykorzystanie mediów społecznościowych doprowadziłoby do osobistych zagrożeń cybernetycznych. Poparcie mediów społecznościowych wśród organizacji gwałtownie rośnie wraz z ryzykiem ataku. Wraz z radykalnym postępem na różnych platformach, biznes może spodziewać się wzrostu liczby profili w mediach społecznościowych wykorzystywanych jako droga do strategii inżynierii społecznej. Na przykład osoby atakujące mogą odwiedzać witryny internetowe, takie jak LinkedIn, aby wykryć wszystkich użytkowników pracujących w firmie i zebrać wiele danych osobowych w celu wymyślenia ataku. Ostatnio niektóre portale społecznościowe, takie jak Yandex z siedzibą w Rosji, umożliwiają zwykłym użytkownikom wyszukiwanie informacji o danej osobie, takich jak konto w mediach społecznościowych, po prostu przesyłając zdjęcie twarzy danej osoby. Aby poradzić sobie z takimi zagrożeniami, firmy musiałyby wykroczyć poza podstawy rozwoju polityki i procesów w kierunku bardziej innowacyjnych technologii, takich jak zapobieganie wyciekom danych, ulepszone monitorowanie sieci i analiza plików dziennika. Szkolenie pracowników w zakresie świadomości bezpieczeństwa jest również skutecznym środkiem odstraszania od socjotechniki.
Atak złej uniwersalnej magistrali szeregowej (USB)
Złe USB jest również uważane za złośliwy atak USB, w którym proste urządzenie USB (tj. pendrive USB) może zostać przekształcone przez atakujących w klawiaturę, aby użyć tych urządzeń do wpisywania złośliwych poleceń i przejęcia kontroli nad komputerem ofiary. Jest to nowy rodzaj metody ataku, o której po raz pierwszy wspomniał badacz bezpieczeństwa Karsten Nohl na konferencji Black Hat w 2014 r., a kod ataku został udostępniony w interesie publicznym. Podstawową zasadą ataku było zastosowanie inżynierii wstecznej w oprogramowaniu mikrokontrolerów USB, a tym samym oprogramowanie zostało przeprogramowane, aby urządzenie USB mogło imitować funkcje klawiatury. Jak to ,że atak został przeprowadzony na poziomie oprogramowania układowego, przechowywanie szkodliwego programu może również odbywać się w zapisywalnym kodzie na podstawowym poziomie wejścia/wyjścia USB (I/O), w którym nawet jeśli cała zawartość pamięci flash USB zostanie usunięta, nie miałby żadnego wpływu. Sugeruje to, że złośliwe oprogramowanie jest w zasadzie niezdatne do łatania. Dlatego trudno jest uniknąć takiego ataku ze względu na zaangażowanie socjotechniki. Na przykład urządzenie USB można łatwo uzyskać za jednorazową cenę.
Atak na system z luką powietrzną
W kontekście bezpieczeństwa cybernetycznego, luka powietrzna może oznaczać środek bezpieczeństwa sieci, który umożliwia oddzielenie sieci lub komputera od dowolnego zewnętrznego połączenia internetowego. Zasadniczo, ponieważ komputer z luką powietrzną nie ma interfejsów sieciowych, dozwolona jest tylko bezpośrednia kontrola fizyczna. Systemy komputerowe służą do zabezpieczania różnego rodzaju systemów o znaczeniu krytycznym, np. obrona wojskowa, giełda, a także systemy wykorzystywane do kontroli infrastruktury krytycznej, takiej jak elektrownie jądrowe. Jeśli zapewnimy, że kopie zapasowe danych są pozbawione powietrza, ułatwi to przywracanie systemu w przypadku awarii systemu. Zazwyczaj pomiędzy systemem komputerowym z pustką powietrzną a ścianami zewnętrznymi, a także między jego przewodami a przewodami innych urządzeń technicznych, ustawiana jest określona ilość miejsca, aby uniknąć nieautoryzowanego dostępu do komputera lub potencjalnego włamania za pomocą luk elektromagnetycznych lub elektronicznych. Chociaż systemy z pustką powietrzną mogą wydawać się całkowicie zabezpieczone, ale te systemy mają również wady. Jak wynika z ostatnich badań nad cyberbezpieczeństwem, exploity można wdrażać za pomocą specjalistycznego sprzętu do przechwytywania sygnałów telekomunikacyjnych emitowanych przez komputer z luką powietrzną, takich jak naciśnięcia klawiszy lub obrazy na ekranie, z fal zdemodulowanego promieniowania elektromagnetycznego (EMR). Jak wynika z innego badania naukowego, eksploatacja izolowanych komputerów może odbywać się również za pośrednictwem zainfekowanej karty dźwiękowej, która emituje fale EMR. Informacje można również zbierać z izolowanych klawiatur, ekranów i innych elementów komputera, stosując ciągłe napromienianie falami EMR. Do ataku na taki system można również wykorzystać socjotechnikę. Robak Stuxnet, złośliwe oprogramowanie atakujące konkretny przemysłowy system kontroli, to niesławny przykład, który prawdopodobnie został przeniesiony za pośrednictwem zainfekowanych pamięci USB od pracowników lub rozprowadzany jako darmowe prezenty.
Technologie rozwiązań bezpieczeństwa cybernetycznego
Ustanowienie cyberbezpieczeństwa może pomóc w unikaniu naruszeń danych, cyberataków i kradzieży tożsamości, a także pomóc w zarządzaniu ryzykiem. Przez lata rozwijano różne najnowocześniejsze technologie, aby zminimalizować ryzyko ataków cybernetycznych, a niewiele z nich opisano w kolejnych sekcjach.
Skanery podatności
Skaner podatności można zdefiniować jako narzędzie bezpieczeństwa wykorzystywane do oceny bezpieczeństwa aplikacji, serwera lub sieci. Zasadniczo skaner podatności może być postrzegany jako narzędzie, które może również myśleć tak, jak zrobiłby to haker. Ocenia cel w podobny sposób jak haker, tj. identyfikuje słabości lub podatności. Skanery aplikacji internetowych można zdefiniować jako zautomatyzowane narzędzia, które jako pierwsze przemierzają aplikację internetową, a następnie skanują jej strony internetowe w celu znalezienia luk w zabezpieczeniach, które mogą istnieć w aplikacji, wykorzystując technikę pasywną. W tym przypadku dane wejściowe sondy są generowane przez skanery, po czym odpowiedź jest porównywana z takimi danymi wejściowymi w celu zidentyfikowania luk w zabezpieczeniach .
System zapobiegania włamaniom
System zapobiegania włamaniom (IPS) może być urządzeniem programowym lub sprzętowym, które posiada wszystkie funkcje systemu wykrywania włamań (IDS). W niektórych przypadkach IPS umożliwia również zapobieganie ewentualnym incydentom. IPS może reagować na wykryte zagrożenie na wiele sposobów:
1. aby zablokować przyszłe ataki, umożliwia rekonfigurację innych kontroli bezpieczeństwa w systemach, takich jak firewall lub router;
2. w ruchu sieciowym złośliwa zawartość może zostać usunięta z ataku w celu odfiltrowania zagrażających pakietów; lub
3. Inne mechanizmy kontroli bezpieczeństwa i prywatności w ustawieniach przeglądarki mogą również zostać ponownie skonfigurowane, aby uniknąć przyszłych ataków.
System wykrywania włamań
Specjalistyczne narzędzie o nazwie Intrusion Detection System (IDS) posiada możliwość odczytywania i interpretowania treści dotyczących plików logów z serwerów, zapór sieciowych, routerów oraz innych urządzeń sieciowych. IDS ma również możliwość utrzymywania bazy danych zawierającej informacje o znanych sygnaturach ataków. Umożliwia to porównanie różnych wzorców ruchu, aktywności lub zachowania, a także szybkie sprawdzanie dzienników pod kątem monitorowania pod kątem takich sygnatur w celu zidentyfikowania ścisłego dopasowania między sygnaturą a ostatnim lub bieżącym zachowaniem. Po ustanowieniu dopasowania system może generować alerty lub alarmy, uruchamiając różne rodzaje automatycznych działań, takich jak zamknięcie łączy internetowych lub określonych serwerów, a także uruchamianie śledzenia wstecznego. Może również podejmować inne aktywne próby rozpoznania napastników, a także aktywnie gromadzić dowody dotyczące ich nikczemnych działań.
Wyzwania
Problemy z cyberbezpieczeństwem mogą wiązać się z wieloma wyzwaniami dla interesariuszy, takich jak firmy biznesowe, firmy i użytkownicy końcowi. Według nas wyzwania związane z Przemysłem 4.0 można opisać jako trzy główne aspekty: zarządzanie ryzykiem cyberbezpieczeństwa, prywatność użytkowników oraz kryminalistyka cyfrowa. Poniższe sekcje wyczerpująco wyjaśnią każde wyzwanie.
Prywatność użytkownika
W kontekście zastosowania Przemysłu 4.0 jedną z zasad jest oferowanie zorientowanych na klienta, wysoce spersonalizowanych usług wysokiej jakości, które odpowiadają jego konkretnym potrzebom. Zwykle sugeruje to, że gromadzenie danych o użytkowaniu jest powszechne, co może stanowić warunek wstępny przed próbą dostosowania. Typowym powszechnym przykładem jest instalacja aplikacji w telefonach komórkowych, w której użytkownicy muszą do pewnego stopnia wyrazić zgodę na korzystanie z określonych funkcji telefonu w celu gromadzenia danych - na przykład dostęp do danych z kamery, dostęp do mikrofonu, dane dotyczące cech twarzy , dostęp do danych odcisków palców, a nawet dostęp do plików systemowych, wszystko to pozwala aplikacji działać jak najlepiej. Chociaż dane gromadzone za pomocą takich środków mają głównie na celu zapewnienie lepszych, spersonalizowanych doświadczeń, użytkownicy mogą nie zawsze wiedzieć, co aplikacja może faktycznie zrobić. Zwykle przesyłanie tych spersonalizowanych danych odbywa się na centralny serwer, na którym firma dostarczająca aplikację prowadziłaby również pewne analizy, biorąc pod uwagę informacje o profilu użytkownika, raporty o awariach, statystyki użytkowania itp. W tym kontekście użytkownicy mogą udzielili dostępu do danych osobowych nieświadomie. Nawet jeśli użytkownik ma wiedzę i rozumie potencjalne ryzyko, niechętnie udzieliłby dostępu, aby w pełni korzystać z aplikacji. Taka praktyka z pewnością stanowi zagrożenie dla prywatności użytkowników w postaci wielu rodzajów kradzieży danych użytkownika, a także cyfrowego nadzoru. W przypadku tych pierwszych kradzież danych jest możliwa z powodu ataków na serwer WWW. Zazwyczaj cyberprzestępcy mogą wykraść cenne dane osobowe, tj. osobiste dane identyfikacyjne, numery ubezpieczenia społecznego, informacje o kartach kredytowych lub płatnościach oraz adresy z zaatakowanych serwerów internetowych. Po przeprowadzeniu udanej operacji kradzieży danych takie zebrane informacje mogą zostać ujawnione w domenie publicznej lub sprzedane zainteresowanym stronom z różnych powodów, takich jak marketing internetowy lub oszustwa. Wspomniany kontekst przedstawia również kompromis między zachowaniem prywatności użytkownika a zapewnieniem wysoce spersonalizowanej, wysokiej jakości obsługi klienta. Firmy potrzebują danych, aby przeprowadzać analizy klientów i dostosowywać się, aby świadczyć usługi lepszej jakości. Jednak klienci coraz częściej borykają się z obawami o prywatność użytkowników, co spowodowało ciągły problem z wdrożeniem biznesowym. Po licznych wyciekach danych zgłoszonych przez znane serwisy internetowe, takie jak Yahoo, Facebook i Marriot International, klienci w dzisiejszych czasach stają się bardziej świadomi potencjalnych pułapek, gdy udostępniają dane osobowe w domenie publicznej. Stwarza to ograniczenia dla przedsiębiorstw i firm przy podejmowaniu decyzji, w jaki sposób można uniknąć nadmiernego gromadzenia danych osobowych, przy jednoczesnym utrzymaniu jakości ich usług. Z punktu widzenia użytkowników obawiają się również, jak takie zagrożenie wykryć i jak powinni zareagować w obliczu takiego zagrożenia. Istnieje kilka sposobów rozwiązania tego problemu. Po pierwsze, należy zapewnić użytkownikom edukację dotyczącą ryzyka, jakie niesie ze sobą udostępnianie danych osobowych. W dzisiejszych czasach firmy usługowe mają łatwy dostęp do cyfrowych danych klientów, m.in. polubienia i udostępnienia, publikowanie, rejestracja zakupów i lokalizacja za pośrednictwem aplikacji, takich jak strony internetowe zakupów online i media społecznościowe. Ponieważ użytkownicy zazwyczaj muszą wyrazić zgodę na wykorzystanie ich danych osobowych w celu uruchomienia tej aplikacji, muszą być czujni w odniesieniu do tego, co udostępniają online. Ponieważ te cyfrowe zapisy mogą być na stałe przechowywane w silosach danych, muszą zdać sobie sprawę, że to, co zamierzają udostępnić, może być również przeglądane przez każdego, a informacje pozostaną na stałe w Internecie. Muszą również zostać wyedukowani, jak zachować czujność przed zainstalowaniem jakiejkolwiek aplikacji na swoim cyfrowym Po drugie, dostawcy usług muszą przestrzegać pewnych standardów dotyczących wdrażania polityki prywatności. Na przykład serwisy internetowe wykorzystują pliki cookie, które umożliwiają im przechowywanie, śledzenie i udostępnianie zachowań użytkowników, a także stanowią potencjalne zagrożenie dla prywatności. Firmy muszą ustalić jasną politykę dotyczącą wykorzystywania plików cookie, aby uniknąć nadmiernego wycieku informacji związanych z użytkownikami. Muszą na przykład przestrzegać najnowszych obowiązujących standardów, takich jak europejskie ogólne rozporządzenie o ochronie danych (RODO) , które podjęło próbę ustalenia najlepszych praktyk, których należy przestrzegać, aby poprawić prawa do prywatności, a także egzekwować ochronę konsumentów. Chociaż regulacje takie jak te są uważane za kłopotliwe we wdrażaniu i mogą nawet zmienić sposób prowadzenia działalności przez firmy, mogą być również postrzegane jako forma zapewnienia klientów w celu zapewnienia, że ich prywatność jest traktowana priorytetowo i chroniona podczas Dostawa usługi. Pomaga to również zwiększyć zaufanie klientów i zachować ich lojalność, ponieważ firmy przechowują przejrzyste informacje dotyczące sposobu wykorzystywania ich danych osobowych, a także zapewniają wyjaśnienia dotyczące projektu i praktyki, które umożliwiają zarządzanie danymi klientów ujawnianymi w całej usłudze koła życia.
Zarządzanie ryzykiem cyberbezpieczeństwa
Cyberbezpieczeństwo jest ogólnie uważane za wysoce wyspecjalizowaną dziedzinę, a zatem mniejsze firmy i osoby prywatne uważają, że zdobycie niezbędnej wiedzy i umiejętności, aby chronić je przed cyberatakiem, jest trudne. Często mniejsze organizacje mają ograniczone zasoby finansowe lub ludzkie do obsługi cyberbezpieczeństwa. Kierownictwo wyższego szczebla firmy często nie do końca rozumie potrzebę/priorytet i ma tendencję do pomijania zagrożeń związanych z cyberbezpieczeństwem. W rzeczywistości firmy te często zlecają swoje usługi IT firmom zewnętrznym, ponieważ uważają, że są bardziej zdolne, a teraz stało się to trendem. W związku z tym obawy związane z bezpieczeństwem cybernetycznym są pomijane, ponieważ mają tendencję do myślenia, że to złagodziło ich ryzyko. Trudna prawda jest taka, że firmy, generalnie małe lub średnie przedsiębiorstwa (MŚP), które zwykle zlecają swoje usługi IT na zewnątrz, współpracują z firmami świadczącymi usługi IT, które z kolei są MŚP lub organizacjami typu start-up z ograniczonym doświadczeniem w zakresie dobrych praktyk w zakresie bezpieczeństwa cybernetycznego. Na przykład, ponieważ istnieją ograniczenia zasobów, ciężar obsługi obowiązków związanych z cyberbezpieczeństwem spada na personel IT w ramach obowiązków i zadań. W świetle najlepszych praktyk w zakresie bezpieczeństwa cybernetycznego, należy zniechęcać do takiego delegowania, próbując jednocześnie rozdzielać obowiązki. Niespełnienie takiego wymogu może mieć poważne konsekwencje. Na przykład w 2012 roku w Malezji miał miejsce niesławny przypadek włamania się do usług hostingu w chmurze exabytes.my, w którym usunięto wiele maszyn wirtualnych (dla usług w chmurze). Atak przeprowadził pracownik organizacji, który został już zakończony, ale dane logowania do systemu nie zostały zmienione i nadal były ważne. Z powodu tego incydentu firma poniosła nieodwracalne szkody, w których tylko ~80% danych klientów można było odzyskać ze starych kopii zapasowych, podczas gdy pozostałe dane klienta zostały trwale utracone. Takiego incydentu można było łatwo uniknąć, gdyby firma bardziej rygorystycznie przestrzegała standardów bezpieczeństwa cybernetycznego oraz najlepszych praktyk. W epoce, w której firmy dążą do cyfrowej transformacji swoich usług, zarządzanie ryzykiem i świadomość bezpieczeństwa cybernetycznego stały się ważniejszą kwestią, którą należy się zająć. Na podstawie tej liczby zagrożenie działa na podatność zasobu, co skutkuje wpływem. Gdy istnieje motywacja ataku, wraz z podatnością na ataki, daje to szansę na zrealizowanie zagrożenia. Następnie wpływy i prawdopodobieństwo łączą się w ryzyko plonów. Procedura oceny ryzyka zazwyczaj obejmuje pięć kroków, jak pokazano w: ustalaniu kontekstu, identyfikacji ryzyka, analizie ryzyka, ocenie ryzyka i postępowaniu z ryzykiem. Obejmuje praktyczne kroki dotyczące całego procesu zarządzania ryzykiem na arenie cyberbezpieczeństwa, co również pomaga organizacjom chronić ich zasoby danych.
Cyfrowa kryminalistyka
Cyfrową kryminalistykę można zdefiniować jako gałąź kryminalistyki, która zajmuje się procesem identyfikacji, utrwalania, wydobywania, a także dokumentacją dowodów komputerowych, które sąd może wykorzystać w sprawach. Pod względem bezpieczeństwa cybernetycznego uważa się, że jest to proces odzyskiwania dowodów, który wyodrębnia się z mediów cyfrowych, takich jak telefon komórkowy, komputer, sieć lub serwer WWW, a także proces weryfikacji, który ma na celu zebranie dowodów po cyberataku. Wraz z rosnącą liczbą aplikacji Przemysłu 4.0 przewidywanych w najbliższej przyszłości, stało się to znaczącym obszarem, który przyciągnął wiele uwagi w ostatnich latach. Praktyka cyberbezpieczeństwa jest uzupełniana przez kryminalistykę cyfrową w celu zapewnienia bezpieczeństwa i integralność systemów i operacji obliczeniowych, ponieważ umożliwia przetwarzanie, wydobywanie i interpretację dowodów faktycznych za pośrednictwem skompromitowanych systemów informatycznych w celu ustalenia przed sądem działań cyberprzestępczych. Ogólnie rzecz biorąc, kryminalistyka cyfrowa obejmuje pięć podstawowych etapów: (1) identyfikacji, (2) konserwacji, (3) analizy, (4) dokumentacji i (5) prezentacji. W pierwszym kroku identyfikowany jest cel śledztwa i zasoby potrzebne do zadania kryminalistycznego, po czym dane odzyskane z nośników cyfrowych są izolowane, konserwowane i zabezpieczane. W trzecim kroku pobrane dane są analizowane, co wiąże się z wykorzystaniem odpowiednich narzędzi i technik oraz interpretacją wyników analizy danych. Następnie, na podstawie analizowanych wyników, dokumentowane jest miejsce przestępstwa oraz wykonywane jest szkicowanie, fotografowanie i mapowanie miejsca przestępstwa. W ostatnim kroku przedstawiane jest wyjaśnienie podsumowania wyników oraz wnioski. W dzisiejszych czasach dziedzina kryminalistyki cyfrowej stała się bardziej skomplikowana i trudniejsza z powodu pojawienia się tanich urządzeń komputerowych z dostępem do Internetu (np. urządzeń IoT), szybko zmieniających się aplikacji technologii obliczeniowych każdego roku i łatwa dostępność narzędzi hakerskich. Wszystko to wpływa na najlepsze praktyki w tej dziedzinie, ponieważ specjaliści medycyny sądowej muszą często aktualizować swoją wiedzę i umiejętności, aby nadążyć za bardziej wyrafinowanymi cybereksploitami. Ponieważ firmy zaczęły niedawno wdrażać zarządzanie ryzykiem cyberbezpieczeństwa, kryminalistyka cyfrowa jest uważana za nowy aspekt, o którym firmy mogą myśleć, aby stać się zrównoważonym wraz z nadejściem ery Przemysłu 4.0, a także zapewnić nieprzerwane prowadzenie działalności biznesowej .
Wnioski
Przemysł 4.0 przyniósł innowacyjną erę, która jest dobrze skomunikowana, ma responsywne sieci dostaw i umożliwia inteligentną produkcję, co usprawnia proces produkcji i usługi. Nawet jeśli możliwości cyfrowe zostały znacznie ulepszone w całym łańcuchu dostaw i procesach produkcyjnych, zwiększyło to również ryzyko cyberzagrożeń, a branża mogła nie być w pełni przygotowana. Ponieważ ekspansja wektorów zagrożeń była raczej radykalna wraz z nadejściem Przemysłu 4.0, cyberbezpieczeństwo powinno stanowić istotną część strategii, działania i projektowania oraz być brane pod uwagę od początku każdego nowego urządzenia/aplikacji połączonej z przemysłem Inicjatywa napędzana 4.0.
Rola IIoT w smart Industries 4.0
Wzrost gospodarczy jest kręgosłupem każdego kraju, związanym głównie z energetyką przemysłową, produkcją i wydajnością. Branże zmieniają się od staroświeckich do nowych perspektyw technologicznych z wymaganiami nowej ery. Branże w pełni wyposażone w technologię znane są jako przemysł inteligentny. Przemysłowy Internet Rzeczy (IIoT) jest źródłem, które przekształca zwykłe branże w inteligentne branże, zapewniając im cięcie kosztów, zdalny dostęp, zarządzanie produkcją, łańcuch dostaw i monitorowanie, a także zmniejszenie kosztów zużycia energii itp. IIoT przynosi rewolucję w branży, aby tanio zwiększyć produkcję i umożliwić przemysłowi zdalny dostęp do danych i udostępnianie ich. Inteligentny przemysł lub Przemysł 4.0 (I4.0) to nowy paradygmat, który przyniósł rewolucję w całej branży produkcyjnej i produkcyjnej. Obecnie wiele branż przekształca się w branże inteligentne, podczas gdy reszta znajduje się w fazie konwergencji. W tym rozdziale książki szczegółowo omówimy istniejący stan wiedzy w zakresie IIoT, różne zastosowania IIoT, przypadki użycia, otwarte zagadnienia i wyzwania badawcze, a także przyszłe kierunki i aspekty inteligentnego przemysłu. Ponadto w tym rozdziale omówimy silne powiązanie między Internetem rzeczy (IoT), IIoT i inteligentnymi branżami.
Wstęp
IoT odgrywa istotną rolę w kilku domenach aplikacji. Cieszy się bardzo dużym zainteresowaniem ze względu na łatwość konfiguracji i wdrożenia, a także zapewnienie większego dostępu do różnych aplikacji życia. IoT jest dalej rozwijany, aby zapewnić kilka rozwiązań dla przemysłu, które są znane jako Industrial IoT (IIoT). W tej części rozdziału pokrótce przedstawimy IoT w różnych aspektach, takich jak to, co dokładnie oznacza IoT, podróż IoT w kierunku IIoT do I4.0, znanego również jako ewolucja przemysłowa, i wreszcie wyjaśnienie różnic między IoT i IIoT.
Co oznacza Internet Rzeczy?
Koncepcja życia mądrego i łatwego, w którym większość rutynowej pracy może być wykonana lub wspomagana inteligentnie w odpowiednim czasie, co wcześniej nie było możliwe. Na przykład marzeniem było wiedzieć o swoim domu lub biurze i zdalnie sterować różnymi urządzeniami w domu lub biurze. Wszystko to stało się możliwe dzięki koncepcji inteligentnego domu, w którym można zdalnie sterować i monitorować wszystkie pożądane przedmioty z dowolnego miejsca na świecie. IoT jest tym, co napędza inteligentny dom, aby był inteligentny. Jednocześnie marzenie o monitorowaniu i kontrolowaniu otoczenia poza domem i biurem, takie jak wiadomości o informacjach o trasie, informacje o wypadku na trasie, połączenia z nagłośnieniem samochodu, wyświetlanie obliczonych map drogowych itp. To wszystko stało się możliwe w oparciu o IoT. W ten sam sposób IoT jest używany w większości naszych codziennych zastosowań. Można uzyskać bardzo jasne wyobrażenie o wpływie aplikacji IoT używanych na co dzień, odwołując się do aplikacji.
Podróż IoT przez IIoT do Przemysłu 4.0
Termin IoT został wprowadzony przez Kevina Ashtona w 1999 roku. Jego pierwotnym pomysłem było podłączenie fizycznych obiektów do sieci lub popularnie zwanej Internetem. Ten pomysł przyniósł rewolucję, a świat informatyki został całkowicie zmieniony dzięki integracji różnych czujników z różnymi obiektami. Obiekty zaczęły komunikować się z internetem poprzez wykrywanie i przekazywanie informacji do sieci. Ta rewolucja nie wymaga więcej umiejętności programowania i innych formalnych obliczeń, które zwykle są wymagane do programowania. Komunikujące się obiekty znane są później jako inteligentny obiekt, a następnie koncepcja przeszła w kierunku koncepcji inteligentnego domu, w której większość obiektów w domu może łatwo komunikować się i łączyć z Internetem. Później ekspansja tego pomysłu rozkwitła dzięki zastosowaniu GPS, inteligentnych samochodów, monitorowania kondycji i aplikacji e-zdrowia; w ten sposób IoT ewoluował, aby stać się liderem koncepcji następnej rewolucji przemysłowej, znanej jako IIoT.
Różnica między IoT a IIoT?
IoT jest źródłem inteligentnego środowiska, o którym wspomniano we wcześniejszych sekcjach, które umożliwia obiektom komunikowanie się z innymi obiektami za pomocą różnego rodzaju czujników podłączonych do niego. Dołączone czujniki umożliwiają obiektowi przekazywanie informacji do innych komponentów, a także udostępnianie danych w Internecie. Prawdziwą różnicą między IoT a IIoT jest obszar operacyjny lub zakres aplikacji; gdy Internet Rzeczy zostanie udostępniony branży na dużą skalę i rozwiąże problemy branżowe, takie jak produkcja, zarządzanie łańcuchem dostaw, produkcja itp., będzie on określany jako IIoT. IIoT wnosi cuda do branży, gdzie branża może być monitorowana i kontrolowana zdalnie na szerszą skalę. Zwiększyło to postęp branży na dużą skalę we wszystkich sektorach. Jednak obecnie IIoT nie jest w pełni wdrożony, ale ma coraz większy zakres. Większość krajów już wdrożyła IIoT i uczyniła swoje branże inteligentnymi I4.0, podczas gdy inne szybko podążają za inteligentnymi celami branżowymi. Pojawienie się IoT mogą sobie wyobrazić naukowcy, którzy spodziewają się tego do 2020 r.; Liczba urządzeń IoT będzie na całym świecie ponad 50 miliardów, czyli prawie siedmiokrotnie więcej niż populacja świata
Przegląd IoT w smart Industrial 4.0
IoT odgrywa istotną rolę w kilku domenach aplikacji. Cieszy się bardzo dużym zainteresowaniem ze względu na łatwość konfiguracji i wdrożenia, a także szeroki dostęp do różnych aplikacji życiowych. IoT został rozszerzony, aby zapewnić kilka rozwiązań dla przemysłu, które są znane jako Industrial IoT (IIoT). W tej części pokrótce przedstawimy IoT w jego różnych aspektach, takich jak to, co dokładnie oznacza IoT, podróż IoT w kierunku IIoT do I4.0, który jest również znany jako ewolucja przemysłowa, i wreszcie różnica między IoT i IIoT na lepsze zrozumienie czytelników. Na początku dziewiętnastego wieku angielscy robotnicy, zwani luddytami, byli przeciwni zmianom technologicznym i w ramach protestu atakowali fabryki i niszczyli maszyny. Działanie to nie tylko nie zatrzymało postępu technologicznego, ale także przyspieszyła trend. Od XVIII wieku, który był początkiem wynalezienia narzędzi mechanicznych umożliwiających wykorzystanie energii cieplnej i kinetycznej, rozwój segmentu przemysłowego zmienił nasze życie. Kolejne wynalazki były częścią pierwszej rewolucji przemysłowej. Później wynalazki do połowy XIX wieku, a zwłaszcza rozwój elektrycznego systemu produkcji technologicznej, złożyły się na drugą rewolucję przemysłową, która przekształciła cały przemysł poprzez umożliwienie produkcji masowej. Wykorzystanie programowalnego sterownika logicznego (PLC) w roku 1969 umożliwiło ludziom współpracę między technologią informatyczną a elektroniką, przyspieszając rozwój automatyki przemysłowej, który trwa do dziś. Ta ewolucja znana jest jako trzecia rewolucja przemysłowa. Obecnie firmy produkcyjne stoją przed innowacyjnymi wyzwaniami, takimi jak ograniczony cykl życia innowacji i technologii oraz zapotrzebowanie na niestandardowe produkty kosztem produkcji na dużą skalę. Te wymagania były dobrymi receptami na narodziny nowej rewolucji przemysłowej o nazwie IoT. IoT jako idea istnieje już od dłuższego czasu, a terminologii tej po raz pierwszy użyto już w 1999 roku. Od początku istnienia Internetu myśli o komunikujących się ze sobą maszynach były dla wielu wizją. Jest to nowy proces, w którym urządzenia są połączone ze sobą za pomocą różnych protokołów komunikacyjnych bez konieczności interwencji człowieka. W dzisiejszych czasach automatyzacja staje się coraz bardziej powszechna zarówno w przemyśle, jak i w codziennym życiu ludzi. Duża część tego to zdolność przetwarzania w chmurze do przechowywania ogromnych danych, miniaturyzacja elektroniki o mniejszym zużyciu energii oraz protokół internetowy (IP) w wersji 6, pozwalający na wystarczającą liczbę adresów do zarejestrowania każdego wyobrażalnego urządzenia, z którym chciałoby się połączyć przez Internet . IoT rozszerzył się na świat produkcyjny, co skutkuje rewolucją produkcyjną o nazwie I4.0. To przyczyniło się do powstania wielu automatyzacji przemysłowej, która jest ogólnie określana jako IIoT. Rewolucja przemysłowa rozpoczęła się w Wielkiej Brytanii pod koniec XVIII wieku, kiedy produkcja odbywała się na ogół w domach ludzi przy użyciu podstawowych maszyn i narzędzi ręcznych, i trwała do czasów istniejących na platformie IIoT. Krótka historia rewolucji przemysłowej pomaga nam lepiej zrozumieć, jak rozwijał się przemysł w ciągu ostatnich trzech stuleci, który nadal rozwija się przez kolejne pokolenia. Pierwsza rewolucja przemysłowa miała miejsce pod koniec XVIII wieku, a głównym celem była produkcja mechaniczna. Na początku XX wieku pojawiła się rewolucja przemysłowa 2.0 i wkroczyła era elektroniki z możliwością produkcji masowej. Niecałe 50 lat temu wraz z wprowadzeniem sterownika PLC, który umożliwił automatyzację produkcji opartą na IT, rozpoczęła się trzecia rewolucja przemysłowa. Niedawno I4.0 został połączony z koncentracją na paradygmatach IoT i systemów cyber-fizycznych (CPS), aby analizować, monitorować i automatyzować procesy biznesowe w ogóle. Te rewolucje technologiczne przemodelują procesy montażu i dostaw w rozsądne środowiska fabryczne, co zwiększy wydajność i siłę działania. W tej dziedzinie firmy są w stanie zautomatyzować procesy w celu zapewnienia bezpieczeństwa, szybkości lub obniżenia kosztów łączenia maszyn i procesów, które wcześniej nie były w stanie się komunikować. IIoT ma prognozę rynkową zbliżoną do 100 miliardów dolarów do roku 2020, więc teraz przyciąga uwagę wszystkich. Rozwój tanich i szybkich czujników pomógł firmom zautomatyzować procesy bardziej wydajnie i przy minimalnych kosztach. W przeszłości do wizualnego śledzenia obiektu i przeprowadzania czasochłonnych kontroli potrzebnych było kilku pracowników. Teraz wizja maszynowa pozwala na inspekcje w czasie rzeczywistym z możliwością oddzielania materiałów uznanych za wadliwe. Wszystko to dzieje się bez interwencji człowieka. Niektóre miejsca posunęły się nawet do przemieszczania materiałów za pomocą autonomicznych pojazdów kierowanych bez obaw o bezpieczeństwo pracowników. Przyszła wizja zakładu produkcyjnego z minimalną siłą roboczą rośnie wraz z opracowywaniem i wdrażaniem robotów i innych technik automatyzacji w takich miejscach pracy. Zdolność do gromadzenia wszystkich tych danych w czasie rzeczywistym i automatycznego podejmowania decyzji przez maszyny jest prawdziwym duchem, który napędza rozwój IIoT. W tym zakresie system produkcyjny powinien być niezawodny, dostępny i zoptymalizowany pod kątem bezpieczeństwa aplikacji. IIoT to maszyna przemysłowa, która jest powiązana z obszarem przechowywania danych w chmurze przedsiębiorstwa zarówno w celu pobierania, jak i przechowywania danych. IIoT ma potencjał do dużych zmian w zarządzaniu globalnym łańcuchem dostaw. Podejście Lean Six Sigma w globalnym łańcuchu dostaw z wykorzystaniem IIoT i I4.0 tworzy idealny przebieg procesu, który jest doskonały i wysoce zoptymalizowany, co minimalizuje wady i straty. Podsumowując, inteligentna technologia produkcji, człowiek, maszyna i sam produkt łączą siły w niezależną i inteligentną sieć skupiającą się na opracowanie komponentu, systemu i rozwiązania, które dotyczy przemysłowej infrastruktury bazowej, rozwiązania automatyzacji, inteligentnego sterownika i funkcjonalnego bezpieczeństwa przed cyberatakami. Ta rewolucja produkcyjna zmienia ekonomię, zwiększa produktywność, sprzyja wzrostowi przemysłowemu i modyfikuje profil siły roboczej, co ostatecznie zmienia konkurencyjność firm i branż w każdym zakątku świata.
Najnowocześniejszy przemysłowy Internet Rzeczy
IIoT pojawił się jako nowy trend w ciągu ostatnich kilku lat, w którym kontinuum urządzeń i obiektów jest połączone z różnymi rozwiązaniami komunikacyjnymi, takimi jak Bluetooth, Wi-Fi, ZigBee, globalne systemy mobilne (GSM) itp. Te urządzenia komunikacyjne sterują i zdalnie wyczuł wszystkie urządzenia i obiekty, co daje więcej możliwości bezpośredniej integracji z urządzeniami zewnętrznymi za pośrednictwem systemów komputerowych w celu poprawy produkcji przemysłowej, takiej jak kontrola jakości, zrównoważone i ekologiczne praktyki. Przewiduje się, że miliardy urządzeń, takich jak czujniki, smartfony, laptopy i konsole do gier, będą połączone z Internetem za pośrednictwem wielu różnorodnych sieci dostępowych wyposażonych w technologie sieciowe, takie jak identyfikacja radiowa (RFID) i bezprzewodowe sieci czujników (WSN). IIoT jest znany w czterech różnych paradygmatach: zorientowane na Internet, inteligentne aktywa, czujniki, analityka i aplikacje [10]. Zwykle wdrożenie technologii IoT można zrozumieć bardzo
blisko współczesnego społeczeństwa, w którym inteligentne aktywa i rzeczy są wirtualnie zintegrowane, tworząc systemy, które mogą oferować monitorowanie, gromadzenie, wymianę i analizę danych, dostarczając cennych informacji, które umożliwiają firmom przemysłowym szybsze podejmowanie mądrzejszych decyzji biznesowych. Różne adaptacje technologii sieci bezprzewodowych sprawiły, że IIoT jest kolejną rewolucyjną technologią, wykorzystującą zalety technologii internetowej. Tymczasem sieci WSN obejmują dużą liczbę urządzeń z funkcjami wykrywania, łącznością bezprzewodową i ograniczonymi możliwościami przetwarzania, co pozwala na wdrażanie węzłów w pobliżu środowiska . WSN obsługuje miniaturowe, niskobudżetowe i energooszczędne urządzenia, które łączą od setek do tysięcy z jednym lub kilkoma czujnikami. Czujnik posiada nadajnik-odbiornik radiowy do wysyłania i odbierania sygnałów, mikrokontroler, obwód elektroniczny do łączenia czujników i źródło energii, zwykle baterię lub wbudowaną formę zbierania energii.
Istotnym mechanizmem łączenia urządzeń i obiektów ma być kręgosłup wszechobecnej informatyki, umożliwiające inteligentnym środowiskom rozpoznawanie i identyfikowanie obiektów oraz pobieranie informacji. Ponadto technologie takie jak sieci czujników i RFID rozwiążą te pojawiające się wyzwania, które koncentrują się na integracji systemów informacyjnych i komunikacyjnych. Wprowadzono nową strukturę o nazwie Monitorowanie Health IIoT , w której elektrokardiogram (EKG) i inne dane dotyczące opieki zdrowotnej są gromadzone za pośrednictwem urządzeń mobilnych i czujników oraz bezpiecznie przesyłane do chmury przez pracowników służby zdrowia w celu zapewnienia bezproblemowego dostępu. Pracownicy służby zdrowia będą używać wzmocnienia sygnału, znaków wodnych i innych powiązanych analiz, aby zapobiec kradzieży tożsamości lub błędom klinicznym. Zarówno ocena eksperymentalna, jak i symulacja potwierdziły przydatność tego podejścia poprzez wdrożenie w chmurze usługi monitorowania stanu zdrowia opartej na IoT, opartej
na EKG. Oferowana jest nowa architektura synchronizacji zegara sieci dla IoT, która opiera się na poziomie organizacji, adaptacji i regionu. Architektura poziomu adaptacji ma zapewnić rozwiązanie umożliwiające dostosowanie rzeczy do Internetu; architektura organizacyjna ma organizować i zarządzać systemem synchronizacji zegara, a architektura na poziomie regionu zapewnia synchronizację zegara. Celem jest zapewnienie niezawodnego bezpieczeństwa i dokładności synchronizacji zegara. Zaproponowano nowatorskie podejście oparte na metamodelu do integracji obiektów architektury w IoT. Pomysł polega na półautomatycznym zasilaniu holistycznego środowiska cyfrowej architektury korporacyjnej. Głównym celem jest zapewnienie odpowiedniego wsparcia decyzyjnego za pomocą systemów oceny rozwoju oraz środowiska IT do kompleksowego zarządzania biznesem i architekturą. Dlatego decyzje architektoniczne dotyczące IoT są ściśle powiązane z implementacją kodu, aby umożliwić użytkownikom zrozumienie, w jaki sposób zarządzanie
architekturą przedsiębiorstwa jest zintegrowane z IoT. Potrzeba jednak więcej pracy, aby zapewnić prace koncepcyjne nad federacją architektury korporacyjnej IoT poprzez rozszerzenie architektury modelu federacji i podejść do transformacji danych. Skalowalna i samokonfigurująca się architektura peer-to-peer dla dużej sieci IoT jest sugerowana przez Cirani i in. [18]. Celem jest zapewnienie mechanizmów automatycznego wykrywania usług i zasobów, które nie wymagają interwencji człowieka w celu ich skonfigurowania. Rozwiązanie opiera się na odkryciu lokalnych i globalnych usług, które umożliwiają udaną interakcję i wzajemną niezależność. Ważną rzeczą w tym rozwiązaniu jest to, że dzięki eksperymentowi przeprowadzonemu w rzeczywistym wdrożeniu, konfiguracja pokazuje. Jednak możliwość wystąpienia błędu jest głównym czynnikiem decydującym o tym, że architektura IoT jest bardziej niezawodnym rozwiązaniem. W [, badanie IoT umożliwiło scenariuszowi inteligentnego domu przeanalizowanie wymagań aplikacji IoT. W związku
z tym zaproponowano architekturę CloudThings w celu dostosowania CloudThings PaaS, SaaS i IaaS w celu przyspieszenia aplikacji IoT opartych na platformie IoT opartej na chmurze. Integracja chmury w IoT zapewnia realne podejście do ułatwienia tworzenia aplikacji Things. Podstawowe zmiany w podejściu do architektury CloudThings opierają się na wszechobecnych aplikacjach IoT działających i komponujących. Jednak system wymaga komunikacji sieci bezprzewodowej, która jest osadzona w IoT, aby poradzić sobie z heterogenicznością. W programie badany jest Internet Rzeczy oparty na strumieniowaniu wideo, który opiera się na architekturze sieciowej zorientowanej na treść. Eksperyment został przeprowadzony w oparciu o mechanizm dynamicznego adaptacyjnego przesyłania strumieniowego przez HTTP w celu dzielenia fragmentów wideo i wielu przepływności. Podzielone filmy są następnie przesyłane strumieniowo przez klienta dynamicznego adaptacyjnego przesyłania strumieniowego z typowego serwera HTTP za pośrednictwem sieci
centrycznej. Wynik pokazuje, że sieć centryczna może pasować do środowiska IoT, a jej zintegrowane mechanizmy zarabiania są ograniczone. Niemniej jednak wymagane są dodatkowe eksperymenty, aby ocenić różne powiązane sieci i porównać je z istniejącą. W artykule zaproponowano modułową i skalowalną architekturę opartą na wirtualizacji. Modułowość zapewniana przez proponowaną architekturę w połączeniu z lekką orkiestracją wirtualizacji platformy Docker upraszcza zarządzanie i umożliwia wdrożenia rozproszone. Funkcje dostępności i odporności na błędy są zapewniane przez dystrybucję logiki aplikacji na różne urządzenia, w których pojedyncza mikrousługa lub nawet awaria urządzenia nie mają wpływu na wydajność systemu.
Zastosowania IIoT dla smart Industries 4.0
I4.0 to nowa cyfrowa technologia przemysłowa, która umożliwia szybszy, bardziej elastyczny i wydajny proces wytwarzania towarów o wyższej jakości przy obniżonych kosztach oraz umożliwia zbieranie i analizowanie danych z różnych maszyn. Zastosowania IoT polegają na łączeniu ludzi z urządzeniami, które posiadali przez ostatnie lata, ale dostarczaniu im informacji, które wcześniej nie były łatwo dostępne. W nowych wydarzeniach branżowych, które mają wpływ na produkcję, sposób organizacji przemysłu i wszystko inne wokół nas, takie jak inteligentny dom, inteligentna sieć, inteligentny budynek itp., z łącznością wszelkiego rodzaju rzeczy napędzanych obecnością komunikacji bezprzewodowej przez moc obliczeniową, która wbudowuje ją w nowe inteligentne i elastyczne produkty. Wpływają one bezpośrednio na sposób faktycznego wytwarzania produktów, a który proces produkcyjny może wykorzystywać te technologie i koncepcje napędzane przez Internet Rzeczy. W pełni osadzone w IoT i CPS ułatwiły produkcję, nieograniczone paradygmaty, podobnie jak zakład przemysłowy w dłuższej perspektywie i I4.0, przewidują środowiska analizy biznesowej wymagające dużej ilości danych, w których rozsądne, spersonalizowane towary są tworzone za pomocą inteligentniejszych procesów i procedur. I4.0 opiera się na logice CPS, w której będzie arbitralny, samooptymalizowany i samowystarczalnie działające systemy, które komunikują się ze sobą i ostatecznie optymalizują produkcję jako całość. Innowacje technologiczne w miniaturyzacji wraz z komunikacją bezprzewodową umożliwiły urządzeniom mobilnym, czujnikom i aplikacjom komunikowanie się ze sobą i ciągłe przebywanie w sobie i swoim wzajemnym zasięgu. Na bazie tych siłowników i czujników bezprzewodowych zbudowano zaawansowane technologicznie aplikacje i usługi kontekstowe. Obecnie firmy produkcyjne borykają się z obciążeniami adaptacyjnymi wynikającymi z szybkich zmian technologicznych, tj. zmiennym popytem, wysoce spersonalizowanymi produktami i krótkimi cyklami życia produktów. Aby sprostać tym wyzwaniom, firmy produkcyjne są w stanie sprostać przyszłym wyzwaniom rynkowym, muszą być w stanie wyprodukować małe grupy produktu lub pojedynczego produktu w sposób terminowy i oszczędny, z odpowiednią funkcjonalnością, łącznością i elastycznością z klientami i dostawcami wymagania . Aby sprostać tym istniejącym wyzwaniom, obecne systemy muszą być bardziej skomplikowane, co będzie trudniejsze do kontrolowania i monitorowania. W związku z tym tradycyjne systemy produkcyjne z dedykowanymi liniami produkcyjnymi nie będą w stanie konkurować w przyszłej erze wysokich technologii. Dlatego branża potrzebuje radykalnej zmiany, aby dostosować się i sprostać istniejącym wyzwaniom. Odpowiedzią na te wyzwania jest I4.0. Podstawową zasadą I4.0 jest wykorzystanie najnowszych pojawiających się technologii informatycznych, takich jak IoT, Internet of Services (IoS), CPS, big data, sieć semantyczna, przetwarzanie w chmurze i wirtualizacja, tak aby inżynieria i procesy biznesowe były głęboko zintegrowane, dzięki czemu produkcja działa w wydajnym, modyfikowalnym, przyjaznym dla środowiska, niedrogim, a jednocześnie wysokiej jakości. Wizją I4.0 jest doprowadzenie Internetu do najniższego punktu, w którym każdy siłownik i czujnik ma swój wkład w IoT. W tym środowisku każde urządzenie ma swój unikalny adres IP, dzięki czemu zautomatyzowany system i produkty mogą się ze sobą efektywnie komunikować. IIoT to maszyna przemysłowa, która jest powiązana z obszarem przechowywania danych w chmurze korporacyjnej, zarówno do pobierania, jak i przechowywania danych, z potencjałem dużych zmian w zarządzaniu globalnym łańcuchem dostaw. Podejście Lean Six Sigma w globalnym łańcuchu dostaw wykorzystujące IIoT i I4.0 tworzy idealny przepływ procesów, który jest doskonały i wysoce ulepszony, co minimalizuje wady i marnotrawstwo. Zastosowanie IIoT może dotyczyć wielu aspektów infrastruktury społeczeństwa i przyczynić się do poprawy ludzkiego życia.
Inteligentna fabryka
Wdrażanie technologii CPS i IoT w systemach produkcyjnych przyniosło nowe możliwości, umożliwiając zarządzanie złożonymi i elastycznymi systemami w celu dostosowania się do szybkich zmian. Wraz z rozwojem I4.0, a także pojawieniem się modelu inteligentnej fabryki, standardowa filozofia wytwarzania systemów została zmodyfikowana. Inteligentna fabryka wprowadza zmiany w czynnikach i częściach konwencjonalnych systemów produkcyjnych i uwzględnia te potrzeby inteligentnych systemów, aby mogła konkurować w przyszłości. Zawiera również moduły, które są inteligentne i ustandaryzowane, które mogą łączyć się i mieszać w prosty sposób z każdym innym modułem i posiadają określoną funkcjonalność, aby utworzyć sieć online w fabryce. Coraz większa ilość analiz w każdej akademii i branży poświęcona jest przejściu koncepcji dobrej manufaktury od teorii do namacalnego produktu. Jednym z najważniejszych wyzwań jest to, że system inteligentnej fabryki powinien osiągnąć wysoki poziom udostępniania i wymiany informacji między ich towarami, infrastrukturą ich towarów i procesów, ich systemem kontroli i zastosowaniem przedziałów czasowych. Całkowicie sterowana maszynowo produkcja w przyszłości, która może oszczędzić koszty, czas, narzędzia i procesy, jest w całości przedstawiana cyfrowo.
Wymagania inteligentnej fabryki
Fabryki są potrzebne, aby rozszerzyć swoją inteligencję i automatyzację na to, co jest obecnie możliwe przy użyciu istniejącej technologii i czujników.
Modułowość
Dotyczy to planowania elementów systemu. Modułowość można scharakteryzować ze względu na możliwość prostego i szybkiego rozdzielania i łączenia elementów systemu.
Interoperacyjność
Oznacza to dla każdego elastyczność udostępniania danych technicznych między elementami systemu wraz z produktem oraz elastyczność udostępniania danych biznesowych między przedsiębiorstwami produkcyjnymi a klientami. CPS umożliwia afiliację przez IoT, a także IoS.
Decentralizacja
Części systemu (towar magazynowy, moduły itp.) mogą samodzielnie tworzyć wybory, niepodporządkowane jednostce uderzeniowej, której wybory będą tworzone autonomicznie.
Samochody bez kierowcy
Autonomiczny samochód jest jednym z najważniejszych futurystycznych zastosowań IoT. Te samochody, które pojawią się jako taki produkt w niedalekiej przyszłości, naprawdę istnieją w dzisiejszych czasach i są głównie w fazie prototypu lub rozwoju. Samochody nie mają operatorów i są na tyle sprytne, aby same zawieźć Cię do wybranej lokalizacji. Samochody te są wyposażone w inteligentne urządzenia i zaawansowane technologie, takie jak żyroskopy, czujniki, Internet i usługi w chmurze. Wykorzystują te urządzenia do wykrywania ogromnych ilości danych o ruchu drogowym, pieszych, warunkach na drodze, takich jak wyboje, ograniczniki prędkości, zakręty i ostre zakręty, i natychmiast je przetwarzają. Zebrane informacje są przekazywane do kontrolera, który podejmuje powiązane ze sobą decyzje dotyczące jazdy. Uczenie maszynowe i sztuczna inteligencja to podstawowe aspekty samochodów bez kierowcy.
Inteligentne pokoje hotelowe
Właściciele hoteli zapewniają większe bezpieczeństwo, zastępując klucze do drzwi oparte na karcie aplikacjami na smartfony, dzięki którym lokator może wejść do pokoju, wskazując swoim smartfonem zamki w pokoju. Ponadto systemy oświetlenia i ogrzewania są połączone z Internetem, aby zapewnić gościom spersonalizowane wrażenia. Dzięki tej funkcji będziesz mógł ustawić oświetlenie i kontrolować temperaturę w pomieszczeniu w oparciu o swoje preferencje. Ponadto będziesz mógł w prosty sposób zarejestrować się i uzyskać sugestie dotyczące podróży oraz wiele informacji na temat oferowanych ofert hotelowych. W przypadku hoteli i zarządzania energią skutkuje to spójnymi rozwiązaniami zapewniającymi wydajną eksploatację poprzez integrację systemów produkcyjnych. Zwiększa to efektywność energetyczną przy jednoczesnym obniżeniu kosztów operacyjnych.
Automatyzacja i adaptacja z maksymalną wydajnością
Zachowanie adaptacyjne zapewnia elastyczność, radzi sobie z wszelkiego rodzaju zakłóceniami w celu uzyskania maksymalnej wydajności i ostatecznie wzmacnia produkcję. Zamiast posiadania centralnego sterownika jako metody konwencjonalnej, istnieje inteligentna współpraca i sterowniki rozproszone, które dostosowują się niezależnie do urządzeń i urządzeń procesowych. W tej dziedzinie łatwiej jest zoptymalizować i zarządzać złożonymi procesami i nieoczekiwanymi zdarzeniami, co oznacza produkcję partii o wielkości jednej partii przy równie niskich kosztach produkcji masowej. Inteligentny i autonomiczny system produkcyjny jest ekonomiczny przez długi czas.
produkcja i produkcja dzięki uczeniu maszynowemu i eksploracji danych
Więcej programu i inteligencji jest integrowanych z produkcją przemysłową, aby tworzyć systemy obniżające koszty i poprawiające jakość, moc i elastyczność produkcji. W inteligentnym systemie sterowania element obrabiany wyposażony w tag RFID przechodzi przez wszystkie stanowiska produkcyjne. Inteligentny system sterowania jest w stanie zidentyfikować, na którym stanowisku produkcyjnym obrabiany przedmiot będzie obrabiany.
Optymalizacja procesów branżowych za pomocą przetwarzania w chmurze i big data
Chociaż model IoT i współczesne postępy w komunikacji maszyna-maszyna (M2M) umożliwiają jednoczesne monitorowanie inteligentnych fabryk, zużycie zasobów i efektywna optymalizacja procesów biznesowych zasadniczo opierają się na procesach wymagających dużej ilości danych, dla których dostępne na miejscu zasoby obliczeniowe nie są wystarczające. W tej percepcji big data i cloud computing przygotowują technologie dla paradygmatu I4.0. Jest to nie tylko miejsce, w którym większość decyzji dotyczących danych urządzeń przemysłowych i ważnych informacji jest pozyskiwanych i analizowanych, ale oferuje również możliwość dostosowania do skalowania na żądanie dla różnych obciążeń, które mogą zautomatyzować i zoptymalizować procesy biznesowe. Umożliwia analizę informacji z nieuniknioną wydajnością, nawet w przypadku rosnących przemysłowych sieci bezprzewodowych połączonych ze sobą elementów, co prowadzi do opłacalnego łańcucha ofert. Ogólne zastosowanie inteligentnego przemysłu zostanie rozszerzone tak, aby było komunikatywne i bezpieczne, łatwe w instalacji, prototypowane wirtualnie, łatwe w obsłudze i zasobooszczędne.
Przypadki użycia IIoT dla smart Industries 4.0
W tej sekcji opisano kilka przypadków użycia związanych z IIoT dla inteligentnych branż, z różnymi aspektami zastosowań.
Samochodowy system nawigacji
Aby nawigacja GPS wskazywała kierunek kierowcy, wymaga samochodowego systemu nawigacyjnego, który podaje dane o położeniu w celu zlokalizowania samochodu na drodze w bazie danych map. Jednak ta akcja wymaga połączenia z Internetem, aby móc w pełni działać. Korzystanie z osobistej architektury IoT pozwala systemowi nawigacyjnemu łączyć się z Internetem. Pomysł polega na tym, że procedura zdalnego sterowania nawigacją samochodową wykorzystuje urządzenie do nawigacji samochodowej, smartfon i serwer zdalnego sterowania oraz klienta, aby łatwo mieć połączenie z Internetem. To urządzenie nawigacyjne może być zdalnie sterowane za pomocą smartfona, co nie wymaga komunikacji bezprzewodowej technologii .
Zarządzanie i optymalizacja łańcucha dostaw.
Platforma IoT NetObjex może zapewnić łatwy i uproszczony dostęp do informacje o łańcuchu dostaw w czasie rzeczywistym. Odbywa się to poprzez dokładne śledzenie sprzętu, materiałów i produktów w trakcie ich przemieszczania się w łańcuchu dostaw. Rozwiązania NetObjex I4.0 zapewniają Twojej organizacji większą kontrolę, wgląd i widoczność danych w całym łańcuchu dostaw. Skuteczne i dokładne raportowanie pomaga gromadzić i dostarczać informacje dotyczące zarządzania cyklem życia produktów o znaczeniu krytycznym, planowania zasobów biznesowych i innych systemów. Pomaga to śledzić przepływ materiałów, współzależności i czasy cyklu produkcji. Dostęp do tych danych pomoże Ci zredukować zapasy, przewidzieć problemy i zminimalizować potrzeby kapitałowe.
Śledzenie i optymalizacja zasobów
Rozwiązania I4.0 od NetObjex via PiQube i NetObjex Matrix Digital Twin Platform pomagają producentom na każdym etapie łańcucha dostaw stać się bardziej wydajnymi i zyskownymi. Pomaga im to dokładnie sprawdzać możliwości związane z logistyką pod kątem jakości, zapasów i optymalizacji. Ponadto pracownicy Twojej organizacji korzystający z IoT mogą czerpać korzyści z lepszej globalnej widoczności swoich zasobów. Ponadto zadania związane ze standardowym zarządzaniem aktywami, takie jak likwidacja, przenoszenie aktywów, korekty i reklasyfikacja, mogą być centralnie zarządzane i usprawniane w czasie rzeczywistym.
Napędzanie transformacji przedsiębiorstwa
IBM oferuje klientom pomoc wdrożeniową, która ma ogromny wpływ na zwiększenie efektywności operacyjnej, zrewolucjonizowanie modeli biznesowych (BM), usprawnienie operacji w branży i odzwierciedlenie doświadczenia ich klientów. Daimler został poproszony o obsługę niektórych operacji wewnętrznych przy użyciu technologii Internetu Rzeczy. Firma korzysta z usług IBM, aby uruchomić cargo, flotę przyjaznych dla środowiska inteligentnych samochodów na żądanie, które użytkownicy mogą rezerwować z aplikacji mobilnych. Wykorzystując architekturę IoT, która obejmuje czujniki i komunikację bezprzewodową, firma jest w stanie monitorować osiągi pojazdu, zapewnić dostępną sieć pojazdów i analizować dane w celu zwiększenia wydajności samochodu.
Podłączanie formularza do chmury
Firma John Deere, która produkuje wyróżniający się zielony i żółty sprzęt rolniczy, wdrożyła technologie IoT, które zmieniają sposób funkcjonowania tradycyjnego rolnictwa. Firma wykorzystuje IoT do łączenia swoich pojazdów z aplikacją mobilną o nazwie JDLink. Ta nowa technologia umożliwia rolnikom i dealerom zdalny dostęp, używanie i diagnozowanie danych dla każdej maszyny. Rozwiązanie opiera się na technologiach IoT, które obejmują bezprzewodowe strumieniowanie danych produkcyjnych, monitorowanie i raportowanie pogody w czasie rzeczywistym. W efekcie wartość ich działania jest podnoszona poprzez zapewnienie niezawodnej pracy sprzętu
Aktualne zastosowania i ograniczenia IIoT w inteligentnym Przemyśle 4.0
W tej sekcji przedstawiono niektóre z istniejących zastosowań i ograniczeń IIoT w inteligentnym Przemyśle 4.0. Ograniczenia te mogą być związane z infrastrukturą, siecią i internetem, problemami energetycznymi, zasobami ludzkimi, środowiskiem gospodarczym, kosztami i wymaganiami oprogramowania. Poniżej przedstawiono niektóre z kluczowych ograniczeń w obecnych zastosowaniach IIoT w inteligentnym Przemyśle 4.0.
Łączność
Większość nowoczesnych IIOT korzysta ze scentralizowanego modelu, aby zapewnić łączność z różnymi czujnikami i systemami, takimi jak urządzenia do noszenia, inteligentne samochody, inteligentne domy i inteligentne miasta. Model może być wydajny, biorąc pod uwagę ilość mocy u przy użyciu IIoT, gdzie komunikacja M2M dominuje w terenie, aby połączyć wszystkie te różne obiekty. Jednak wraz ze wzrostem liczby urządzeń do miliardów korzystających z sieci jednocześnie może to spowodować znaczne wąskie gardło w łączności IoT, wydajności i ogólnej wydajności.
Władza autonomiczna
Główne ograniczenia związane z IIoT dotyczą autonomicznego działania opartego na kontekście. W ten sposób pewien poziom automatyzacji z IoT jest wykorzystywany jako obiekt do tworzenia połączonych i zarządzania systemami. Wykorzystanie technologii ewoluuje od WSN do RFID i wąskopasmowego IoT, które zapewniają możliwości wykrywania i komunikowania się przez Internet. W ciągu następnej dekady dużym ograniczeniem, jakie IoT musi przezwyciężyć, jest uzyskanie kontekstu i niezależne wykonywanie działań. System, który uczy się i dostosowuje bez konieczności konfiguracji, jest znany jako inteligentny i zautomatyzowany system.
Sprzęt IoT
Wiele branż wykorzystuje Internet Rzeczy, aby uczynić systemy bardziej inteligentnymi; jednak przetwarzanie w chmurze i integralność danych nadal pozostają wyzwaniem. Biorąc pod uwagę ogromną ilość danych zebranych z różnych źródeł, należy odpowiednio podkreślić znaczenie oddzielenia użytecznych i przydatnych informacji od nieistotnych danych. Niezwykle ważne jest regularne kalibrowanie czujników IoT, tak jak w przypadku każdego innego rodzaju czujnika elektrycznego. Wiele czujników jest wbudowanych w różne urządzenia, w tym mierniki, cęgi prądowe, rejestratory wykresów, monitory mocy i wiele innych, a przepływ danych między całym tym sprzętem jest trudny do zsynchronizowania bez pomocy profesjonalnego zespołu.
Bezpieczeństwo
Urządzenia IoT stają się wszechobecne i rozciągają się od cyberświata do świata fizycznego, tworząc nowe rodzaje problemów i obaw związanych z bezpieczeństwem, które są bardziej złożone. IoT był początkowo promowany jako sieć o wysokim poziomie bezpieczeństwa, nadająca się do przechowywania i przesyłania poufnych zestawów danych. Chociaż prawdą jest, że Internet Rzeczy jest bezpieczniejszy niż przeciętne połączenie internetowe lub LAN, nie była to dokładnie kuloodporna powłoka, jakiej oczekiwali niektórzy użytkownicy. Niektóre z najważniejszych problemów związanych z bezpieczeństwem dotyczą Internetu Rzeczy i chmury. Przeprowadzona niedawno analiza przewiduje, że usunięcie tylko jednego centrum danych w chmurze oznacza utratę nawet 120 miliardów dolarów w skutkach ekonomicznych
Otwarte zagadnienia badawcze i wyzwania smart Industries 4.0
Zgodnie z ogólnym przekonaniem, korzystanie z urządzeń i systemów IoT w branży zwiększa produktywność poprzez zmianę zwykłego sprzętu na inteligentne i połączone ze sobą o wyższej wydajności i niższych kosztach utrzymania. Proces produkcyjny będzie bardziej zwinny, a wygenerowane dane IoT oferują znacznie głębszy wgląd. Jednak wady i zalety osadzania systemów IoT w branży są nadal badane i analizowane są wyzwania związane z wdrażaniem, takie jak opór kulturowy wobec zmian technologicznych, cyberataki i inne problemy infrastrukturalne, które mogą wystąpić. Według badań Thobena i in. te zagadnienia badawcze można podzielić na trzy grupy: (1) metodologiczne, (2) technologiczne i (3) biznesowe. Jednak niektóre ze zidentyfikowanych problemów można podzielić na więcej niż jedną grupę. Stąd te badania kategoryzują je w oparciu o najważniejsze czynniki według wiedzy autora. Niektóre wyzwania można pogrupować w wiele kategorii, a większość z nich ma charakter technologiczny, ponieważ urządzenia, technologie i dane IoT są kluczowymi elementami technologicznego aspektu smart Industries 4.0. Czujniki IIoT umożliwiają firmie produkcyjnej zbieranie wszelkiego rodzaju danych ze wszystkich fizycznych i wirtualnych obiektów biorących udział w procesie produkcyjnym. Na przykład temperatury urządzeń i prędkość maszyn można łatwo rejestrować za pomocą czujników IIoT. Dane te są zbierane do wykorzystania w analizie danych w czasie rzeczywistym. Ta możliwość otwiera interesujące okno przemysłowych i biznesowych możliwości poprawy wydajności operacyjnej i wzmocnienia władzy decydentów poprzez wydobywanie znaczących informacji z danych IIoT. Pozostała część tego rozdziału przedstawia niektóre z istniejących problemów badawczych i wyzwań smart Industries 4.0.
Interoperacyjność
Wyzwanie to dotyczy interoperacyjności pomiędzy różnymi systemami firm, gdzie część firm korzysta z autorskich rozwiązań dostępnych na rynku, a część innych korporacji z rozwiązań open-access lub samodzielnie opracowanych. Rozwiązania te dobierane są według różnych wymiarów, takich jak charakter działalności, rodzaje generowanych danych oraz proces operacyjny. Dlatego też, gdy te różne systemy mają ze sobą współpracować, interoperacyjność staje się głównym wyzwaniem, które należy odpowiednio rozwiązać, aby umożliwić inteligentną produkcję. Na przykład integracja systemów transportowych i urządzeń interfejsu użytkownika używanych przez różnych sprzedawców wymaga skutecznego rozwiązania problemów z interoperacyjnością. W bardziej dynamicznym i złożonym środowisku produkcyjnym mogą być potrzebne różne integracje, aby rozwiązać problem w celu uproszczenia rozwoju i procesu inteligentnych sieci dostaw w produkcji.
Analiza danych Big IIoT
Analityka danych Big IIoT obejmuje procesy gromadzenia danych, przenoszenia ich do scentralizowanych centrów danych w chmurze oraz wdrażania preprocessingu, eksploracji danych, analizy, wizualizacji i raportowania. Analityka big data obejmuje procesy przeszukiwania bazy danych, wydobywania i analizowania danych przeznaczonych do poprawy wydajności firm produkcyjnych. Analiza danych Big IoT oferuje eleganckie narzędzia analityczne do przetwarzania dużych danych IoT w czasie rzeczywistym. Ta szansa daje decydentom rozsądne i terminowe wyniki. Analiza danych Big IIoT jest jednym z głównych elementów inteligentnej produkcji opartej na danych i inicjatyw I4.0. Chociaż analityka dużych danych IoT jest klasyfikowana jako problematyka badań technologicznych, to ze względu na wymóg projektowania odpowiednich metodologii analitycznych można ją zaklasyfikować do kwestii badań metodologicznych. W niektórych przypadkach posiadanie lepszych metod analitycznych jest ważniejsze niż rodzaj narzędzi i algorytmów analitycznych. W rzeczywistości czasami wybór metod łączenia starych i nowo opracowanych algorytmów zgodnie z pewnikami inteligentnej produkcji ma kluczowe znaczenie. Bardzo ważne jest, aby zaangażować ludzi w cykl procesu analizy danych przechwyconych danych poprzez produkcję czujników i urządzeń IoT. Zapewnia to silną wizualizację danych i dogłębny wgląd w bramkę wyników. Automatyzacja procesu, dostępność danych w czasie rzeczywistym oraz zautomatyzowane monitorowanie za pomocą wysokopoziomowych algorytmów wspierających ludzkie decyzje to kluczowe cechy smart Industries 4.0. Bezpieczna interakcja między ludźmi a inteligentnymi systemami, która jest zaangażowana w automatyzację procesów, taką jak automatyzacja procesów w robotyce, wymaga niezawodnych i ulepszonych algorytmów analitycznych. W kilku badaniach zgłoszono i opisano problemy związane z analizą danych, jeśli chodzi o big data i inteligentne branże. Jednak najważniejszą kwestią analizy dużych zbiorów danych w inteligentnej produkcji jest integracja różnych zależnych i niezależnych danych z różnych źródeł, takich jak zużycie energii, przepływ materiałów, dane z kontroli jakości i inne dodatkowe informacje w czasie rzeczywistym . Kolejnym ważnym wyzwaniem jest rosnąca dostępność surowych danych i związane z nimi kwestie, takie jak jakość danych, złożoność danych, dane dynamiczne, walidacja i weryfikacja danych.
Ochrona danych
Inteligentne branże zajmują się cennymi danymi w czasie rzeczywistym generowanymi przez inteligentne urządzenia i czujniki IoT wykorzystujące protokoły komunikacji internetowej za pośrednictwem sieci bezprzewodowych i adhoc. Dane te są coraz częściej przechowywane w centrach danych za pomocą usług opartych na chmurze. Korzystanie z analizy danych na tych cennych danych w inteligentnych branżach zapewnia bardziej znaczące informacje, a jednocześnie motywuje przestępców i osoby fizyczne do próby wykorzystania tej możliwości w nielegalne sposoby. Dlatego systemy inteligentnych branż muszą być stale ulepszane, aby zapobiegać nieautoryzowanemu dostępowi do cennych danych i wykrywać wszelkie inne zagrożenia bezpieczeństwa . W rzeczywistości sprytni producenci wolą ograniczać dostęp do swoich danych, dostarczając je w odizolowanych centrach danych i serwerach oraz dając dostęp tylko uprawnionym klientom i użytkownikom, aby zobaczyć tylko bardzo szczegółowe i ograniczone wyniki analiz . Drugie wyzwanie w zakresie bezpieczeństwa danych wiąże się z mechanizmami zapobiegania nieuprawnionemu dostępowi do systemów sterowania oraz podłączonych do nich urządzeń i maszyn, które są kolejnym celem przestępców sabotujących maszyny i procesy produkcyjne.
Jakość danych
Tworzenie systemów IoT z możliwością generowania wiarygodnych danych nie jest łatwe, a zebrane dane z urządzeń IoT w większości cierpią na brak jakości. Dlatego jakość danych wytwarzanych przez systemy IIoT w inteligentnych branżach jest tak samo ważna, jak inne kwestie i wyzwania, takie jak duża analityka danych IIoT. Wykorzystywanie danych niskiej jakości w inteligentnych branżach zagraża systemom monitorowania i kontroli, a także wszelkiej optymalizacji zorientowanej na dane. Stąd też wymagane jest opracowanie algorytmów jakości danych do automatycznego monitorowania jakości generowanych danych w inteligentnych procesach produkcyjnych i maszynach. Poprawia to poziom zaufania i trafności decyzji podejmowanych na podstawie danych. Ponadto heterogeniczność danych w inteligentnych branżach to kolejny aspekt jakości danych w całym cyklu życia produktu. Integracja różnych źródeł danych o różnych formatach i semantyce to wciąż duże wyzwanie dla zaawansowanej analityki danych. Dlatego semantyczne systemy mediatorów muszą zostać opracowane i osadzone na etapie wstępnego przetwarzania przed rozpoczęciem fazy analizy danych. Mediatorzy ci mogą być aktualizowani zgodnie z wymaganiami analityki danych.
Wyobrażanie sobie
Istnieje silna potrzeba wizualizacji danych, aby dostarczać użytkownikom ilustrowane informacje w inteligentny, zrównoważony i solidny sposób . Wyzwania wizualizacyjne można rozpatrywać zarówno jako kwestie technologiczne, jak i metodologiczne. Wizualizacja jest niezbędnym narzędziem przekazywania złożonych informacji produkcyjnych. Na przykład, złożone wyniki analizy danych muszą być udostępniane różnym udziałowcom firmy. Jest to wyzwanie, ponieważ różni akcjonariusze mogą mieć różne uprawnienia dostępu do wizualizacji i istniejących wyników. To samo dotyczy innych użytkowników, takich jak administratorzy zarządzający systemami wizualizacji czy inżynierowie odpowiedzialni za planowanie produkcji. Różni użytkownicy wymagają dostępu do różnych informacji, wyników wizualizacji, a nawet interfejsu użytkownika w porównaniu do kierowników sprzedaży lub fabryk. Wizualizacja jest kluczowym elementem inteligentnego przemysłu i wymaga ścisłej współpracy zarówno przemysłu, jak i środowiska akademickiego w celu prowadzenia odpowiednich badań nad wizualizacją, aby zrozumieć, jakie rodzaje informacji należy przedstawić różnym udziałowcom. Muszą również zaprojektować i wdrożyć rygorystyczne rozwiązania wizualizacyjne, które mogą rozbić abstrakcyjne dane oparte na czujnikach, dostarczyć dodatkową wartość i odpowiednie informacje. Należy tutaj podkreślić, że procesy wizualizacji i wyniki są niezwykle zależne od indywidualnych potrzeb akcjonariuszy. Dlatego nie jest możliwe użycie jednego rozwiązania wizualizacyjnego dla wszystkich możliwych scenariuszy, gdy oczekuje się, że będzie miało pozytywny wpływ na operacje.
Prywatne problemy
Oczywiste jest, że kwestie prywatności danych są związane z bezpieczeństwem danych. Jednak kwestie bezpieczeństwa danych dotyczą bardziej technologicznego aspektu przetwarzania danych w inteligentnych branżach, w których koncentruje się na ochronie i zachowaniu wrażliwych danych produkcyjnych. Ale kwestie prywatności danych opisują pewne wyzwania związane z wewnętrzną i zewnętrzną wymianą danych, informacji i wiedzy. Ujawnianie cennych danych lub informacji nieuprawnionym stronom lub osobom może stworzyć wiele problemów dla właścicieli danych. Na przykład posiadanie dostępu do cennych danych przez konkurentów może dać im możliwość wykorzystania inżynierii wstecznej do wytwarzania tych samych produktów lub wyodrębnienia istotnych informacji, co może być jeszcze bardziej problematyczne. W związku z tym należy opracować mechanizm ochrony prywatności, aby zapewnić każdemu, kto ma dostęp do dowolnej części danych, możliwość korzystania z nich wyłącznie w określonych z góry celach, dla których dane są udostępniane. Na przykład dane wideo z nadzoru statku powietrznego należące do linii lotniczej są przechowywane przez dostawcę usług. Dane te są regulowane zgodnie z prywatnością pasażerów, a przepisy różnią się w zależności od kraju. Udostępnianie niektórych informacji z pewnych powodów, takich jak poprawa jakości, może być korzystne. Wymaga to polityki zapewnienia, która musi być opracowana w oparciu o interdyscyplinarne badania z udziałem prawa, biznesu, inżynierów i ekspertów z dziedziny informatyki.
Kwestie inwestycyjne
Jest to ogólny problem biznesowy w inteligentnych branżach. Złożoność i interdyscyplinarny charakter rat smart industries stanowi barierę dla każdego małego i średniego przedsiębiorstwa (MŚP). Wdrożenie inteligentnych ram przemysłowych w MŚP, takich jak system cyber-fizycznej logistyki (CPLS), wymaga znacznych inwestycji. Celem posiadania systemu CPLS jest zwiększenie elastyczności poprzez niezależne decyzje i umożliwienie redukcji zapasów poprzez niezależne rozwiązywanie błędów w czasie rzeczywistym. Pomiar zaufania do współpracy i możliwości usprawnień organizacyjnych nie są łatwe. Solidne stanowiska testowe stworzone przez Smart Manufacturing Leadership Coalition lub projekty latarni morskich mogą być właściwym początkiem do przeprowadzenia testów porównawczych i udanych przypadków, aby podkreślić potencjał takiej inwestycji. Poza tym potrzebne są badania teoretyczne dotyczące kwantyfikacji i zwrotu z inwestycji w inteligentne zastosowania przemysłowe, szczególnie w odniesieniu do efektów współpracy w złożonych i dynamicznych sieciach dostaw w MŚP
Obsługiwane modele biznesowe
Tradycyjnie BM w branżach produkcyjnych skupiają się głównie na produkcji lub montażu niestandardowych produktów fizycznych, a przychody mogą być generowane przez sprzedaż tych produktów. Ale koszty materiałów, urządzeń i sprawnej obsługi są bardzo wysokie. Tym samym wydajność procesów i powiązanie łańcucha dostaw mają istotny wpływ na konkurencyjność firmy. Jednocześnie tradycyjne BM są popychane przez globalną harmonizację standardów technologicznych i zmniejszenie barier handlowych do przejścia na nowoczesne BM. Kilku badaczy sugeruje, że firmy produkcyjne w rozwiniętych gospodarkach odgrywają kluczową rolę w łańcuchu wartości, dodając więcej usług do swoich produktów. Dzięki tym rozszerzeniom nie muszą już konkurować jedynie kosztami produkcji. Zgodnie z badaniem, zaproponowany framework wykorzystujący koncepcję systemu produkt-usługa (PSS) opisuje realizację, zintegrowany rozwój i oferuje określone pakiety produkt-usługa jako rozwiązanie dla klienta. Proponowane ramy opierają się na pięciu fundamentalnych zmianach: (1) przejście ze świata produktów do świata obejmującego rozwiązania, (2) produkty wyjściowe do wyników, (3) transakcje do relacji, (4) dostawcy do partnerów sieciowych i (5 ) elementy do ekosystemów . Koncepcja zastosowana w tym kontekście jest bardzo podobna do idei inteligentnych branż, w których tzw. CPS oferuje rozwiązanie konkretnego problemu poprzez wynik ich zastosowania. Relacje pomiędzy innymi systemami i ich otoczeniem mogą być budowane przez CPS i zastępowane jednorazowymi transakcjami sprzedaży. Na przykład dostęp do użytkowania w cyklu życia może prowadzić do usprawnienia procesów produkcyjnych. Może również oferować usługi dodatkowe dla podstawowego produktu. Dlatego wokół CPS można stworzyć ekosystem sieciowy, który łączy klientów, dostawców i innych partnerów. W innym badaniu wymyślono termin "Cyber-fizyczny system obsługi produktów" (CPSS) w celu zintegrowania koncepcji PSS i inteligentnych gałęzi przemysłu. Teraz, jeśli firma produkcyjna przechodzi od wytwarzania produktów do proponowania rozwiązań CPSS i przekształca swoją bazę dostawców w sieciowy ekosystem partnerów, musi analizować i dostosowywać elementy swojego BM, aby nadal osiągać zyski, a także pozostać konkurencyjną. Elementy te obejmują nową propozycję wartości, kluczowe zasoby, różne segmenty i relacje klientów, kanały dystrybucji, kluczowe zasoby, strukturę kosztów, a także strumienie przychodów.
Przyszłe kierunki IIoT w smart Industries 4.0
IoT to koncepcja, w której sieć/internet rozciąga się na rzeczywisty świat, obejmując przedmioty codziennego użytku. Z pomocą IoT teraz fizyczne przedmioty są w stanie pozostać połączone w ramach wirtualnego świata i można nimi sterować zdalnie jako fizyczny punkt dostępu do usługi internetowej. IoT naprawdę przynosi rewolucję w branży, gdzie obniża koszty, ułatwia monitorowanie, zwiększa produkcję, w pełni monitoruje zarządzanie łańcuchem dostaw, a także procesy produkcyjne różnych branż, co ma bardzo bezpośredni i duży wpływ na gospodarkę świat. Można się spodziewać przyszłej koncepcji inteligentnego przemysłu, w której wszystkie procesy będą zarządzane w inteligentny sposób, sterowane przez inteligentną robotykę. W obecnej epoce znaczenie danych, zdalny dostęp i terminowość jest niezbędnym elementem rozwoju każdej organizacji, co będzie miało bezpośredni wpływ na rozwój branży, a także pośrednio na gospodarkę kraju . IIoT prowadzi inteligentne branże do szybkiego tempa wzrostu, zapewniając wszelkie niezbędne wsparcie dla danych branżowych, poza ich automatyzacją i zdalnym monitorowaniem. IIoT jest źródłem transformacji dla branż, które poprawią wiele aspektów branży, w tym automatyzację i transport, opiekę zdrowotną, produkcję, handel detaliczny, łańcuch dostaw, infrastrukturę, ubezpieczenia, usługi komunalne itp. Ponadto zastosowania IoT mają bardzo szeroki zakres, w tym aplikacje IIoT. Niedawne badanie analizuje 20 najważniejszych zastosowań IIoT na teraźniejszość i przyszłość, które zmienią styl pracy i będą miały wysoki wzrost i wkład w gospodarkę. Wśród 20 sugerowanych zastosowań przemysłowych znajdują się:
1. ABB: Inteligentna robotyka
2. Airbus: fabryka przyszłości
3. Amazon: wymyślanie magazynów na nowo
4. Boeing: wykorzystanie Internetu Rzeczy do zwiększenia wydajności produkcji
5. Bosch: innowator śledzenia i śledzenia
6. Caterpillar: pionier IIoT
7. Fanuc: pomoc w minimalizowaniu przestojów w fabrykach
8. Gehring: pionier w połączonej produkcji
9. Hitachi: zintegrowane podejście do IIoT
10. John Deere: Ciągniki samojezdne i nie tylko
11. Kaeser Kompressoren: Powietrze jako usługa
12. Komatsu: Innowacje w górnictwie i ciężkim sprzęcie
13. KUKA: Połączona robotyka
14. Maersk: Inteligentna logistyka
15. Magna Steyr: Inteligentna produkcja motoryzacyjna
16. North Star BlueScope Steel: Zapewnienie bezpieczeństwa pracownikom
17. Innowacje w czasie rzeczywistym: innowacje w zakresie mikrosieci
18. Rio Tinto: Kopalnia przyszłości
19. Shell: inteligentny innowator na polu naftowym
20. Stanley Black & Decker: Połączona technologia dla budownictwa i nie tylko
Wniosek
Wzrost gospodarczy kraju jest bezpośrednio związany z jego rozwojem przemysłowym, podczas gdy wykorzystanie nowych technologii jest niezbędne dla rozwoju przemysłowego. Branże mogą produkować dobrze wydajnie i mądrze, i znany jako inteligentny przemysł, przyjmując technologie nowej ery, takie jak IIoT itp. W związku z tym branże zmieniają się wraz z wymaganiami nowej ery, od starszej mody do perspektywy technologicznej. Branże w pełni wyposażone w technologię są znane jako inteligentne branże, a IIoT to ten, który sprawia, że zwykłe branże stają się inteligentne, zapewniając im cięcie kosztów, zdalny dostęp, zarządzanie produkcją, łańcuch dostaw, monitorowanie, zmniejszanie kosztów zużycia energii itp. IIoT przynosi rewolucję w branży, aby znacznie zwiększyć swoją produkcję i umożliwić przemysłowi zdalny dostęp do danych i udostępnianie ich. Ten rozdział książki przyczynił się do wyjaśnienia podstawowych aspektów inteligentnego przemysłu lub I4.0, oprócz najnowocześniejszej rewolucji przemysłowej opartej na IIoT. Ponadto badamy bardziej dogłębne koncepcje, dostarczając różne przypadki użycia I4.0 opartego na IIoT. Ponadto rozdział zawiera również szczegółowe informacje na temat bieżących zastosowań, ograniczeń, otwartych problemów, wyzwań i przyszłych kierunków IIoT w inteligentnych branżach.
Symulacja w IV rewolucji przemysłowej
Zgodnie z definicją Boston Consulting Group, jednym z filarów technologicznych czwartej rewolucji przemysłowej jest symulacja, w której stwierdza się, że symulacje będą wykorzystywane w szerszym zakresie w operacjach zakładu, aby wykorzystać dane w czasie rzeczywistym i odzwierciedlić świat fizyczny w modelu wirtualnym , które mogą obejmować maszyny, produkty i ludzi. Umożliwi to operatorom przetestowanie i zoptymalizowanie ustawień maszyny dla następnego produktu w linii w świecie wirtualnym przed fizyczną zmianą, co skróci czas konfiguracji maszyny i zwiększy jakość. Według www.dictionary.com jedną z definicji symulacji jest reprezentacja zachowania lub właściwości jednego systemu poprzez użycie innego systemu, zwłaszcza programu komputerowego zaprojektowanego do tego celu. Sama symulacja nie jest pojęciem nowym; istnieje od czasu wynalezienia komputerów (przed czwartą rewolucją przemysłową). Jednak wraz z nadejściem czwartej rewolucji przemysłowej, w której wszystko zmienia się z zawrotną prędkością, znaczenie symulacji jeszcze bardziej wzrasta. Tu podamy przykłady różnych typów dostępnych symulacji, a także kilka przykładów i opisują korzyści płynące z symulacji, zwłaszcza w kontekście czwartej rewolucji przemysłowej.
Rodzaje symulacji
Symulacja to zazwyczaj model, który naśladuje charakterystykę i zachowanie systemu/procesu, bez faktycznego wykonywania lub uruchamiania systemu/procesu. Istnieją różne typy modeli, które zostaną szczegółowo opisane w tej sekcji.
Symulacja systemu fizycznego
Modele matematyczne układu fizycznego mogą przybierać różne formy, na przykład układy dynamiczne, modele statystyczne lub równania różniczkowe. W oprogramowaniu symulacyjnym i pakietach użytkownik musi po prostu wprowadzić (lub zaprogramować) informacje matematyczne, a oprogramowanie rozwiąże informacje (lub równania) i wygeneruje wynik.
Projekt kontrolera
Obszarem, w którym symulacja jest popularna, jest obszar teorii sterowania, którego celem jest zaprojektowanie sterowników dla systemów dynamicznych tak, aby zachowywały się w pożądany sposób. Zazwyczaj zachowaniem tych układów dynamicznych rządzą równania różniczkowe. Popularnym oprogramowaniem do tego rodzaju symulacji jest MATLAB, szeroko stosowany do rozwiązywania równań różniczkowych. W MATLAB dostępny jest również zestaw narzędzi Simulink, który zawiera bloki przeciągania i upuszczania dla użytkowników, którzy mogą potrzebować bardziej wizualnych reprezentacji modelu. Rozważmy popularny, ale prosty przykład, jakim jest układ masa-sprężyna, pokazany na rysunku.
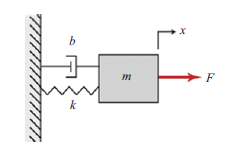
Blok ma masę m (kg), a jego przemieszczenie oznaczono przez x (m). Sprężyna ma stałą k (N/m), a amortyzator ma stałą b (Ns/m). Na blok działa również siła F (N). Sprężyna generuje siłę, która jest proporcjonalna do przemieszczenia bloku, mianowicie kx, a amortyzator generuje siłę, która jest proporcjonalna do prędkości bloku, mianowicie bx. Oczywiste jest, że suma sił (na bloku) to F - bx - kx. Korzystając z drugiego prawa Newtona, suma sił jest równa masie razy przyspieszenie, a zatem zastosowanie drugiego prawa Newtona do bloku da równanie różniczkowe, które określa ruch bloku, a mianowicie
F - bx - kx = mx (1)
Równanie (1) można zaimplementować w środowisku MATLAB Simulink w formie graficznej, wykorzystując integratory i matematyczne bloki wzmocnienia, co pokazano na rysunku
br>
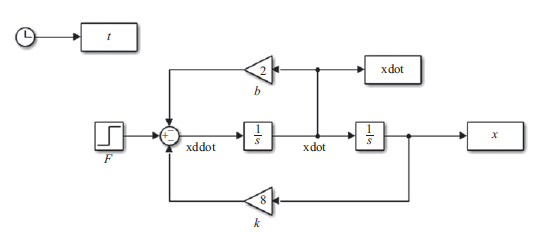
Teraz pożądane jest symulowanie (i przewidywanie) odpowiedzi systemu. Przypuśćmy, że stałe przyjmują wartości m = 1, b = 2, k = 8 i z zastrzeżeniem wejścia skoku jednostki (wielkości) w czasie t = 5. Dwa rysunki pokazują odpowiednio przemieszczenie i prędkość masy w odpowiedzi na siłę przyłożoną w czasie t = 5.
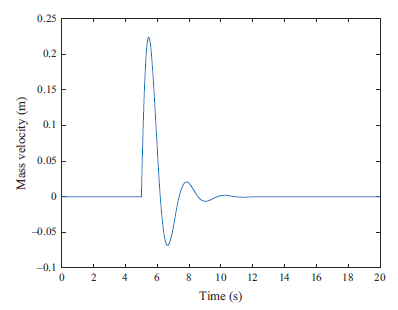
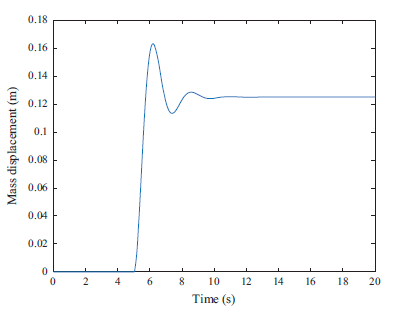
Z rysunku powyżej, można również sprawdzić inne sygnały, na przykład przyspieszenie. Dodatkowo można również zmienić przyłożoną siłę (na falę sinusoidalną lub na zaszumiony sygnał), a Simulink pokaże odpowiedź układu (przemieszczenie, prędkość, przyspieszenie). Wartości parametrów (np. masa, stała sprężyny, stała amortyzatora) również mogą być zmieniane i na tej podstawie można wykreślić odpowiedź. Stąd z tego przykładu można wywnioskować, że symulacja umożliwia:
- uzyskać głęboki wgląd w system, taki jak interakcja sygnałów wewnętrznych i
- przewidzieć reakcję systemu dla różnych wejść i wartości parametrów.
Z opracowanego modelu można teraz projektować i szeroko testować sterowniki, aż do uzyskania zadowalających wyników. Tutaj pokazujemy przykład konstrukcji kontrolera i pożądane jest uzyskanie niższego przeregulowania; jak pokazano na rysunku, przeregulowanie wynosi 20%, co jest bardzo wysokim wynikiem. Załóżmy, że wejście sterujące (czyli siła F) jest teraz funkcją sprzężenia zwrotnego położenia masy, tj. F = kp(r- x) gdzie r jest wartością odniesienia (docelową) wartości x; ta konfiguracja dla F jest znana jako sterowanie proporcjonalne, gdzie wejście sterujące (w tym przypadku F) jest proporcjonalne (pomnożone przez kp) do błędu śledzenia (którym jest w tym przypadku r). Diagram symulacji został teraz zmodyfikowany, aby uwzględnić to, jak pokazano na rysunku
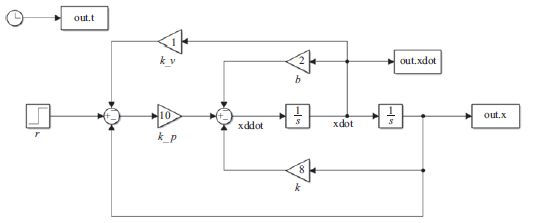
Poprzez ustawienie następujących zmiennych wartości; kp = 0,5, 1.0, 10.0 symulację można łatwo powtórzyć, a wyniki odpowiedzi x pokazano na rysunku.
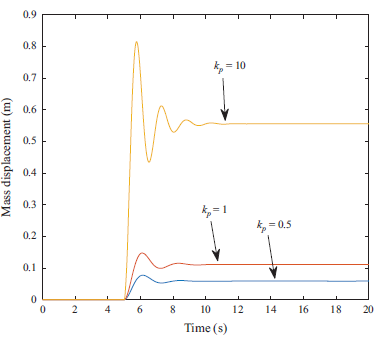
Z rysunku widać, że różne wartości wzmocnienia proporcjonalnego kp nie zmniejszają procentowego przeregulowania, aw rzeczywistości go zwiększają. Dlatego używana jest inna konfiguracja regulatora, a mianowicie F = kp(r-x) - kvx, gdzie dodano człon sprzężenia zwrotnego prędkości (i stąd otrzymujemy sprzężenie proporcjonalne prędkości), jak pokazano na rysunku
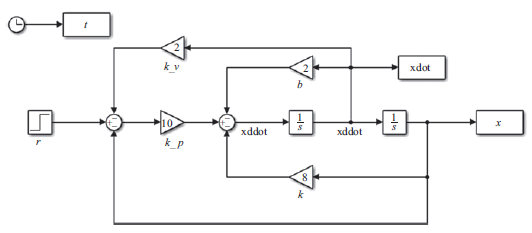
Następnie przeprowadzono kilka symulacji, przy czym ustalono kp = 10 i kv przyjmując wartości kv = 0.2 , 1.0, a wyniki pokazano na rysunku
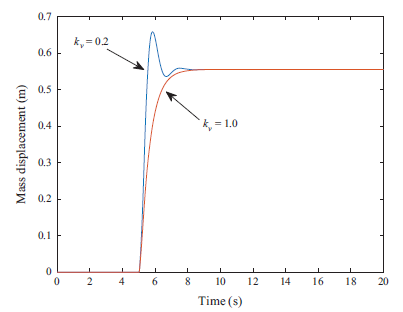
, gdzie jest teraz oczywiste, że sprzężenie zwrotne prędkości znacznie zmniejszyło przeregulowanie. Z tego widać, że oprócz umożliwienia przewidywania wyjścia dla różnych wejść i parametrów, symulacja umożliwiła testowanie różnych struktur regulatorów (od regulatora proporcjonalnego do regulatora proporcjonalnego prędkości) płynnie i prawie bez wysiłku.
Systemy mechaniczne
Wychodząc z symulacji matematycznej, symulacja graficzna to oparta na fizyce animacja rzeczywistych środowisk, która jest często wykorzystywana w obszarach takich jak układy dynamiczne i dynamika płynów. W obliczeniowej dynamice płynów (CFD) inżynierowie przeprowadzają symulacje w celu wizualizacji przepływu płynów, które mogą być następnie wykorzystane do przyspieszenia (i optymalizacji) projektowania wydajnych samolotów lub samochodów wyścigowych, na przykład, jak pokazano na rysunku, który przedstawia analizę przepływu powietrza wokół bolidu Formuły 1.

W symulacji dynamiki wieloobiektowej inżynier jest w stanie zwizualizować ruch kilku ciał (sztywnych lub elastycznych), biorąc pod uwagę czynniki mechaniczne, takie jak ciężar, masa, siły, tarcie i bezwładność. Symulacje wieloczłonowe są szeroko stosowane w wielu sektorach, takich jak transport i automatyka, jako integralna część projektowania samolotów , projektowanie konstrukcji zawieszenia samochodowego i badanie dynamiki interakcji pociąg-tor. Jest również szeroko stosowany w biomechanice, na przykład do nieinwazyjnej oceny obciążenia kości [6], badania pogorszenia/zwyrodnienia stawu kolanowego oraz kontroli ruchu chodu [8]. Istnieje wiele programów umożliwiających przeprowadzanie symulacji dynamiki wieloobiektowej; Wśród nich znajdują się COMSOL i ADAMS. Oprogramowanie to rozwiązuje również równania ruchu w celu wygenerowania wyników symulacji. Użytkownicy mogą wprowadzać te równania, a także wszelkie skojarzone ograniczenia, a oprogramowanie je rozwiąże, a wyniki zostaną odzwierciedlone w symulacji.
Systemy produkcyjne
Symulacja jest również szeroko stosowana w przemyśle wytwórczym, gdzie symulacja to komputerowe modelowanie rzeczywistego systemu produkcyjnego. W przemyśle wytwórczym zapotrzebowanie na wydajność nigdy nie było większe i będzie nadal rosło. Koszty materiałów, transportu i pracy rosną z roku na rok, a konkurencja również się nasila - istnieje ogromna presja, aby produkować więcej, produkować lepiej i taniej. Aby utrzymać przewagę konkurencyjną, firmy muszą zadbać o to, aby koszty związane z czasem, sprzętem i inwestycjami były brane pod uwagę i optymalizowane. Producenci mogą wykorzystywać symulację do analizowania i eksperymentowania ze swoimi procesami w środowisku wirtualnym, zawsze w celu osiągnięcia celów produkcyjnych przy możliwie najniższych kosztach. Ponieważ odbywa się to w oprogramowaniu, eliminuje (lub znacznie zmniejsza) potrzebę uruchamiania rzeczywistego fizycznego procesu - oszczędzając w ten sposób czas i koszty. Symulacja zapewnia również środki do testowania i wdrażania zasad Lean Manufacturing i Six Sigma. Istnieje również wiele dostępnych na rynku pakietów oprogramowania do symulacji produkcji, takich jak FlexSim i Arena, żeby wymienić tylko kilka. W studium przypadku producent sprzętu AGD chciał przeprojektować znaczną część procesu końcowego montażu wkładów do lodówki oraz stworzyć i wdrożyć skuteczny i odpowiedni harmonogram produkcji dla tego procesu. Celem jest (a) określenie optymalnej ilości przestrzeni buforowej dla wykładzin oraz (b) zlokalizowanie dodatkowej powierzchni na zakup nowego sprzętu. System produkcyjny wytwarza wkłady do lodówek o różnych rozmiarach, przenosi całe wkłady do obszaru, w którym są cięte, oklejane i prasowane, a następnie przenosi wkładki do obszaru wkładania.
Na rysunku wyzwanie polegało na drugim podprocesie, aby określić odpowiednią mieszankę różnych rozmiarów wkładek do przeniesienia do obszaru "prasy", aby zmaksymalizować wykorzystanie sprzętu systemowego, ponieważ przezbrojenie może zająć dużo czasu. Przed strefą prasową znajduje się strefa buforowa, która ma "złożyć" wkładki na później aby używać podczas pracy poza zmianą lub powolnej produkcji z powodu awarii lub wąskich gardeł. Potrzebna była większa przestrzeń buforowa do przechowywania przelewów, a dodatkowa powierzchnia musiała zostać zlokalizowana na zakup nowego sprzętu. Firma była gotowa zainwestować znaczną ilość sprzętu i personelu w przeprojektowanie zakładu produkcyjnego; jednak ilość sprzętu i siły roboczej nie była znana. Oprogramowanie symulacyjne Arena zostało wykorzystane do opracowania przyjaznego dla użytkownika modelu symulacyjnego. Model był bardzo szczegółowy i mógł oceniać dynamiczne przepływy produktów przez system, oceniając obsługę materiałów oraz operacje produkcyjne. Do uchwycenia wrażliwości systemu dla operacji produkcyjnych w systemie potrzebny był wysoki poziom szczegółowości. Analiza i obliczenia wykazały wymaganą przestrzeń buforową dla różnych scenariuszy produkcyjnych i dla wielu układów urządzeń. Aby zweryfikować model, szczegółowa animacja wyświetlała każdą wkładkę podczas jej przemieszczania się przez system (i ujawniała wąskie gardła w systemie) i pokazywała dynamiczny stan buforów, weryfikując w ten sposób model. Wreszcie, dzięki realizacji przewidywanego harmonogramu produkcji, możliwe było wykonanie projektu z minimalnymi zasobami systemowymi niezbędnymi do realizacji celów produkcyjnych. W oparciu o model, sprzęt wyważający i koszty przenośników obliczono różne kompromisy kosztowe w stosunku do przepustowości i wielkości produkcji. W innym studium przypadku firma zajmująca się dystrybucją kosmetyków wykorzystała FlexSim do stworzenia modelu symulacyjnego swojego centrum dystrybucji, który został następnie wykorzystany jako narzędzie wspomagające podejmowanie decyzji. Korzystając z modelu, decydenci w firmie mogli szybko wprowadzać zmiany w zmiennych wejściowych (takich jak rozmieszczenie produktów, wielkości zamówień, asortyment zamówień, plany personelu/harmonogramu, wydajność operatorów i wiele innych) oraz dokładnie określić efekty. Model jest elastyczny i można go zmieniać i analizować w ciągu kilku minut. Stworzono pulpit nawigacyjny, aby natychmiast informować operatora/inżyniera o aktualnym stanie systemu, o tym, co wydarzyło się w ciągu dnia pracy, wskaźnikach wykorzystania operatora oraz zrównoważeniu obszarów kompletacji i stref kompletacji.
Systemy transportowe
Symulacja jest również wykorzystywana w dyscyplinie ruchu i transportu, gdzie urbaniści i inżynierowie transportu wykorzystują symulacje do planowania, projektowania i obsługi systemów transportowych. W transporcie symulacja jest bardzo ważna, ponieważ jej modele są bardzo skomplikowane, nieprzewidywalne, a czasem chaotyczne i dlatego uzyskanie matematycznego (czy analitycznego) rozwiązania jest prawie niemożliwe. W tych symulacjach projektant może zmieniać warunki (takie jak liczba pasów, czasy sygnalizacji świetlnej, położenie skrzyżowań itp.) i zobaczyć ich efekt. Symulacja ruchu odbywa się często na dwóch poziomach - makroskopowym i mikroskopowym. Symulacja mikroskopowa jest wykonywana na niskim poziomie, co obejmuje pojedyncze pojazdy, gdzie badane jest zachowanie pojazdów w odpowiedzi na zmiany zmiennych. Natomiast symulacja makroskopowa jest na wyższym poziomie, gdzie symulacja wykonywana jest dla sieci drogowej. Dostępne są różne pakiety oprogramowania do symulacji ruchu, takie jak SUMO (Simulation of Urban Mobility) i Vissim, żeby wymienić tylko kilka.
Interaktywna symulacja
Interaktywna symulacja zwykle obejmuje człowieka, gdzie symulator reaguje na działania człowieka. Jest to nieco podobne (lub powiązane) z wirtualną rzeczywistością, w której wirtualne środowisko jest platformą symulacyjną. Takie symulacje umożliwiają wizualizację otoczenia bez konieczności wchodzenia w nie. Na przykład istnieją symulatory jazdy, symulatory motocykli i symulatory lotu. Chociaż wiele z nich jest wykorzystywanych do rozrywki i gier, są one również bardzo przydatne do treningu. Na przykład symulator lotu może być wykorzystywany jako znacząca część szkolenia pilota; mimo że wymagane jest prawdziwe szkolenie w terenie, symulator może zapewnić większą część szkolenia, oszczędzając w ten sposób koszty i czas.
Symulacje reagujące fizycznie
Symulacje reagujące fizycznie to te, które wytwarzają ruchy mechaniczne, wibracje lub dźwięki w odpowiedzi na działania danej osoby; Symulacja kliniczna jest jednym z tych typów symulacji, w których symulowane są scenariusze kliniczne. Zwykle ma postać ludzkiego manekina, który może symulować różne stany, takie jak (wielokrotne) zatrzymanie akcji serca lub bycie przedmiotem chirurgii , w celu szkolenia studentów medycyny i pielęgniarstwa w reagowaniu na różne warunki, z jakimi mogą się zetknąć w przyszłej karierze zawodowej. Innym przykładem symulacji reagującej fizycznie jest taka, która generuje fizyczne reakcje, gdy użytkownik wykonuje określoną czynność. Na przykład systemy dotykowe symulują dotyk, wytwarzając siły, wibracje lub ruchy na użytkownika w odpowiedzi na jego działania. Ważnym zastosowaniem haptyki jest teleoperacja, w której użytkownik zdalnie steruje systemem (lub różnymi agentami) w środowiskach niebezpiecznych, takich jak sterowanie manipulatorami robotów do obsługi materiałów radioaktywnych lub kontrolowanie roju robotów w trudnych warunkach. W tych zadaniach byłoby bardzo korzystne, gdyby siły lub ruchy były zwracane do odczuwania przez użytkownika/operatora. W przypadku zdalnie sterowanego manipulatora robota, poprzez dostarczenie informacji zwrotnej o sile reakcji, umożliwiłoby to użytkownikowi/operatorowi określenie odpowiedniego poziomu siły chwytu do zastosowania. Innym zastosowaniem teleoperacji dotykowej jest robotyka chirurgiczna, gdzie chirurg wykonuje operację zdalnie sterując robotem, który jest w stanie osiągnąć znacznie większą precyzję. Jedną z kluczowych technologii wspomagających jest sprzężenie zwrotne siły dostarczane chirurgowi. Da Vinci firmy Intuitive Surgical jest jednym z takich istniejących robotów chirurgicznych do użytku klinicznego.
Symulacja rzeczywistości wirtualnej
Rzeczywistość wirtualna to platforma, która zapewnia wciągające wrażenia dla użytkownika. Był używany w wielu dziedzinach. Na przykład Balfour Beatty Rail wykorzystuje wirtualną rzeczywistość do symulacji konstrukcji, która ma zostać zbudowana, nawet przed podniesieniem łopaty. Planowanie urbanistyczne to kolejny obszar, który czerpie korzyści z wirtualnej rzeczywistości. Amerykańskie Stowarzyszenie Architektów Krajobrazu nazywa wirtualną rzeczywistość "potężnym narzędziem dla architektów krajobrazu, architektów, planistów i deweloperów - naprawdę każdego zaangażowanego w projektowanie naszych środowisk zabudowanych i naturalnych". Wciągający charakter VR, który pozwala widzom na poznanie symulowanego krajobrazu 3D z wielu punktów widzenia, może być bardzo przydatnym narzędziem dla urbanistów . Mogą go używać do przerysowywania ulic i dzielnic, oferując rzeczywiste i wyimaginowane widoki istniejących i proponowanych inwestycji. Rzeczywistość wirtualna może być również wykorzystywana do zwiększania wrażenia zwiedzających miejsca historyczne, gdzie odwiedzający mogą teraz aktywnie angażować się w eksponaty, na przykład, aby "doświadczyć" miejsc historycznych lub wydarzeń; można to wykorzystać, aby przyciągnąć znacznie większą publiczność (zwłaszcza młodsze dzieci), w przeciwieństwie do tradycyjnych metod wystawienniczych, które zwykle przyciągają tylko starsze pokolenie. Jednym z takich miejsc, które dodało tę funkcję, jest Instytut Franklina.
Korzyści z symulacji
Konserwacja predykcyjna
W procesach przemysłowych nieplanowane przestoje są bardzo kosztowne, zarówno pod względem zakłóceń produkcji/usług (utrata przychodów), jak i kosztów przywrócenia obsługi majątku. Niedziałający proces produkcyjny/urządzenia mogą nadal oznaczać straty w przychodach rzędu tysięcy dolarów na minutę. Regularna zaplanowana konserwacja może pomóc w uniknięciu (lub skróceniu) nieplanowanych przestojów, ale nie gwarantuje, że proces/sprzęt nie ulegnie awarii. Dlatego bardzo przydatna i cenna byłaby możliwość przewidzenia, kiedy proces lub sprzęt ulegnie awarii, tak aby można było podjąć niezbędne i odpowiednie działania naprawcze w zakresie konserwacji; zmniejsza to również częstotliwość prac konserwacyjnych. Wszystkie te korzyści można osiągnąć dzięki konserwacji predykcyjnej. Aby przeprowadzić konserwację predykcyjną, dane operacyjne w normalnych warunkach są uzyskiwane z procesu/urządzenia. Następnie dane są przetwarzane w celu stworzenia modelu symulacyjnego procesu/urządzenia (znanego również powszechnie jako Digital Twin). Model można również opracować przy użyciu pierwszych zasad lub równań fizycznych, które rządzą zachowaniem procesu/urządzenia (oprócz uzyskanych danych operacyjnych). Model zostanie następnie wykorzystany do symulacji wadliwych warunków w celu uzyskania danych podczas wadliwego działania (które określimy jako wadliwe dane). Wadliwe dane zostaną następnie wykorzystane do opracowania modelu predykcyjnego lub algorytmu predykcyjnego. Algorytm jest następnie wdrażany, aby działał równolegle z procesem/sprzętem, odbierając dane procesu/urządzenia w czasie rzeczywistym oraz przetwarzając i analizując dane w celu przewidzenia wystąpienia błędu oraz czasu, zanim proces/urządzenie ulegnie awarii . Przebieg konserwacji predykcyjnej zademonstrowano na pompie triplex z trzema tłokami. Symulacja 3D wieloobiektu jest opracowywana (przy użyciu modelu CAD producenta) i optymalizowana. Po opracowaniu symulacji wieloobiektowej (cyfrowy bliźniak) do modelu dodawane są zachowania awaryjne w celu symulacji wadliwych warunków, takich jak wyciek z uszczelnienia i zablokowany wlot. Na tej podstawie generowane są (błędne) dane dla wszystkich możliwych kombinacji usterek (uszkodzeń pojedynczych, a także usterek występujących jednocześnie). Przeprowadzono liczne symulacje, aby uwzględnić efekty kwantyzacji w czujniku - byłoby to prawie niemożliwe (i bardzo kosztowne) bez modelu symulacyjnego (lub Digital Twin). Wadliwe dane są następnie wykorzystywane do trenowania algorytmu uczenia maszynowego, który będzie rozpoznawał wzorce błędnych danych. Po opracowaniu algorytmu uczenia maszynowego jest on następnie testowany z większą liczbą danych symulacyjnych, aby zweryfikować jego skuteczność, a gdy to zrobisz, algorytm może zostać wdrożony w systemie.
Prognoza
Symulacja umożliwia użytkownikom przewidywanie wydajności systemu dla danych wejść i parametrów. Jednym z takich przykładów jest Nowa Zelandia, gdzie zapewnione są nieprzerwane dostawy z krajowej sieci energetycznej. Moc wytwórcza i zużycie obciążenia muszą być zbilansowane, gdzie musi istnieć wystarczająca rezerwa mocy, aby zaspokoić każde (wzrost) zapotrzebowania, a mimo to rezerwa mocy nie może być zbyt wysoka, ponieważ utrzymywanie wytworzonej mocy w rezerwie jest kosztowne. W związku z tym istnieje potrzeba precyzyjnego obliczenia minimalnej rezerwy wymaganej do zapewnienia niezawodności sieci. Tradycyjnie, aby to osiągnąć, do obliczenia wymaganej rezerwy minimalnej stosowano arkusze kalkulacyjne, co wymagało od pracownika wykonania wielu ręcznych czynności i uruchomienia niektórych skryptów. Spowodowało to sztywność, w której trudno było włączyć nowe generatory i przestrzegać coraz bardziej skomplikowanych zasad. Aby przezwyciężyć tę trudność, w MATLAB i Simulink opracowano narzędzie do zarządzania rezerwami (RMT), zawierające szczegółowy model całej sieci, hermetyzujący generatory, obciążenie i połączenia między dwiema głównymi wyspami Nowej Zelandii. Co 30 minut symulacje są uruchamiane w RMT w oparciu o informacje minuta po minucie w celu określenia aktualnie wymaganej rezerwy. W tych symulacjach zmierzone dane (mierzone co minutę) są wprowadzane do RMT i weryfikowane z rzeczywistą wydajnością generatora. Takie podejście umożliwiło udoskonalenie modelu sieci i poszczególnych modeli generatorów. W ten sposób zapewnione jest niezawodne zasilanie (wystarczająca rezerwa) w opłacalny sposób.
Projektowanie, rozwój i szkolenia
Jak wyjaśniono wcześniej, symulacja umożliwia powtarzalne działanie systemu, szybko i bez żadnych kosztów. Dzięki temu użytkownik (lub projektant) może modyfikować parametry oraz wizualizować i oceniać wydajność systemu. Dzięki temu użytkownik/projektant może szybko, bez kosztów i bezpiecznie przetestować symulację (produktu lub systemu) pod kątem różnych parametrów i ustawień. Jest to szczególnie nieocenione w przypadku wrażliwych systemów, takich jak samoloty lub statki kosmiczne, które są drogie, wrażliwe i potencjalnie niebezpieczne. Powtarzające się symulacje, na podstawie których użytkownik/projektant może zwizualizować/ocenić wydajność, mogą przyspieszyć proces projektowania i rozwoju, a tym samym skrócić czas wprowadzenia produktu (lub systemu) na rynek. Zdolność symulacji do szybkiego, bezpiecznego i bezkosztowego uruchamiania systemu w sposób powtarzalny jest również korzystna w przypadku szkolenia ludzi, ponieważ znacznie przyspiesza i zmniejsza koszty szkolenia ludzi. Posiadanie ustalonego symulatora umożliwia szkolenie danej osoby o wiele szybciej. Na przykładzie symulatora lotu przedstawiono zalety wykorzystania symulacji do szkolenia ludzi, zwłaszcza w misjach o kluczowym znaczeniu dla bezpieczeństwa.
1. Łatwe powielanie scenariuszy: Stażyści muszą znać wiele scenariuszy, aby mogli się zakwalifikować i muszą doświadczyć tych scenariuszy. Symulator może łatwo tworzyć te scenariusze i konsekwentnie je replikować. Ponadto za pomocą symulatora można dostosować program szkoleniowy do potrzeb osoby szkolącej się, co dodatkowo przyczynia się do przyspieszenia szkolenia.
2. Szybsze szkolenie: Ze względu na łatwość i spójność replikowanych scenariuszy, pilot może zostać przeszkolony znacznie szybciej. Symulacja pozwala również trenującemu na popełnianie błędów bez większych konsekwencji, co dodatkowo przyspiesza trening.
3. Tańsze szkolenie: Replikacja niektórych scenariuszy może być bardzo kosztowna, a symulator eliminuje ten problem.
4. Bezpieczniejsze szkolenie: Od poprzedniego punktu, niektóre scenariusze mogą być nawet niebezpieczne do odtworzenia (zwłaszcza sytuacje awaryjne związane z samolotami), i po raz kolejny symulator eliminuje ten problem.
Uznaje się jednak, że podczas szkolenia zawsze wymagane jest prawdziwe doświadczenie w terenie, a symulacja może osiągnąć pewne ograniczenia. Mimo to symulacja zmniejsza czas, koszty i ryzyko szkolenia, a zatem nadal stanowi integralny element szkolenia, zwłaszcza w zastosowaniach o znaczeniu krytycznym.
Przemysł 4.0 i inteligentne miasta
Industry 4.0 reprezentuje czwartą rewolucję, jaka dokonała się w przemyśle wytwórczym. Ta rewolucja nastąpiła dzięki cyfryzacji całego procesu produkcyjnego, która powoduje znaczną zmianę w sposobie wytwarzania produktów dzisiaj. Od pierwszej rewolucji przemysłowej, która obejmowała mechanizację poprzez energię parową, do drugiej rewolucji przemysłowej, która obejmowała masową produkcję i linie montażowe z wykorzystaniem silników i elektryczności, ogromny skok w produkcji nastąpił w trzeciej rewolucji przemysłowej, w której komputery i automatyzacja zostały szeroko wprowadzone na scenę przemysłową . Programowalne sterowniki logiczne (PLC) i roboty zostały wykorzystane do znacznej poprawy tempa, ilości i jakości produkcji, co w konsekwencji przyniosło dużą zmianę standardów życia w dzisiejszych miastach. Ponieważ produkty umożliwiające automatyzację można szybciej wytwarzać i wprowadzać na rynek przy niższych kosztach, ceny produktów na rynku znacznie spadły, co pozwala dużej części populacji zaangażować się w pojawienie się technologii, takich jak komputery i smartfony. Z biegiem czasu doprowadziło nas to do czwartej rewolucji przemysłowej, która bierze to, co rozpoczęło się w trzeciej rewolucji, i wzbogaca ją o inteligentne i autonomiczne systemy zasilane danymi i sztuczną inteligencją (AI). Dziś komputery mają możliwość łączenia się i komunikowania ze sobą na bardzo dużą skalę, dzięki szybkiemu rozwojowi Internetu, technologii komunikacji mobilnej, mocy obliczeniowej i pojemności pamięci. Rozwój posunął się do tego stopnia, że dzisiejsze komputery są zdolne do podejmowania szybkich, podobnych do ludzkich decyzji bez udziału człowieka, co byłoby niemożliwe na taką skalę przed rewolucją przemysłową. Poprzez ekspansję systemów cyber-fizycznych, Internetu Rzeczy (IoT) i AI, Przemysł 4.0 stał się rzeczywistością, prowadząc do istnienia inteligentnej fabryki. Inteligentna fabryka to fabryka, która jest bardziej wydajna i produktywna oraz mniej marnotrawna. Działa poprzez inteligentne i połączone ze sobą maszyny, które są w stanie samodzielnie podejmować decyzje, komunikować się i rejestrować dane w ujednoliconej bazie danych. Ustanowienie Przemysłu 4.0 wprowadza nową koncepcję zwaną Smart Cities, która odnosi się do miast, które wykorzystują duże ilości dostępnych technologii danych i komunikacji w celu poprawy wydajności i jakości życia oraz usług miejskich, aby ostatecznie zmniejszyć zużycie zasobów, marnotrawstwo i ogólne koszty. Zgodnie z podsumowaniem sesji inicjatywy Belt and Road dotyczącej miejskich rozwiązań przemysłowych w ramach Organizacji Narodów Zjednoczonych ds. Rozwoju Przemysłowego, koncepcja inteligentnego miasta to paradygmat rozwoju miejskiego integrujący nowe innowacyjne pomysły, koncepcje i pojawiające się technologie, takie jak IoT, Internet usług (IoS), Internetu Ludzi (IoP) i Internetu Energii (IoE), które ostatecznie tworzą koncepcję Internetu wszystkiego (IoE), znanego również jako Przemysł 4.0 lub Czwarta Rewolucja Przemysłowa. Koncepcja ta ma na celu zapewnienie skutecznych i wysokiej jakości usług publicznych i infrastruktury w czasie rzeczywistym, a tym samym lepszej jakości życia obywateli i przejście w kierunku zrównoważonych miast . Wraz z rosnącą innowacją i wprowadzaniem nowszych technologii, inteligentne miasta są już dziś rzeczywistością i nadal się rozwijają i stają się bardziej przedefiniowane. Według danych CB Insights dotyczących wielkości rynku, globalny rynek inteligentnych miast ma wynieść 1,4 biliona USD w ciągu najbliższych 6 lat. Miasta można sklasyfikować jako miasta inteligentne, gdy są w stanie zbierać i analizować duże ilości danych z wielu różnych branż, aby zoptymalizować wykorzystanie zasobów i czasu w celu maksymalizacji zrównoważonego rozwoju i efektywności środowiskowej oraz zminimalizowania marnotrawstwa czasu i zasobów. Duże ilości danych są pozyskiwane z dużej liczby czujników, urządzeń i oprogramowania, które są ze sobą połączone, aby udostępniać dane jednemu źródłu, co pozwala na szybką i systematyczną analizę wszystkich danych. Aby miasto naprawdę stało się miastem inteligentnym, musi spełnić te kryteria dla dużej liczby przestrzeni, w tym zarządzania ruchem, zarządzania parkingami, zarządzania energią, zarządzania odpadami i planowania infrastruktury. Według artykułu badawczego Politechniki Białostockiej, norma ISO37120 jest najbardziej praktyczną metodą pomiaru wydajności miasta. Jednym z kluczowych aspektów definiujących "inteligentność" inteligentnego miasta jest możliwość analizowania dużych ilości danych w krótkich odstępach czasu w celu zapewnienia optymalizacji usług w czasie rzeczywistym. Chociaż dostępna dziś moc obliczeniowa umożliwia bardzo szybką analizę danych, większość form danych występuje w postaci nieustrukturyzowanej, która wymaga podobnych do ludzkich zdolności rozumienia języka naturalnego, rozpoznawania wzorców i podejmowania decyzji. Dzięki sztucznej inteligencji i technikom uczenia maszynowego jest to możliwe. Algorytmy uczenia maszynowego (MLA) zmieniają sposób, w jaki zbieramy, przetwarzamy, kontrolujemy i analizujemy dane, aby zapewnić dokładne prognozy, które umożliwiają taką analizę danych w wielu branżach. W rzeczywistości sztuczna inteligencja i uczenie maszynowe są już dziś wykorzystywane od przemysłu wodnego i energetycznego po zarządzanie ruchem, organy ścigania i branżę opieki zdrowotnej ze sprawdzonymi wynikami. Przy dużym i szybkim napływie danych w miastach co sekundę, sztuczna inteligencja odgrywa kluczową rolę w rozwoju inteligentnych miast.
Sztuczna inteligencja
Termin "sztuczna inteligencja" został po raz pierwszy ukuty przez Johna McCarthy′ego w Propozycji Projektu Sztucznej Inteligencji w Dartmouth w 1956 roku, kiedy zaprosił grupę badaczy do wzięcia udziału w letnich warsztatach o nazwie Dartmouth Summer Research Project on Artificial Intelligence w celu omówienia szczegółów tego, co mogłoby stać się polem AI. Badacze składali się z ekspertów z różnych dyscyplin, takich jak symulacja języka, sieci neuronowe i teoria złożoności. Termin "sztuczna inteligencja" został wybrany ze względu na jego neutralność, to znaczy, aby uniknąć nazwy, która zbytnio skupiała się na którymkolwiek z projektów , które były w tym czasie realizowane. Propozycja konferencji głosiła: "Badanie ma opierać się na przypuszczeniu, że każdy aspekt uczenia się lub jakakolwiek inna cecha inteligencji może być w zasadzie tak dokładnie opisana, że można stworzyć maszynę do jej symulacji. Podjęta zostanie próba znalezienia sposobu na to, by maszyny posługiwały się językiem, formowały abstrakcje i koncepcje, rozwiązywały problemy zarezerwowane obecnie dla ludzi i doskonaliły się". Jednak sztuczna inteligencja stała się popularniejsza dopiero w ostatnim czasie dzięki rosnącym wolumenom danych, opracowywaniu bardziej zaawansowanych algorytmów oraz udoskonalaniu mocy obliczeniowej i pamięci masowej. Ponadto, wraz ze wzrostem konieczności automatyzacji bardziej szczegółowych zadań w dziedzinach takich jak produkcja, sztuczna inteligencja zyskuje coraz większą uwagę w dzisiejszym świecie. W przeszłości rozwój sztucznej inteligencji ewoluował etapami. Od lat 50. do 70. rozwój sztucznej inteligencji obracał się wokół sieci neuronowych. Od lat 80. do 2010 r. uczenie maszynowe stało się popularne, a dziś boom sztucznej inteligencji jest napędzany przez głębokie uczenie. Sieć neuronowa składa się z połączonych ze sobą warstw węzłów, zaprojektowanych w celu bardzo prostego odtworzenia połączeń neuronów w mózgu. Każdy węzeł reprezentuje neuron, a połączenia w sieci neuronowej zaczynają się od wyjścia jednego sztucznego neuronu do wejścia drugiego. Przykładem sieci neuronowej jest splotowa sieć neuronowa (CNN). Sieci CNN zawierają pięć różnych typów warstw, którymi są warstwy wejściowe, konwolucji, łączenia, w pełni połączone i wyjściowe. CNN okazały się obiecujące w zastosowaniach, takich jak klasyfikacja obrazów i wykrywanie obiektów, przetwarzanie języka naturalnego (NLP) i prognozowanie. Innym przykładem sieci neuronowych jest rekurencyjna sieć neuronowa (RNN). RNN wykorzystują informacje sekwencyjne, takie jak dane ze znaczników czasu z czujników lub zdania złożone z sekwencji słów. Sieci RNN działają inaczej niż tradycyjne sieci neuronowe, w których nie wszystkie dane wejściowe do sieci RNN są od siebie niezależne, a dane wyjściowe dla każdego elementu zależą od obliczeń elementów poprzedzających. Są szeroko stosowane w prognozowaniu, aplikacjach szeregów czasowych, analizie sentymentu i innych aplikacjach tekstowych. Uczenie maszynowe to technika analizy danych, która uczy komputery uczenia się na podstawie doświadczenia, czyli z powtarzających się wzorców. MLA wykorzystują metody obliczeniowe, aby uczyć się bezpośrednio z danych, bez początkowego wymagania modelu w postaci z góry określonego równania. Wraz ze wzrostem wielkości próbki algorytm dostosowuje się i poprawia się jego wydajność. Uczenie maszynowe wykorzystuje dwa rodzaje technik, czyli uczenie nadzorowane i uczenie nienadzorowane. Nadzorowane metody uczenia, takie jak klasyfikacja i regresja, opracowują model predykcyjny oparty zarówno na danych wejściowych, jak i wyjściowych, dzięki czemu zyskuje możliwość przewidywania danych wyjściowych na podstawie danych wejściowych, podczas gdy nienadzorowane metody uczenia, takie jak grupowanie grup, interpretują dane na podstawie danych wejściowych, tak że mogą znaleźć ukryte złożone wzorce, które istnieją w danych. Powszechnymi algorytmami klasyfikacji są maszyny wektorów nośnych (SVM) i k-najbliższy sąsiad. Typowe algorytmy technik regresji to regresja liniowa i regresja nieliniowa. Typowe algorytmy klastrowania to klastrowanie hierarchiczne i grupowanie subtraktywne. Sztuczna inteligencja zyskuje na znaczeniu z wielu powodów. Wykorzystując gromadzone przez lata dane, sztuczna inteligencja automatyzuje powtarzalne uczenie się i proces odkrywania. Jednak sztuczna inteligencja to coś więcej niż tylko sprzętowa automatyzacja robotów, która po prostu automatyzuje zadania ręczne. Sztuczna inteligencja ma moc wykonywania dużych i częstych zadań niezawodnie i bez zmęczenia. Co ważniejsze, sztuczna inteligencja może nawet zautomatyzować zadania które wymagają zdolności poznawczych, które wcześniej były możliwe tylko dla ludzi. Ponadto sztuczna inteligencja włącza inteligencję do istniejących produktów. W większości przypadków sztuczna inteligencja nie będzie pakowana jako indywidualny produkt. Zamiast tego produkty, które już istnieją na rynku, będą wyposażone w możliwości sztucznej inteligencji. Przykładami takiego włączenia dzisiaj są dodanie Siri do nowszych generacji produktów Apple i dodanie Watsona do usług obliczeniowych IBM. Dzięki dużej ilości danych, które są obecnie tworzone i przechowywane, a także tonom danych, które już istnieją, Sztuczna inteligencja w postaci automatyzacji, platform konwersacyjnych, botów i inteligentnych maszyn usprawni wiele technologii w domach i miejscu pracy w wielu dziedzinach, od wywiadu bezpieczeństwa po finanse i bankowość. Co więcej, sztuczna inteligencja może dostosowywać się za pomocą algorytmów progresywnego uczenia się, dzięki czemu zamiast programistów kodujących reguły na podstawie danych, dane mogą wykonywać programowanie poprzez generowanie reguł na podstawie przeszłych zdarzeń. Sztuczna inteligencja szuka struktur i wzorców w danych, co zamienia algorytm w predyktor lub klasyfikator, ponieważ może następnie wyszukiwać podobne wzorce w nowych danych, aby podejmować decyzje. Na przykład algorytm AI zaprogramowany do gry w szachy może nauczyć się następnego zestawu ruchów, które musi wykonać, na podstawie poprzednich ruchów i tego, czy wynik ruchów był pozytywny, czy negatywny. Podobnie algorytm usługi przesyłania strumieniowego filmów, takiej jak Netflix, zaprogramowany do polecania filmów użytkownikom, może nauczyć się, jakie filmy preferują niektórzy użytkownicy, i polecić filmy podobnego gatunku, aby zapewnić użytkownikom większą wygodę. Ponieważ modele otrzymują więcej różnych rodzajów danych, dostosowują się. Gdy użytkownik uczy się nowego gatunku filmów i zaczyna preferować ten gatunek; algorytm uczy się tej preferencji i zaczyna polecać różne rodzaje filmów z tego nowo preferowanego gatunku. Techniką AI polegającą na dostosowywaniu się do danych jest propagacja wsteczna, która umożliwia dostosowanie modelu poprzez trenowanie i dodawanie danych, gdy początkowe wyniki są nieprawidłowe. Ponieważ moc obliczeniowa i pamięć gwałtownie wzrosły w poprzednich dekadach, w ostatnich latach możliwe stało się analizowanie większych ilości i głębi danych za pomocą sieci neuronowych, które mają wiele ukrytych warstw. Jeszcze kilka lat temu zbudowanie algorytmu sieci neuronowej do wykrywania oszustw z zaledwie pięcioma ukrytymi warstwami było prawie niemożliwe. To samo zadanie można łatwo wykonać dzisiaj, korzystając z istniejącej mocy obliczeniowej i dużych zbiorów danych. Ponadto do trenowania modeli uczenia głębokiego z wieloma ukrytymi warstwami potrzebne są duże ilości danych, ponieważ uczą się one bezpośrednio z danych. Im więcej danych jest podawanych do modeli, tym modele stają się dokładniejsze. Na przykład produkty takie jak Alexa firmy Amazon, wyszukiwarka Google i Zdjęcia Google, które codziennie uzyskują duże ilości danych poprzez interakcje z ludźmi i są oparte na głębokim uczeniu, stają się tym dokładniejsze, im częściej są używane. W dziedzinie medycyny techniki sztucznej inteligencji pochodzące z głębokiego uczenia się, takie jak klasyfikacja obrazów i rozpoznawanie obiektów, mogą obecnie wykrywać raka w obrazowaniu metodą rezonansu magnetycznego (MRI) z dokładnością podobną do tej, jaką mają doświadczeni radiolodzy. Ostatecznie, dzięki sztucznej inteligencji, jakość prognoz jest prawie całkowicie zależna od jakości danych. To sprawia, że dane stają się własnością intelektualną. Ponieważ dane odgrywają teraz ważniejszą rolę niż kiedykolwiek wcześniej, mogą one stworzyć przewagę konkurencyjną. Dane o najwyższej jakości oznaczają najwyższą jakość prognoz, klasyfikacji i rekomendacji. Typowe zastosowania sztucznej inteligencji to widzenie maszynowe i rozpoznawanie obiektów, NLP i przetwarzanie kognitywne. Rola sztucznej inteligencji w inteligentnych miastach w większości wykorzystuje te trzy aplikacje, które zostały omówione poniżej.
Widzenie maszynowe i rozpoznawanie obiektów
Według Tractica News prognozuje się, że do 2022 r. rynek sprzętu i oprogramowania do wizji komputerowej wyniesie 48,6 mld USD, przy łącznym rocznym tempie wzrostu wynoszącym 32,9 procent . Widzenie komputerowe to dziedzina badań obejmująca wysiłki na rzecz zapewnienia komputerom możliwości wizualnego odczuwania świata za pomocą kamer, w sposób, w jaki ludzie używają oczu do interakcji ze światem. Odbywa się to poprzez automatyczne wyodrębnianie, analizowanie i rozumienie cennych informacji z obrazów. Jednym z najpopularniejszych obecnie zastosowań widzenia maszynowego jest wykrywanie obiektów. Wykrywanie obiektów to aspekt widzenia maszynowego, który obejmuje wykrywanie i klasyfikowanie obiektów na obrazie lub filmie, takich jak ludzie, pojazdy i różne rodzaje żywności. Wykrywanie obiektów umożliwia automatyzację powtarzalnych zadań, takich jak liczenie tłumu, co wcześniej było możliwe tylko dzięki zastosowaniu bardziej skomplikowanych i kosztownych czujników, a niemożliwe przy użyciu zwykłych kamer. Wykrywanie obiektów istnieje już od dłuższego czasu; jednak stał się bardzo popularny dopiero w ostatnich latach dzięki odkryciu najnowocześniejszych modeli wykrywania obiektów opartych na sztucznej inteligencji, które sprawiają, że proces wykrywania obiektów jest niezwykle dokładny i możliwy z prędkością w czasie rzeczywistym. Obecnie narzędzia takie jak interfejs programowania aplikacji (API) Tensorflow Object Detection umożliwiają bardzo szybkie uczenie modelu wykrywania obiektów na przeciętnym komputerze wyposażonym w procesor graficzny (GPU). W rezultacie technologie wykrywania i rozpoznawania obiektów stały się powszechnie dostępne dla każdego, z którymi można eksperymentować i umożliwić sobie stanie się popularną dziedziną badań o szybkim rozwoju. Różne techniki wykrywania obiektów, które istnieją, obejmują splotową sieć neuronową opartą na regionie (RCNN), Fast RCNN, Faster RCNN, detektor pojedynczego strzału multibox (SSD), patrzysz tylko raz (YOLO) i RetinaNet. Niektóre z tych technik wyjaśniono poniżej. Podejście do głębokiego uczenia się do wykrywania obiektów wykorzystuje model wykrywania obiektów RCNN .Przed zrozumieniem działania modelu RCNN konieczne jest zrozumienie, jak działa model CNN. Model CNN przyjmuje obraz jako dane wejściowe, dzieli obraz na różne regiony, traktuje każdy region jako osobny obraz, przekazuje regiony przez CNN i klasyfikuje je na różne klasy oraz łączy regiony z klasami, aby uzyskać oryginalny obraz z wykryte obiekty. Korzystanie z modelu opartego na CNN ma tę wadę, że obiekty na obrazie mogą mieć różne lokalizacje przestrzenne i proporcje. Ten problem można rozwiązać, dzieląc obraz na dużą liczbę regionów; wymaga to jednak dużej mocy obliczeniowej i zajmuje dużo czasu. RCNN rozwiązuje ten problem, przekazując CNN tylko niektóre obszary zainteresowań (RoI). Odbywa się to za pomocą metody propozycji regionu, takiej jak wyszukiwanie selektywne. Wyszukiwanie selektywne pobiera obraz wejściowy, generuje początkowe podsegmentacje w celu wytworzenia różnych regionów obrazu, a następnie łączy podobne regiony w oparciu o podobieństwo koloru, tekstury, rozmiaru i kształtu, aby utworzyć większe segmentacje, a te segmentacje dają ostateczną lokalizację obiektu, czyli , ROI. Model RCNN jest opracowywany przez przeszkolenie wstępnie wytrenowanego modelu CNN przez trenowanie ostatniej warstwy sieci neuronowej na podstawie liczby klas, które mają zostać wykryte. Po wdrożeniu modelu pobiera obraz, uzyskuje RoI za pomocą sieci propozycji regionów (RPN), takiej jak wyszukiwanie selektywne, przekształca regiony zainteresowania tak, aby pasowały do rozmiaru wejściowego CNN i używa SVM do klasyfikowania obiektów. Dla każdej klasy, która ma zostać wykryta, szkolona jest osobna binarna maszyna SVM. Daje to przybliżone ramki ograniczające w lokalizacjach wykrytych obiektów. Model regresji liniowej służy do uzyskania ściślejszych ramek ograniczających, które dokładniej wiążą wykryte obiekty na obrazie. Ponieważ przy wykrywaniu obrazów podejmowana jest duża liczba kroków, model RCNN może zająć do 50 s, aby wykonać prognozy dla każdego nowego obrazu, co sprawia, że model jest niewykonalny do wykrywania obiektów i kłopotliwy w przypadku uczenia modelu z dużymi zestawami danych. Ze względu na wady RCNN opracowano model Fast RCNN. Zamiast używać trzech różnych modeli, takich jak RCNN, FastRCNN używa pojedynczego modelu, który wyodrębnia cechy z regionów na obrazie, dzieli je na różne klasy i zwraca pola graniczne dla zidentyfikowanych klas za jednym razem. Dlatego zamiast konieczności przepuszczania tysięcy obszarów obrazu przez CNN, co jest obliczeniowo kosztowne, cały obraz przechodzi przez CNN raz. Odbywa się to poprzez przekazanie obrazu przez metodę propozycji regionu, która generuje RoI. Następnie do wszystkich tych regionów stosuje się pulowanie ROI w celu przekształcenia ich zgodnie z danymi wejściowymi metody propozycji regionów, a regiony są jednocześnie przekazywane do CNN. W górnej części CNN do wyprowadzania klas używana jest warstwa softmax. Równolegle używana jest warstwa regresji liniowej do wyprowadzania współrzędnych prostokąta granicznego dla każdej wykrytej klasy. To sprawia, że Faster RCNN jest znacznie szybszy niż RCNN. Ponieważ jednak wyszukiwanie selektywne jest nadal używane w szybkim RCNN, podobnie jak w RCNN, a ponieważ wyszukiwanie selektywne jest procesem czasochłonnym, wykrywanie jest spowolnione i zajmuje około 2 s, aby dokonać prognozy dla każdego nowego obrazu. Aby rozwiązać ten problem, opracowano Faster RCNN, który działa nawet szybciej niż Fast RCNN. W porównaniu do Fast RCNN, który wykorzystuje selektywne wyszukiwanie do generowania RoI, Faster RCNN wykorzystuje metodę o nazwie RPN. Najpierw obraz przechodzi przez CNN, która tworzy mapy cech obrazu. Mapy cech są następnie przekazywane do RPN, który używa przesuwanego okna nad mapami cech i generuje w każdym oknie k-Zakotwiczenia o różnych kształtach i rozmiarach. Dla każdej kotwicy wykonywane są dwie prognozy - (a) prawdopodobieństwo, że kotwica jest obiektem i (b) regresor pola ograniczającego w celu dostosowania kotwic, aby lepiej pasowały do obiektu. Tworzy to ramki ograniczające o różnych kształtach i rozmiarach, które są następnie przekazywane do warstwy puli RoI. Warstwa puli wyodrębnia mapy obiektów o stałym rozmiarze dla każdej kotwicy. Mapy obiektów są przekazywane do ostatniej warstwy, która zawiera warstwę softmax i warstwę regresji liniowej. Warstwy te tworzą klasy wykrytych obiektów i współrzędne obwiedni dla każdego obiektu. Dzięki ulepszeniom wprowadzonym z Faster RCNN do Faster RCNN prognozy dla każdego nowego obrazu zajmują około 0,2 s przy użyciu modelu Faster RCNN. Model wykrywania obiektów SSD jest przeznaczony do wykrywania obiektów w czasie rzeczywistym. Termin "Single Shot" oznacza, że zadania lokalizacji i klasyfikacji obiektów są wykonywane w jednym przejściu do przodu sieci neuronowej, "MultiBox" to nazwa techniki regresji pola ograniczającego, a "Detector" oznacza, że sieć jest detektorem obiektów który klasyfikuje wykryte obiekty. W przeciwieństwie do modelu Faster RCNN, który wykorzystuje RPN do tworzenia ramek granicznych, a następnie używa tych ramek do klasyfikowania obiektów, co tworzy predykcje o dużych dokładnościach, dysk SSD eliminuje RPN z modelu. Dzieje się tak, ponieważ model RCNN działa z prędkością około 7 klatek na sekundę, co jest niezwykle powolne w przypadku wykrywania obiektów w czasie rzeczywistym. Jednak usunięcie RPN wiąże się z kosztami dokładności. Dysk SSD rekompensuje tę stratę, włączając funkcje wieloskalowe i domyślne pola. Dzięki temu dysk SSD jest w stanie osiągnąć szybkość przetwarzania w czasie rzeczywistym i dokładność nawet lepszą niż w modelu Faster R-CNN. W standardowych zestawach danych, takich jak PascalVOC i COCO, dysk SSD osiąga ponad 70 procent średniej precyzji (mAP) przy 19 klatkach na sekundę. Jednym z najnowocześniejszych podejść do wykrywania obiektów, dającym szybkości i dokładności większe niż inne podejścia, jest YOLO. Jak sama nazwa wskazuje, w przeciwieństwie do poprzednich modeli, YOLO pobiera cały obraz w jednej instancji i przewiduje prawdopodobieństwa klas oraz współrzędne ramki granicznej dla wykrytych obiektów na obrazie. YOLO działa, wykonując obraz wejściowy, dzieląc obraz wejściowy na siatki, na przykład siatki 3 x 3, a następnie przeprowadzając klasyfikację i lokalizację obrazu na każdej siatce. Następnie YOLO przewiduje prawdopodobieństwa klas i współrzędne ramki granicznej dla wykrytych obiektów. Na standardowych zestawach danych, takich jak VOC2007, YOLO wykazał, że generuje mAP na poziomie 63,4%, a wykrywanie odbywa się z prędkością 45 klatek na sekundę. Innym aspektem wizji komputerowej, który zyskuje na popularności, jest szacowanie ludzkiej pozy. Szacowanie ludzkiej pozy to przewidywanie części ciała i pozycji stawów osoby na podstawie obrazu lub filmu. Jest to narastający problem związany z rosnącą liczbą zastosowań w dziedzinie bezpieczeństwa i nadzoru, opieki zdrowotnej, transportu i sportu. Przykłady takich zastosowań obejmują nadzór wideo w czasie rzeczywistym, wykrywanie udaru i zawału serca, życie wspomagane, zaawansowane systemy wspomagania kierowcy (ADAS) i analiza sportu. Szacowanie ludzkiej pozy jest ogólnie podzielone na dwie kategorie: (a) szacowanie pozycji 2D i (b) szacowanie pozycji 3D. Szacowanie pozycji 2D obejmuje oszacowanie pozycji człowieka we współrzędnych x i y, podczas gdy oszacowanie pozycji 3D obejmuje oszacowanie pozycji człowieka we współrzędnych x, y i z dla stawów w kolorze czerwonym/zielonym/niebieskim (RGB). Szacowanie ludzkiej pozy jest uważane za trudny problem do rozwiązania ze względu na różnice między ludźmi, które występują na obrazach, a także inne czynniki, takie jak okluzja, odzież, warunki oświetleniowe, małe stawy i silne artykulacje. Wcześniej do szacowania pozycji przegubowych używano metod klasycznych, takich jak ramy struktur obrazkowych. Jest to ustrukturyzowane zadanie przewidywania obejmujące reprezentację obiektu za pomocą zbioru "części", które są ułożone w odkształcalnej konfiguracji. "Części" to szablony ludzkich stawów, które są dopasowane do tych na obrazie, a sprężyny służą do pokazywania połączeń przestrzennych między częściami. Ta metoda może modelować artykulację, dając przybliżenie ludzkiej pozy. Innym klasycznym podejściem do szacowania pozy człowieka są modele części odkształcalnych. W tym podejściu zastosowano mieszany model części, które wyrażają złożone relacje połączeń. Podobnie do struktury obrazkowej, model ten jest zbiorem szablonów w odkształcalnej konfiguracji; jednak ten model jest bardziej złożony, ponieważ składa się z większej liczby "części" z szablonami globalnymi i szablonami części. Jednak klasyczne podejścia mają swoje ograniczenia, takie jak brak wyrazistości, a dziś badania nad szacowaniem pozy w dużej mierze wymagają użycia CNN. Po wprowadzeniu metody szacowania ludzkiej pozy DeepPose opartej na głębokich sieciach neuronowych, większość badań nad szacowaniem ludzkiej pozy rozpoczęła się polegać na głębokim uczeniu się. Obecnie ConvNets zastąpiły większość zaprogramowanych funkcji i modeli graficznych jako główny blok konstrukcyjny większości systemów szacowania pozycji, tworząc duże ulepszenia wydajności szacowania pozycji w standardowych testach porównawczych. Niektóre z najpopularniejszych podejść do szacowania ludzkich pozycji opartych na głębokim uczeniu to DeepPose, Convolutional Pos Machines, wydajna lokalizacja obiektów za pomocą sieci Convolutional Networks, Convolution Network Estimation with iterative error Feedback i Stacked Hourglass Networks do szacowania ludzkiej pozycji. Chociaż opublikowano wiele artykułów naukowych dotyczących głębokiego uczenia się i innych podejść AI do szacowania ludzkich pozycji, DeepPose był pierwszym ważnym artykułem, który zastosował głębokie uczenie w szacowaniu ludzkiej pozy, uzyskując najnowocześniejszą wydajność i pokonując istniejące modele. DeepPose formułuje problem szacowania pozy jako problem regresji opartej na CNN w stosunku do stawów ciała. Kaskada regresorów jest używana do udoskonalania szacowania pozy. Artykuł badawczy na temat DeepPose stwierdza, że CNN zapewniają holistyczne rozumowanie ludzkich póz, więc nawet jeśli stawy są niejasne, małe lub ukryte, CNN są w stanie wnioskować i oszacować pozycję stawów. Zazwyczaj oszacowanie pozy obejmuje wnioskowanie o lokalizacji części ciała lub punktów orientacyjnych, a jakość prognozy opiera się na metrykach obejmujących porównania między przewidywaną a naziemną lokalizacją na płaszczyźnie obrazu. Innym aktywnym polem badań jest szacowanie kątów w stawach ludzkich, które polega na szacowaniu kątów tworzonych przez segmenty ludzkiego ciała w punktach orientacyjnych stawów we współrzędnych światowych. Można to zrobić na dwa różne sposoby: (a) bezpośrednio regresując kąty połączeń z obrazu i (b) oszacowując kąty połączeń za pomocą geometrii. Pierwsza metoda wymaga przeszkolenia modelu szacowania kąta stawu poprzez zasilenie go obrazami pozycji ludzkich i kątów stawu, które można rejestrować za pomocą czujników, takich jak system przechwytywania ruchu Qualisys (MoCap), dzięki któremu wdrożenie modelu zapewniłoby wspólne kąty z obrazów wejściowych. Druga metoda polega na oszacowaniu ludzkiej pozy na obrazie, co daje jako wynik przestrzenny układ 2D lub 3D wszystkich stawów ciała. Można to łatwo osiągnąć za pomocą trygonometrii, wytwarzając niezbędne kąty stawów w trzech wymiarach, jeśli ocena ludzkiej pozy odbywa się w trzech wymiarach. Zastosowanie oceny ludzkiej pozy polega na tym, aby robot podążał trajektorią ludzkiej pozy, tak aby odtwarzał ruchy osoby. Roboty przydatne w tej dziedzinie to roboty dwuramienne z wieloma osiami na ramię, takie jak YuMi firmy ABB, z dwoma ramionami i siedmioma osiami na ramię. Tę aplikację można osiągnąć, wykonując kadry osoby i przekazując je do modelu szacowania ludzkiej pozy, który daje trójwymiarowy układ stawów ciała, obliczając kąty stawów ramion za pomocą geometrii i wysyłając te kąty do każdej odpowiedniej osi ramienia robota. Osie ramienia robota są następnie programowane do poruszania się pod tymi kątami. Wykonanie tego w czasie rzeczywistym zapewniłoby replikację ludzkiej pozy w czasie rzeczywistym na robocie z dwoma ramionami. To zastosowanie może zyskać duże znaczenie w szkoleniu robota, aby wytwarzał ruch bardziej podobny do ludzkiego, co staje się przydatne w dziedzinie opieki zdrowotnej podczas programowania robotów do wspomaganego życia osób starszych lub przy wykonywaniu operacji z użyciem robota.
Przetwarzanie języka naturalnego
NLP to dziedzina, która umożliwia maszynom rozumienie, analizowanie i manipulowanie ludzkim językiem. Jest to rozległa dziedzina obejmująca wiele dyscyplin, od informatyki po lingwistykę komputerową. Ostatecznym celem NLP jest wypełnienie luki, która istnieje między komunikacją ludzką a językiem maszynowym. Podczas gdy ludzie mówią wieloma różnymi językami, od angielskiego przez chiński po hiszpański, komputery z natury pracują i rozumieją język maszynowy, który na najniższych poziomach maszyn jest złożoną kombinacją jedynek i zer. Ponad 70 lat temu programiści wybijali karty z jedynkami i zerami, aby komunikować się z maszynami. NLP ma na celu umożliwienie komputerom zrozumienia komunikacji międzyludzkiej i, na bardziej złożonych poziomach, interakcji międzyludzkich, a jednocześnie umożliwienie ludziom okiełznania dużej ilości dostępnej obecnie mocy obliczeniowej do wykonywania zadań, od przetasowania do następnej piosenki, po tłumaczenie akapit e-maila w innym języku, zachowując ton tekstu. NLP jest uważany za trudny problem do rozwiązania ze względu na naturę ludzkiego języka. Różnorodność reguł ludzkich języków utrudnia zaprogramowanie narzędzi NLP do rozumienia i analizowania szerokiego zakresu tekstów i rozmów. Gdy mamy do czynienia z podstawowymi zasadami gramatyki, takimi jak dodanie litery "s" na końcu rzeczownika w celu wskazania liczby mnogiej, podczas opracowywania narzędzi NLP można napisać proste warunki "jeśli-inne". Jednak radzenie sobie z sarkazmem w przekazywaniu informacji jest złożonym problemem do rozwiązania i wymagałoby od narzędzia NLP zrozumienia wzorców rozmowy i tematów ostatnio omawianych w celu wykrycia sarkazmu. Podczas opracowywania narzędzia NLP do rozwiązywania złożonych problemów związanych z przetwarzaniem tekstu lub rozmów, sztuczna inteligencja jest kluczowym składnikiem ze względu na jej zdolność do rozpoznawania wzorców. Głębokie sieci neuronowe są dziś powszechnie używane do opracowywania potężniejszych systemów NLP, które są w stanie prowadzić z ludźmi konwersację podobną do ludzkiej. Przykładami takich aplikacji są zautomatyzowane chatboty wykorzystujące sztuczną inteligencję, używane obecnie przez wielu dostawców usług do zapewniania natychmiastowych odpowiedzi na zapytania swoich klientów. Chociaż NLP istnieje od lat 50. XX wieku, kiedy Alan Turing opublikował artykuł zatytułowany "Computing Machinery and Intelligence", w którym jako kryterium inteligencji zaproponował to, co obecnie nazywa się testem Turinga, zyskał on ostatnio wiele uwagi ze względu na rosnące zainteresowanie komunikacja człowiek-maszyna (H2M), oprócz dużych ilości danych przechowywanych każdego dnia, coraz potężniejszej dostępnej mocy obliczeniowej i ulepszonych algorytmów. Ponadto, wraz z wykładniczym wzrostem AI i głębokich sieci neuronowych, które okazały się obiecujące, gdy są stosowane w narzędziach NLP, rynek NLP rośnie w szybkim tempie. Według raportu firmy Gartner 2018 World Artificial Intelligence Industry Development Blue Book, globalny rynek NLP będzie wart 16 miliardów dolarów do 2021 roku. NLP bardzo szybko staje się istotnym narzędziem dla firm, w zastosowaniach takich jak analiza sentymentu, chatboty, obsługa klienta, zarządzanie reklamami lejki i wywiad rynkowy. Jednym z prostszych zadań NLP z AI jest klasyfikacja tekstu. Podobnie jak modele wykrywania obiektów klasyfikują obiekty na obrazie, klasyfikacja tekstu za pomocą NLP obejmuje klasyfikację tekstu na różne predefiniowane kategorie. Staje się to ważne w aplikacjach, takich jak wykrywanie spamu lub analiza sentymentu, w których wiersze lub akapity tekstu są danymi wejściowymi modelu NLP, a dane wyjściowe modelu to "prawda" lub "fałsz" w przypadku systemów wykrywania spamu lub "szczęśliwe" lub "smutny" na przykład w przypadku systemów analizy sentymentu. Kolejnym zadaniem NLP jest odkrywanie tematów i modelowanie. Modelowanie tematyczne to zadanie polegające na wykorzystaniu uczenia nienadzorowanego do wyodrębnienia głównych tematów występujących w tekście lub zbiorze dokumentów; w związku z tym można go łatwo porównać z grupowaniem. W większości przypadków dane pojawiają się w formie nieustrukturyzowanej, na przykład szeroki zakres tematów publikowanych codziennie w witrynie blogowej lub szeroki zakres produktów publikowanych w witrynie sprzedawcy. Wykonując modelowanie tematyczne na danych, możemy uzyskać zestaw tematów, które są bardziej powszechne i pozwalają na sklasyfikowanie dużej ilości danych w ramach tych tematów. Istnieje kilka algorytmów modelowania tematów, takich jak utajona alokacja Dirichleta (LDA), oparta na probabilistycznych modelach graficznych, utajona analiza semantyczna (LSA) i nieujemna faktoryzacja macierzy (NMF), które są oparte na algebrze liniowej.
Obliczenia kognitywne
Obliczenia poznawcze to symulacja procesów myślowych człowieka w maszynie lub modelu skomputeryzowanym. Definiuje się ją jako zestaw komponentów obliczeniowych siły przemysłowej wymaganych do dostarczania klientom poznania jako usługi (w tym trzech L - języka (language), uczenia się (learning) i poziomów (levels)). Obliczenia kognitywne umożliwiają poznanie jako usługę i zasilają usługi kognitywne, które poszerzają i skalują ludzką wiedzę. Trzy kluczowe filary obliczeń kognitywnych to uczenie maszynowe, NLP i generowanie hipotez z możliwością wyjaśnienia opartego na dowodach. Wykorzystując cechy poznawcze ludzkiego mózgu, takie jak eksploracja danych, NLP, rozpoznawanie wzorców i inne algorytmy samouczące się, przetwarzanie kognitywne umożliwia komputerom podejmowanie decyzji w oparciu o zdarzenia lub warunki, tak jak zrobiłby to człowiek. Jednak replikowanie ludzkich procesów myślowych nie jest łatwym zadaniem, ponieważ wciąż nie mamy do niego pełnego zrozumienia. Mimo że komputery uzyskują niezrównaną szybkość obliczeń i przetwarzania znacznie przekraczającą ludzkie możliwości, nie były w stanie wykonywać zadań, które ludzie uważają za proste, takich jak rozumienie języka naturalnego lub wykrywanie obiektów na obrazie. Przykładem systemu kognitywnego jest IBM Watson, który opiera się na sieciach neuronowych i algorytmach głębokiego uczenia. Przetwarza dane, porównując je z uczącym zestawem danych. W związku z tym im więcej danych trafia do systemu IBM Watson, tym więcej się uczy i tym bliżej jego decyzji do podjęcia właściwej decyzji. sektora finansowego. Wybór akcji, która ma dobre wyniki i oczekuje się, że będzie mieć rosnącą wartość, wymaga wielu zgadywania i badania wzorców akcji przez inwestorów. Edge Up Sports to kolejna firma w branży sportowej, która wykorzystuje obliczenia kognitywne do pomocy trenerom i trenerom osobistym w rozwijaniu zespołu. Wykorzystuje sztuczną inteligencję, aby pomóc zmniejszyć urazy sportowe w terenie za pomocą kamer śledzących czujniki na sportowcach, które przekładają ich ruch na wgląd w wyniki, aby dostarczać trenerom informacje na temat zdrowia i aktywności. Przewiduje się, że ogromne zdolności poznawcze globalnych dostawców CaaS (poznanie jako usługa) będą tanie i dostępne za pośrednictwem interfejsów API dla każdego urządzenia od nanoskali po gigantyczne globalne aplikacje i usługi. W takim świecie poznanie jako usługa może być tak samo wszechobecne, jak elektryczność jest dla nas dzisiaj. W sektorze edukacji przetwarzanie kognitywne może stać się silną siłą napędową w procesie nauczania i uczenia się, aby zmaksymalizować potencjał ucznia. Podobnie jak w przypadku nauczyciela, który musi przejść liczne szkolenia i lata doświadczenia, zanim stanie się biegły w kształceniu uczniów, program informatyki kognitywnej musi być zasilany dużą ilością danych dotyczących procesu rozwoju uczniów i programu nauczania w systemie edukacyjnym zanim będzie mogła skutecznie wspomóc proces edukacji. Jednak nauczyciel nie może po prostu natychmiast przekazać całej swojej wiedzy i wykształcenia nowemu, niedoświadczonemu nauczycielowi. Nowy nauczyciel musiałby przejść przez lata szkolenia, zanim stanie się tak zręczny jak doświadczony nauczyciel. Jednak dobrze wyszkolony program poznawczy można szybko i łatwo odtworzyć bez konieczności ponownego wykonywania całego procesu szkoleniowego. Umożliwia to wykorzystanie komputerów kognitywnych w klasach jako spersonalizowanych asystentów dla każdego ucznia, skupiając się na mocnych i słabych stronach każdego ucznia i zapewniając niezbędny poziom trudności w ćwiczeniach, aby uczeń szybko się rozwijał. Może to złagodzić stres, z jakim borykają się nauczyciele, gdy prowadzą zajęcia z dużą liczbą uczniów. Pojedynczy nauczyciel nie może również zaspokoić potrzeb każdego ucznia, nie zaniedbując postępów innych uczniów. Taka kognitywna aplikacja obliczeniowa w edukacji może również rozwijać wiele technik, takich jak tworzenie scenariuszy lekcji dla uczniów. Dziś sztuczna inteligencja w procesie edukacji istnieje już jako aplikacje mobilne, takie jak Mika i Thinskter Math, wirtualni nauczyciele, którzy dostosowują się do potrzeb uczniów i pomagają im doskonalić się w przedmiotach. Oczekuje się, że obliczenia kognitywne przekształcą sektor biznesu na trzy sposoby. Po pierwsze, obliczenia kognitywne poprawią zdolności pracowników, ich wkład i wydajność. Algorytmy głębokiego uczenia przyspieszą i podniosą jakość pracy, automatyzując zadania o małej wartości, takie jak zbieranie danych statystycznych czy aktualizowanie rekordów klientów o dane finansowe lub demograficzne. Kodowanie predykcyjne, mechanizm sztucznej inteligencji, pomoże prawnikom przeszukiwać duże ilości danych, aby przyspieszyć proces eksploracji, aby zapewnić klientom większą wartość i lepsze usługi. Po drugie, obliczenia kognitywne umożliwią analizę danych o wyższej jakości. Organizowanie danych w znaczące porcje nie jest łatwym procesem, zwłaszcza jeśli dane mają wiele różnych ustrukturyzowanych i nieustrukturyzowanych form. Algorytmy głębokiego uczenia umożliwią dokładną, terminową i znaczącą analizę dużych ilości danych, oszczędzając duże ilości czasu. Po trzecie, przetwarzanie kognitywne poprawi ogólne wyniki biznesowe. Informatyka kognitywna pomoże firmom uchwycić istotne informacje i wykorzystać je do podejmowania dobrych decyzji podczas dostarczania na rynek lepszych produktów lub usług o wyższej jakości przy użyciu statystyk rynkowych i wyników wcześniejszych decyzji podjętych przez firmy. W dzisiejszych czasach najbardziej udane firmy to te, które łączą planowanie strategiczne i inteligentne technologie osadzone w poznaniu. Dwie firmy, które mają obie te funkcje, to Google i Amazon, dwie spośród obecnie najlepiej działających firm.
Rola AI w inteligentnych miastach
Bezpieczeństwo i nadzór
Bezpieczne miasto to kluczowa koncepcja inteligentnego miasta. Bezpieczeństwo i ochrona to niezwykle istotne elementy jakości życia w mieście. Dlatego inteligentne miasto musi być bezpiecznym miastem do życia. Na sympozjum Campbell Institute, National Safety Council, skupiono się na implikacjach IR4.0 dla bezpieczeństwa. Najbardziej przypisywaną tej epoce etykietą jest "Cyber-Fizyczny System". Według prognoz ONZ do 2050 roku 68 procent światowej populacji będzie mieszkać na obszarach miejskich. Wraz z rozwojem coraz większej liczby i inteligentniejszych miast rządy inwestują więcej w infrastrukturę publiczną w celu poprawy usług publicznych, takich jak transport i opieka zdrowotna ,operacji i ogólnego doświadczenia miejskiego. Dzięki większej liczbie połączonych urządzeń w rozkwicie IoT przez Internet przesyłanych jest więcej danych niż kiedykolwiek wcześniej. Wraz z postępem technologii telekomunikacyjnych i wzrostem liczby wzajemnie połączonych urządzeń, przywódcy i obywatele miast każdego dnia są przedstawiani nowym zagrożeniom bezpieczeństwa i prywatności. Według badania przeprowadzonego przez McMaster University, 88 procent ludzi w Kanadzie obawia się o swoją prywatność w kontekście inteligentnych miast. Ponieważ wdrażanie inteligentnych miast wciąż przyspiesza, miasta mają coraz większe trudności z identyfikowaniem, reagowaniem i zapobieganiem cyberatakom i zagrożenia prywatności z następujących powodów:
1. Bezpieczeństwo wciąż nie jest priorytetem dla urbanistów. Niezabezpieczone urządzenia są nadal bardzo podatne na ataki, ponieważ można uzyskać do nich dostęp z Shodan.io.
2. Miasta nie są przygotowane na ogromne ilości gromadzonych danych.
3. Zespoły ds. bezpieczeństwa nie są przygotowane do radzenia sobie z lukami w cyberbezpieczeństwie.
4. Fizyczne zagrożenia dla podłączonych systemów nie są dokładnie rozwiązywane.
Wraz z szybkim rozwojem sztucznej inteligencji i IoT w ostatnich latach, sztuczna inteligencja wielokrotnie wykazała, że jest zdolna do zastosowania rzeczywistych aplikacji do wspomagania, a nawet całkowitego nadzorowania systemów bezpieczeństwa. Gdy zbliżamy się do ludzkich ograniczeń w wykonywaniu tych aplikacji, sztuczna inteligencja staje się realnym zamiennikiem ludzi w dziedzinie bezpieczeństwa. Według wiadomości NBC, policja w wielu miastach w całych Stanach Zjednoczonych już ma za mało personelu, co utrudnia zapewnienie bezpieczeństwa publicznego we wszystkich miejscach przez cały czas [20]. Niektóre sposoby, w jakie inteligentne miasta mogą wykorzystywać sztuczną inteligencję wraz z IoT i czujnikami w celu poprawy ogólnego bezpieczeństwa w miastach, obejmują wykorzystanie analizy wideo do monitorowania nadzoru kamer w czasie rzeczywistym, używanie czujników i kamer do monitorowania dużych tłumów w celu wykrywania potencjalnych zagrożeń oraz używanie robotów patrolowych i drony do monitorowania potencjalnie niebezpiecznych obszarów. Trzy główne obszary bezpieczeństwa i ochrony, które mają ulec znacznej poprawie dzięki zastosowaniu sztucznej inteligencji, to:
1. Wykrywanie przestępstw
2. Zapobieganie przestępczości
3. Cyberbezpieczeństwo.
Wykrywanie przestępstw
Jednym z głównych celów wykorzystania AI jest wykrywanie zjawisk przestępczych i wspieranie władz w dotarciu na miejsce przestępstwa w jak najkrótszym czasie. Na przykład po oddaniu strzału policji trudno jest określić dokładną lokalizację strzału i ocenić krytyczność sytuacji. Zaawansowana technologia nadzoru Shotspotter jest w stanie rozwiązać ten problem, wykrywając przemoc z broni palnej za pomocą czujników akustycznych i sztucznej inteligencji. Wysyła ostrzeżenie do policji i innych władz w ciągu 45 sekund od incydentu z bronią palną. Alarm zawiera ważne informacje sytuacyjne dotyczące incydentu, takie jak dokładna lokalizacja, liczba oddanych strzałów oraz strzelanie jednego lub wielu strzelców. Wykrywanie przestępstw Jednym z głównych celów wykorzystania AI jest wykrywanie zjawisk przestępczych i wspieranie władz w dotarciu na miejsce przestępstwa w jak najkrótszym czasie. Na przykład po oddaniu strzału policji trudno jest określić dokładną lokalizację strzału i ocenić krytyczność sytuacji. Zaawansowana technologia nadzoru Shotspotter jest w stanie rozwiązać ten problem, wykrywając przemoc z użyciem broni za pomocą czujników akustycznych i sztucznej inteligencji. Wysyła ostrzeżenie do policji i innych władz w ciągu 45 sekund od incydentu z bronią palną. Alarm zawiera ważne informacje sytuacyjne dotyczące incydentu, takie jak dokładna lokalizacja, liczba oddanych strzałów oraz strzelanie jednego lub wielu strzelców. Wykrywanie przestępstw Jednym z głównych celów wykorzystania AI jest wykrywanie zjawisk przestępczych i wspieranie władz w dotarciu na miejsce przestępstwa w jak najkrótszym czasie. Na przykład po oddaniu strzału policji trudno jest określić dokładną lokalizację strzału i ocenić krytyczność sytuacji. Zaawansowana technologia nadzoru Shotspotter jest w stanie rozwiązać ten problem, wykrywając przemoc z broni palnej za pomocą czujników akustycznych i sztucznej inteligencji. Wysyła aby zaalarmować policję i inne władze w ciągu 45 sekund od strzału z broni palnej. Alarm zawiera ważne informacje sytuacyjne dotyczące incydentu, takie jak dokładna lokalizacja, liczba oddanych strzałów oraz strzelanie jednego lub wielu strzelców.
Zapobieganie przestępczości
Oprócz wykrywania przestępczości sztuczna inteligencja okazała się również przydatna w ogólnym zapobieganiu przestępczości w miastach. Korzystając ze zdolności MLA do rozpoznawania wzorców, można zdekonstruować wzorce przestępczości, stworzyć mapy cieplne krytyczności przestępczości i przewidzieć przyszłe przestępstwa w miastach. W Vancouver wydział policji wdrożył rozwiązanie do uczenia maszynowego, które przeprowadza analizę przestrzenną, aby przewidzieć, gdzie nastąpi włamanie do mieszkań, aby można było odpowiednio rozmieścić patrole policyjne, aby zminimalizować przestępczość . System został opracowany przez inżynierów geoprzestrzennych i statystyków, którzy opracowali algorytm do prawidłowego wykrywania wzorców przestępstw przeciwko mieniu. System przewiduje przestępstwa w promieniu 100 mi 2-godzinnym oknie czasowym na podstawie przeszłych przypadków przestępstw. Według Esri, twórcy systemu prognozowania przestępczości, system wykazał dokładność większą niż 80 procent. W Kalifornii Aveta Intelligence wykorzystuje sztuczną inteligencję do przewidywania działań terrorystów. Odbywa się to poprzez analizę opisową, diagnostyczną i predykcyjną z inteligencją kognitywną i uczeniem maszynowym w celu dynamicznego uczenia się różnych rodzajów zagrożeń bezpieczeństwa i reagowania na nie . Firma wykorzystuje wiele narzędzi, takich jak analiza grafów, sieci neuronowe, heurystyka, złożone przetwarzanie zdarzeń, symulacje, silniki rekomendacji i uczenie maszynowe, aby pomóc w poprawie bezpieczeństwa w miastach. Aveta Intelligence oferuje dwa podstawowe produkty: Trust i Sentinel, w których Trust określa potencjalne zagrożenia w organizacji poprzez zachowania społeczne, analizy predykcyjne i konkurencyjne, a Sentinel przewiduje fizyczne zagrożenia bezpieczeństwa pracowników organów ścigania i kampusu poprzez analizę danych fizycznych, takich jak media społecznościowe, incydenty raporty, harmonogramy imprez i nagrania telewizji przemysłowej (CCTV) w celu zapobiegania przestępstwom. Inną firmą, która wykorzystuje sztuczną inteligencję w predykcji przestępczości jest Predpol, skrót od predykcyjnego policji. Predpol twierdzi, że jego algorytmy analizy przestępczości mogą poprawić wykrywanie przestępstw o 10-50 procent w niektórych miastach. Wykorzystując wieloletnie dane historyczne, takie jak rodzaj, miejsce i czas wystąpienia przestępstw oraz inne dane społeczno-ekonomiczne, algorytm, początkowo zaprojektowany do prognozowania wstrząsów wtórnych po trzęsieniach ziemi, przeprowadza analizę przestępczości i przewiduje miejsce, czas i rodzaj przestępstwa, które nastąpi w ciągu najbliższych 12 godzin, a w miarę wprowadzania nowych danych algorytm jest codziennie aktualizowany. Stosowana technika jest nazywana przez firmę "prognozowaniem przestępczości w następstwie wstrząsów w czasie rzeczywistym w czasie rzeczywistym". Prognozy dotyczące przestępstw są wyświetlane na mapie za pomocą kolorowych pól, z których każde reprezentuje obszar 46 metrów kwadratowych. Miejsca "wysokiego ryzyka" są oznaczone czerwonymi ramkami, a patrole policyjne są zachęcane do spędzania tam co najmniej 10 procent czasu.
Bezpieczeństwo cybernetyczne
Ponieważ liczba podłączonych urządzeń szybko rośnie, a liczba podłączonych urządzeń IoT ma wzrosnąć do prawie 20 miliardów do 2020 r. , cyberbezpieczeństwo nabiera coraz większego znaczenia w rozwoju inteligentniejszych miast. Cyberataki w jednym regionie mogą mieć nasilony wpływ na inne regiony, prowadząc do poważnej utraty danych, ryzyka utraty reputacji i skutków finansowych dla firm, a nawet mogą zakłócić krytyczne usługi miejskie i infrastrukturę w wielu dziedzinach, w tym w opiece zdrowotnej, transporcie, mieszkalnictwie, usługi energetyczne, komunalne, prawne i egzekucyjne. Takie podatności mogą spowodować śmiertelne niebezpieczeństwo i załamanie systemów ekonomicznych i społecznych. Obecnie najpopularniejszą metodą ochrony sieci jest wdrożenie zapory, zainstalowanej jako oprogramowanie lub fizycznie podłączonej do sieci jako sprzęt. Zapory sieciowe śledzą połączenia sieciowe i śledzą, które połączenia są dozwolone na portach sieciowych, blokując inne żądania. Generalnie administratorzy sieci serwera
kontrolują uprawnienia połączeń przychodzących do określonych portów w systemie. Jeśli hakerowi uda się przebić przez zaporę systemu i zabezpieczenia sieci, następną linią obrony jest system antywirusowy zainstalowany na serwerze. System antywirusowy jest zazwyczaj przeznaczony do wyszukiwania złośliwego kodu w oprogramowaniu lub podejrzanych połączeń, którego celem jest usunięcie złośliwego oprogramowania lub wirusa, zanim zdąży zaatakować system, na przykład oprogramowanie ransomware, lub rozprzestrzeni się na inne połączone ze sobą maszyny w organizacji. Systemy antywirusowe uniemożliwiają również podejrzanym połączeniom uzyskanie osobistych lub zastrzeżonych informacji z systemu bez zgody właściciela. Zazwyczaj organizacje przechowują również kopie zapasowe swoich systemów i mają zorganizowany system zarządzania kopiami zapasowymi, aby zapobiec utracie danych w przypadku ataku, na przykład oprogramowania ransomware. Dzięki planowi odzyskiwania po awarii mogą szybko odzyskać sprawność po awariach lub
naruszeniach bezpieczeństwa danych. Techniki stosowane obecnie w cyberbezpieczeństwie ostatecznie zależą od wiedzy osób obsługujących serwery sieci, a umiejętności osób są budowane dzięki energicznym szkoleniom i doświadczeniu. Organizacje odnoszące największe sukcesy stale edukują swoich nowych i dotychczasowych pracowników w zakresie zagrożeń występujących w Internecie oraz sposobów ochrony siebie i organizacji. Większość istniejących narzędzi cyberbezpieczeństwa wymaga interakcji z człowiekiem w celu konfiguracji systemu i sieci, zasad zapory, harmonogramów tworzenia kopii zapasowych i ostatecznie zapewnienia pomyślnego działania systemu. Wykorzystując sztuczną inteligencję w systemach cyberbezpieczeństwa można zminimalizować interakcję człowieka z systemem. Ponadto, ponieważ pracownicy w organizacji muszą być stale szkoleni w zakresie obsługi bezpieczeństwa sieci, a pracownicy w organizacji ciągle się zmieniają, zaawansowana sieć cyberbezpieczeństwa oparta na sztucznej inteligencji może być lepsza,
ponieważ może przejść uczenie się transferu i staje się bardziej dokładna z czasem, gdy zbiera więcej informacji. Dzisiejsze narzędzia AI mogą już obsługiwać dużą liczbę zadań wykonywanych przez administratorów sieci, takich jak monitorowanie zdarzeń i reagowanie na incydenty. Sztucznie inteligentne zapory będą miały wbudowane MLA, które pozwolą im rozpoznawać wzorce w żądaniach sieciowych i automatycznie blokować te, które mogą stanowić zagrożenie. Ponadto systemy sztucznej inteligencji mają możliwości języka naturalnego, które mają odegrać dużą rolę w przyszłości cyberbezpieczeństwa. Skanując duże pule danych w Internecie, systemy cyberbezpieczeństwa z wbudowanymi narzędziami NLP mogą dowiedzieć się, w jaki sposób dochodzi do cyberataków i ostrzec organizację, zanim pojawi się poważny problem. Firmą, która opracowuje narzędzia cyberbezpieczeństwa osadzone w NLP, jest Armorblox. Według Dhananjay Sampath, współzałożyciela Armorblox, wiadomości e-mail i pliki są głównymi wektorami kradzieży danych. Według
ankiety Trend Micro 91 procent cyberataków zaczyna się od wiadomości phishingowej zawierającej złośliwe załączniki lub odsyłacze do złośliwego oprogramowania. Według Armorblox w ciągu ostatnich 2 lat z powodu kompromitacji biznesowej poczty e-mail stracono 12 miliardów dolarów. Armorblo to silnik NLP, który uzyskuje wgląd w komunikację organizacyjną i dane. Uczy się, co jest kluczowe dla misji organizacji i przedstawia zalecenia dotyczące zasad. W przypadku potencjalnego naruszenia wysyła alerty do odpowiednich osób w organizacji, dzięki czemu można podjąć środki zapobiegawcze przed atakiem. Według Maurice′a Stebila, dyrektora ds. bezpieczeństwa informacji w firmie Harman, Armorblox wykorzystuje rozumienie języka naturalnego, aby poradzić sobie z warstwą bezpieczeństwa, która była nieosiągalna dla innych systemów bezpieczeństwa, czyli warstwą ludzką - kontekstem komunikacji między ludźmi. Hakerzy są świadomi tej słabości, a zrozumienie języka naturalnego jest w stanie rozwiązać ten problem. System wykrywania i zapobiegania włamaniom (IDPS) to zainstalowane oprogramowanie lub podłączony system sprzętowy, który wykrywa występowanie wejść systemu i próbuje im zapobiec. Zazwyczaj IDPS powinien mieć te cechy, aby zapewnić skuteczną ochronę przed cyberatakami, jak pokazano w tabeli.
Charakterystyka IDPS: Opis w zakresie inteligentnej fabryki
Czas rzeczywisty : Wykrywanie włamań podczas trwania ataku. Wykrywanie włamań natychmiast po ataku
Niezawodna niezależność : minimalna liczba fałszywych alarmów. Minimalny nadzór człowieka. Praca ciągła. Możliwość samodzielnego monitorowania w celu wykrycia prób włamań
Odzyskiwalne: Możliwość przywrócenia systemu po przypadkowych awariach. Możliwość przywrócenia systemu po cyberataku
Zgodny : Monitorowanie zachowania użytkowników w odniesieniu do polityk bezpieczeństwa systemu
Adaptowalność: Dostosowywanie się do zmian w zachowaniu użytkowników w czasie Dostosowywanie się do zmian systemowych
W przeszłości w ciągu ostatnich kilku lat systemy IDPS zostały zintegrowane z MLA, algorytmami genetycznymi, logiką rozmytą i sztucznymi sieciami neuronowymi w celu zwiększenia szybkości wykrywania i zminimalizowania czasu wykrywania systemów. Według raportu Reinventing Cybersecurity with Artificial Intelligence Report firmy Capgemini pięć najczęstszych przypadków wykorzystania sztucznej inteligencji w celu poprawy cyberbezpieczeństwa to wykrywanie oszustw, wykrywanie złośliwego oprogramowania, wykrywanie włamań, ryzyko punktacji sieci oraz analiza zachowań użytkowników/maszyny. Dwadzieścia przypadków użycia w IoT, IT i technologii operacyjnej zostało przeanalizowanych i uszeregowanych według złożoności wdrożenia i korzyści w zakresie skrócenia czasu. Zgodnie z analizą Capgemini, Forbes zalecił pięć z największych potencjalnych przypadków użycia o wysokich korzyściach i niskiej złożoności. Pięćdziesiąt cztery procent przedsiębiorstw w Stanach Zjednoczonych już wdrożyło przypadki użycia .
Opieka zdrowotna
Szpitale i przychodnie od dłuższego czasu gromadzą i archiwizują duże ilości danych, w tym informacje o pacjentach i procesach leczenia. Dzięki dostępnej mocy obliczeniowej, szybkiemu rozwojowi technik sztucznej inteligencji i ogromnym zbiorom danych z branży medycznej, umowy MLA mogą zrewolucjonizować sposób, w jaki szpitale i instytucje opieki zdrowotnej wykorzystują dane do tworzenia prognoz, które mogą identyfikować potencjalne skutki zdrowotne. Ogólnie rzecz biorąc, oczekuje się, że sztuczna inteligencja przekształci branżę opieki zdrowotnej poprzez następujące aspekty:
1. Dobre samopoczucie
2. Wczesne wykrycie
3. Diagnoza
4. Podejmowanie decyzji
5. Leczenie
6. Opieka u schyłku życia
7. Badania
8. Szkolenie
Dobre samopoczucie
Jedną z największych potencjalnych korzyści płynących ze sztucznej inteligencji jest pomoc ludziom w utrzymaniu ich zdrowia w ryzach, dzięki czemu wizyty u lekarza stają się rzadsze. Aplikacje oparte na sztucznej inteligencji w urządzeniach mobilnych mogą śledzić wiele istotnych aspektów zdrowia i dostarczać sugestii lub zmian, które należy wprowadzić, aby poprawić samopoczucie użytkownika i poprawić stan jego zdrowia w dłuższej perspektywie. Wykorzystanie AI i Internetu Rzeczy Medycznych (IoMT) w zastosowaniach związanych ze zdrowiem konsumentów jest już w użyciu i pomaga ludziom. Mobilne aplikacje medyczne wykorzystujące sztuczną inteligencję obejmują TalkLife, która pomaga użytkownikom z problemami ze zdrowiem psychicznym, depresją, samookaleczeniami i zaburzeniami odżywiania, oferując im bezpieczne miejsce do rozmowy o ich problemach, oraz Flo Period Tracker, który zapewnia dokładne i wiarygodne prognozy menstruacji , owulacja i dni płodne przy użyciu uczenia maszynowego, nawet jeśli użytkownicy mają nieregularne cykle. Ponadto sztuczna inteligencja w aplikacjach mobilnych umożliwia pracownikom służby zdrowia, takim jak lekarze, uzyskiwanie informacji dotyczących codziennych wzorców diety pacjenta, rutyny ćwiczeń i innych aspektów związanych ze zdrowiem, a dzięki tym informacjom są w stanie zapewnić lepsze informacje zwrotne, wsparcie i wskazówki dotyczące zachowania zdrowia.
Wczesne wykrycie
Jeśli chodzi o wykrywanie chorób, takich jak rak, lekarze wykorzystują lata swojego doświadczenia w poszukiwaniu wzorców, które wykazują nieprawidłowości w skanowaniu lub diagnozie, i na podstawie znalezionych wzorców potwierdzają istnienie choroby. Dzięki zdolności rozpoznawania wzorców sztuczna inteligencja może być wykorzystywana do wykrywania chorób, nawet na wcześniejszych etapach niż specjaliści medyczni. W rzeczywistości sztuczna inteligencja jest już wykorzystywana we wczesnej diagnostyce raka z większą dokładnością. Według American Cancer Society duża część mammografii daje fałszywe wyniki. W rezultacie jedna na dwie zdrowe kobiety dowiaduje się, że ma raka. Naukowcy z HoustonMethodist Research Institute w Teksasie opracowali oprogramowanie AI, które może przeglądać i tłumaczyć mammogramy 30 razy szybciej i z 99-procentową dokładnością, zmniejszając potrzebę niepotrzebnych, inwazyjnych biopsji. Ponadto naukowcy z Mayo Clinic przeprowadzili badanie, w którym sztuczną inteligencję wykorzystano do szybkiego i niedrogiego wykrywania wczesnych stadiów chorób serca przy użyciu wyłącznie sygnałów elektrokardiograficznych (EKG), uzyskując dokładność 85,7 procent.
Diagnoza
Oprócz wczesnego wykrywania chorób przewlekłych sztuczna inteligencja jest również wykorzystywana do szeroko zakrojonej, potężnej ogólnej diagnozy stanów zdrowia. Na przykład program Watson for Health firmy IBM pomaga wielu organizacjom opieki zdrowotnej w stosowaniu technologii kognitywnych do zaawansowanych diagnoz. Watson jest w stanie przechowywać znacznie więcej informacji medycznych, w tym każde studium przypadku i odpowiedź na leczenie, każdy dziennik medyczny i każdy objaw, oraz przeglądać je z szybkością wykładniczo większą niż to tylko możliwe . Ponadto firma DeepMind Health firmy Google współpracuje z klinicystami i naukowcami, aby rozwiązywać problemy związane z opieką zdrowotną i przenosić pacjentów z testów do leczenia w krótszym czasie za pomocą sieci neuronowych, które naśladują ludzki mózg. Naukowcy wykorzystują również metody sztucznej inteligencji, aby znacznie zwiększyć dokładność diagnoz określonych chorób. System sztucznej inteligencji został opracowany przy użyciu algorytmów sztucznych sieci neuronowych (ANN) do diagnozowania chorób serca na podstawie sygnałów fonokardiogramu, zapewniając dokładność do 98 procent.
Podejmowanie decyzji
Sztucznie inteligentne technologie kognitywne są wprowadzane w dziedzinie opieki zdrowotnej, aby zmniejszyć ludzką rolę w podejmowaniu decyzji, a docelowo mają na celu zminimalizowanie czynnika ludzkiego błędu w podejmowaniu decyzji w opiece zdrowotnej. Według badania Johnsa Hopkinsa błędy medyczne są trzecią najczęstszą przyczyną śmierci w Stanach Zjednoczonych, ale niekoniecznie wynikają one ze złego personelu medycznego; zamiast tego są one często spowodowane błędami poznawczymi, takimi jak nieudane heurystyki i uprzedzenia, brak bezpieczeństwa i innych protokołów oraz nieuzasadniony kontrast w praktykach lekarzy. Sztuczna inteligencja okazała się obiecująca w wykonywaniu obciążenia poznawczego, zapewniając lepsze dokładności i ogólne wrażenia pacjenta. Badania wykazały, że wspomagane komputerowo odczyty obrazów radiologicznych są tak samo dokładne, jak te wykonywane przez radiologów. Może się to jednak wydawać zagrożeniem bezpieczeństwa pracy lekarzy i lekarzy na całym świecie. Jednak zamiast utraty pracy na dużą skalę spowodowanej automatyzacją ludzkiej pracy, sztuczna inteligencja może dać szansę na bardziej skoncentrowane na człowieku podejście do augmentacji. Wraz z przejęciem obciążeń poznawczych przez systemy sztucznej inteligencji klinicyści będą mogli swobodniej wykonywać zadania wyższego poziomu
Leczenie
Oprócz przeglądu wcześniejszych danych dotyczących zdrowia, aby pomóc pracownikom medycznym w diagnozowaniu chorób, sztuczna inteligencja może również pomóc im przyjąć bardziej integracyjne podejście do zarządzania chorobami, poprawić koordynację planów opieki zdrowotnej i pomóc pacjentom w zarządzaniu i przestrzeganiu ich długoterminowych programów leczenia. Sztuczna inteligencja może być również wykorzystywana do przewidywania skuteczności zabiegów medycznych i ich wyników. Korzystając z modelowania, fińscy naukowcy z Uniwersytetu Wschodniej Finlandii, szpitala KuopioUniversity i Uniwersytetu Aalto opracowali metodę porównywania różnych alternatyw leczenia i identyfikacji pacjentów, którzy odniosą korzyści z leczenia. Metoda oparta na sztucznej inteligencji opiera się na przyczynowych sieciach bayesowskich. Od prostych robotów laboratoryjnych do bardzo złożonych robotów chirurgicznych, zrobotyzowane metody leczenia chirurgicznego są stosowane w medycynie od ponad 30 lat i mogą albo wspomagać chirurga ludzkiego, albo wykonywać samodzielnie operacje. Wykorzystywane są również w powtarzalnych zadaniach, takich jak rehabilitacja i fizjoterapia. Sztuczna inteligencja poprawi wydajność robotów chirurgicznych, zapewniając większą optymalizację ruchu robota, a w przyszłości będą mogły samodzielnie wykonywać bardziej złożone operacje.
Opieka u schyłku życia
Według Banku Światowego średnia długość życia w Malezji wyniosła 75,3 lat w 2016 roku i wykazuje stały wzrost od lat 90. XX wieku. Ponieważ średnia długość życia na całym świecie rośnie, ludzie umierają wolniej i w inny sposób. Dzisiaj, gdy ludzie zbliżają się do końca życia, cierpią na schorzenia takie jak osteoporoza, niewydolność serca i demencja. Ta faza życia często obejmuje samotność i depresję. Chociaż sztuczna inteligencja nie zastąpi lekarzy pod koniec życia, umożliwi im podejmowanie lepszych decyzji. Medyczna sztuczna inteligencja wdroży MLA do analizy uporządkowanych danych i charakterystyki pacjentów w klastrach w celu przewidywania prawdopodobieństwa wystąpienia choroby. Ostrzeże to lekarzy o pogarszającym się stanie zdrowia, zanim stanie się on poważny i nieuleczalny. Na przykład MLA, które mogą wykryć występowanie pogarszającej się osteoporozy lub niewydolności serca, mogą umożliwić lekarzom podjęcie wczesnych działań, zanim stan się pogorszy, a pacjent zestarzeje się z nieuleczalnymi fazami tych schorzeń. Ponadto sztuczna inteligencja wraz z robotyką ma ogromny potencjał, aby zrewolucjonizować opiekę u schyłku życia, pomagając osobom starszym w dłuższej samodzielności i zmniejszając konieczność przyjęć do domów opieki lub szpitali. Narzędzia NLP stosowane przez sztuczną inteligencję mogą umożliwiać konwersacje i inne interakcje społeczne ze starzejącymi się ludźmi, aby zachować bystrość umysłu i spowolnić rozwój chorób, takich jak demencja.
Badania
Dostarczanie pacjentom nowego leku z laboratoriów badawczych to długi i kosztowny proces. Według Kalifornijskiego Stowarzyszenia Badań Biomedycznych, podróż leku z laboratorium badawczego do pacjenta zajmuje średnio 12 lat. Tylko pięć na 5000 leków, które rozpoczynają badania przedkliniczne, trafia do testów na ludziach, a tylko jeden z tych pięciu jest zatwierdzony do stosowania u ludzi. A opracowanie nowego leku z laboratorium badawczego do pacjenta będzie kosztować firmę średnio 359 milionów dolarów. Na spotkaniu CASP13 w Meksyku w grudniu 2018 r. DeepMind firmy Google pokonał doświadczonych biologów w przewidywaniu kształtów białek, podstawowych elementów budulcowych choroby. W procesie poszukiwania sposobów, w jakie leki mogą atakować choroby, uporządkowanie struktur białek jest niezwykle złożonym problemem. Istnieje więcej możliwych kształtów białek niż atomów we wszechświecie, co sprawia, że przewidywanie jest zadaniem niezwykle intensywnym obliczeniowo. Przez ostatnie 25 lat biolodzy obliczeniowi spędzili dużo czasu na tworzeniu oprogramowania, aby skuteczniej wykonywać to zadanie. Narzędzie, które może dokładnie modelować struktury białkowe, może przyspieszyć opracowywanie nowych leków. DeepMind, z ograniczonym doświadczeniem w fałdowaniu białek, ale wyposażony w najnowocześniejsze algorytmy sieci neuronowych, zrobił więcej niż 50 najlepszych laboratoriów z całego świata. Badania i odkrycia leków mogą być jednym z najnowszych zastosowań sztucznej inteligencji w opiece zdrowotnej, ale przynoszą obiecujące wyniki. Takie zastosowanie sztucznej inteligencji może znacząco skrócić zarówno czas wprowadzania nowych leków na rynek, jak i ich koszty.
Szkolenie
Sztuczną inteligencję, za pomocą algorytmów sieci neuronowych, można nauczyć rozumienia naturalnej mowy i interakcji z drugim człowiekiem prawie tak, jak człowiek, a to tworzy środowisko dla osób z sektora opieki zdrowotnej, które przechodzą szkolenie, aby przechodzić naturalistyczne symulacje w sposób, który jest prosty komputer- sterowane algorytmy nie są w stanie. Pojawienie się rozumienia i syntezy mowy naturalnej oraz potencjał sztucznie inteligentnego komputera do niemal natychmiastowego czerpania z dużej bazy danych scenariuszy może stwarzać wyzwania dla uczestników szkolenia w oparciu o szeroki zakres scenariuszy i danych poprzez zadawanie pytań, porad i decyzji oraz odpowiadanie na nie. Sesje szkoleniowe są również elastyczne i łatwo dostępne, ponieważ sieci neuronowe mogą uczyć się na podstawie odpowiedzi uczestnika szkolenia i dostosowywać wyzwania, aby zmaksymalizować tempo uczenia się uczestnika, a szkolenie można przeprowadzić w dowolnym miejscu dzięki wbudowaniu sztucznej inteligencji w smartfony i inne urządzenia mobilne. Oznacza to, że kursant może przejść szkolenie w mniejszych i szybszych sesjach, a nawet podczas chodzenia lub jazdy.
Big Data
Analityk branżowy Doug Laney sformułował definicję big data jako trzech V:
1. Wolumen (Volume)- dane są gromadzone z wielu różnych źródeł, takich jak dane maszynowe, dane z czujników, media społecznościowe i transakcje biznesowe. Przechowywanie tak dużych ilości danych było kiedyś dużym problemem. Jednak dzisiaj, przy dużych pojemnościach pamięci masowej i technologiach, takich jak Hadoop, proces ten stał się duży łatwiejszy.
2. Szybkość (Velocity) - Nowe dane są dziś wprowadzane z niezwykłą szybkością; konieczne jest szybkie przetwarzanie tych danych. Ciągłe wprowadzanie dzienników z aplikacji, tagów RFID, inteligentnych pomiarów, danych z mediów społecznościowych i danych z czujników sprawia, że bardzo ważne jest radzenie sobie z napływem danych w czasie zbliżonym do rzeczywistego.
3. Różnorodność (Variety) - wprowadzanie danych odbywa się zarówno w formatach ustrukturyzowanych, jak i nieustrukturyzowanych. Dane strukturalne obejmują uporządkowane dane w tradycyjnych bazach danych, a dane niestrukturalne obejmują dokumenty tekstowe, artykuły, e-maile i filmy.
Oprócz trzech powyższych V, SAS Institute, Inc. bierze pod uwagę dwa dodatkowe wymiary w big data:
1. Zmienność - Wraz z nadwyżką prędkości i różnorodności danych napływ danych może być bardzo nieprzewidywalny. Chociaż niektóre formy danych są przewidywalne, takie jak okres między logami danych z czujników, inne formy danych mogą przepływać niespójnie, na przykład temat zyskujący popularność w mediach społecznościowych. Takie formy przepływu danych mogą osiągać szczyt w dowolnym momencie dnia, co utrudnia zarządzanie dużymi danymi. Obsługa nieustrukturyzowanych danych po prostu zwiększa wyzwanie.
2. Złożoność - dane mogą pochodzić z wielu źródeł, co utrudnia łączenie, dopasowywanie, czyszczenie i przekształcanie danych w różnych systemach. Niemniej jednak ważne jest, aby powiązać relacje i hierarchie, w przeciwnym razie organizacja może szybko stracić kontrolę nad danymi.
Z drugiej strony Oracle twierdzi, że w ciągu ostatnich kilku lat pojawiły się jeszcze dwa V big data, które są wartością i prawdziwością. Powszechnie wiadomo, że dane są niezwykle cenne; jednak dopóki ta wartość nie zostanie zrealizowana, dane są bezużyteczne. Co ważniejsze, trzeba wiedzieć, czy dane są prawdziwe i wiarygodne. Korzystanie z niewiarygodnych danych zapewniłoby organizacjom niedokładne spostrzeżenia, które mogą wyrządzić więcej szkody niż pożytku. Znalezienie wartości w dużych zbiorach danych to coś więcej niż tylko analiza danych. Obejmuje cały proces eksploracji, który wymaga wnikliwych analityków, użytkowników biznesowych i kadry kierowniczej, którzy potrafią rozpoznawać wzorce, formułować świadome założenia i przewidywać zachowania. Według badań przeprowadzonych przez CB Insights, 32 firmy, które wykorzystują sztuczną inteligencję w swoich podstawowych obszarach działalności, przekroczyły w 2018 r. granicę wyceny 1 mld USD. Wykorzystują one uczenie maszynowe i inne rozwiązania sztucznej inteligencji w różnych dziedzinach, w tym w opiece zdrowotnej, pojazdach autonomicznych, cyberbezpieczeństwie i robotyce. Te firmy oparte na sztucznej inteligencji mają szereg modeli biznesowych i branż; łączy je jednak wspólna przewaga, którą dzielą także najbardziej innowacyjne i wartościowe organizacje na świecie, takie jak Alphabet, Amazon, Microsoft, Netflix, Salesforce czy Samsung. Zaletą jest to, że wykorzystują sztuczną inteligencję w analizie Big Data. Organizacje te przodują w łączeniu dużych ilości danych i możliwości sztucznej inteligencji w zróżnicowane rozwiązania o dużych wartościach rynkowych. Raport MIT Sloan Management Review nazywa połączenie dużych zbiorów danych i sztucznej inteligencji "pojedynczym najważniejszym osiągnięciem, które kształtuje przyszłość tego, w jaki sposób firmy czerpią wartość biznesową ze swoich danych i możliwości analitycznych" Według badania Forrester Business Technographics obejmującego ponad 3000 globalnych technologii i biznesu decydentów od 2016 r. 41 proc. światowych firm już inwestuje w sztuczną inteligencję, a kolejne 20 proc. planuje zainwestować w przyszłym roku. Na podstawie raportów analityka badawczego firmy Forrester, Brandona Purcella, dotyczących obecnego dużego zainteresowania sztuczną inteligencją i tego, czego można się po niej spodziewać, "Najlepsze wschodzące technologie w sztucznej inteligencji" oraz "Technologie i rozwiązania sztucznej inteligencji, I kwartał 2017 r.", większość dużych organizacji zaczyna integrować sztuczną inteligencję do swoich firm poprzez chatboty do obsługi klienta, co nazywa się "rozwiązaniami w zakresie obsługi konwersacyjnej". Odchodząc od zakodowanych na stałe chatbotów opartych na regułach, które są wstępnie zaprogramowane do wyszukiwania słów kluczowych i udzielania odpowiedzi z baz danych, obecnie chatboty są sztucznie inteligentne dzięki wykorzystaniu NLP i głębokiego uczenia. Wiele firm korzysta nawet z możliwości analizy obrazu, wideo i mowy, jakie daje sztuczna inteligencja, aby uzyskać wgląd w nieustrukturyzowane dane. Każdego dnia wprowadzane są duże ilości danych, a każdego dnia ilość dodawanych danych rośnie. Według Domo, Inc. do 2020 r. każda osoba na ziemi będzie generować 1,7 MB danych na sekundę. Wszystkie dodane dane mają potencjał rozwiązywania problemów, które są dziś prawie niemożliwe do rozwiązania, jeśli zostaną odpowiednio wykorzystane. I tu wkracza sztuczna inteligencja. Głębokie sieci neuronowe są w stanie działać aby dokładnie rozpoznawać wzory w wielu sytuacjach; jednak najpierw muszą zostać przeszkolone przy użyciu danych. Im więcej danych wykorzystanych w procesie uczenia, tym dokładniejszy model w tworzeniu prognoz. Obfitość zebranych danych zapewnia sztucznej inteligencji szkolenie potrzebne do identyfikowania różnic i dostrzegania drobniejszych szczegółów we wzorcach. Zwykle trudno jest wyodrębnić przydatne informacje z ogromnych zbiorów danych wraz z danymi nieustrukturyzowanymi. Jednak dzisiaj sztuczna inteligencja pomaga dużym firmom w uzyskiwaniu wglądu z danych, które przez długi czas znajdowały się w ogromnych bankach danych. W rzeczywistości dzisiejsze bazy danych zmieniają się i stają się coraz bardziej wszechstronne i wydajne. W porównaniu do konwencjonalnych relacyjnych baz danych, dziś istnieją potężne bazy danych grafowych. Te bazy danych są osadzone w sztucznej inteligencji i są w stanie kojarzyć punkty danych i odkrywać relacje. Według Singularity University proces wdrażania AI w analityce big data można podzielić na cztery różne kategorie. Najbardziej podstawową kategorią, która dostarcza najbardziej podstawowych spostrzeżeń dla organizacji, jest analityka opisowa, w której dane z przeszłości są wykorzystywane do opisu wydarzeń w organizacji. Na przykład firma A, której sprzedaż spada od lat, może skorzystać z systemu analityki opisowej, który pokazuje dokładnie, jaka jest sprzedaż firmy, traci w ujęciu rocznym, kwartalnym i miesięcznym. Kolejna kategoria to analityka diagnostyczna, która wyszukuje wzorce w danych, aby przedstawić historię. Na przykład firma A może wykorzystać analitykę diagnostyczną do badania i analizowania danych dotyczących warunków rynkowych i przeszłych transakcji, aby zapewnić bardziej szczegółowy wgląd w schematy, w których firma traciła sprzedaż, co opowiada historię o tym, jak firma A traciła sprzedaż i co to spowodowało. W ten sposób firma A może rozpocząć poszukiwanie rozwiązań problemu, eliminując źródła problemu. Następnie analityka predykcyjna wykorzystuje istniejące dane do przewidywania przyszłych zdarzeń. Firma A może również korzystać z analiz predykcyjnych do przewidywania przyszłości swoich firm, dzięki czemu może zdecydować, w jaki sposób będzie musiała utrzymać lub zmienić swoje strategie biznesowe, aby dostosować się do zmian rynkowych. Wreszcie, analiza nakazowa zapewnia największą wartość i spostrzeżenia dzięki informacjom kognitywnym, które umożliwiają podjęcie decyzji o kolejnym kierunku działania w celu uzyskania maksymalnych korzyści. Zastosowanie analityki nakazowej może pomóc firmie A w procesie zarządzania firmą, poprzez zasady, modele i polityki, które zostały przez firmę ustalone. Na tym etapie system AI pełni w firmie rolę konsultanta. Wiele organizacji stosuje te strategie na różnych poziomach iw różnych kombinacjach; jednak organizacje, które odnoszą największe sukcesy w analizie Big Data, mają solidną wiedzę na temat analiz predykcyjnych i nakazowych. Dzięki bardziej dogłębnym zastosowaniom tych strategii organizacje mają tendencję do lepszego zrozumienia zachowań klientów, lepszego wglądu w wyniki biznesowe obecnie i w przyszłości, kluczowych wskaźników wydajności dla podejmowania decyzji oraz większej ogólnej przewagi nad swoimi mniej opartymi na danych konkurentami. . W przyszłości integracja sztucznej inteligencji i technik uczenia maszynowego z analityką big data może oznaczać sukces lub porażkę organizacji. Przy tak dużych ilościach przepływających obecnie danych wiele organizacji korzysta już z zaawansowanej analityki, aby wykorzystać posiadane dane. Obejmuje to prognozowanie odpowiednich trendów technologicznych i rynkowych, które umożliwiłyby im proaktywne podejmowanie niezbędnych działań i podejmowanie lepszych decyzji w celu dostosowania się i wyprzedzenia konkurentów nawet przed zmianami na rynku. Miałyby również tę zaletę, że wykorzystywałyby analitykę predykcyjną, aby zminimalizować występowanie efektu HiPPO, czyli oparcia się na Opinii Najwyższego Płatnika, a nie danych, które opowiadają rzeczywistą historię aktualnej sytuacji biznesowej. Ponadto przy obecnej mocy obliczeniowej systemy sztucznej inteligencji byłyby w stanie z łatwością śledzić postęp i prędkość każdego projektu realizowanego w organizacji na każdym etapie rozwoju oraz przewidywać wartość i wynik każdego projektu, aby organizacje mogły zmaksymalizować wartościowe projekty i zminimalizować projekty związane z białym słoniem.
Transport i infrastruktura
Zastosowanie AI w branży infrastrukturalnej to wykrywanie defektów struktury. Korzystając z wizji komputerowej wraz z głębokim uczeniem, struktury lub poszczególne elementy wyposażenia mogą być stale skanowane pod kątem usterek, aby można było zidentyfikować problemy, zanim staną się poważne. W większości przypadków defekty strukturalne narastają z czasem i pozostają niezauważone, a zanim staną się wystarczająco poważne, aby można je było zauważyć, naprawa wady staje się procesem kosztownym, trudnym i czasochłonnym. Jeśli wada zostanie wykryta we wcześniejszych stadiach, problem można łatwiej rozwiązać. Dziś modelowanie rzeczywistości jest już wykorzystywane do wykrywania wad w betonie lub pęknięć w konstrukcji, podkreślając wagę problemu. Po wykryciu i fragmentacji defektu inżynierowie mogą określić skalę defektu wraz z innymi informacjami, takimi jak kształt i rozmiar defektu. Dzięki tym informacjom inżynierowie mogą łatwiej i szybciej sformułować rozwiązanie. Oprócz wykrywania wad konstrukcyjnych sztuczna inteligencja jest wykorzystywana do przeprowadzania zdalnych i autonomicznych inspekcji, aby skrócić czas trwania inspekcji i zmniejszyć ryzyko zawodowe inspektorów. Firma Aiview Group, będąca klientem, poprawia się w zakresie pomiarów, konserwacji i inspekcji ponad 4000 budynków infrastrukturalnych każdego roku, używając bezzałogowego statku powietrznego (UAV) firmy Leica Geosystems do generowania bardzo precyzyjnych danych do inspekcji mostów. Opracowali również algorytm oceny zdjęć zrobionych przez UAV i wykrywania problemów z biblioteką taksonomii defektów, która sprawdza problemy z cementem, żelazem dla mostu, roślinnością i ogólnie środowiskiem, według Marietti, inspektora mostu z Grupa Aiview. Ponadto bloki Komisji Mieszkaniowej i Rozwoju (HDB) w Jurong East w Singapurze rozpoczęły wykorzystywanie dronów z wbudowanymi kamerami w celu uzupełnienia działań związanych z inspekcją budynków, szczególnie w miejscach trudno dostępnych lub takich, które mogą stanowić większe zagrożenie dla inspektorów. Dron był obsługiwany przez HUS Unmanned Systems, a analizę obrazu przeprowadza system AI firmy H3 Zoom.AI. Dron wykonuje tysiące zdjęć, które są przesyłane do systemu AI hostowanego w chmurze w celu przeprowadzenia analizy. Następnie system identyfikuje usterki w raporcie generowanym automatycznie po każdej inspekcji. Aby chronić prywatność mieszkańców, oprogramowanie maskujące zamazuje szczegóły, jeśli podczas inspekcji zostaną zrobione zdjęcia mieszkańców. Popularnie rosnącym zastosowaniem sztucznej inteligencji w branży transportowej są pojazdy autonomiczne. Chociaż w pełni autonomiczne samochody i ciężarówki są jeszcze w powijakach, liczba produkowanych nowych autonomicznych pojazdów rośnie w szybkim tempie. Według badania przeprowadzonego przez Allied Market Research, światowy rynek pojazdów autonomicznych będzie wart 54,23 mld USD w 2019 r., a do 2026 r. wzrośnie do 556,67 mld USD, przy łącznym rocznym tempie wzrostu wynoszącym 39,47 proc. w tym okresie . Oznacza to, że wartość globalnego rynku pojazdów autonomicznych wzrośnie ponad dziesięciokrotnie w latach 2019-2026. Zbudowano również prototypy dla większych pojazdów autonomicznych, takich jak pojazdy do zbiórki śmieci, a Szwecja i Niemcy pilotowały autobusy bez kierowcy. Pojazdy autonomiczne to pojazdy zdolne do przyspieszania, hamowania i manewrowania po drogach bez ingerencji człowieka. Opierają się na wyspecjalizowanych czujnikach, takich jak czujniki wykrywania światła i zasięgu (Lidar), radary, anteny GPS i kamery, aby zrozumieć swoją aktualną lokalizację, otoczenie i otaczające je obiekty, aby podjąć decyzję o kolejnym działaniu. Wykorzystując lidar do pojazdów autonomicznych, firmy najpierw wyposażają zwykłe pojazdy w czujniki lidarowe, które zbierają informacje i generują mapę otoczenia. Gdy mapa jest gotowa, pojazdy autonomiczne mogą używać mapy do śledzenia swojego otoczenia i porównywania mapy z rzeczywistym otoczeniem, aby zrozumieć, gdzie się znajduje i jakie obiekty leżą wokół niego. Towarzyszy temu GPS, aby poprawić oszacowanie pozycji pojazdu. Korzystając z transmisji na żywo z kamer zainstalowanych wokół pojazdu, pojazdy autonomiczne mogą zrozumieć otaczające je obiekty, takie jak poruszające się samochody i motocykle oraz pieszych, poprzez wykrywanie i rozpoznawanie obiektów. Może również uzyskać informacje, takie jak odległość od pojazdu do obiektu i szybkość zbliżania się do pojazdu. Ze względu na złożoność zdarzeń, które mogą wystąpić w prawdziwym życiu, zaprogramowanie działania pojazdu autonomicznego w każdej możliwej sytuacji za pomocą zestawu reguł byłoby prawie niemożliwe. Firmy takie jak Waymo i Uber polegają na uczeniu maszynowym, aby uczyć się zachowań za pomocą dużych ilości danych dotyczących dróg i zachowań innych obiektów na drogach. Wzrost wykorzystania pojazdów autonomicznych przyniósłby wiele korzyści nie tylko użytkownikom dróg, ale ostatecznie gospodarce kraju i środowisku. Wraz ze wzrostem liczby pojazdów autonomicznych ogólny ruch na drogach się zmniejszy. Naukowcy Dan Work z Vanderbilt University i Benjamin Seibold z Temple University ustalili w swoim artykule badawczym, że nawet procent pojazdów autonomicznych tak mały, jak 5 procent, może mieć znaczący wpływ na eliminację fal i zmniejszenie całkowitego zużycia paliwa nawet o 40 na procent i wypadki hamowania nawet o 99 procent. Naturalnie, kierowcy mają tendencję do tworzenia ruchu typu stop-and-go z powodu naturalnych oscylacji podczas jazdy przez człowieka. Zwykle dzieje się tak w przypadkach, gdy ktoś zmienia pas lub łączy się. Naukowcy odkryli, że kontrolując tempo autonomicznego samochodu w swoich eksperymentach terenowych, autonomiczny samochód rozpraszałby fale stop-and-go, więc ruch uliczny nie oscyluje, jak to ma miejsce, gdy wszystkie samochody są prowadzone przez ludzi. Ponadto powszechne stosowanie pojazdów autonomicznych może wyeliminować do 90 procent wypadków w samych Stanach Zjednoczonych, zapobiegając szkodom i kosztom zdrowotnym sięgającym 190 miliardów USD rocznie i ratując tysiące istnień ludzkich, wynika z nowego raportu firmy konsultingowej McKinsey. & Co. Dzięki zmniejszeniu korków i bardziej zoptymalizowanym algorytmom jazdy pojazdy autonomiczne znacznie zmniejszą emisje. Według artykułu, samo korzystanie z autonomicznych taksówek elektrycznych może zmniejszyć emisje gazów cieplarnianych o 87-94% na milę do roku 2030. Te korzyści ostatecznie wynikają z zastosowania sztucznej inteligencji w optymalizacji ruchu pojazdu w celu zminimalizowania czasu podróży , zużycie i ogólne zagęszczenie ruchu. Oprócz wyżej wymienionych korzyści płynących ze sztucznej inteligencji w pojazdach, sztuczna inteligencja prowadziłaby również do większej wydajności samochodów elektrycznych. Dr Michael Fairbank i dr Daniel Karapetyan z University of Essex pracowali z firmą Spark EV Technology, aby opracować algorytmy, które pomogą pojazdom elektrycznym w dalszej podróży między ładowaniami i eliminują stres kierowców, którzy nie wiedzą, czy mają wystarczającą moc, aby ukończyć podróż. Oprogramowanie gromadzi dane na żywo dotyczące wielu zmiennych, takich jak warunki drogowe, warunki pogodowe, zużycie opon i zachowanie kierowcy, aby przewidzieć, ile energii jest potrzebne do każdej podróży. Spark wykorzystuje uczenie maszynowe do porównywania prognozy z rzeczywistym zapotrzebowaniem na energię, aby zwiększyć dokładność każdej przyszłej podróży. Sztuczna inteligencja jest również wykorzystywana w systemach transportu publicznego do planowania i optymalizacji harmonogramów systemów transportowych, ostatecznie oszczędzając czas pasażerów i koszty operacyjne. Według Retail Sensing, ich automatyczny system liczenia pasażerów oszczędza brytyjskiej firmie autobusowej tysiące funtów na autobus] . Automatycznie zlicza liczbę osób, które wsiadają i wysiadają z autobusu, aby sprawdzić liczbę pasażerów z transakcjami w automatach biletowych. Kiedy firma zdała sobie sprawę, że liczba pasażerów była większa niż liczba transakcji biletowych, podjęła działania w celu naprawienia brakujących przychodów z taryf. Licząc liczbę osób, które wsiadają i wysiadają z autobusu, firma transportowa może zebrać dane, które pomogą w planowaniu i prognozowaniu. Mogą również z łatwością generować raporty dla zewnętrznych agencji finansujących, takich jak władze regionalne, i monitorować jazdę na przestrzeni czasu. Jest to również ważne w analizie wydajności, dając miary, takie jak liczba pasażerów na milę, koszt na pasażera i liczba pasażerów na kierowcę. System liczenia wykorzystuje rozpoznawanie obiektów do rozpoznawania osób, a następnie zlicza liczbę osób wchodzących lub wychodzących z autobusu w oparciu o kierunek ich ruchu w materiale wideo. Retail Sensing twierdzi, że system zliczania wideo ma dokładność 98 procent, czyli większą niż ręczne zliczanie, które jest dokładne tylko w około 85 procentach. Sztuczna inteligencja jest również wykorzystywana w przestrzeni nawigacyjnej, aby zapewnić użytkownikom najszybszą trasę do celu. Mobilne aplikacje nawigacyjne, takie jak Waze i Mapy Google, wykorzystują algorytmy odnajdywania ścieżek AI, aby sugerować najwygodniejsze trasy, aby dotrzeć do żądanego miejsca docelowego. Decyzję podejmuje się na podstawie wielu czynników, w tym preferencji użytkownika dotyczących tras bez opłat i warunków na drodze. Dzięki dużej ilości danych gromadzonych przez aplikacje nawigacyjne z dużą liczbą codziennych użytkowników, mogą one stale szkolić swoje algorytmy uczenia maszynowego i głębokiego uczenia, aby poprawić wrażenia użytkowników, analizując i testując duże ilości danych. Ponadto użytkownicy mogą ustawić alarm na czas, w którym muszą opuścić swoją lokalizację, aby dotrzeć do miejsca docelowego w określonym czasie. Te platformy nawigacyjne stale zbierają dane o ruchu i przechowują je w oparciu o określone funkcje, takie jak pora dnia, dzień tygodnia, święto państwowe i warunki pogodowe. Trenując algorytmy AI na podstawie zebranych danych, są w stanie dokładnie przewidzieć, jak warunki drogowe będą się zmieniać w przyszłości i zapewnić użytkownikom dokładny czas podróży. Dzieje się tak również w przestrzeni e-mailowej. Firmy takie jak Uber i Grab są w stanie dokładnie oszacować cenę przejazdu podczas rezerwacji taksówki za pomocą uczenia maszynowego. Co więcej, wykorzystują również algorytmy sztucznej inteligencji w wyborze najlepszego kierowcy dla każdego pasażera, aby zminimalizować czas oczekiwania i objazdy. W przeciwieństwie do aplikacji nawigacyjnych, takich jak Waze i Mapy Google, które opierają się na dużych ilościach danych geolokalizacyjnych użytkownika do obliczania warunków drogowych, można korzystać z systemów prognozowania ruchu opartych na kamerach, wykonując analizę ruchu na obrazie wideo przechwyconym przez kamery drogowe zainstalowane na drogach i autostrady. Takie systemy przewidywania ruchu oparte na kamerach działają poprzez rozpoznawanie obiektów na klatkach wideo i zliczanie liczby różnych typów pojazdów na różnych drogach. Jest to konieczne, aby uzyskać oddzielne dane o ruchu dla każdej drogi i zrozumieć, jak różne rodzaje pojazdów wpływają na ruch. Na przykład ciężarówki mają większy wpływ na zagęszczenie ruchu w porównaniu do motocykli, ponieważ zajmują większy obszar i zazwyczaj przyspieszają wolniej niż motocykle. Przybliżona prędkość pojazdów jest również obliczana poprzez obliczenie odległości przebytej przez pojazd między klatkami i pomnożenie jej przez liczbę klatek na sekundę. Średnia liczba pojazdów i średnia prędkość pojazdu w większości wystarczają do zrozumienia warunków ruchu na określonej drodze. Dane te można wykorzystać do obliczenia współczynnika zagęszczenia ruchu dla każdej drogi na skrzyżowaniu, aby zrozumieć, jak przepływa ruch na drogach i skrzyżowaniach. Dane o ruchu drogowym można następnie wykorzystać do trenowania modelu głębokiego uczenia, który może być następnie wykorzystany do przewidywania warunków ruchu na podstawie różnych czynników, takich jak pora dnia i warunki pogodowe (rysunek 8.7). Dodatkową korzyścią z używania kamer drogowych na skrzyżowaniach z sygnalizacją świetlną jest to, że zebrane dane o ruchu mogą być bezpośrednio wykorzystywane do sterowania sygnalizacją świetlną. Zwykle celem sterowania sygnalizacją świetlną jest zapewnienie równomiernego ruchu na wszystkich drogach. Dlatego konwencjonalnie różne sygnalizacje świetlne na skrzyżowaniu są programowane z tym samym czasem trwania światła czerwonego i zielonego. Jednak zwykle tak nie jest, ponieważ natężenie ruchu na różnych drogach zmienia się w ciągu dnia w zależności od kierunku dróg. Na przykład rano natężenie ruchu może być wyższe na drodze prowadzącej z obrzeży do miasta w porównaniu z drogą prowadzącą z miasta na przedmieścia, ponieważ wielu mieszkańców z przedmieść pracuje w mieście. Wieczorami działo się odwrotnie, bo mieszkańcy wracali do swoich domów po pracy. Dłuższy czas trwania zielonego światła powinien być zapewniony na drogach o większym natężeniu ruchu, aby zmaksymalizować przepływ ruchu przez skrzyżowanie. Ponieważ system może z dużą dokładnością obliczyć liczbę pojazdów na każdej drodze, dane te można wykorzystać do kontrolowania czasu rotacji sygnalizacji świetlnej.
Planowanie i zarządzanie energią
Ze względu na niską sprawność i destrukcyjny wpływ nieodnawialnych źródeł energii na środowisko, o których dyskutowano podczas rozmów klimatycznych ONZ w Polsce, wiele narodów aktywnie podejmuje wysiłki na rzecz zwiększenia wykorzystania odnawialnych źródeł energii, takich jak energia słoneczna, wiatrowa i wodna, co są korzystne dla środowiska. Jednak korzystanie z odnawialnych źródeł energii stanowi wyzwanie dla energetyki ze względu na nieprzewidywalny charakter zużycia energii przez konsumentów i odnawialne źródła energii. Sztuczna inteligencja służy do rozwiązania tego problemu i poprawy ogólnego procesu wytwarzania, przesyłu, dystrybucji i zużycia energii, przy jednoczesnym obniżeniu całkowitych kosztów procesów i minimalizacji strat energii. Jest używany w różnych zastosowaniach w przemyśle energetycznym, w tym w prognozowaniu wahań podaży i popytu na energię, aby dostawcy mogli zapewnić nieprzerwaną dostępność energii, oraz optymalizację zużycia energii elektrycznej w celu zmniejszenia marnotrawstwa. Na przykład DeepMind firmy Google obniżył zużycie energii w swoich centrach danych o 15 procent, korzystając z umowy MLA. Prowadzone są również badania nad wykorzystaniem sztucznie inteligentnych systemów do łagodzenia zjawiska miejskiej wyspy ciepła, którą definiuje się jako obszar metropolitalny, który jest znacznie cieplejszy niż otaczające go obszary wiejskie. Ciepło generowane jest przez pojazdy, takie jak samochody, autobusy i pociągi oraz budynki w dużych miastach, takich jak Nowy Jork, Pekin i Kuala Lumpur. Ze względu na ciepło wytwarzane przez pojazdy i właściwości izolacyjne materiałów budowlanych, ciepło jest gromadzone i wychwytywane w dużych miastach, tworząc miejskie wyspy ciepła, co pogarsza jakość powietrza i wody oraz obciąża rodzime gatunki, takie jak organizmy wodne przyzwyczajone do niższych temperatur. Aby złagodzić ten problem, badana jest integracja i optymalizacja inteligentnych systemów sterowania dla budynków o zerowym zużyciu energii. Inteligentne technologie sterowania, takie jak metody oparte na uczeniu, w tym systemy rozmyte i sieci neuronowe, technika sterowania predykcyjnego opartego na modelach (MPC) i systemy sterowania oparte na agentach, są prawdopodobnymi technikami, które spełniają kilka celów, w tym zwiększenie efektywności energetycznej i kosztowej operacji budowlanych oraz poziom komfortu w budynkach. Technologie te mogą być stosowane w sterowaniu siłownikami systemów zacieniających, systemów wentylacyjnych, pomocniczych systemów ogrzewania/chłodzenia oraz sprzętu AGD w celu optymalizacji kosztów i zużycia energii elektrycznej. Podczas gdy zużywają energię elektryczną, pojazdy elektryczne staną się również mobilnymi magazynami energii dla inteligentnej sieci, eksportując energię do sieci. Wraz ze wzrostem popularności pojazdów elektrycznych sieć stanie się bardziej elastyczna w reagowaniu na podaż i zapotrzebowanie na energię. Pojazdy byłyby wyposażone w dopracowane technologie Vehicle-to-grid (V2G) i Grid-to-vehicle (G2V), aby sprostać wyzwaniom związanym z wykorzystaniem technik energii odnawialnej. Na przykład, jeśli w mieście nastąpi nagły nieoczekiwany wzrost zapotrzebowania na energię elektryczną, dostawcy energii mogą nie być w stanie natychmiast dostarczyć dużej ilości energii elektrycznej do odbiorców z powodu niedoboru dostępnej energii. Mogą natychmiast zwiększyć produkcję energii elektrycznej z elektrowni wodnych, a nawet elektrowni węglowych; jednak nadal może występować opóźnienie w przesyłaniu energii ze stacji do odbiorców. W takim przypadku inteligentna sieć może tymczasowo pobierać energię elektryczną zmagazynowaną w akumulatorach pojazdów elektrycznych podłączonych do sieci i dostarczać energię elektryczną, aby zaspokoić wzrost zapotrzebowania. Do czasu, gdy wytworzona energia będzie gotowa do użycia, inteligentna sieć może nadal ładować pojazd elektryczny, aby zastąpić pobraną energię. Francisco Carranza, dyrektor ds. usług energetycznych w Nissan Europe, potwierdził, że pojazdy elektryczne mogą być wykorzystywane z korzyścią dla sieci. Badanie przeprowadzone w Danii przez Nissana i Enel S.p.A., największego włoskiego przedsiębiorstwa energetycznego, wykazało, że przedsiębiorstwa użyteczności publicznej mogą wykorzystywać zaparkowane pojazdy elektryczne do pompowania energii do sieci, a nawet zapewniać właścicielom pojazdów zwrot pieniężny. Chociaż wykorzystanie pojazdów elektrycznych do wspierania inteligentnych sieci w dostarczaniu energii może rozwiązać wielkie wyzwanie stojące przed systemami inteligentnych sieci, stanowi nowe wyzwanie dla właścicieli pojazdów elektrycznych. Z jednej strony wiadomo, że pojazdy elektryczne mają bardziej ograniczony zasięg w porównaniu z pojazdami benzynowymi, co oznacza, że pozyskiwanie zmagazynowanej energii z pojazdów elektrycznych dodatkowo ograniczyłoby dostępną energię zmagazynowaną w pojazdach elektrycznych, potencjalnie powodując unieruchomienie użytkowników, gdyby byli podróżować na większe odległości. Z drugiej strony, przy dużej liczbie pojazdów elektrycznych, które mają być podłączone do sieci, lokalne sieci dystrybucyjne napotkają szczyty, które mogą skutkować wysokimi cenami energii elektrycznej i przeciążeniem elektrycznym. Obecnie prowadzone są duże ilości badań w celu opracowania strategii rozwiązywania tych problemów. Wśród najpopularniejszych technik znajduje się wykorzystanie sztucznej inteligencji do usprawniania pojazdów elektrycznych i systemów zarządzających zbiorami pojazdów elektrycznych. Na podstawie ankiety dotyczącej zarządzania pojazdami elektrycznymi w inteligentnej sieci za pomocą sztucznej inteligencji opracowano kilka technik sztucznej inteligencji o różnej złożoności i skuteczności, aby rozwiązać szeroki zakres problemów związanych z pojazdami elektrycznymi i inteligentnymi sieciami, w tym:
1. Energooszczędne wyznaczanie tras pojazdów elektrycznych i maksymalizacja zasięgu w celu wyznaczania tras pojazdów elektrycznych w celu zminimalizowania strat energii i maksymalizacji energii zebranej podczas podróży. Obejmuje to również maksymalizację wydajności baterii, aby zmaksymalizować żywotność baterii.
2. Zarządzanie zatorami w celu zarządzania i kontroli ładowania pojazdów elektrycznych tak, aby zminimalizować kolejki na stacjach ładowania i dyskomfort kierowców.
3. Włączenie pojazdów elektrycznych do inteligentnej sieci w celu planowania i kontrolowania ładowania pojazdów elektrycznych w celu uniknięcia szczytów i ewentualnych przeciążeń sieci elektrycznej przy jednoczesnym zminimalizowaniu kosztów energii elektrycznej.
Szanse i zagrożenia
Wcześniej omówiono zastosowanie AI w różnych aspektach miast w tworzeniu inteligentnych miast. Oczywiste jest, że sztuczna inteligencja i techniki uczenia maszynowego są nie tylko szybko rozwijane, ale są już przyjmowane przez miasta w celu obniżenia kosztów operacyjnych, zwiększenia zrównoważonego rozwoju i ostatecznie poprawy jakości życia. Obecnie większe korporacje używają głównie inteligentnych narzędzi analitycznych do badania swoich danych, ponieważ mają więcej danych, z którymi muszą sobie radzić i są w stanie pozwolić sobie na tak drogie systemy, podczas gdy mniejsze firmy i firmy mogą nadal nie mieć konieczności i możliwości korzystania z takich systemów. Jednak w miarę postępów w rozwoju narzędzi uczenia maszynowego i coraz większej liczby firm i organizacji zaczynających stosować te systemy, koszty operacyjne tych inteligentnych narzędzi analitycznych zmniejszą się, umożliwiając mniejszym firmom korzystanie z nich. Ponadto, ponieważ firmy stają się coraz bardziej zależne od danych, aby zmaksymalizować swoje przychody, w końcu zaczną brakować umiejętności analizy dużych ilości danych i ostatecznie będą wymagać AI do obsługi ich operacji. Ponieważ algorytmy NLP i rozpoznawania obiektów wciąż się poprawiają, organizacje i rządy będą miały większe zaufanie do korzystania z nich w celu poprawy usług i przejmowania zadań, gdy mogą wykonać zadanie z większą wydajnością. Na przykład większość dzisiejszych sygnalizacji świetlnych jest programowana za pomocą sterowników PLC i zaprogramowana jest tak, aby mieć ustalone czasy dla każdego pasa ruchu na skrzyżowaniu. Niekoniecznie musi to być najlepsza metoda minimalizowania ruchu, ponieważ sygnalizacja świetlna na pustym pasie może być zielona, podczas gdy sygnalizacja świetlna na zatłoczonym pasie jest czerwona. Funkcjonariusz policji drogowej kontrolujący ruch drogowy wykonałby lepszą pracę niż taki system sygnalizacji świetlnej, ponieważ może zapewnić bardziej zatłoczone drogi więcej "czasu zielonego światła". Jednak system AI, który analizuje dane o ruchu w celu sterowania sygnalizacją świetlną, może przewyższać oba systemy. Dzięki licznym połączonym ze sobą kamerom drogowym w całym mieście, wraz z danymi geolokalizacyjnymi ruchu, systemy AI mogą optymalizować czasy sygnalizacji świetlnej dla wszystkich sygnalizacji świetlnej na wszystkich skrzyżowaniach miasta, aby zminimalizować skutki zatorów na jednym skrzyżowaniu na drugim skrzyżowaniu miasta. Jednak rządy musiałyby mieć dużą pewność co do takiego systemu, zanim wdrożą go na dużą skalę. Jeśli system AI kontrolujący ruch ulegnie awarii, spowoduje to duże zatory w całym mieście. Firmy, które opracowują te systemy AI, zaczynałyby od przetestowania systemu w symulacjach, a następnie do testów na mniejszą skalę, zanim w pełni wdrożą taki system. Najczęściej rozwijany rodzaj sztucznej inteligencji jest znany jako wąska sztuczna inteligencja, co oznacza, że jest przeznaczony do wykonywania określonego zadania i nie wykonuje innych rodzajów zadań. Większość przykładów wykorzystania sztucznej inteligencji opisanych tu, takich jak rozpoznawanie twarzy, NLP i przewidywanie ruchu, jest klasyfikowana jako wąska sztuczna inteligencja. Jednak wielu badaczy pracuje nad rozwojem ogólnej sztucznej inteligencji, która może dobrze wykonywać wiele zadań. Podczas gdy wąskie systemy sztucznej inteligencji są w stanie przewyższyć ludzi w określonych zadaniach, ogólne systemy sztucznej inteligencji byłyby w stanie prześcignąć ludzi w wielu zadaniach poznawczych. Chociaż sztuczna inteligencja jest postrzegana jako bardzo korzystna w automatyzacji codziennych zadań, wiele znanych nazwisk w nauce i technologii, takich jak Elon Musk, Bill Gates i Stephen Hawking, wraz z wieloma czołowymi badaczami sztucznej inteligencji wyraziło swoje obawy dotyczące zagrożeń stwarzanych przez sztuczną inteligencję. Obawy pojawiły się, gdy rozwój sztucznej inteligencji, który eksperci przewidywali, że będzie oddalony o dziesięciolecia, został osiągnięty zaledwie 5 lat temu, co doprowadziło do możliwości superinteligencji w naszym życiu. Większość badaczy zgadza się, że superinteligentna sztuczna inteligencja prawdopodobnie nie będzie przedstawiać ludzkich emocji, więc nie spodziewają się, że sztuczna inteligencja stanie się celowo uprzejma lub złośliwa. Według Future of Life, przy rozważaniu, w jaki sposób sztuczna inteligencja może stać się zagrożeniem, eksperci biorą pod uwagę następujące dwa scenariusze:
1. AI jest zaprogramowana do robienia czegoś destrukcyjnego. Przykładem technologii dostosowanej do tego scenariusza jest broń autonomiczna, która może powodować masowe ofiary. W miarę jak techniki sztucznej inteligencji staną się bardziej zaawansowane, niektóre strony zdadzą sobie sprawę z potencjału sztucznej inteligencji w powodowaniu geofizycznych uszkodzeń na dużą skalę, co wkrótce doprowadzi do wynalezienia autonomicznej broni sztucznej inteligencji. Ponadto wyścig zbrojeń AI może doprowadzić do wojny AI, która może spowodować straty przekraczające wojny toczone przez ludzi. Nawet przy wąskiej AI to ryzyko jest obecne. Wraz z rozwojem ogólnej sztucznej inteligencji, broń autonomiczna zyskałaby większą autonomię, powodując, że ludzie prawdopodobnie straciliby kontrolę nad sytuacją.
2. Cel AI staje się niezgodny z celem, w jakim został stworzony. W tym scenariuszu, w przeciwieństwie do poprzedniego, sztuczna inteligencja jest zaprogramowana do wykonania korzystnego zadania; jednak opracowuje destrukcyjną metodę osiągnięcia swojego celu. Może się tak zdarzyć, gdy AI otrzymuje zadanie do rozwiązania lub wykonania i skupia się wyłącznie na rozwiązaniu problemu bez uwzględniania konsekwencji swoich działań w innych aspektach. Jeśli superinteligentny system otrzyma zadanie wykonania dużego projektu geoinżynieryjnego, może to wyrządzić szkodę ekosystemowi jako efekt uboczny, ponieważ jego jedynym celem jest wykonanie danego zadania, bez względu na konsekwencje.
Badania nad bezpieczeństwem AI to obszar badań, który koncentruje się na zapewnieniu, że cel AI jest zawsze zgodny z naszym, a jednocześnie AI musi troszczyć się o ludzkość i środowisko. Z powyższych scenariuszy widać, że troska o zaawansowaną sztuczną inteligencję nie wynika z obawy, że może stać się zła, ale że osiąga poziom kompetencji, na którym ludzie nie są w stanie jej powstrzymać. Podczas gdy tygrysy znajdują się na szczycie łańcucha pokarmowego w dżungli, są obezwładnieni przez ludzi, ponieważ nasza inteligencja znacznie przewyższa ich inteligencję. Ponieważ sztuczna inteligencja znacznie przewyższa ludzką inteligencję, może uzyskać podobną formę kontroli nad nami. Kluczowym celem badań nad bezpieczeństwem AI jest zapewnienie, że motywacja AI w wykonywaniu jej zadań nigdy nie przewyższa bezpieczeństwa ludzkości i środowiska.
Jak roboty przemysłowe tworzą inteligentne fabryki
Od wielu lat roboty przemysłowe są wykorzystywane do zmiany masowej produkcji i automatyzacji rejestracji w celu szybszego i bezpieczniejszego wykonywania unikalnych procedur bez żadnych potknięć. Masowa produkcja z robotów przemysłowych obniża koszt produktu i zwiększa szybkość dostawy bez większych błędów. Procedury produkcyjne, rozwój technologii, inteligentny łańcuch dostaw i aspekty handlowe zostały zmienione przez Przemysł 4.0. Sztuczna inteligencja (AI) i uczenie maszynowe zmieniły starsze sposoby realizacji procesów i obsługi robotów przemysłowych. W tym celu przeprowadzono nowatorskie badania i opracowano plany dotyczące przyszłej generacji robotów, linii automatyzacji i inteligentnych fabryk. Chociaż Przemysł 4.0 nie jest powszechnie używanym terminem i znaną ideą, to jest wyjątkowo zdolny do poprawy ludzkiego życia. Prognozuje się, że wszystkie procedury produkcyjne i poziomy dostaw będą miały wpływ na produkcję. W tym rozdziale opisano związek Przemysłu 4.0 i inteligentnych fabryk w zakresie robotów przemysłowych oraz omówiono korzyści i zastosowania. Wpływ robotów przemysłowych na inteligentne fabryki i przyszłe oczekiwania zostaną omówione w dalszej części tekstu.
Przemysł 4.0 i roboty przemysłowe
Jaki jest główny wpływ Przemysłu 4.0 na inteligentne maszyny i jak inteligentne fabryki są generowane przez roboty przemysłowe? Na początku wyrażenie "Czwarta Rewolucja Przemysłowa" lub cyfryzacja produkcji, zwłaszcza "Przemysł 4.0", zostało wprowadzone w ramach niemieckiego projektu realizowanego przez Germany Trade and Invest (GTAI) rozpoczętego w 2011 roku. W tym projekcie Przemysł 4.0 jest definiowany jako zmiana paradygmatu, która jest aktualizowana przez postęp technologiczny, polegający na odwróceniu tradycyjnej logiki procesu produkcyjnego. Oznacza to, że nie tylko oczekuje się, że maszyny wykonają obróbkę, ale również produkt musi być komunikowany przez maszyny, aby poinformować go o tym, co dokładnie ma robić. W projekcie znanym jako wizja niemieckiej strategii 2020, końcowe wyniki tej komisji połączą zaawansowane technologie i międzynarodowe przywództwo. Programy takie jak "Smart Nation Program" w Singapurze, "Industrial Value Chain Initiative" w Japonii, "Made in China 2025" w Chinach i "Smart Manufacturing" w Stanach Zjednoczonych należą do podobnych kroków podejmowanych przez inne narody. Co więcej, projekt GTAI wspomina, że Przemysł 4.0 oznacza technologiczny wzrost od systemów wbudowanych do systemów cyber-fizycznych, która jest metodą łączącą wbudowane technologie produkcyjne i inteligentne procedury produkcyjne. Innymi słowy, Przemysł 4.0 to stan, w którym systemy produkcyjne i wytwarzane przez nie produkty są nie tylko połączone, ale Przemysł 4.0 przenosi fizyczne informacje na pole cyfrowe i przekazuje, analizuje i wykorzystuje tego rodzaju informacje, aby uzyskać bardziej inteligentne działania z powrotem do świata fizycznego, aby przeprowadzić transformację z fizycznego na cyfrowy i odwrotny. Przemysł 4.0 to mieszanka wielu innowacyjnych rozwiązań technologicznych takich jak technologie informacyjne (IT) i technologie komunikacyjne, systemy cyberfizyczne, komunikacja sieciowa, masowe przetwarzanie danych i przetwarzanie w chmurze, modelowanie, wirtualizacja, symulacja oraz ulepszony sprzęt do komunikacji i współpracy człowiek-komputer. Pojęcie Przemysłu 4.0 toruje drogę do różnych pozytywnych zmian w dzisiejszej produkcji, takich jak personalizacja masowa, elastyczna produkcja, zwiększona szybkość produkcji, więcej produktów wysokiej jakości, obniżony poziom błędów, zoptymalizowana wydajność, podejmowanie decyzji w oparciu o dane, większa bliskość z klientem, produkcja nowej wartości strategie i rozszerzone życie zawodowe. Ponadto istnieją kwestie związane z przekształceniami paradygmatu biznesowego, bezpieczeństwem, ochroną, kwestiami prawnymi i standaryzacją, a także szereg problemów związanych z planowaniem zasobów ludzkich. Poprzez maszynę parową i krosno Przemysł 1.0 zajmował się mechanizacją w XVIII i XIX wieku. Mechanizacja wyparła główny rodzaj energii, jaką była siła ludzka, i umożliwiła szybsze i bezpieczniejsze wykonywanie procesów. W międzyczasie tempo produkcji znacznie wzrosło później. Druga rewolucja miała miejsce pod koniec XIX wieku poprzez uprzemysłowienie elektryczności. W fabrykach wykorzystywano energię elektryczną; linie montażowe zostały wykorzystane do celów masowej produkcji. Wykorzystanie mikroelektroniki i programowalnych sterowników logicznych (PLC) nastąpiło w Industry 3.0 wraz z niezwykłym postępem w dziedzinie komputerów, robotyki, sterowników PLC, komputerowego sterowania numerycznego (CNC) i większej automatyzacji. Obecnie korzyści czerpie się z eksplozji czujnika oraz możliwości sieci i zdalnego dostępu do informacji z tych maszyn. Rysunek 9.1 przedstawia ogólny widok osi czasu rewolucji przemysłowych. Wraz z rozwojem technologii i pojawieniem się algorytmów uczenia maszynowego większość rutynowych prac wykonywała automatyka, komputery, roboty i maszyny. Przewiduje się, że tego typu prace są wyspecjalizowane w powtarzających się procesach i nie posiadają żadnych umiejętności na wysokim poziomie. Rejestracja robotów przemysłowych do rutynowych zadań będzie bardzo wydajna w Przemyśle 4.0. Robotyka, systemy cyber-fizyczne, automatyzacja i Internet rzeczy (IoT) stworzyły inteligentne fabryki. Po Przemyśle 3.0 (komputery i internet), Przemyśle 2.0 (produkcja masowa i elektryczność), Przemyśle 1.0 (mechanizacja i energetyka wodno-parowa), inteligentne fabryki to czwarta rewolucja przemysłowa. Producenci Przemysłu 4.0 próbują połączyć swoje maszyny z chmurą i stworzyć Industrial IoT. Oczekuje się, że przyszła generacja produkcji i fabryk będzie inteligentna w schemacie przemysłowym 4.0. Wszystkie obiekty, czyli maszyny, urządzenia, roboty, procesy i komputery muszą być połączone w grupy lub jeden po drugim. Masowe łączenie systemów tworzy bogatą społeczność zajmującą się ogromną analizą danych, przewidywalnymi pętlami i procesami autokorekty wśród wielu innych prawdopodobieństw. Inicjalizacja Przemysłu 4.0 jest już doceniona pomimo ogromnych przeobrażeń dla rozwoju w przyszłości. Przekształcenie surowca w produkt końcowy wydaje się bardzo trudne. Bardzo trudno jest nawigować drogą projektowania procesów o wysokich kosztach z najszybszym procesem dostawy w momencie dostosowywania linii produkcyjnej na podstawie życzeń konsumentów. Pomimo niezwykłego postępu i przełomu w produkcji i wytwarzaniu, przewiduje się więcej od Przemysłu 4.0. Reorganizacja struktury, metodologii i wydajności jest wymagana zgodnie z potencjałami Przemysłu 4.0 na każdym etapie, począwszy od rozwoju produktu i sprzedaży, aż po zaopatrzenie i dostawę. Wraz z wprowadzeniem nowatorskich, opracowanych technologii oczekuje się, że Przemysł 4.0 uzyska lepszą wydajność i produktywność w zakresie gromadzenia danych, analizy danych i korekcji procesów. W inteligentnych fabrykach produkcja stanie się cyfrowa, a sztuczna inteligencja będzie realizowana. Przemysł 4.0 wpływa na wszystkie etapy produkcji fabrycznej, takie jak projektowanie, produkcja, inżynieria, marketing, operacje, finanse i tak dalej. Podstawową troską jest oddzielny rozwój każdego etapu wraz z innymi bez pomysłu, jak dojść do porozumienia. Ten problem może rozwiązać scentralizowany inteligentny system sieciowy. Zero Down Time Solution to oparte na chmurze oprogramowanie produkowane przez General Motors (GM), głównego producenta amerykańskiego przemysłu motoryzacyjnego w zakresie kryteriów konserwacji. Za pomocą tej platformy analizowane są dane zebrane z robotów w fabrykach GM w celu przewidywania przyszłości. Od uruchomienia tej platformy w 2014 roku jest ona codziennie rozwijana i przynosi niewiarygodne rezultaty. Program przeanalizował dane zebrane w celu zapewnienia zwrotu z inwestycji (ROI) i uniknięcia przestojów. Każdy przestój może kosztować ponad 20 000$ za każdą minutę w branży motoryzacyjnej. ROI został wykorzystany przez oprogramowanie do przewidywania awarii, zanim ona nastąpi. Poprzednie tło było wykorzystywane przez mózg AI do szacowania i znajdowania konserwacji, podczas gdy jest to bardzo wymagane w produkcji. Chociaż nie jest to jeszcze możliwe po zebraniu wystarczających danych o działaniu robota, celem jest stworzenie systemu do samodiagnozy zgodnie z niewielkimi zmianami w procedurach dostosowanych w celu zwiększenia całkowitej wydajności
Inteligentne fabryki
Gromadzenie i analizowanie danych jest jednym z głównych kryteriów Przemysłu 4.0. Informacje są zbierane ze wszystkich stacji przez AI. Następnie informacje są wydobywane, porządkowane i analizowane w celu uzyskania wyników. Do przetwarzania i podejmowania decyzji o analizie ogromnych danych potrzebna jest wysoce zaawansowana technika analityczna. Uczenie maszynowe jest możliwe dzięki masowej analizie danych. Oznacza to umiejętność poznania wzorców danych i wykorzystania przeszłych doświadczeń w celu uzyskania precyzyjnych prognoz. Zamiast pisać miliony wierszy kodu dla przewidywalnych drzew decyzyjnych, uczenie maszynowe umożliwia samouczenie się algorytmu, aby indywidualnie radzić sobie z nadchodzącymi problemami lub dobrze obsługiwać obiekty . Technologia identyfikacji radiowej należy do szeroko stosowanych nowatorskich technologii w przemyśle produkcyjnym w celu cyfryzacji. Technologia ta została wykorzystana w różnych czujnikach, siłownikach, komunikatorach, nadajnikach, tagach i kodach kreskowych. Dane zebrane z takich urządzeń informują nas o stanach magazynowych, aby zapewnić sprawną realizację operacji lub czas naprawy sprzętu. Aktualny nadzór i optymalizację czasu można przeprowadzić, łącząc wszystkie urządzenia i maszyny za pośrednictwem centralnego systemu w inteligentnej fabryce. Wszystko można było połączyć w inteligentnej fabryce, a maszyny, zasoby i procedury można by zautomatyzować i połączyć. Ten rodzaj produkcji mógłby być bardziej wydajny, przewidywalny i umożliwiałby wytwarzanie towarów wyższej jakości przy krótszych przestojach sprzętu niż to, o czym wiemy obecnie. Wdrożenie koncepcji komunikacji jeden po drugim nie jest przewidziane w Industry 4.0, natomiast wymagane jest okablowanie wraz z maszynami. Wiadomo, że jest to niezwykła szansa dla producentów. Powinna wziąć pod uwagę możliwości automatyzacji i przeprowadzić badania nad technologią niezbędną do połączenia automatyzacji w sprawne działanie. Bardzo prostym przykładem jest samodzielny robot mobilny przechodzący obok otwieranych drzwi. W przeciwnym razie takie drzwi byłyby obsługiwane przez ludzi podczas transportu elementów, podczas gdy nawet już wykonane produkty muszą być łączone, aby umożliwić robotom komunikowanie się z nimi wraz z automatycznym otwieraniem i zamykaniem podczas przenoszenia produktów. Z robotami można również zintegrować urządzenia bezpieczeństwa, takie jak alarm przeciwpożarowy lub sytuacja awaryjna. Jakie są oczekiwania wobec inteligentnych fabryk i jakie są główne komponenty Przemysłu 4.0? Przemysł 4.0 może pozytywnie wpływać na zaspokajanie indywidualnych potrzeb klientów, elastyczność produkcji, optymalizację podejmowania decyzji, produktywność i wydajność zasobów, możliwości tworzenia wartości dzięki nowatorskim usługom, zmiany demograficzne w miejscu pracy, siłę roboczą ludzi, równowagę między życiem zawodowym a prywatnym oraz konkurencyjność gospodarka z wysokimi zarobkami. Podkreślono tutaj cztery główne elementy, które, jak się przewiduje, mogą spowodować wielką różnicę. Są to
• wydajność i produktywność,
• bezpieczeństwo i ochrona,
• elastyczność i
• łączność.
Wydajność i produktywność
Zwiększenie wydajności inteligentnych maszyn jest jednym z głównych celów w branży. Różne rodzaje czujników są wdrażane przez inteligentne maszyny w celu nadzorowania siebie, aby uniknąć wszelkiego rodzaju awarii. Dzięki gromadzeniu danych z inteligentnych maszyn i sieci możemy mieć bardziej niezawodne i elastyczne linie automatyzacji/montażu, które zapewniają bardziej wydajną wydajność. Inteligentne maszyny są używane na pierwszej linii produkcyjnej w hali produkcyjnej, a wbudowane inteligentne maszyny są bardzo potrzebne w przypadku czujników i siłowników maszyny. Przy takim poziomie wyposażenia możliwe byłoby uniknięcie lub zminimalizowanie wszelkich uszkodzeń, konserwacji zapobiegawczej dotyczącej maszyn i ich przestojów. To dodaje wartości do systemu. Produkcja będzie szybsza dzięki zaawansowanej cyfryzacji i symulacji/wirtualizacji produktu. Prawdopodobne jest wykrycie wartości każdej transformacji projektowej i wpływu szybkości produkcji. Przejrzystość zostanie zapewniona w całej produkcji poprzez zbieranie, wstępne przetwarzanie i analizowanie wszystkich dostępnych danych z hali produkcyjnej. Dopuszcza się identyfikację wąskich gardeł i potencjalnych miejsc poprawy. Na przykład, w większości przypadków cechy projektowe są już określone przez klientów. W smartie wymagany jest odpowiedni poziom inteligencji maszyny do szybkiej analizy zebranych danych. Po przekroczeniu ustalonych kryteriów w przypadku danych z czujnikami, bardziej wydajne byłoby zarządzanie całym systemem i łatwiejsza obsługa systemu.
Bezpieczeństwo i ochrona
Należy wziąć pod uwagę poprawę wydajności lub skuteczności, bezpieczeństwo i ochronę. Czujniki bezpieczeństwa, takie jak alarmy, skanery laserowe, detektory ręczne i kamery dodane do elementów automatyki, w tym sterowników PLC, napędów, komputerów i innych, muszą być brane pod uwagę w celu zwiększenia bezpieczeństwa operatorów. Wykorzystanie tych możliwości jest możliwe dzięki inteligentnym fabrykom, a bezpieczeństwo danych jest głównym wyzwaniem w gromadzeniu danych. W dzisiejszych czasach bezpieczeństwo danych jest głównym czynnikiem hamującym przyjmowanie przez użytkowników końcowych nowych technologii sieciowych i procedur pracy. Osiąganie korzyści produkcyjnych poprzez łączenie w sieć komponentów i maszyn niesie ze sobą ryzyko. Należy wziąć pod uwagę bezpieczeństwo na różnych poziomach, zwłaszcza w przypadku IoT (lub IIoT) i rosnących poziomów łączności. Bezpieczeństwo musi być zapewnione na różnych poziomach, podczas gdy sprzęt, oprogramowanie i usługi muszą być włączone. Producenci maszyn (i dostawcy komponentów automatyki) muszą upewnić się, że użytkownicy są świadomi luk w zabezpieczeniach. Infrastrukturą sieciową można zarządzać w celu zmniejszenia ryzyka naruszenia. Cyberbezpieczeństwo to jeden z problemów, który niepokoi producentów: należy mieć gwarancję, że nie zostaną zinfiltrowani lub ich fabryki nie zostaną przejęte. Ponadto musimy upewnić się, że sprzęt produkcyjny nie zagraża zasobom ludzkim ani środowisku pracy. Należy zadbać o to, aby pracownicy byli stale szkoleni w kwestiach bezpieczeństwa.
Elastyczność
Oczekuje się, że inteligentne maszyny będą zgodne z obecnymi instalacjami lub maszynami wielu producentów oryginalnego sprzętu (OEM); użytkownicy produktów żądają produktów, które można zainstalować w krótkim czasie. Obecnie monolityczna lub pojedyncza konstrukcja nie jest dopuszczalna przez cykl życia maszyn. Wykorzystywane są wzorce sprawdzonego projektu od prostych funkcji oprogramowania do całkowicie funkcjonalnych jednostek, które zapewniają opis mechaniki, elektryki, ruchu i interfejsów, cech i zachowań. Modułowość jest czynnikiem umożliwiającym, w którym model ponownego wykorzystania oprogramowania i sprzętu w innej sytuacji wymaga nowego poziomu myślenia. Idea precyzyjnych i sztywnych interfejsów z dobrze opisanym zachowaniem do zbadania wywodzi się ze świata IT. Jego przestrzeń znajduje się w automatyce z pewną adaptacją. Dzięki utworzeniu inteligentnych fabryk, bardziej elastyczna produkcja jest możliwa dzięki inteligentnym maszynom, które torują drogę do wytwarzania szerokiej gamy produktów za pomocą danego sprzętu produkcyjnego, szybszych procedur produkcyjnych przy jednoczesnym reagowaniu na zmiany i tymczasowe potrzeby [6] . W ten sposób firmy zaczynają produkować dla większej liczby klientów i zmieniają się zgodnie z chwilowymi wzrostami i spadkami rynku. Na przykład, w przypadku niskiego zapotrzebowania na dany produkt, linię produkcyjną można łatwo przekształcić w inny produkt o większej wydajności i szybszym niż oczekiwanym dostarczaniu komponentów do klientów. W ten sposób klienci będą bardziej ufać producentom.
Łączność
Szersze (oparte na Ethernet) sieci zostaną bezpośrednio zintegrowane z inteligentnymi maszynami. Dzięki temu możliwe jest udostępnianie danych i planowanie produkcji. To więcej niż możliwości samodzielnych maszyn i automatyzacji. Technologia informatyczna i operacyjna jest zintegrowana z inteligentnymi maszynami, co umożliwia dostęp do danych produkcyjnych. Ten zestaw danych może być wykorzystywany w wielu środowiskach zarządzania. Pomysł wykorzystania urządzeń mobilnych w pracy jest mile widziany przez operatorów maszyn i inżynierów hal produkcyjnych. Monitorowanie i zarządzanie wydajnością personelu nie zależy już od bliskości maszyny. Problemy mogą być diagnozowane przez inżynierów maszynowych z dużej odległości, a tym samym mogą być oferowane wskazówki, aby przyspieszyć przeprowadzenie rozwiązania. W ten sposób zminimalizowane są przestoje i straty wynikające z awarii komponentów. Wyśmienity hamburger może być łatwo przygotowany przez wielozadaniowy robot (Momentum Machines) w ciągu 10 s, zastępując
cały zespół McDonalds. Pionier technologii sztucznej inteligencji Google zdołał zdobyć patent na rozpoczęcie produkcji robotów robotniczych z własnymi tożsamościami. Coraz częściej inteligentne maszyny rozpoczęły swoją drogę do pracy i stają się bardziej skomplikowane i rozwinięte niż poprzednie pokolenia. Nie trzeba dodawać, że w inteligentnych fabrykach na pewnym etapie wymagane jest monitorowanie i dostosowywanie przez ludzi. Nadzorcy mogą zarządzać działaniami robotów za pomocą technologii podręcznych, takich jak smartfony i tablety, oraz wprowadzać zmiany za pomocą powszechnie dostępnej, niedrogiej i specjalistycznej technologii. Zastosowanie inteligentnej technologii przyspiesza pracę kierowników produkcji w warunkach szybkiego tempa produkcji, w których kiedyś byli przywiązani do komputera lub stacjonarnego systemu danych.
Internet przedmiotów
Niezależne strategie produkcyjne umożliwione przez IoT to kluczowa cecha Przemysłu 4.0. W tym stanie każda maszyna, obiekt, urządzenie i komputer muszą być połączone i mogą się komunikować. Nadal możemy znaleźć ślady IoT w naszym świecie, a liczba urządzeń podłączonych cyfrowo rośnie coraz bardziej. Bardzo mała liczba takich urządzeń kontaktuje się z nami, podczas gdy oczekuje się, że będzie ich więcej. Niezależne roboty, które są powszechne we wszystkich branżach, są prostym przykładem dla produkcji przemysłowej i inteligentnych fabryk. Wcześniej procedura automatyzacji i programowanie były zarządzane przez sterowniki PLC. PLC zachowują się jak szefowie automatyki przemysłowej, ale ich wadą jest to, że prawdopodobnie zostaną okablowane. Do ich obsługi i pisania drabin logicznych potrzebni są bardzo wykwalifikowani programiści. Biorąc pod uwagę zawiłość i surowość, wykonanie i przekształcenie tych rozwiązań dużo kosztuje. Roboty muszą być połączone w celu komunikacji w inteligentnych fabrykach Przemysłu 4.0. Dzięki połączeniu z centralnym serwerem, bazą danych lub sterownikiem PLC koordynacja i automatyzacja działań robotów byłaby prawdopodobna w większym stopniu niż kiedykolwiek. Zadania można inteligentnie wykonać w uporządkowany sposób przy najmniejszym udziale człowieka. Autonomiczne roboty mobilne (AMR) mogą transportować materiały po hali produkcyjnej, jednocześnie omijając bariery, współpracując z kolegami z floty i próbując w dowolnym momencie dowiedzieć się, gdzie wymagany jest odbiór i odbiór. Pracownicy montażu i produkcji mogą skoncentrować się na rzeczywistym montażu i produkcji, biorąc pod uwagę odbiór przez AMR sygnałów pracy z systemów produkcyjnych w czasie rzeczywistym i systemu wdrażania produkcji. Na przykład obecne systemy PLC można łączyć z robotami za pomocą zestawu narzędzi integracyjnych Logic OS firmy Aethon. Komunikacja dowodzenia i kontroli między urządzeniami automatyki, narzędziami i czujnikami jest ułatwiona przez Logic OS, podczas gdy jest nadzorowana przez sterowniki PLC i niezależne roboty mobilne. Do wstępnej analizy surowych danych i raportowania zgodnie z wymaganiami należy wziąć pod uwagę kilka warstw i filtrów, aby zapobiec łączeniu producentów z ogromną ilością otrzymanych danych. Dane mogą być raczej rozumiane i cenione przez firmy w bardzo silny sposób. Roboty są znane jako wybitny fizyczny i poznawczy partner producentów w procesie tworzenia cyfrowej fabryki. Takie maszyny są niezbędne ze względu na ich zdolność do wykonywania zadań, gromadzenia i analizowania wydajności danych, jakości, wiarygodności, a także ich kosztów i innych udogodnień w procedurze z wglądem dostępnym do zrozumienia i wykonania.
Sztuczna inteligencja
Sztuczna inteligencja została wdrożona w branży produkcyjnej, czego liczne przykłady wskazują, że technologia ta jest obecnie wykorzystywana w całym sektorze. Firmy technologiczne z najwyższej półki, takie jak Tesla, Intel i Microsoft, są pionierami na arenie międzynarodowej, inwestując, wytwarzając lub stosując aplikacje. Sieci neuronowe są od lat wykorzystywane przez firmę Siemens do nadzorowania wydajności swoich hut. To wcześniejsze doświadczenie jest wykorzystywane do zrewolucjonizowania produkcji sektora AI z wykorzystaniem AI w nadzorowaniu zmiennych (np. temperatury) na turbinach gazowych koordynujących pracę maszyn w celu uzyskania wysokiej wydajności bez nieoczekiwanych produktów ubocznych. Nadrzędne systemy są również wykorzystywane do znajdowania możliwych problemów i ich rozwiązań, jeszcze zanim zostaną rozpoznane przez operatora. Ze względu na zdolność sztucznej inteligencji do wykrywania zużycia maszyn, zanim wymknie się ono spod kontroli, zastosowanie tej technologii przyniosło pozytywne rezultaty dla inteligentnych fabryk, takie jak obniżenie kosztów utrzymania. Wszystko wskazuje na to, że uważa się, że globalne obroty na rynku "inteligentnej produkcji" osiągną prognozowane 320 miliardów dolarów do roku 2020. Wiadomo, że uczenie maszynowe jest jednym z powszechnych zastosowań sztucznej inteligencji w produkcji, podczas gdy technika ta opiera się głównie na dokonywać prognoz ze strony systemów predykcyjnego utrzymania ruchu. Ta technika ma wiele zalet; jednym z nich jest znaczna redukcja kosztów i wyeliminowanie konieczności planowanych przestojów w wielu przypadkach. Po zapobieżeniu awarii za pomocą algorytmu uczenia maszynowego, nie mogą wystąpić żadne przerwy w działaniu systemu. Gdy wymagana jest naprawa, należy skoncentrować się na przekazywaniu informacji o tym, jakie elementy należy sprawdzić, naprawić i wymienić, określając jednocześnie, jakich narzędzi użyć i jakich metod zastosować. Sztuczna inteligencja może być również wykorzystywana przez producentów w fazie projektowania. Algorytm sztucznej inteligencji, znany również jako oprogramowanie do projektowania generatywnego, może być używany przez projektantów i inżynierów do eksploracji prawdopodobnych konfiguracji rozwiązania za pomocą dokładnie opisanego briefu projektowego jako danych wejściowych. W briefie można uwzględnić ograniczenia i definicje rodzajów materiałów, strategii produkcji, ograniczeń czasowych i budżetowych. Uczenie maszynowe może służyć do testowania zestawu rozwiązań podanych przez algorytm. Dodatkowe informacje są podane w fazie testowania na temat wydajności i nieefektywności pomysłów i decyzji projektowych. W ten sposób można aktualizować więcej opracowań, aż do osiągnięcia optymalnego rozwiązania. W sektorze produkcyjnym należy zwrócić uwagę na dostęp do danych. Niewątpliwie notoryczne koszty systemów AI mogłyby wpłynąć na przychody małych i średnich przedsiębiorstw (MŚP), czyli w konkurencji finansowej z międzynarodowymi korporacjami, gdyby zostały one bardziej wzmocnione przez AI. Oprócz odniesień do terminatorów, kolejnym ważnym problemem w technologii AI jest bezpieczeństwo. "Trzy prawa robotyki" Asimova są obecnie zaniedbywane, a kwestie odpowiedzialności nie są rozwiązywane, gdy awaria maszyny może spowodować obrażenia pracownika. Sektory biznesu muszą być przygotowane na prawdopodobne przekształcenia kadrowe, oprócz bezpośredniej regulacji. Przewiduje się, że sztuczna inteligencja będzie "kosztować miejsca pracy"; jednak faktem jest, że stworzy tyle miejsc pracy, ile zostało utraconych. Mianowicie nowe obiekty będą zajmować się obecnym personelem wymagającym oceny wpływu działalności na każdy biznes. Przykładowo algorytmy sztucznej inteligencji zostały wykorzystane w optymalizacji łańcucha dostaw operacji produkcyjnych w celu wspomagania ich w reagowaniu i przewidywaniu zmian rynkowych. Wzorce popytu sklasyfikowane według daty, lokalizacji, atrybutów społeczno-ekonomicznych, zachowań makroekonomicznych, statusu politycznego, wzorców pogodowych i innych elementów muszą zostać uwzględnione przez algorytm w celu oszacowania zapotrzebowania rynku. Te niezwykłe informacje mogą być wykorzystane przez producentów w optymalizacji kontroli zapasów, personelu, zużycia energii i surowców przy lepszych decyzjach finansowych dotyczących metodologii firmy. Biorąc pod uwagę złożoność wykorzystania AI w automatyce przemysłowej, producenci są zobowiązani do współpracy ze specjalistami w zakresie niestandardowych rozwiązań. Budowa wymaganej technologii kosztuje dużo, a większość producentów nie posiada we własnym zakresie niezbędnych umiejętności i wiedzy. System Industry 4.0 składa się z wielu komponentów/etapów, które muszą zostać ponownie skonfigurowane, aby spełnić wymagania producentów:
• Zbieranie danych historycznych
• Przechwytywanie danych na żywo za pomocą czujników
• Agregacja danych
• Łączność za pośrednictwem protokołów komunikacyjnych, urządzeń routingu i bram
• Integracja ze sterownikami PLC
• Pulpity nawigacyjne do monitorowania i analizy
• Aplikacje AI: uczenie maszynowe i inne techniki
Producenci będą próbowali współpracować z ekspertami, którzy realizują swoje cele i potrafią stworzyć jasno opisaną mapę drogową z szybkim procesem rozwoju łączącym integrację AI z powiązanymi kluczowymi wskaźnikami wydajności (KPI).
Inteligentne materiały i druk 3D
Dzięki drukowi 3D, który jest procedurą wytwarzania przyrostowego, obiekty są wytwarzane warstwa po warstwie. Istnieją różne rodzaje druku 3D i niektóre z nich wykorzystują materiały termoplastyczne, podczas gdy inne wykorzystują materiały polimerowe. Druk 3D, który wykorzystuje nowo powstałe inteligentne materiały, stwarza nowe możliwości i umożliwia dostęp do różnych branż. Wykorzystanie inteligentnych materiałów, które zapewniają przekształcenie lub przeprojektowanie obok druku 3D, jest bardzo wydajne i niedrogie. Biorąc pod uwagę ich produktywność i wydajność, nowe inteligentne materiały i opracowane strategie produkcyjne zastępują tradycyjne rodzaje produkcji. Naukowcy z Self-Assembly Lab w Massachusetts Institute of Technology (MIT) twierdzą, że "samoskładane" rury wodne prawdopodobnie pewnego dnia zostaną wyprodukowane. Byłoby to możliwe bez użycia czujników, siłowników, oprogramowania lub mikroprocesorów, polegając jedynie na projektowaniu właściwości fizycznych materiałów. Ponadto dr Tibbits nadzorował grupę badaczy z MIT, którzy rozpoczęli drukowanie 4D, które pomogło w rozwoju inteligentnych materiałów. Druk 4D to rozwinięta forma 3D, w której ostatecznym wymiarem jest "czas". W obliczu bodźca (ciepło, światło ultrafioletowe lub woda) na wydruku wyświetlany jest czas, a wydruk jest regulowany, dzięki czemu jest dynamiczną strukturą o zgodnych cechach i funkcjonalności . Dzięki temu rozwojowi produkcja cyfrowa jest szerzej stosowana; jednak do tego celu wymagana jest wiedza i umiejętności multidyscyplinarne (np. matematyka, mechatronika, inżynieria mechaniczna i chemiczna). Druk 3D głęboko wpłynął na dziedzinę biomedyczną. Adaptację drukarek 3D do programów edukacyjnych i szkoleniowych zaobserwowano w wielu uczelniach i ośrodkach medycznych. Druk atramentowy 3D został wykorzystany do opracowywania i tworzenia narzędzi do szkolenia i planowania chirurgicznego w Centrum Innowacji z Przewodem Obrazowym i Interwencji Terapeutycznej Szpitala dla Chorych Dzieci w Toronto, Kanada. Pokazano i zbadano wiele nowatorskich inteligentnych materiałów inżynieryjnych: inteligentne zawory do sterowania przepływem na gorąco i na zimno lub kwaśnym i zasadowym , adaptacyjne rury , czujniki i miękkie roboty. Narzędzia open source, w których połączony jest sprzęt i oprogramowanie, zostały stworzone z myślą o projektowaniu produktów w oparciu o platformę. Ta procedura została ostatnio zastosowana przez naukowców z Uniwersytetu Harvarda w Cambridge w stanie Massachusetts, aby wydrukować kwiat, który automatycznie rozwija się w kontakcie z wodą. W ślad za tym rozwojem zastosowano hydrożel, w którym mamy mieszankę włókien celulozowych, maleńkich cząstek gliny i plastikowych monomerów. Oprócz wody istnieją inne wyzwalacze, które zmieniają kształt materiałów 4D: materiały o odpowiedniej konstrukcji mogą być również aktywowane przez ciepło, ruch, światło ultrafioletowe i każdy inny rodzaj energii. Intrygujące są jednocześnie materiały "samonaprawiające się" - na przykład tworzywa sztuczne - które mają zdolność samonaprawy. Połączenie maleńkich nanorurek wypełnionych nieutwardzonym polimerem w plastik to jeden ze sposobów na zapewnienie tego wpływu. W przypadku uszkodzenia plastiku, gdy rurki są szeroko otwarte, płynne polimery są uwalniane do naprawy materiału. W unikalnym procesie naukowcy z Uniwersytetu w Bristolu wykorzystali tradycyjne drukowanie 3D wraz z falami ultradźwiękowymi w celu ustawienia nanorurek we właściwej pozycji. W płynnym plastiku wzorzyste pola siłowe wewnątrz nanorurek zostały utworzone przez fale. Ta procedura ma wpływ nie tylko na nanorurki, ale także na włókna węglowe. Konwencjonalne materiały kompozytowe, wcześniej wytwarzane ręcznie, można wytwarzać w procesie drukowania 3D. To z kolei jest prawdziwym sukcesem. Ze względu na swoje unikalne właściwości fizyczne kompozyty termoutwardzalne można porównać z metalami lub tworzywami termoplastycznymi. Ze względu na stabilność materiałów termoutwardzalnych w warunkach wysokiej temperatury mogą być z powodzeniem stosowane do celów przemysłowych. Popularność żywic termoutwardzalnych wynika z przetwarzania pod niskimi ciśnieniami i lepkościami. Dopuszcza się zatem dogodną impregnację włókien wzmacniających, takich jak włókno szklane, włókno węglowe lub Kevlar. Podczas procesu utwardzania w tworzywach termoutwardzalnych można znaleźć polimery, które można usieciować, tworząc nieodwracalne wiązanie chemiczne. Po zastosowaniu ciepła problem przetapiania produktu jest usuwany poprzez sieciowanie. Ta funkcja zapewnia materiały termoutwardzalne do zastosowań zaawansowanych technologicznie, takich jak elektronika i urządzenia. Tworzywa termoutwardzalne znacznie poprawiają właściwości fizyczne materiałów, a jednocześnie poprawiają odporność chemiczną, termiczną i integralność strukturalną. Ze względu na odporność tworzyw termoutwardzalnych na odkształcenia stosuje się je głównie do wyrobów zgrzewanych. Materiały termoutwardzalne mogą być wykorzystywane w grubościach i cienkich ściankach. Mają doskonały estetyczny wygląd przy wysokim poziomie stabilności wymiarowej. Warto wspomnieć, że tworzywa termoutwardzalne nie mogą być poddawane recyklingowi, powtórnie formowane ani przerabiane, co sprawia, że ich wykończenie powierzchni jest coraz większym wyzwaniem.
Rewolucja integracyjna: budowanie zaufania za pomocą technologii
Sztuczna inteligencja, uczenie maszynowe, robotyka i blockchain to produkty Czwartej Rewolucji Przemysłowej. Chociaż trudno powiedzieć, co ma szerszy wpływ na świat pracy i obecny stan społeczeństwa, każdy z nich w istotny sposób przyczynia się do zmiany sposobu, w jaki postrzegamy i wchodzimy w interakcję z technologią. Blockchain w tym sensie można scharakteryzować jako mechanizm budowania zaufania, który ułatwił sposób, w jaki przeprowadzamy transakcje, przynosząc większą niezawodność, przejrzystość i zaufanie do systemu. Technologia, która kiedyś stanowiła podstawę bitcoinów i walut cyfrowych, wykroczyła poza swoje kompetencje, by tworzyć nowe pola. Co ważniejsze, bardziej niż rozwinięte gospodarki, blockchain ma przynieść korzyści krajom rozwijającym się, pomagając ograniczyć przypadki korupcji i wycieków dzięki efektywnemu systemowi kontroli i równowagi. W rozdziale skupimy się na wpływie blockchain na różne obszary, aby zbudować to, co nazywamy gospodarkami zaufania i jego ograniczeniami. Skupiamy się również na naturze technologii i tym, jak marginalizowane sekcje mogą zostać pominięte, jeśli rządy nie podejmą inicjatywy, aby edukować ich w zakresie nowych technologii i systemów.
Wstęp
Początek trzeciej rewolucji przemysłowej charakteryzował się wprowadzeniem komputerów, z drugiej strony, opierał się na szeregu technologii, które razem opierają się na rewolucji komputerowej. Profesor Klaus Schwab, założyciel i przewodniczący wykonawczy Światowego Forum Ekonomicznego, zauważa, że "Poprzednie rewolucje przemysłowe wyzwoliły ludzkość spod władzy zwierząt, umożliwiły masową produkcję i udostępniły możliwości cyfrowe miliardom ludzi. Ta czwarta rewolucja przemysłowa jest jednak zasadniczo inna. Charakteryzuje się szeregiem nowych technologii, które łączą świat fizyczny, cyfrowy i biologiczny, wpływając na wszystkie dyscypliny, gospodarki i branże, a nawet podważając idee dotyczące tego, co to znaczy być człowiekiem". Blockchain, zdecentralizowany system księgi głównej, to technologia, która napędza bitcoin, ale z biegiem lat pojawił się o wiele więcej przypadków użycia. Będąc systemem księgowym, tworzy niezmienny zapis transakcji, które są nie tylko szybkie, ale także bezpieczne. Zatem blockchain można scharakteryzować jako mechanizm budowania zaufania, który ułatwił sposób, w jaki przeprowadzamy transakcje, przynosząc większą niezawodność, przejrzystość i zaufanie do systemu. W rzeczywistości blockchain stanowi podstawę do otwierania nowych sektorów w zakresie produkcji, organizacji, usług i finansów. Ponieważ coraz więcej narodów, firm i osób korzysta z technologii, coraz ważniejsze staje się zniwelowanie deficytu zaufania. Blockchain to mechanizm działający w zdecentralizowanym systemie, który buduje zaufanie między kontrahentami. Ma to znaczenie nie tylko dla gospodarek rozwiniętych, ale ma również zastosowanie w krajach rozwijających się, które borykają się z przypadkami wycieków z systemów dystrybucji, nieefektywnych platform i korupcji. Chociaż blockchain mógł pobudzić wyobraźnię wielu, jego zastosowania były ograniczone do naukowców i inżynierów. Większość badań nad blockchainem dotyczyła kwestii ulepszania technologii lub skupiania się na najdrobniejszych szczegółach jej funkcjonowania. To wystarczy, ale brak informacji w dziedzinie nauk społecznych hamuje dalszy rozwój i wiedzę. Co więcej, brak dokumentów skupiających się na wpływie blockchain na społeczeństwo oraz tych, które mogą stanowić końcowego konsumenta technologii, prowadzi do większej niejasności. Ten rozdział ma na celu wypełnienie luki w przedsiębiorstwach blockchain. Na tym tle w rozdziale omówimy ewolucję technologii blockchain, nowe inicjatywy, które mogą przekształcać systemy za pomocą blockchain, oraz jej wpływ na wcześniej istniejące struktury w społeczeństwie. Rozdział podzielony jest na pięć części, z których druga opisuje szczegółowo metodologię i cele badania. Trzecia sekcja podkreśla, czym jest blockchain, pochodzenie blockchain i jego ewolucja poza walutami cyfrowymi. Podczas gdy czwarty wyjaśnia, w jaki sposób można zbudować gospodarkę zaufania za pomocą tej technologii, w tym jej wpływ na kraje rozwinięte i rozwijające się, ze szczególnym uwzględnieniem Indii. Dla jasności, sekcja ta dotyczy wykorzystania technologii w procesach produkcyjnych, organizacji, usługach, zarządzaniu finansami oraz kwestii jej przenikania do najniższej części społeczeństwa. Piąty wskazuje na przeszkody w efektywnym wykorzystaniu blockchain i na to, jak różne instytucje mogą przezwyciężyć te ograniczenia. Część szósta kończy dyskusję wskazującą na stronniczość selekcji, która pojawia się przy nadużywaniu technologii i jak marginalizowani są wykluczani z jej korzyści z powodu źle poinformowanych decyzji i nieprzygotowania rządu do zapoznania ich z nowymi środkami.
Cele i metodologia
Blockchain, który zaczynał jako system księgi głównej dla bitcoinów, przeszedł długą drogę pod względem jego zastosowania. Rozproszony system księgi rachunkowej, który tworzy bloki danych, do których praktycznie nie można się włamać, działał jako bezpieczny i wydajny system do pracy z fragmentami danych i przechowywania dużych zbiorów danych. W ten sposób blockchain podąża za serią innowacji, które pojawiły się w różnych dziedzinach. Chociaż w łańcuchu bloków dostępnych jest niewiele danych, dostępnych jest wystarczająco dużo popularnych artykułów, aby zaprezentować wykorzystanie technologii. Co ważne, wraz z pojawieniem się komputerów kwantowych pojawiło się wiele czasopism szczegółowo opisujących nowe technologie i przypadki użycia w blockchain. Będąc systemem opartym na kryptowalutach, jest całkiem zrozumiałe, że blockchain śledził większość swoich zmian w świecie finansów. Zastosowaliśmy podobną metodę, aby rozszyfrować wpływ blockchain na sektory, zaczynając od szczegółowego przeglądu rozwoju blockchain, a następnie jego przypadków użycia w finansach, biznesie i zarządzaniu. Ponieważ gospodarka współdzielenia stała się modnym hasłem dla rozwoju, cały nacisk w tym ćwiczeniu opiera się na tym, jak blockchain może poprawić te gospodarki współdzielenia, a dokładniej, gdy konsumenci prowadzą interesy przez Internet, istnieje potrzeba nowych mechanizmów zaufania. W związku z tym, szczegółowo omawiając popularne artykuły, czasopisma i artykuły naukowe, w tym rozdziale próbujemy powiązać nowe przypadki użycia blockchain z pojęciem gospodarki zaufania, jednocześnie szczegółowo omawiając wady systemu.
Ewolucja łańcucha bloków
Historia blockchain jest powiązana z historią walut cyfrowych. Chociaż bitcoiny zyskały nieco międzynarodową sławę z powodu złej reputacji, z drugiej strony blockchain przyciągnął uwagę wielu. System opracowany w celu wspomagania cyfrowej waluty nie tylko pomógł w rewolucji cyfrowej waluty, ale także doprowadził do opracowania nowego systemu finansowego. Aby zrozumieć, dlaczego blockchain był tak ważny, kluczowe byłoby odkrycie historii cyfrowej waluty i blockchainu
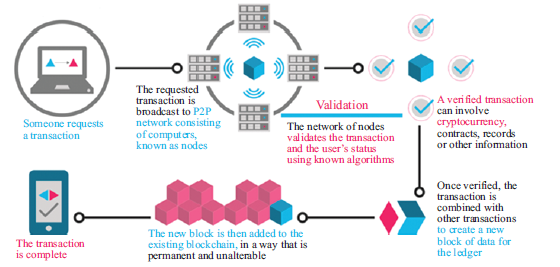
Cały system Internetu opiera się na mechanizmach zabezpieczających, zapewniających bezpieczeństwo Twoich informacji. Tak więc, jeśli chodzi o opracowanie cyfrowej waluty, którą można by handlować na całym świecie, byłoby zaskakujące, gdyby twórcy nie poszli w kierunku bezpieczeństwa. Ergo, twórcy musieli wymyślić sposób, aby zapewnić systemowi bezpieczeństwo i prywatność, jednocześnie umożliwiając transakcje na skalę globalną. Co ważne, musieli to zrobić w taki sposób, aby systemu nie dało się sfałszować, a żadna nieczysta gra nie doprowadziła do powstania bańki i wyciągnięcia milionów. Poza tym była to zbyt duża władza z jedną agencją lub osobą, więc system musiał być zdecentralizowany. Rewolucja bitcoin doprowadziła również do rewolucji blockchain, przy czym ta ostatnia wspierała infrastrukturę i architekturę tego ogólnoświatowego zjawiska. Cały system, często pozbawiony skrupułów, jak na ironię pracował nad zaufaniem, które było zapewnione przez przejrzystość. Blockchain zapewnił utworzenie zdecentralizowanej księgi, która była widoczna dla kontrahentów w celu weryfikacji, z dodatkowym zabezpieczeniem każdego bloku oddzielonego od siebie. Gdybyśmy mieli to łatwo wyjaśnić, pomyśl o arkuszu Excela, który jest chroniony lub zablokowany, aby nie każdy mógł go edytować, ale niewielu, którzy mają dostęp do arkusza, może wprowadzać zmiany. Teraz, gdybyśmy mieli napisać jakąś informację na pierwszej karcie tego arkusza, ta informacja musiałaby zostać zweryfikowana przez nielicznych, którzy są częścią tego arkusza. Po zweryfikowaniu, że informacji nie można usunąć lub usunąć, wszelkie uzupełnienia lub zmiany zostaną odzwierciedlone i będą musiały zostać zatwierdzone przez wszystkich. Chociaż arkusz kalkulacyjny byłby widoczny dla wszystkich jako księga, jego zawartość pozostanie między zaangażowanymi stronami, chyba że zgodzą się udostępnić ją innym. Podobnie kolejna zakładka tego arkusza byłaby kolejnym blokiem transakcji, z tymi samymi regułami, co poprzednia. Tak więc, wdrażając ten system, twórcy bitcoina nie tylko zapewnili przejrzystość, ale także stworzyli pierwsze wskazówki dotyczące zdecentralizowanego systemu, w którym transakcje mogły odbywać się płynnie i bez wielu problemów. Ponadto dzięki łatwemu przepływowi transakcji i bezpieczeństwu płatności międzynarodowe stały się znacznie bezpieczniejsze. Jakby nawet włamać się do systemu, mogliby zhakować tylko jeden blok danych, podczas gdy inne pozostają praktycznie poza zasięgiem hakerów. Rewolucja blockchain nie ograniczała się tylko do bitcoina; doprowadziło to również do rozwoju systemu walut cyfrowych poza sferą bitcoinów. W ciągu ostatnich kilku lat pojawiło się wiele naśladowców i nowych pomysłów obracających bitcoin. Nawet banki zaczęły polegać na systemie, aby stworzyć sieć płynnych transakcji. Jednym z punktów do rozważenia mogą być wysiłki prawie wszystkich głównych światowych banków w celu stworzenia własnych systemów walutowych, na wzór bitcoina. I ta rewolucja została wywołana przez łatwość transakcji i skrócenie czasu transakcji dla klientów i banków. Jeśli ktoś miałby przejrzeć system transakcji międzynarodowych i międzynarodowych rozliczeń płatniczych, odkryłby, że był on wypełniony zbyt wieloma kontrolami wstecznymi, aby zapobiec przypadkom oszukańczych transakcji. Załóżmy, że transakcja będzie miała miejsce z kraju ojczystego do kraju obcego. Teraz bank w kraju ojczystym przetworzy transakcję tutaj, która następnie trafi do izby rozliczeniowej w kraju ojczystym, a następnie do izby rozliczeniowej w kraju międzynarodowym i ostatecznie zostanie przekazana do banku w obcym kraju. W przypadku blockchain, gdyby był to ten sam bank, bank taki jak Citi może ominąć cały proces z transakcjami swojej waluty cyfrowej, które leżą w gestii przepisów każdego z krajów, a także w ciągu kilku minut od rozliczenia. Z drugiej strony, obecny system zajmuje kilka dni, aby wydać kwotę. Ale tam, gdzie brakuje tych zamkniętych systemów grupowych, jest interoperacyjność monet. Chociaż Citi może z łatwością przelać kwotę z Citi Home do Citi International, nie może tego zrobić w przypadku żadnego innego banku. Tak więc bitcoin nadal ma przewagę, jeśli banki nie spotykają się na tej samej platformie, aby świadczyć bezproblemowe usługi. Ta kwestia wysuwa również na pierwszy plan ważny punkt klasyfikacji systemów blockchain. Chociaż omawialiśmy blockchain jako pojedynczą jednostkę, w rękach prywatnych graczy stał się znacznie szerszą siecią z większą liczbą zawiłości.
Systemy zamknięte i otwarte
Od czasu jego ewolucji i przyjęcia przez prywatnych graczy, blockchain opracował kolejną iterację sieci zamkniętej. Podczas gdy w swojej wcześniejszej formie blockchain był systemem otwartym, czy raczej publicznym; w rękach prywatnych przestał nim być
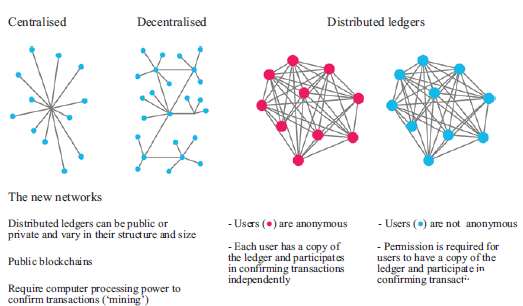
W rzeczywistości, daleki od bycia otwartą siecią, jaka była pod reżimem bitcoin, każdy z systemów, który rozwijał blockchain, skierował go w stronę prywatnego źródła. Weźmy na przykład przypadek Ripple i Bitcoin; chociaż obie są wersjami waluty cyfrowej, Bitcoin jest systemem publicznym, w którym dane są dostępne dla wszystkich; z drugiej strony Ripple jest siecią zamkniętą. Pomimo powiązań z wieloma bankami na całym świecie, Ripple może zezwalać na przelewy pieniężne tylko między swoimi sieciami partnerskimi i ma niewielką interoperacyjność. Można to łatwo wytłumaczyć za pomocą innego przykładu systemów płatniczych. Apple Pay jest własnością Apple Computers, a Google Pay to sieć dla urządzeń z systemem Android. Chociaż Google jest również dostępny na platformie Apple i podobnie jak bitcoin, staje się systemem typu open source, Apple ma ograniczone możliwości, ponieważ jest dostępny tylko dla użytkowników Apple. Chociaż zapewnia to Apple znacznie większe bezpieczeństwo, przy ograniczonej podstawie jego dostępność pozostaje problemem. W związku z tym, będąc prywatnym graczem, ogranicza przypadek użycia blockchain, ponieważ informacje o bloku są dostępne tylko dla kilku graczy, tak jak w naszym arkuszu kalkulacyjnym Excel. Z drugiej strony, w przypadku gdy bitcoin jest siecią otwartą lub publiczną, prawie każdy może uzyskać dostęp do bazy informacji.
Gospodarki zaufania
Zaufanie stało się ważnym elementem współdzielenia gospodarek. Ponieważ technologia przenika wszystkie warstwy naszego społeczeństwa, zaufanie zyskuje na znaczeniu niż modele zysku czy plany biznesowe. W rzeczywistości sukces współdzielenia ekonomii opiera się na zaufaniu między graczami i pewnej mierze bezpieczeństwa zapewnianej użytkownikom. Dlatego ważne jest, aby zarówno przedsiębiorstwa, jak i rządy skupiły się na kwestii zaufania i bezpieczeństwa, a także bardziej promują cyfryzację. Blockchain jest mało prawdopodobnym mistrzem tego systemu zaufania. Zbudowany jako system księgi głównej do handlu bitcoinami, przeszedł długą drogę od tego czasu. Chociaż niesława sieci bitcoin nadszarpnęła część jej reputacji, technologia ta jest wykorzystywana na różne sposoby, aby zapewnić, że nowe systemy nie będą cierpieć z powodu wad starych. W rozdziale omówiono ewolucję blockchaina i jego przypadków użycia, skupiając się na aspekcie zaufania i bezpieczeństwa. Przedstawia również wady i ograniczenia technologii, sugerując drogę naprzód. Oprócz pieniędzy jednym z głównych celów instalacji blockchain jest deficyt zaufania, który tworzy system. Zaufanie stało się jedną z najważniejszych walut w Internecie, ponieważ żadna z korzyści płynących z usług via web nie jest namacalna. To jest ważne zaufanie między kontrahentami, aby system działał sprawnie. Dlatego w niedawnej przeszłości rozkwitły oceny i strony internetowe promujące korzystanie z ocen. Co ważne, przy ogólnym niezadowoleniu z rządu ta miara zaufania przenosi się z rządu na ludzi. Ludzie ufają ocenom bardziej niż rządowi, ponieważ wierzą, że system może zostać sfałszowany na korzyść kilku dużych graczy. Weźmy na przykład jadłodajnie i usługi ratingowe, podczas gdy ludzie nie ufają zbytnio świadectwom zdrowia dostarczanym przez rząd, Cały system zwrócił się teraz do firm pozwalających ludziom oceniać restauracje na podstawie usług, jakości jedzenia i czystości, dzięki czemu usługi takie jak Zomato stały się ważnym źródłem informacji. Podobnie w przypadku ekonomii współdzielenia, ludzie zaczęli bardziej ufać firmom takim jak AirBnB i Bla Bla Car niż tradycyjnym usługom. Blockchain może nie zastąpić gospodarki ratingowej, ale jest dobrym źródłem zaufania dla ludzi. Dzięki przejrzystości u podstaw jego funkcji pomaga w budowaniu zaufania między różnymi źródłami, tworząc w ten sposób coś, czego rynek potrzebuje i na czym bardzo polega. Chociaż zastosowanie blockchain dotyczyło krajów rozwiniętych, kraje rozwijające się, takie jak Indie, również mogą z niego skorzystać. Ponieważ usługi internetowe stają się coraz bardziej wszechobecne w całym regionie, a ludzie stają się bardziej przyjaźni technologicznie, blockchain może być dobrodziejstwem dla rozwijających się i słabo rozwiniętych gospodarek, które zapewniają system kontroli i równowagi. Blockchain może ograniczyć przypadki korupcji, pomóc w wyeliminowaniu korupcji. Jako ,że cały system jest nagrywany blok po bloku, system może zapewnić przejrzystość, co nie wróży dobrze dla korupcyjnych lub skrytych praktyk. Co ważniejsze, ponieważ każdy zapis jest ostateczny, będzie to również cios w problemy z legalnością spraw.
Produkcja
Nic nie może być kompletne bez pomiaru wpływu blockchain i produkcji, jeśli blockchain nie jest w stanie wywrzeć wpływu na produkcję, nie ma sensu skalować tej technologii do dalszych zastosowań. Dlatego najważniejsze jest, aby blockchain był używany do produkcji. Podobnie jak inne procesy, można go wykorzystać do poprawy wydajności łańcucha dostaw i zapewnienia zaufania po stronie klienta. W przypadku zarządzania łańcuchem dostaw większość firm korzystających z blockchain ma stać się bardziej wydajna, zapewniając niewielkie wycieki z systemu. Znaczenie zarządzania łańcuchem dostaw można ocenić na podstawie ankiety przeprowadzonej przez firmę Deloitte. Według ankiety 79% firm o wysokich wynikach łańcucha dostaw odnotowały wyższy niż przeciętny wzrost przychodów. Z drugiej strony tylko 8% firm z mniej sprawnym łańcuchem dostaw mogło to zrobić. Blockchain w tym przypadku może pomóc w śledzeniu danych w sieci, aby uzyskać wszystkie dane w jednym miejscu. Ponadto wykorzystanie połączonych łańcuchów bloków może pomóc w rozwinięciu systemu, w którym o opóźnionej dostawie surowca można informować producenta w czasie rzeczywistym. Podobnie proces ten można wykorzystać po stronie konsumenta, aby upewnić się, że produkt został przetestowany i że wszelkie nieprawidłowości zostały zgłoszone przez firmę, zapewniając większe zaufanie do systemu. W przypadku podróbek można zastosować blockchain wraz z wysoce ulepszonymi chipami mikrokontrolera, aby zapewnić klientom możliwość sprawdzenia prawdziwości produktów. Co ważniejsze, wszelkie testy przeprowadzone na dowolnym produkcie mogą zostać umieszczone przez firmę w łańcuchu bloków, aby klient miał pewność, że testowanie jego produktu zostało zakończone.
Organizacja
Blockchain jest wydajny na liniach produkcyjnych, ale to, co czyni go bardziej wydajnym, to procesy, które może zawierać. W ten sposób wydajna organizacja może zapewnić wydajny proces produkcyjny. W takim przypadku zbiorowe podejmowanie decyzji i inteligentne kontrakty mogą naprawdę pomóc firmom zapewnić przejrzystość i skalowalność.
Inteligentne kontrakty
Jednym z podstawowych przykładów tego zaufania mogą być inteligentne kontrakty lub noty kredytowe, które są wydawane przez banki jako miara gwarancji kredytowej. Kontrakty te można przekształcić w kontrakty inteligentne z uwzględnieniem wszystkich kontrahentów w ramach kontraktu zarządzanego przez blockchain. Weźmy pod uwagę noty kredytowe i wysyłkę. Obecnie istnieje wiele niejasności w przypadku branży żeglugowej i wypłat kredytów. Asymetria informacji może prowadzić do oszustw, co z kolei prowadzi do wyprowadzania pieniędzy z banków. Jeśli inteligentny kontrakt jest zapewniony między kontrahentami, w tym bankami, ubezpieczeniami i spedycją a handlowcami, tę niejednoznaczność można w dużym stopniu zmniejszyć. Na przykład, jeśli handlowiec z Kraju X miałby otrzymać zamówienie od podmiotu z Kraju Y, to handlowiec z Kraju X może przyjąć to zamówienie do Banku A w swoim kraju i otrzymać kredyt na produkcję i eksport takich produktów. Tymczasem, jeśli Y udzieli trochę kredytu, trafi on do banku B w jej własnym kraju, a oba banki będą mogły zweryfikować te informacje na nowo utworzonym bloku. Tymczasem jak banki są połączone. X nie może zaciągnąć kredytu od żadnego innego banku niż A, jeśli spełnia on jego wymagania, ponieważ banki udostępniają te informacje we własnym łańcuchu bloków w celu zmniejszenia przypadków oszustw. Co ważniejsze, ponieważ oba banki weryfikują się nawzajem, proces wypłaty kredytu staje się całkowicie uproszczony, a firma spedycyjna może stać się stroną umowy. Teraz w grę może wchodzić również ubezpieczyciel, bo cały system jest połączony, każda ze stron może sporządzić umowę ubezpieczenia na podstawie świadczonych usług, z przejrzystością, która już istnieje w systemie. Ostatecznie płatność może zostać zwolniona, gdy firma spedycyjna dostarczy zamówienie do kraju Y, zapewniając w ten sposób szybki i wydajny system. W ten sposób blockchain może zmniejszyć niepewność, ponieważ różne podmioty z różnymi łańcuchami bezproblemowo współdziałają ze sobą w ramach jednego zamówienia.
Głosowanie akcjonariuszy
Jednym z kluczowych problemów firm było sprawienie, by akcjonariusze stali się częścią tego procesu. Podczas gdy duże ryby mają szansę głosować w sprawie decyzji firmy, drobni akcjonariusze rzadko mają coś do powiedzenia. Proces jest żmudny i uciążliwy, co utrudnia akcjonariuszom stanie się posiadaczami jakiejkolwiek wartości. Ponieważ istnieje niejasność co do głosowania, obecność wszystkich w siedzibie firmy jest praktycznie niemożliwa. Blockchain może rozwiązać ten dylemat, podobnie jak ubezpieczenie, tworząc osobny blok dla każdego akcjonariusza, a następnie poprosić ich o głosowanie w tym bloku może być łatwym rozwiązaniem. Nie tylko zapewni to udziałowcom prawo głosu, ale także uczyni ich równymi uczestnikami procesu spółki. Tak więc blockchain staje się nie tylko przejrzysty, ale także egalitarny, ponieważ zapewnia każdemu akcjonariuszowi równe prawa w procesie głosowania, niezależnie od ich względnego udziału. Co ważne, proces ten staje się bardziej demokratyczny dla całej firmy, nie tylko akcjonariusze mogą być częścią tej decyzji, ale również posiedzenia zarządu mogą być zwoływane w podobny sposób, przy czym głosowanie odbywa się w ten sam sposób. Już w trakcie wdrażania w krajach takich jak Ghana, głosowanie na blockchainie stanowi miarę wagi dla akcjonariuszy, którzy czynią je częścią decyzji firmy. Chociaż rynki akcji w krajach rozwijających się rozwinęły się, wiele z nich wciąż nie jest świadomych swoich praw. Co ważniejsze, istnieje niejednoznaczność w konwersji akcji z formy zmaterializowanej na Demat. System podobny do łańcucha bloków może zapewnić, że rząd ma dane dotyczące transferów akcji oraz sprzedaży i zakupów od jednego podmiotu do drugiego do końca czasu, a także bez opóźnień. Co ważniejsze, może zapewnić, że firmy są właściwie reprezentowane, przy jak najmniejszych miarach rozbieżności.
Rejestracje firm
Nie tylko akcjonariat firmy, blockchain może również pomóc w rejestracji i śledzeniu firm-widm. Jednym z największych problemów departamentu podatkowego jest obsługa danych firm, ponieważ departament nie ma możliwości śledzenia, które z firm są tylko operatorami typu fly-by-night, wykorzystywanymi do offshoringu lub prania pieniędzy. Z blockchainem to wszystko można to ułatwić, ponieważ każdemu dyrektorowi przypisywany jest numer identyfikacyjny dyrektora, system może śledzić, jakiego rodzaju firmy prowadzi dana osoba i ile z tych przedsiębiorstw faktycznie składa deklaracje i prowadzi działalność. Ułatwiłoby to również rządowi zamykanie i otwieranie firm, a także ułatwiłoby start-upom składanie deklaracji i upadłości. Co ważniejsze, przyczyniłoby się to do ułatwienia prowadzenia działalności gospodarczej poprzez stworzenie przejrzystego systemu, wspomagającego prywatność danych i szybkie śledzenie procesów
Usługi
Podobnie jak w przypadku produkcji i organizacji, blockchain może zapewnić zdrowe dostarczanie usług, gdzie monetyzacja usług i ich dostarczanie stają się łatwiejsze.
Skandal Volkswagena
W 2014 roku rządy i regulatorzy odkryli nowy skandal związany z pojazdami Volkswagena. Firma celowo oszukiwała regulatorów urządzeniami, które nie ujawniałyby rzeczywistego poziomu zanieczyszczeń emitowanych przez samochody. Tak więc w fazie testów laboratoryjnych samochód wykazywałby inne poziomy zanieczyszczenia niż te, które były na drodze. Po wykryciu skandal doprowadził do masowych odwołań, a firma musiała przeprosić ludzi za zdradę zaufania. Co więcej, dochodzenia ujawniły, że chociaż wielu ostrzegało firmę przed tym nieszczęściem, niektórzy z najwyższego kierownictwa zignorowali takie notatki. Blockchain w tym przypadku uniknąłby przypadków takiego skandalu, a firma mogłaby uratować twarz. Ponieważ system jest niezmienny, każda instancja jako taka rejestrowałaby odpowiedzialność na szczycie łańcucha. Zamiast tego, po skandalu nastąpił proces ukrywania, w którym notatki dotyczące problemu zostały zgubione lub zagubione. Zatem blockchain w tym przypadku mógł być zbawicielem dla organizacji, a każda procedura testowa była zapisywana w blokach, tworząc dane, których firma nie mogła wymazać.
IoT i opieka zdrowotna
Według raportu IEEE, blockchain może być również wykorzystywany do ochrony aplikacji Internetu Rzeczy (IoT). IoT może być modnym hasłem od kilku lat, ale wraz ze wzrostem liczby prób hakerskich pojawiły się obawy dotyczące jego zastosowania. Przy obecnej infrastrukturze systemy IoT są tak podatne na ataki, że gdyby haker uzyskał dostęp do choćby jednego z urządzeń, mógłby wyłączyć całą sieć. Blockchain może wyeliminować tę niepewność w odniesieniu do urządzeń IoT. Ponieważ każdy blok jest chroniony osobnym kodem, nawet jeśli haker uzyska dostęp do jednego bloku, pozostałe urządzenia pozostają bezpieczne, ponieważ system uniemożliwia mu dostęp do jakichkolwiek dalszych informacji. W ten sposób łańcuch jest chroniony. Może to być dobrodziejstwem nie tylko dla systemów IoT, ale także dla blockchain. Ponieważ technologia może zapewnić bezpieczeństwo systemów w firmach i domach, jej powielanie może również zapewnić szybką cyfryzację sektora opieki zdrowotnej. Podobnie blockchain może zapewnić, że systemy opieki zdrowotnej nie będą podatne na próby włamań. W ten sposób można powstrzymać takie przypadki, jak włamywanie się do instytucji opieki zdrowotnej. W takim przypadku blockchain może zapewnić, że próby włamania nie wykroczą poza jeden system lub komputer, zapobiegając w ten sposób zamknięciu całego systemu. Co ważniejsze, ponieważ agencje takie jak brytyjska Narodowa Służba Zdrowia mówią o cyfryzacji na masową skalę, blockchain może ograniczyć zasięg hakowania. Może to być i zostało również wdrożone w usługach użyteczności publicznej, gdzie inteligentne sieci mogą być chronione przez aplikacje blockchain, zapewniając, że nie ma to wpływu na usługi użyteczności publicznej. Ponieważ technologia przenika każdy aspekt naszego życia, o wiele ważniejsze staje się zachowanie aspektu bezpieczeństwa. Blockchain w pewnym stopniu może zapewnić taką ulgę.
Inteligentne sieci/energia
W przypadku inteligentnych sieci użyteczność blockchain wykracza poza zapewnienie efektywnego świadczenia usług. Tutaj blockchain może również zapewnić model monetyzacji. Inteligentne sieci działają poprzez zapewnienie, że większość problemów jest zgłaszana w czasie rzeczywistym, a rachunki są generowane przez rząd. Ale w przypadku nowej rewolucji zielonej energii może zdziałać znacznie więcej. Na przykład w niektórych przypadkach ludzie mogą nie tylko kupować energię od rządu, ale także dostarczać energię rządowi. W przypadku, gdy generują więcej, niż mogą zużyć, a następnie rząd może wydać tę energię tym, którzy jej potrzebują. Zapewniając ten model, może sprawić, że alternatywy zielonej energii staną się atrakcyjne i sprawić, że większość ludzi stanie się zielona. Gdy technologia słoneczna będzie wystarczająco wydajna, blockchain zapewni umowę między konsumentem a producentem lub dostawcą energii. Tak więc, jeśli dostawca w tym przypadku pobierze od konsumenta jakąkolwiek ilość energii, to odpowiednio zrekompensuje, a dane znajdujące się w blockchain zapewnią, że będzie on przejrzysty i wolny od wad.
Finanse
Finanse były jedną z pierwszych i najważniejszych dziedzin adopcji blockchain. Pierwsza iteracja blockchain miała miejsce w walutach cyfrowych, a banki i instytucje finansowe rozszerzyły wykorzystanie konsorcjów tworzących blockchain, aby jak najefektywniej wykorzystywać tę technologię.
Bankowość i finanse
Bankowość była jedną z ostatnich dziedzin adopcji technologii. Świat finansów potrzebował 20 lat na przyjęcie Internetu, podczas gdy bankowość komórkowa pojawiła się znacznie później. Patrząc na bardzo niedawny przykład, który jest bliżej domu, moment Apple Pay w Indiach nadszedł dwa lata po uruchomieniu go przez Apple i prawie dziesięć lat odkąd rząd rozpoczął przelewy online za pomocą National Electronic Fund Transfer (NEFT), Real- Time Gross Settlement (RTGS) i system płatności natychmiastowych (IMPS). Ale po zweryfikowaniu przez finanse, technologia zyskuje znacznie szersze zastosowanie w różnych grupach i otwiera kilka możliwości zainicjowania efektu spływania. Blockchain był jedną z takich technologii, która stała się modna, ponieważ sektor bankowy był gotowy na jej przyjęcie. Chociaż ta technologia zajęła prawie dekadę, została wykorzystana jako źródło bitcoinów do przyjęcia. Bankowość i świat finansów nadały blockchainowi nowe znaczenie. Technologia, która stanowi podstawę systemu dystrybucji bitcoinów, wkrótce staje się jednym z najbardziej nadużywanych zjawisk w bankowości. Co ważne, ze względu na zaufanie, blockchain znalazł zastosowanie poza sferą bankowości. Widać to wyraźnie na podstawie liczby start-upów technologicznych związanych z blockchainem, które pojawiły się na przestrzeni lat, oraz tego, jak kwota ich finansowania wzrosła ponad dziesięciokrotnie w ciągu ostatnich pięciu lat. Dane Statista pokazują, że chociaż firmy Blockchain zarobiły w 2013 roku 93 miliony dolarów, w 2017 roku liczba ta wzrosła do 1,032 miliarda dolarów. Jedną z głównych zalet blockchain jest to, że jego przypadki użycia wykraczają poza zakres walut cyfrowych i rozciągają się od obszaru transakcji po ubezpieczenia. Raport Santander InnoVentures wskazuje, że Blockchain zaoszczędzi 20 miliardów dolarów na kosztach instytucji finansowych. Morgan Stanley podkreśla, że może obniżyć koszty nawet o 50% w porównaniu z tradycyjnymi kanałami. W ten sposób blockchain może być zbawicielem dla instytucji bankowo-finansowej, która chwieje się pod wpływem powolnych transakcji i asymetrycznych systemów informatycznych. Weźmy przykład branży bankowej i potrzebę centralnej izby rozliczeniowej. Chociaż bankowość od lat dobrze współpracuje z systemem centralnej izby rozliczeniowej i jest jedną z podstawowych funkcji banku centralnego, może być pozbawiona takich funkcji i być regulatorem w branży, jeśli dozwolona jest technologia blockchain lub rozproszona księga funkcjonować . W przypadku blockchaina i sieci połączonej banki nie byłyby zobowiązane do sporządzania oddzielnego rachunku transakcyjnego dla centralnej izby rozliczeniowej, ponieważ wszystkie dane i transakcje byłyby rejestrowane przez jedną i byłyby widoczne dla drugiej. Firma lub rząd opracowujący ten system może oczywiście pobierać opłaty za takie usługi, ale system zapewniłby sposób, aby banki działały bez żadnych opóźnień operacyjnych i opóźnień. Poza tym, z centralną funkcją centralnej izby rozliczeniowej, banki nie wymagałyby wewnętrznego zespołu do sprawdzania takich transakcji, drastycznie zmniejszając koszty pracownicze i koszty bankowe, zarówno dla banków, jak i dla ogółu społeczeństwa. Tak więc przelew, który zajmował godziny, a nawet minuty, może zostać ratyfikowany w ciągu kilku sekund. Ponadto, biorąc pod uwagę zabezpieczenia, nad którymi nadal należy pracować, można manipulować tylko fragmentami danych, podczas gdy cały system pozostaje chroniony przed hakerami.
Ubezpieczenie
Nie tylko wysyłka blockchain może okazać się dobrodziejstwem dla całej branży ubezpieczeniowej. System poprzez zapewnienie przejrzystości i szybkości pozwala na tworzenie niszowych rynków ubezpieczeniowych, które mogą pracować dla transakcji o ograniczonym czasie trwania. Weźmy na przykład ubezpieczenie od opóźnień w lotach. Łatwiejszym przypadkiem w tym przykładzie może być wykupienie ubezpieczenia przed wejściem na lot. Podczas gdy kupujesz to ubezpieczenie i kwotę, firma ubezpieczeniowa może decydować o kwocie płatności i składce, która zostanie ustalona na podstawie danych z przeszłości i przypadku opóźnień lotów, gdy kupujesz to ubezpieczenie, tworzy umowę specjalnie dla Ciebie , co pozwala na wypłatę kwoty X w przypadku opóźnienia lotu powyżej dwóch godzin. Gdy umowa jest egzekwowana, staje się niezmienna, ponieważ żadna ze stron nie może jej później zmienić. Jeśli lot się opóźni, firma ubezpieczeniowa może w każdym przypadku sprawdzić go w publicznej bazie danych o lotach i natychmiast przekazać kwotę klientowi. Takie niszowe, szybsze produkty płatnicze można stworzyć dla dowolnej oferty/usług, które można zweryfikować krzyżowo, od podróży koleją po ubezpieczenie wypadkowe podczas podróży przez Ubera z jednego miejsca do drugiego, ostatecznie otwierając nowe możliwości dla firm ubezpieczeniowych i klientów ponieważ technologie wchodzą ze sobą w interakcje, zwłaszcza że ekonomia współdzielenia staje się znacznie większa i powszechna. Jest to jedno miejsce, w którym kraje takie jak Indie mogą usunąć niejasności dotyczące płatności ubezpieczeniowych. Gdy system zostanie zmechanizowany, wypłaty ubezpieczeń mogą być szybsze, a dzięki interakcji sieci może zmniejszyć obciążenie procesowe. Ponieważ sprawy ubezpieczeniowe stanowią dużą część obciążenia sądu, rozbieżności w wypłatach. Tak więc sprawy związane z ubezpieczeniem samochodowym, na życie i zdrowotnym można załatwić szybciej i bez większych problemów.
Podobnie jak w przypadku finansów, instytucje zarządzające znalazły wiele przypadków użycia blockchain. Księgi rachunkowe to sposób działania rządu, a zatem blockchain może pomóc rządom w wykorzystaniu tej technologii do ulepszenia systemów rejestrowania.
Ewidencja gruntów
Inną powszechną praktyką, w której blockchain może okazać się konsekwencją, jest prowadzenie ewidencji gruntów. Blockchain może ułatwić proces rejestracji, ponieważ rejestracja ewidencji gruntów może odbywać się online. Ponieważ rejestry są niezmienne, każde przeniesienie rejestru lub gruntu będzie również odzwierciedlone w rejestrach za każdym razem, gdy taka dokumentacja jest sporządzona. Poza tym, będąc otwartym blockchainem, każdy miałby dostęp do zasobu. Tak więc w przypadku naszego przykładu arkusza kalkulacyjnego oznaczałoby to, że każda rejestracja byłaby odzwierciedlona w jednym bloku, a wszelkie zmiany stałyby się częścią tego samego bloku, tworząc w ten sposób łańcuch zdarzeń, który ludzie będą śledzić. Nie tylko skróciłoby to czas trwania postępowania sądowego, ale również ułatwiłoby proces sprzedaży i kupna gruntu, gdyż sprzedawać można tylko nieruchomość z wyraźnym tytułem własności. Co więcej, ograniczyłoby to przypadki oszustw, ponieważ banki miałyby dostęp do tych publicznych rejestrów w celu potwierdzania zakupów i wypłacania pożyczek, w oparciu o transfer czynów i system wpisów. System ten nie tylko ograniczy niejednoznaczność, w połączeniu z mapowaniem za pomocą dronów, ale może również finalizować tytuły własności gruntów i rozstrzygać sporne kwestie dotyczące gruntów za pomocą rejestracji. System zapewniłby, że sprzedaż i zakup gruntów będzie łatwiejszy i bezproblemowy. Proces rejestracji można przeprowadzić online, a także można bez większych opóźnień przekonwertować swoje nieruchomości z dzierżawy na własność. Proces ten pozwoliłby zaoszczędzić pieniądze na opłatach sądowych i niepotrzebnych sporach sądowych
Wybory
Głosowanie akcjonariuszy może nadal być obarczone pewnymi niepewnościami, głosowanie w wyborach jest znacznie łatwiejsze. Obecnie każdy wyborca nosi legitymację wyborczą lub jakąś formę identyfikacji, która pozwala mu głosować w wyborach. Ta identyfikacja, bez względu na to, jaka może być, byłaby unikalna dla tej osoby, dlatego tworzy osobny magazyn danych dla tych informacji. Blockchain jako sieć publiczna może wykorzystać takie sortowanie, aby stworzyć osobny kanał dla każdego z wyborców. Ponieważ głosowanie jest uważane za głosowanie tajne, bezpieczeństwo w ramach blockchain może zapewnić, że każda linia danych od wyborców jest zaszyfrowana, tak że nawet jeśli komisja wyborcza dowie się, że dana osoba głosowała, nie dowie się, jak i czym preferencji dokonano wyboru. Podczas gdy rządy są w trakcie ustanawiania mechanizmu umożliwiającego żołnierzom służącym w innych krajach lub terytoriach głosowanie w ten sposób, może to również utorować drogę rządom do umożliwienia obywatelom głosowania w zaciszu swoich domów bez wielu problemów. Co więcej, może zapewnić większy udział w imieniu wyborców. Podobnie jak udziałowcy, głosowanie w krajach rozwijających się jest również problematyczną kwestią, zwłaszcza dla migrantów zarobkowych. Niezwykle trudno jest prześledzić proces głosowania, blockchain w połączeniu z umowami rejestracyjnymi i dzierżawą gruntu może zapewnić, że dowód osobisty wyborcy jest tak samo mobilny jak osoba. Tak więc osoba z New Delhi mieszkająca w Bengaluru może głosować w wyborach w Bengaluru, a system może zapewnić, że po oddaniu głosu w Bengaluru nie będzie mogła wrócić i głosować w New Delhi.
Śledzenie płatności podatkowych
Podobnie jak w przypadku firm, można leczyć jednostkę. Chociaż każdej osobie przypisywany jest unikalny identyfikator, dział podatkowy może śledzić transakcje danej osoby, aby rozliczyć jej dochód pieniężny. Przykładem może być system bezgotówkowy, ponieważ coraz więcej usług zwraca się do gospodarki bezgotówkowej, może pojawić się punkt, w którym dział IT może śledzić transakcje związane z osobą w bezpiecznej szafce. Ponieważ taki proces byłby weryfikowany przez użytkownika, transakcje te można następnie łączyć z danymi o dochodach w celu wyszukania rozbieżności w zgłaszaniu dochodu podlegającego opodatkowaniu. Co ważniejsze, taki system może również służyć jako miara śledzenia, w jaki sposób pieniądze są wydawane za pośrednictwem transakcji i ile podatku wpłaciła osoba fizyczna. Chociaż podstawą całego systemu jest przejrzystość, istnieje również potrzeba zachowania prywatności, ponieważ ludzie nie będą chcieli pokazywać swoich wydatków jako sprawy publicznej. Głównym obszarem zainteresowania gospodarek rozwijających się jest podstawa opodatkowania. Chociaż pobór podatków wzrósł, podstawa opodatkowania pozostaje taka sama dla tych gospodarek ze względu na praktyki uchylania się od płacenia podatków. Co ważniejsze, w miarę jak proces staje się bardziej partycypacyjny, dział podatkowy może śledzić inwestycje i wydatki danej osoby, aby powiązać dane z płatnościami, aby upewnić się, że podatek jest w pełni zapłacony i nie dochodzi do uchylania się od płacenia podatków. Gdy pobór podatku dochodowego zwiększy się, rząd może sprawdzić, zmniejszając podatki od sprzedaży, co pomoże biednym i zmarginalizowanym sekcjom.
Dotacje i system dystrybucji
Bardziej niż podatki, blockchain może pomóc w przekazywaniu pieniędzy z dotacji, niezależnie od tego, czy są to towary, usługi czy transakcje gotówkowe. System księgi rachunkowej może pomóc w tworzeniu systematycznej ewidencji płatności w formie dotacji z systemem dwukierunkowym zapewniającym, że z usług korzysta właściwa osoba, a nie pośrednicy. Ponieważ system wymaga uwierzytelnienia przez obie strony, zapewniłby zaufanie i przejrzystość z obu stron. Wykorzystując identyfikatory uwierzytelniające i powiązanie systemu, system może wygenerować doskonały program informacyjny, w którym spływanie korzyści jest kompletne i absolutne. Na przykład, jeśli rząd miałby wypłacić zboże, może je otrzymać dystrybutor, który będzie musiał zweryfikować ilość, a ten sam cykl powtórzy się, gdy dotrze do beneficjenta, zapewniając, że każdy otrzyma należną mu część. Wobec niezliczonych programów uruchomionych przez rząd, jednym z głównych problemów było śledzenie korzyści w ramach takiego programu. Śledzenie danych w każdym momencie zapewniłoby, że korzyści, takie jak posiłek w południe, dotrą do ogółu społeczeństwa, z rundami kontroli na każdym kroku, nie byłoby szans na niewłaściwe postępowanie.
Demonetyzujące zyski
Rząd Indii przeprowadził, jak dotąd, największą w swojej historii wymianę banknotów w dniu 8 listopada 2016 r. Chociaż jest wielu krytyków i zwolenników tego posunięcia, nie ma wątpliwości, że rząd i jego instytucje były do tego źle przygotowane. duży krok na tak gigantyczną skalę. Być może jest to powód, dla którego nawet po wymianie waluty o wartości 15,36 lakh crore, niewiele było śledzenia pieniędzy, które otrzymał bank centralny. W rzeczywistości wymiana gotówki w bankach, która była dozwolona po 4000 rupii dziennie, była największym powodem zmartwień. Ludzie wykorzystywali pozbawione skrupułów środki, aby wybielić swoją walutę, a niektórzy w zmowie banków mogli łatwo ujść na sucho. Chociaż rząd promował cyfryzację jako krok naprzód, nie był w stanie wykorzystać jej w pełnym zakresie. Blockchain w tym przypadku pomógłby rządowi osiągnąć wydajność i zatkać wycieki w systemie. Ponieważ wszystkie dane byłyby dostępne na serwerach bankowych, jeśli jakakolwiek osoba poszłaby wymienić pieniądze z innego banku po wymianie 4000 rupii z jednego, zostałaby zarejestrowana w systemie lub nie byłaby dozwolona. Co ważniejsze, w takim scenariuszu każde użycie identyfikatorów rządowych przez banki musiałoby również zostać zweryfikowane krzyżowo przez konsumenta w celu podwójnego sprawdzenia każdego wpisu. Poza tym kodowanie banknotów mogło pomóc bankowi centralnemu ponownie je sprawdzić.
Wykorzystanie łańcucha bloków
Istnieją jednak pewne ograniczenia systemu, którymi należy się zająć przed jego pełnym wdrożeniem na skalę globalną lub krajową. Należy zająć się kwestiami bezpieczeństwa wraz z obawami dotyczącymi prywatności. Co ważne, niezwykle ważna staje się decyzja, kto jest właścicielem łańcucha bloków. Jednym z powodów sukcesu bitcoina i niepowodzeń innych systemów blockchain była kwestia kontroli. Podczas gdy bitcoin był systemem kontroli publicznej, inne były prywatne, ograniczając ich zdolność do interakcji z innymi. Należy zrozumieć, że aby blockchainy działały idealnie, musi istnieć system, który może przemierzać linie rentowności i motywy korporacyjne. Nawet jeśli chodzi o systemy prywatne, oddzielne systemy muszą z łatwością współdziałać ze sobą, aby rynek mógł zostać stworzony jako taki. Nie oznacza to, że kanały prywatne są skazane na zagładę. Chociaż mogą one doskonale sprawdzać się w przypadku małych zadań, skalowalności i zasięgu ogólnoświatowego, musi istnieć albo interakcja łańcuchów ze sobą, albo system, który jest całkowicie publiczny i zdecentralizowany. Chociaż bezpieczeństwo jest jedną z podstawowych cech blockchain, może zapewnić bezpieczeństwo tylko systemu, a nie każdego węzła. Dlatego ważne jest, aby system był bezpieczny. Jeśli chodzi o prywatność, również jest problem. Chociaż system zapewnia prywatność, istnieje problem polegający na tym, że sieci publiczne muszą zrównoważyć prywatność z przejrzystością. System może oferować większą przejrzystość, ale ceną byłoby poświęcenie prywatności, z której wiele osób może nie chcieć rezygnować. Jednym z podstawowych problemów związanych z systemem jest to, że ludzie muszą rozumieć technologię i być świadomi jej użycia. Blockchain odniesie sukces tylko wtedy, gdy ludzie zrozumieją przypadki użycia technologii i wykorzystają ją na swoją korzyść. Ludzie muszą być świadomi istnienia łańcucha bloków w postaci inteligentnych kontraktów, takich jak waluty cyfrowe. Technologia musi przeniknąć do niższych warstw społeczeństwa, aby mogły wykorzystać ją na swoją korzyść. Jeśli chodzi o dotacje, jeśli ludzie nie będą świadomi korzystania z technologii, nie będą mogli skorzystać z tej technologii ani pokładać wiary w system. Innym ważnym problemem związanym z blockchain jest skalowalność. System działał dobrze na ograniczonych użytkownikach, ale może to nie mieć miejsca w przypadku dużej liczby użytkowników i różnych łańcuchów bloków. Duży ruch, który pociąga za sobą wdrożenie na dużą skalę, jest czymś, na co żaden blockchain nie jest gotowy. Jedynym sposobem, w jaki rząd może zapewnić dostęp do technologii, prywatności i bezpieczeństwa, jest forsowanie jej używania. Rząd może to zrobić, promując korzystanie z technologii w niższych warstwach społeczeństwa i łącząc ze sobą system blockchain. Musi stworzyć system, dzięki któremu każda strona, która jest częścią systemu, będzie miała dostęp do takich informacji. Musi zapewnić, że można zbudować zaufanie, w przeciwnym razie system nie będzie skalowalny lub nie będzie w stanie funkcjonować tak, jak powinien. Powiązanie systemu jest ważne dla zapewnienia wydajnego działania systemu. Ale wszystkie te zastosowania blockchain nie będą kompletne, jeśli technologia będzie trzymana w izolacji. Blockchain sam w sobie jest świetnym systemem zapewniającym, że waluty cyfrowe działają tak, jak powinny, ale jedną z głównych wad bitcoinów związanych z ekspansją na różne rynki jest to, że ma ograniczone zastosowanie wśród osób z uzdolnieniami technologicznymi. Dla zwykłego człowieka bitcoin to przerażające słowo, ponieważ nie rozumie go ani nie wie, jak go używać. Blockchain może pozostać podobnym zjawiskiem, jeśli nie wolno mu wchodzić w interakcje z innymi technologiami i uczynić go zrozumiałym, jeśli nie przyjaznym dla użytkownika. Jakakolwiek dyskusja na temat blockchain nie będzie kompletna, jeśli technologia nie będzie mogła wchodzić w interakcje ze sztuczną inteligencją lub algorytmami uczenia maszynowego. Pierwszym przypadkiem w tym punkcie może być pobór podatków, ponieważ praktycznie niemożliwe jest utworzenie każdego bloku po każdej transakcji, ważne jest, aby sztuczna inteligencja stworzyła system montażu, w którym wszystkie transakcje są grupowane w jednym bloku i pod jednym nagłówkiem. Podobnie, aby zbadać niszowe rynki produktów, nowa kategoria produktów musi dobrze współpracować z systemami blockchain, aby działały idealnie. Jednym z problemów związanych z wdrażaniem technologii jest to, że powinna ona być dostępna dla wszystkich. Problem z platformami wyższych technologii polega na tym, że są one poza zasięgiem ogółu społeczeństwa, a zatem mają ograniczone zastosowanie. Istnieje obawa, że pomimo tego, że jest wydajnym systemem, nie będzie w stanie dotrzeć do mas, ponieważ nie zrozumieją one technologii i zostaną wykluczone z procesu. Dlatego rząd musi zająć się kwestią przenikania technologii, jeśli chce, aby blockchain zwiększał przejrzystość i zapewniał bezpieczeństwo. Co najważniejsze, w przypadku gospodarek rozwijających się, wiedza technologiczna musi zostać poszerzona, jeśli rząd ma realizować takie programy. Tak więc w przypadku krajów takich jak Indie rozsądne byłoby, gdyby gospodarka zaczęła uczyć swoją ludność, jak korzystać z technologii. W miarę jak technologia jest wykorzystywana w większym stopniu, więcej wiary będzie spoczywać w nowych systemach, wzmacniając system zaufania. Jednym z klasycznych przykładów tego błędu selekcji jest to, że kobiety przeoczają modę blockchain. Chociaż wskaźniki uczestnictwa kobiet inżynierów wzrosły w ostatnich latach i nastąpił gwałtowny wzrost liczby kobiet w kształceniu inżynierskim, większość z nich przełożyła się na starsze sektory. Nawet jeśli przyjrzymy się dziedzinie kryptowalut i rozwoju blockchain, liczba kobiet zaangażowanych w ich rozwój jest ograniczona. Jeśli chodzi o wzajemne oddziaływanie technologii, w większości rozwijających się gospodarek kobiety znajdują się na niższym progu korzystania z technologii niż mężczyźni. Tak więc ich świadomość programów i przypadków użycia technologii pozostaje ograniczona. Jeśli blockchain ma mieć znaczący wpływ, nie może zignorować brakującej połowy. W związku z tym istnieje zapotrzebowanie na kobiety zarówno w rozwoju blockchainów, jak i w dostępie do technologii.
Wniosek
To rodzi pytanie, czy blockchain może być technologią przyszłości. W szybko ewoluującym krajobrazie blockchain może zachować swoją intrygę i znaczenie. Ale z czymkolwiek inteligentnym, blockchain może mieć znaczenie. Ponieważ integrujemy więcej systemów z inteligentnymi technologiami, blockchain może być ogniwem, które zapewnia bezpieczeństwo i zapewnia zaufanie. Przyszłość blockchain leży w przyszłości smart. Im więcej sieci zostanie połączonych, jak więcej urządzeń IoT jest wykorzystywanych oraz gdy coraz więcej handlu i usług ma miejsce w skali globalnej, blockchain może być bezpiecznym sposobem zapewnienia transmisji. I to też zaczęło się dziać. Blockchain zajął ważną pozycję w debacie o prywatności i bezpieczeństwie, prezentując ironię dla obecnego pokolenia. Tak więc, chociaż milenialsi chętnie publikują swoje życie osobiste na Facebooku, Twitterze i Instagramie, zwracają się również do usług, które są bezpieczne i gwarantują prywatność. W przestrzeni skandali związanych z prywatnością i prób włamań, podczas których dane witryny są przesyłane na platformy społecznościowe, ludzie zaczęli zwracać się w stronę poczty i platform komunikacyjnych obsługujących blockchain. Nie będzie zaskoczeniem, jeśli rządy i firmy zrobią to samo. Doskonałym tego przykładem może być rewolucja Blackberry, która w połączeniu z przesyłaniem wiadomości zapewniła również ochronę prywatności i bezpieczeństwo. Start-upy i przedsiębiorstwa wspierane przez blockchain mogą rozpocząć podobną rewolucję. Ale w tym przypadku nie jedna firma, ale technologia byłaby liderem. Inteligentne systemy ruchu i inteligentne sieci mogą być jednym z nielicznych zastosowań, które nie zostały szczegółowo opisane w rozdziale dotyczącym tej technologii. Co ważniejsze, każdy system księgi lub zarządzanie bazami danych może mieć wygodę blockchaina. Ale skalowalność, jak wcześniej, może być problemem. Podobnie jak w przypadku Blackberry, gdzie skalowalna technologia oznaczała śmierć dla usługi, blockchain może spotkać podobny los. Tak więc, aby blockchain był naprawdę rewolucyjny, skalowalność wraz z cenami byłaby głównym czynnikiem jego wzrostu. Blockchain może nie być technologią, która olśniewa zwykłych ludzi, ale podobnie jak szyfrowanie może zapewnić, że wiele innych technologii może dokonać zmian, których wymaga społeczeństwo lub potrzeb. Chociaż Blockchain został okrzyknięty technologią przyszłości, zwłaszcza po tym, jak waluty cyfrowe zaczęły się modne, zainteresowanie tą technologią może osiągnąć szczyt. Chociaż finansowanie dla start-upów związanych z blockchain wzrosło - według Statista wzrosło to do 1,032 mld USD w 2017 r. w porównaniu z 93 mln USD w 2013 r.- liczba wyszukiwań związanych z technologią spadła ze szczytu w 2017 r. Ale technologia znalazła przypadki użycia Poza bitcoinami i walutami cyfrowymi, ponieważ technologia staje się coraz bardziej wszechobecna, przenikanie każdego aspektu naszego życia zaufanie i bezpieczeństwo nabrały pierwszorzędnego znaczenia, zwłaszcza gdy prowadzimy działalność na całym świecie. Blockchain to sposób na zbudowanie tego zaufania w Internecie przy jednoczesnym stworzeniu zintegrowanej architektury systemów, która jest bezpieczna. W ten sposób blockchain może budować gospodarkę zaufania opartą na zasadach bezpieczeństwa. Nowe systemy, takie jak inteligentne kontrakty, IoT i ubezpieczenia, mogą wykorzystywać blockchain do tworzenia nowych produktów na rynku i zapewniania niewielkiej ilości asymetrycznych informacji. Jednym z podstawowych problemów w ekonomii jest asymetria informacji, gdzie niektórzy ludzie mają większą wiedzę o produkcie niż inni, co często prowadzi do niejednoznaczności w ustalaniu cen i dostosowaniu rynku. Dzięki blockchain niektóre z tych niejednoznaczności można ograniczyć. W tym celu rozdział podzielił funkcje blockchain na dwie domeny, kategoryzując wykorzystanie technologii do funkcji rządowych i pozarządowych, z zaufaniem jako głównym elementem każdej z nich. W przypadku inteligentnych kontraktów technologia może zapewnić, że wszystkie usługi zaangażowane w system kontraktowy i powiązane strony współpracują ze sobą w celu zabezpieczenia kontraktu. Tak więc umowa gwarantowałaby, że każda strona zaangażowana w proces który honoruje umowę w sposób określony w czasie. Dotyczy to również umów ubezpieczeniowych oraz sektora, w którym proces roszczenia jest procesem długotrwałym i żmudnym. Następnie system może być również wykorzystywany do zapewniania korzyści w zakresie śledzenia podatków, gruntów i innych procesów, zapewniając jednocześnie zachowanie prywatności konsumenta jako najważniejszej. Blockchain mógł być technologią przyszłości, ale skalowalność i ograniczona aplikacja utrudniały jej postęp. Technologia działa w formie arkusza kalkulacyjnego, który może być dostępny dla wszystkich, ale nie może być edytowany dla wszystkich, a każda informacja jest chroniona kodem. Mogło to być korzystne dla systemu kontroli krzyżowej informacji oraz pod względem bezpieczeństwa, ale przy ograniczonej liczbie użytkowników może okazać się kosztowną sprawą. Chociaż nie ma wątpliwości, że blockchain ma stać się technologią przyszłości, nie wyjdzie daleko, dopóki nie stanie się skalowalny dla przedsiębiorstw i rządów. Oznacza to, że jeśli rządy i przedsiębiorstwa nie są w stanie połączyć ze sobą blockchain, przypadki użycia mogą pozostać ograniczone. Dlatego najważniejsze jest, aby rząd skierował się w stronę społeczeństwa, w którym można łączyć łańcuchy blokowe, aby uzyskać maksymalne korzyści. Poważną kwestią budzącą niepokój jest pominięcie sporej populacji korzyści płynących z blockchain. Dopóki obywatele nie będą świadomi przypadków użycia blockchain, istnieje duża szansa, że zostaną pominięci w procesie. Adopcja technologii musi sięgnąć dna piramidy i klas uciskanych, aby była naprawdę rewolucyjna; świadomość obywateli jest ważna w przypadku przyjmowania technologii, tak aby nawet jeśli nie rozumieją sedna sprawy, rozumieją, jak i dlaczego. Ta integracja i równość muszą przekładać się nie tylko między bogatymi a biednymi, ale także między mężczyznami i kobietami. Jeśli blockchain nie ma być tak wykluczający, jak inne technologie, edukacja w tym zakresie musi być inkluzywna. Ponieważ świat potrzebuje integracji, blockchain wydaje się być właśnie rozwiązaniem, którego potrzebuje, ale będzie wymagał kilku poprawek i problemów ze skalowalnością, aby stał się technologią na przyszłość.
Integracja systemu dla Przemysłu 4.0
Integracja systemowa to proces powszechnie realizowany w dziedzinie inżynierii i informatyki. Polega ona na łączeniu różnych systemów obliczeniowych i pakietów oprogramowania w celu stworzenia większego systemu i to właśnie napędza Przemysł 4.0 do optymalnego działania. Integracja systemu zwiększa wartość systemu poprzez tworzenie nowych funkcjonalności poprzez łączenie podsystemów i aplikacji. Świat przeżywa obecnie czwartą iterację rewolucji przemysłowej, Przemysł 4.0, która łączy komputery i automatyzację w celu zwiększenia wydajności w branży produkcyjnej, a także obejmuje systemy cyberfizyczne, Internet rzeczy i przetwarzanie w chmurze. Przemysł 4.0 uwzględnia wszystkie rodzaje technologii i maszyn, od smartfonów i tabletów po samochody, sprzęt AGD, telewizory z dostępem do Internetu i wiele innych. Ponadto rozwój oprogramowania nie jest pominięty w jego procesie dla efektywnego i wydajnego tworzenia oprogramowania. Rozwój oprogramowania i aplikacji coraz częściej rozprzestrzenia się we wszystkich obszarach ludzkich przedsięwzięć. Oznacza to zatem, że aby zaspokoić potrzeby ludności świata, należy stosować zasady Przemysłu 4.0. Jak wspomnieliśmy w naszej poprzedniej pracy, projektowanie oprogramowania wirtualnego systemu uczenia się (VLS) jako aplikacji internetowej to nie tylko pisanie serii stron, łączenie ich ze sobą i prezentowanie jako aplikacji, ale dobra i wydajna strategia integracji systemu za darmo. oraz oprogramowanie open-source wykorzystujące skrypty PHP implementujące warstwę VLS (oprogramowania pośredniczącego), warstwę serwera WWW przy użyciu Apache, warstwę relacyjnej bazy danych przy użyciu MySQL oraz warstwę systemu operacyjnego przy użyciu systemu Linux (zamiennie z systemem operacyjnym Windows). Projekt został bardzo dobrze osiągnięty i problemy z adresem MySQL.
Zastosowanie integracji systemu w projektowaniu replikacji bazy danych VLS
MySQL dostosowuje się do scenariusza master-slave. Ale w przypadku replikacji master-master aktualizacje można wykonać w obie strony, czego potrzebował nasz system; stąd dzięki koncepcji algorytmu master-slave MySQL, opracowano algorytm aktualizacji master-master, przetłumaczony na programowalny kod i zintegrowany z VLS. Użyliśmy zasad replikacji MySQL UNISON i Rsync do oceny wydajności naszego protokołu replikacji. Ocena porównuje przepustowość i czas oczekiwania na procesor. Wykazano, że nasz system radzi sobie z szybkimi zmianami w aktualizacjach klientów przy zachowaniu jakości usług w całej aplikacji.
Replikacja bazy danych
Replikacja bazy danych to tworzenie i utrzymywanie wielu kopii tej samej bazy danych. W większości wdrożeń replikacji bazy danych, na przykład MySQL, jeden serwer bazy danych utrzymuje kopię główną bazy danych, a dodatkowe serwery bazy danych utrzymują kopie podrzędne bazy danych. Zapisy do bazy danych są wysyłane do głównego serwera bazy danych, a następnie replikowane przez serwery podrzędne. Odczyty bazy danych są dzielone między wszystkie serwery bazy danych, co skutkuje dużą przewagą wydajności dzięki współdzieleniu obciążenia. Ponadto replikacja bazy danych może również poprawić dostępność, ponieważ serwery podrzędne bazy danych można skonfigurować tak, aby przejmowały rolę, jeśli baza danych master stanie się niedostępna. Replikacja to okresowe elektroniczne odświeżanie (kopiowanie) bazy danych z jednego serwera komputerowego na drugi, tak aby wszyscy użytkownicy w sieci stale dzielili ten sam poziom informacji/danych. Podobnie replikacja bazy danych szybko staje się kluczowym narzędziem zapewniającym wyższą dostępność, przeżywalność i wysoką wydajność aplikacji bazodanowych. Aby jednak zapewnić użyteczną replikację, należy rozwiązać nietrywialny problem zachowania spójności danych między wszystkimi replikami. W tej pracy opisujemy kompletny i możliwy do udowodnienia algorytm, który zapewnia globalną, trwałą, spójną kolejność w środowisku TCP lub Unicast. Algorytm tworzy ogólny silnik replikacji, który działa poza bazą danych i może być zintegrowany z istniejącymi bazami danych typu open source, na przykład MySQL i aplikacjami. Silnik replikacji obsługuje różne modele opensource, łagodząc lub wymuszając ograniczenia spójności w zależności od potrzeb aplikacji. Zaimplementowaliśmy silnik replikacji w oparciu o program aplikacji wirtualnego środowiska uczenia się i dostarczyliśmy eksperymentalne wyniki wydajności.
Korzeń replikacji
Replikacja była badana przez lata w wielu różnych obszarach. Jej korzenie sięgają dwóch dużych obszarów: baz danych i systemów rozproszonych. Te dwie gałęzie informatyki historycznie miały różne podejścia do replikacji. Pierwszą dużą różnicą był podstawowy byt, który musiał zostać zreplikowany: w świecie baz danych były to dane, podczas gdy w systemach rozproszonych był to proces. Kolejną ważną różnicą był cel wykonywania replikacji. Bazy danych były replikowane głównie ze względu na skalowalność i rozkład obciążenia, podczas gdy w systemach dystrybucyjnych replikacja była wykorzystywana do uzyskania odporności na awarie. Ponieważ te dwa obszary miały różne cele, określono różne wymagania dla algorytmów replikacji; w szczególności określono gwarancje spójności.
Replikacja w systemie rozproszonym
W systemie rozproszonym replikacja jest wykorzystywana głównie do poprawy odporności na awarie. Replikowana jednostka jest procesem; W systemach rozproszonych zastosowano dwie strategie replikacji: replikację aktywną i replikację pasywną. W replikacji aktywnej każde żądanie klienta jest przetwarzane przez wszystkie serwery, podczas gdy w replikacji pasywnej istnieje tylko jeden serwer (tzw. podstawowy), który przetwarza żądania klientów. Po przetworzeniu żądania serwer główny aktualizuje stan pozostałych serwerów (zapasowych) i odsyła odpowiedź do klienta. Jeśli podstawowy ulegnie awarii, jego miejsce zajmuje jeden z serwerów zapasowych.
Replikacja w bazach danych
W replikacji bazy danych algorytmy dzieli się na replikację gorącą i leniwą. W gorliwej replikacji replikujemy każdą operację przed zwróceniem wyniku do klienta. Z drugiej strony, w leniwej replikacji zmiany nie są propagowane natychmiast, ale opóźniane na później. Może to być interwał czasowy lub zatwierdzenie transakcji. Głównym zainteresowaniem w tej pracy są różne algorytmy replikacji baz danych używane do przeprowadzania aktualizacji. W niektórych rozwiązaniach za aktualizację danych odpowiedzialna jest tylko jedna replika, podczas gdy w niektórych bardziej zaawansowanych algorytmach dane mogą być aktualizowane przez różne repliki. Ponieważ zależy nam na zachowaniu spójności danych, konieczne jest zastosowanie jakiegoś mechanizmu kontroli współbieżności. Z powyższego widać, że aktualizacje można przeprowadzać zarówno w jednej witrynie, jak i w wielu witrynach
Replikacja w MySQL
Replikacja MySQL działa dzięki serwerowi głównemu, na którym wszystkie operacje wstawiania, aktualizowania i usuwania (w zasadzie wszystkie pisane) oraz co najmniej jeden serwer podrzędny odpytuje serwer główny w celu zreplikowania bazy danych (rysunek 11.3). Zapytania wybierające można wysyłać tylko do serwera podrzędnego. Można również mieć wiele serwerów głównych, które zostaną omówione w tej pracy. Replikacja bazy danych w klastrze społecznościowym dobrze się skaluje i stanowi realną alternatywę dla korzystania z drogiej konfiguracji sprzętowej wieloprocesorowej i/lub sieciowej pamięci masowej . Celem i motywacją tej pracy jest zaprojektowanie struktury inteligentnej replikacji, która dostosuje MySQL do zasad replikacji master-master zamiast zasad replikacji master-slave. Ponieważ MySQL jest bazą danych o otwartym kodzie źródłowym, językiem implementacji jest skrypt PHP. W systemie połączenie między aplikacją a warstwami bazy danych to zestaw programów planujących (VLE_Repli), jeden na aplikację, który dystrybuuje przychodzące żądania do klastra replik bazy danych. Każdy program planujący (VLE_Repli) po odebraniu zapytania z serwera aplikacji wysyła je przy użyciu schematu replikacji typu "odczyt i zapis-wszystko" do zestawu replik przydzielonego do aplikacji. System wirtualnego środowiska nauki oferuje wsparcie replikacji poprzez usługę VLE_Repli. Replikacje są propagowane z wywołaniami przez przekazanie kontekstu replikacji. Replikacje są koordynowane przez VLE_Repli, który koordynuje aplikację wirtualnego środowiska uczenia się. Harmonogram aplikacji (VLE_Repli) zapewnia spójną replikację. Znaczniki harmonogramu aktualizują się wraz z nazwami pól tabel, które muszą odczytać i wysłać do replik. Jeśli istnieje serwer proxy, program planujący komunikuje się z serwerem proxy bazy danych w każdej replice w celu zaimplementowania replikacji.
Algorytm replikacji (replikacja serwer-serwer)
Edemenang zasugerował, że operacje oczekiwania i sygnału są niepodzielne. Oznacza to, że czytelnik i pisarz nie mogą działać w tym samym czasie. Jest to realizowane podczas replikacji aktualizacji MySQL wirtualnej bazy danych nauczania, ponieważ obejmuje odczytywanie i zapisywanie (aktualizację) podczas wykonywania zapytań.
Problem: Algorytmy, które przeszukają tabelę (bazę danych) z atrybutami lub polami dla określonego wzorca. Jeżeli wzorzec zostanie znaleziony, to jest on zastępowany (replikowany) przez inny podany wzorzec (zaktualizowana baza danych).
Opracowanie algorytmu: Konieczność zastąpienia (replikacji) zawartości bazy danych inną pojawia się bardzo często w bazach danych obsługujących wirtualne środowisko uczenia się z powodu materiałów dydaktycznych, przydziału, powiadomienia, aktualizacji itp. Podstawowym zadaniem jest aktualizacja wszystkich zdarzeń na linii konkretnego wzorzec bazy danych przez inny wzór w zależności od zaktualizowanego.
Według Schneidera każdy algorytm musi przyjąć określony język programowania i technikę implementacji. Na tej podstawie mechanizm, który próbujemy zaimplementować, można traktować jako umieszczenie początku wzorca tabeli (atrybutu bazy danych) na pierwszym polu lub znaku atrybutu w bazie danych, drugim polu lub znaku atrybutu w bazie danych, i tak dalej. Przy każdym pozytywie należy określić stopień dopasowania między wzorem a następnym. W ten sposób nie będzie ryzyka przeoczenia meczu. Centralną częścią naszej strategii wyszukiwania pól lub wzorców atrybutów w bazie danych jest to, że chociaż w bazie danych są jeszcze inne pola lub atrybuty do zastąpienia, strategia wyszukiwania jest kontynuowana.
(a) "Zlokalizuj" pole bazy danych lub wzorzec atrybutu na następnej pozycji w tabeli bazy danych
(b) Sprawdź, czy istnieje pełne dopasowanie w bieżącym polu lub pozycji atrybutu.
Ze sposobu interakcji długości ścieżki wzorca i rozmiaru tekstu pola lub atrybutu (długości tekstu) możemy wywnioskować, że istnieją:
Długość tekstu pola lub atrybutu-długość wzorca (długość bazy danych) +1 pozycja, na której wzorzec może być umieszczony w tabeli za każdym razem, gdy porównujemy znak tekstu pola lub atrybutu i wzorzec tabeli bazy danych, dominuje jedna z dwóch sytuacji, para znaków albo dopasowanie lub niezgodność. Jeśli dojdzie do meczu, jesteśmy zobowiązani do przeprowadzenia dodatkowego testu, aby sprawdzić, czy została ustalona cała sytuacja meczowa. Gdy widzimy problem w tym świetle, znika potrzeba osobnej pętli dopasowującej. Nasza centralna strategia wyszukiwania przekształciła się teraz w:
While i ≤ (pole lub atrybut) textlength-patlength (długość bazy danych) + 1 do
(a) Jeżeli wzorzec [j] = + * t [i + j - i], to
(a.1) zwiększ j o jeden
(a.2) jeśli kompletne dopasowanie to
Wykonaj pominięcie (pole lub atrybut jest tym samym testem co następne pole lub atrybut) else
(a.1) zresetuj wskaźnik wzoru j (Komunikat o błędzie)
(a.2) przesuń wzór do następnej pozycji tekstu, zwiększając i
Doszliśmy teraz do punktu, w którym możemy z powodzeniem wyszukiwać i wykrywać dopasowania pól lub wzorców atrybutów w bazie danych. Zadaniem, które pozostaje, jest sformułowanie kroków replikacji (edycji kopii). W ogólnym przypadku nie możemy oczekiwać, że linia wejściowa i edytowana będą tej samej długości, ponieważ oryginalny wzór i jego zamiennik mogą mieć różną długość. Sugeruje to, że prawdopodobnie najłatwiej będzie stworzyć nową kopię wspólnych części podczas tworzenia edytowanych linii. Nasze kroki replikacji będą zatem obejmować sekwencję kroków kopiowania i zastępowania wzorców, przy czym zamiana ma miejsce, gdy algorytm wyszukiwania znajdzie pełne dopasowanie, a kopiowanie przeważa w przeciwnym razie. Tak więc, tworząc edytowaną linię, musimy albo kopiować z oryginalnej linii, albo zastępować wzór. Kopiowanie z oryginalnego wiersza będzie zatem musiało poprzedzać wyszukiwanie. Pytanie, na które należy odpowiedzieć, brzmi: jak zintegrować operację kopiowania z wyszukiwaniem? Oczywiste jest, że zawsze, gdy występuje niedopasowanie i odpowiadające mu przesunięcie wzoru względem tekstu, może mieć miejsce kopiowanie. W przypadku dopasowania postaci nie jest tak oczywiste, co należy zrobić. Dokładniej badając tę sytuację widzimy, że zwiększy się ona dopiero po pełnym dopasowaniu, a więc w sytuacji częściowego dopasowania będzie potrzebne kopiowanie. Kompletne dopasowanie sygnalizuje potrzebę kopiowania nie z oryginalnej linii, ale z wzorca zastępczego. Tak więc w rzeczywistości dwie sytuacje kopiowania, z którymi musimy sobie radzić, są dobrze zdefiniowane:
(a) W przypadku niezgodności kopii z oryginalnej linii.
(b) Gdy kompletna kopia meczu z nowego wzoru (jeden do aktualizacji).
Rozważmy najpierw niezgodną kopię. Gdy propozycja kopii może być:
newtext[i] := txt[i]
Nie uwzględnia to jednak, że nowa linia będzie rosła w różnym tempie, jeśli stary i nowy wzór mają różną długość. Zmienna i pozycji wzorca nadal będzie odpowiednia, ale dla edytowanego wiersza potrzebna będzie nowa zmienna k, która może rosnąć w różnym tempie. Kopia w sytuacji niezgodności będzie miała wtedy postać:
nonewtext[k] := txt[i]
Kiedy napotkamy pełne dopasowanie, musimy skopiować kompletny wzorzec, a nie pojedynczy znak, ponieważ odpowiada to sytuacji edycji. Nowy wzorzec nowywzorzec musi być wstawiony bezpośrednio za miejscem, w którym został wstawiony ostatni znak w edytowanym wierszu tekstu (tzn. po pozycji k), ponieważ trzeba skopiować pewną liczbę znaków. Najlepszym sposobem na zrobienie tego będzie pętla, czyli
for l := 1 to newpatlength do
begin
k := k+1;
newtext[k]:newpattern[l]
end
Po skopiowaniu wzorca będziemy musieli przejść poza pozycje tekstu zajmowane przez stary wzorzec. Możemy to zrobić, zwiększając i o długość starego wzoru
i := i+ patlength
W tym momencie będziemy musieli również zresetować wskaźnik do wzorca wyszukiwania. Stworzyliśmy teraz mechanizm edycji, który zastąpi wzór znajdujący się w dowolnym miejscu i dowolną liczbę razy w edytowanym wierszu. Skonfigurowaliśmy również mechanizm kopiowania z oryginalnej linii tekstu. Przyglądając się dokładnie temu mechanizmowi, widzimy, że może nie udać się skopiować kilku ostatnich znaków z tekstu ze względu na mniejszą wartość indeksu pozycjonowania w stosunku do liczby znaków w tekście oryginalnym. Musimy zatem wstawić kroki, aby skopiować te "pozostałe" znaki. To znaczy,
While ≤ textlength do
begin
k:=k+1;
Nextext[k]:txt[i];
i:=i +1
end
Gdy te wymagania edycyjne zostaną włączone do naszego schematu wyszukiwania wzorców, otrzymamy kompletny algorytm.
Opis algorytmu
1. Ustal bazę danych, wzorzec wyszukiwania i wzorzec zastępczy oraz związane z nimi długości w znakach.
2. Ustaw początkowe wartości pozycji w starym tekście, nowym tekście i wzorcu wyszukiwania.
3. Chociaż wszystkie pozycje wzorców w bazie danych nie zostały zbadane, nie:
(a) Jeśli bieżąca baza danych i znaki wzorca pasują do siebie, to:
• (a.1) rozszerz indeksy do następnego wzoru/znaku tekstu
• (a.2) jeśli wszystko się zgadza, to
• (2.a) skopiuj nowy wzór do aktualnej pozycji w edytowanej linii
• (2.b) przejdź poza stary wzór w tekście
• (2.c) wskaźnik resetowania wzorca wyszukiwania
W przeciwnym razie
• (a0.1) kopiuje aktualny znak tekstowy do następnej pozycji w edytowanym tekście,
• (a0.2) zresetuj wskaźnik wzorca wyszukiwania,
• (a0.3) przesuń wzór do następnej pozycji tekstu.
4. Skopiuj pozostałe znaki w oryginalnej linii tekstu.
5. Zwróć edytowany wiersz tekstu.
Zasady algorytmu MySQL
• Kod główny jest wykonywany jako pierwszy.
• Oceniany jest test akceptacyjny.
• Jeśli test akceptacji ma wartość TRUE, to wykonywany jest następny segment kodu podstawowego następujący po bieżącym.
W przeciwnym razie przywróć do stanu sprzed bieżącego stanu programu.
• Powtarzaj wykonywanie rezerwowych części zapasowych, aż test akceptacyjny da wynik PRAWDA, w przeciwnym razie system ulegnie awarii
Procedure Update ()
databaseTable (list of variable)
Begin (*Content list of tables are copied into temporal variables*)
Rp = 1(* initially perform primary *)
End Update; (* Update*)
Operacja aktualizacji tworzy nowe środowisko dla uruchomionego programu, dzięki czemu odzyskiwanie jest możliwe przy użyciu zmiennych tymczasowych do ponownego uruchomienia programu we wcześniejszym stanie. Tak więc mamy
Function Check (Tables)
Test: variable match
Begin
If test
Then Begin (* successful - replicate *)
(* discard copies in temporaries *)
Check = TRUE
Rp = 0
Else Begin (* failure*)
(* restore copies for temporaries *)
Check = fail or false
Rp =rp + 1 (* increase rollback counter *)
End
End check
Wyjaśnienie algorytmu replikacji MySQL: W tej sekcji szczegółowo opisujemy algorytm replikacji. Zaczynamy od nakreślenia faz, przez które algorytm przechodzi w swoich działaniach i stanów, w których może znajdować się każda replika, a następnie przechodzimy do omówienia po kolei każdej fazy .
Faza i stan: W każdej chwili system z algorytmem replikacji MySQL znajduje się w jednej z trzech globalnych faz: usługa, wybór.
System jest zwykle w fazie obsługi, akceptując i przetwarzając żądanie aktualizacji od klienta i tworząc tymczasową kopię aktualizacji.
Procedure Update ()
databaseTable (list of variable)
Begin (*Content list of tables are copied into temporal variables*)
Rp = 1(* initially perform primary *)
End Update; (* Update*)
Po zakończeniu system przechodzi do fazy wyborów. Podczas tej fazy repliki przeprowadzają wybory, aby zebrać większość i wybrać jeden ze swoich numerów jako nadrzędny (to również zależy od konfiguracji systemu). Gdy wybory się powiedzie, repliki, które w nich uczestniczyły, nazywane są replikami aktywnymi, a następnie algorytmem przechodzi do fazy regeneracji. Operacja aktualizacji tworzy nowe środowisko dla uruchomionego programu, dzięki czemu odzyskiwanie jest możliwe przy użyciu zmiennych tymczasowych do ponownego uruchomienia programu we wcześniejszym stanie. Tak więc mamy
Function Check (Tables)
Test: variable match
Begin
If test
Then Begin (* successful - replicate *)
(* discard copies in temporaries *)
Check = TRUE
Rp = 0
Podczas odzyskiwania, mistrz kieruje systemem na dwa przeplatające się zadania. Po pierwsze, aktywne repliki uzgadniają wszelkie różnice między swoimi kopiami danych. Po drugie, każda aktywna replika przesuwa zestaw zmiennych, które przechowuje w stabilnym magazynie, dzięki czemu nieaktywne repliki można zidentyfikować jako nieaktualne podczas kolejnych wyborów. Po pomyślnym wykonaniu tych zadań system ponownie wchodzi w fazę obsługi. Zakładając, że podczas procesu uzgadniania występują niezgodności, zgłaszane jest powiadomienie o awarii, system powraca do fazy serwisowej.
Else Begin (*failure*)
(*restore copies for temporaries *)
Check = fail or false
Rp =rp + 1 (* increase rollback counter *)
End
End check
Polityka replikacji wirtualnego systemu nauczania
Dzięki koncepcji replikacji w scenariuszu MySQL opracowano algorytm VLS dla master-master z konfiguracją systemu, która utrzymywała spójne elementy danych. Podczas procesu aktualizacji pobierane i modyfikowane są obiekty danych. Po wywołaniu "VLE_Repli" system szuka obiektu o tej samej strukturze w bazie danych drugiego węzła. Jeśli obiekt jest taki sam, VLE_Repli wykonuje aktualizację obiektu. Jeśli nie, zwracany jest komunikat o błędzie i proces się kończy. Szczegóły są jak poniżej:
• Pobierz obiekt danych, który wymaga modyfikacji
• Zaktualizuj obiekt. Na przykład: CSC 111; notatki z kursu, zadania, materiały referencyjne itp.
• Po zakończeniu wybierz przycisk "aktualizuj"
• Zwróć uwagę, że w naszym programie "aktualizacja" aktualizuje obiekt w bieżącym węźle i uruchamia replikację na innych węzłach
• Sprawdza obiekt danych, aby potwierdzić dopasowanie
• Jeśli atrybuty dwóch obiektów są takie same, następuje replikacja
• Powtarza to we wszystkich węzłach
• Jeśli dopasowanie obiektu nie zostało znalezione na innym serwerze, zostanie zwrócony komunikat o błędzie
• • Replikacja zatrzymuje się
Algorytm replikacji VLS pokazano poniżej.
ProcedureUpdate ()// perform update object (database and schemasmodifications)
Function Check (Tables) // trigger "update" button to carry out check on
the object
(relation having the same database and schema in other connected node(s))
Test: variable match // verify and confirm that all corresponding table relations are the same
Begin// start the verification and confirmations in all table
If test successful// Test for success
Then Begin (* replicate *)// if successful, update (replicate)
Else Begin (* failure*)// if not successful
Get schema from master // ensure that the right schema is obtained from the table
Loop Function Check (object)// go back and check the source of update (* report system fail *)// report error notice and end the operation
End
End
Istnieją dwie główne zalety VLS nad MySQL. Aktualizacja na innych węzłach odbywa się w czasie rzeczywistym. Podczas gdy w polityce MySQL, przed wykonaniem aktualizacji, selekcja usługi, wybór i odzyskiwanie muszą mieć miejsce przed wykonaniem replikacji. Kolejną zaletą replikacji VLS jest to, że replikacja odbywa się jednocześnie we wszystkich podłączonych masterach, podczas gdy w MySQL tylko master może aktualizować wszystkie podłączone do niego slave′y, co może prowadzić do przeciążenia mastera.
Testowanie eksperymentu II (przejście i analiza) testowanie replikacji
Ten eksperyment zademonstrował replikację MySQL (UNISON i RSYNC) oraz projektowanie replikacji VLS. Główną ideą było pokonanie master-slave przyjętego przez UNISON i RSYNC. VLE_Repli przyjął replikację master-master, ale nadal utrzymuje platformę MySQL. Przepustowość replikacji i czas oczekiwania procesora zostały wykorzystane do określenia wyższości wydajności przy użyciu Pentium IV z niską specyfikacją konfiguracji systemu. Dla każdego eksperymentu monitorowano aktywność procesora na przepustowości i czasie oczekiwania podczas wykonywania aktualizacji klienta. W tym eksperymencie całkowita aktualizacja, aktualizacja na sekundę, liczba zaktualizowanych tabel i czas procesora zostały wywołane na ekranie i zapisane w tabeli bazy danych w środowisku Microsoft Window. Również w poprzednim eksperymencie dane zostały zebrane z narzędzia VMSTST Linux do wykreślania wykresów, zarówno przy użyciu programu Microsoft Excel, jak i Lotus 1-2-3 do wykreślania wykresów. Poniższe tablice przedstawiają przechwycony ekran i tabele podsumowania wydajności z różnych lub różnych modyfikacji bazy danych MySQL, a następnie demonstrują aktualizację przy użyciu (MySQL UNISON i Rsync) i zaprojektowanej replikacji VLS. Zaprojektowany VLS nie tylko wykazał wyższą wydajność w aktualizacji, ale także dostosował replikację master-master. Ten eksperyment zademonstrował replikację MySQL (UNISON i RSYNC) oraz projektowanie replikacji VLS. Główną ideą było pokonanie master-slave przyjętego przez UNISON i Rsync. VLE_Repli przyjął replikację master-master, ale nadal utrzymuje platformę MySQL. Zauważ, że przy wyborze RSYNC i UNISON, które przyjmują replikację master-slave, MySQL wymaga rekonfiguracji jak poniżej, ponieważ wykonuje zarówno aktualizację, jak i replikację. Tylko VLS aktualizuje, a MySQL wykonuje replikację.
Konfiguracja urządzeniu głównym w wierszu poleceń
Create user dbname '@'%'identified by 'password';
Grant replication slave on *.* to 'dbname'
Flush tables with read block;
Show master status
Unlock tables;
Konfiguracja na urządzeniu podrzędnym w wierszu polecenia
Stop slave;
Change master to
→ Master_host= ' '
→ Master_user = ' '
→ Master_password = ' '
→ Master_log_file = ' '
→ Master_log_pos = ' '
MySQL configuration file:
→ Retrieve all MySQL.config file in all the connecting systems
→ Retrieve My.ini
→ Call program line containing Log-bin= Mysql-bin and enable the program line
→ Also enable server-id = 1
→ Save the configuration files again and exit
Gdy aktualizacja zostanie wykonana na urządzeniu głównym, automatycznie zostanie ona powielona na urządzeniu podrzędnym. W związku z tym aktualizacje są wykonywane na urządzeniu master, a nie slave w scenariuszu master-slave. Ale w przypadku replikacji master-master aktualizacje można wykonać w obie strony. Dla każdego eksperymentu aktywność procesora była monitorowana podczas wykonywania aktualizacji klienta. W tych eksperymentach całkowita aktualizacja, aktualizacja na sekundę, liczba zaktualizowanych tabel i czas procesora były wywoływane na ekranie i zapisywane w tabeli bazy danych. Poniższe tablice przedstawiają zrzuty ekranu i tabele podsumowania wydajności z różnych lub różnych modyfikacji bazy danych MySQL, a następnie demonstrują aktualizację przy użyciu (MySQL UNISON i RSYNC) i zaprojektowanej replikacji VLS. Zaprojektowany VLS nie tylko wykazał wyższą wydajność podczas aktualizacji, ale także dostosował replikację master-master.
Wymagania sprzętowe i programowe do replikacji
Nasz eksperymentalny algorytm replikacji składa się z aplikacji sieci Web (aplikacji do wirtualnego uczenia się), modułu równoważenia obciążenia i warstw serwera bazy danych. Wszystkie te komponenty wykorzystują ten sam sprzęt. Korzystamy z serwera WWW Apache 1.3.31 oraz serwera bazy danych MySQL 4.0.16 z tabelą NewVLEARN. Kilka eksperymentów zostało przetestowanych przy użyciu systemu operacyjnego Red Hat Fedora Core 3 Linux z jądrem 2.6 i systemem operacyjnym WINDOW używanym zamiennie. Wszystkie węzły zostały połączone przez 100 Mbps Ethernet LAN.
Dane wyjściowe replikacji bazy danych: Wynikiem są cztery wykresy. W każdym eksperymencie aktywność procesora w zakresie przepustowości i czasu odpowiedzi była monitorowana podczas wykonywania aktualizacji klienta przy użyciu katalogu narzędzia VMSTST Linux dla dwóch przeprowadzonych eksperymentów.
Wniosek
Obecny trend rewolucji przemysłowej w tworzeniu oprogramowania polega na tym, że twórcy oprogramowania przestali tworzyć oprogramowanie od zera; raczej aplikacje są obecnie składane z dobrze zaopatrzonych katalogów komponentów oprogramowania wielokrotnego użytku w celu tworzenia złożonych lub dużych aplikacji poprzez integrację systemową. Integracja systemowa, jak zdefiniowano wcześniej, to proces łączenia podsystemów składowych w jeden system (agregacja podsystemów współpracujących tak, aby system mógł pełnić nadrzędną funkcjonalność) i zapewnienia, że podsystemy funkcjonują razem jako system. Główną zaletą Przemysłu 4.0 w integracji systemów wytwarzania oprogramowania jest potrzeba poprawy wydajności i jakości ich działania. Celem jest stworzenie możliwości ponownego wykorzystania komponentów systemu, tak aby można je było łatwo rozszerzyć poprzez integrację z innymi podsystemami w celu opracowania bardziej złożonego systemu w celu przyspieszenia procesu tworzenia oprogramowania. Obecnie tworzenie oprogramowania komputerowego z wykorzystaniem integracji systemów oprogramowania odgrywa ważną rolę w tworzeniu wszelkiego rodzaju aplikacji dla przedsiębiorstw na całym świecie. Integracja systemu we wszystkich wynalazkach naukowych wpływa na prawie wszystkie aspekty naszego życia i naszych codziennych czynności. Dzieje się tak, ponieważ w starych modelach inżynierii oprogramowania istniało wiele krytycznych problemów: niska wydajność i jakość oraz wysokie koszty i ryzyko. Podstawową przyczyną jest próba opracowania oprogramowania jako niezależnego podmiotu, co zawsze prowadziło do opisanych powyżej problemów. W celu skutecznego rozwiązania tych krytycznych problemów przedstawiono nowy model inżynierii oprogramowania, ponowne wykorzystanie komponentów, poprzez zasadę integracji systemu. Zasadniczą różnicą między starym procesem rozwoju inżynierii oprogramowania a procesem integracji systemu jest ponowne wykorzystanie komponentów oprogramowania (open source). Doprowadziło to do rewolucyjnych zmian w prawie wszystkich aspektach inżynierii oprogramowania, aby skutecznie radzić sobie ze złożonością oprogramowania, niewidzialnością, zmiennością i zgodnością oraz rozwiązywać krytyczne problemy (niska wydajność i jakość, wysokie koszty i ryzyko) istniejące w starej inżynierii oprogramowania praktyka tworzenia oprogramowania od podstaw. Problemy rozwiązane, jak wykazano w rozwoju VLS, w którym różne elementy algorytmu
Produkcja przyrostowa w kierunku Przemysłu 4.0
Produkcja przyrostowa (AM) to proces tworzenia obiektu poprzez budowanie go po jednej warstwie na raz. Jest to coś przeciwnego do montażu subtraktywnego, w którym element jest wytwarzany przez usuwanie materiału w mocnym kwadracie, aż do ukończenia ostatniego elementu. Jest to naukowa nazwa praktyk druku 3D stosowanych na rynku, gdzie odróżnia proces od metod usuwania materiału stosowanych w dziedzinie produkcji. AM eliminuje również wiele ograniczeń narzucanych przez konwencjonalną produkcję. AM to "procedura łączenia materiałów w celu utworzenia obiektów z informacji modelu 3D, w większości warstwa po warstwie". Inaczej nazywa się to szybkim prototypowaniem. Wykorzystując AM, projekt w formie skomputeryzowanego modelu bryłowego 3D można łatwo przekształcić w gotowy element bez użycia dodatkowych aparatów i narzędzi tnących. Zdolność adaptacyjna AM umożliwia producentom ulepszenie struktury dla generacji szczupłej, która dzięki swojemu temperamentowi eliminuje marnotrawstwo. Kruth i in. stwierdzają, że szybkie prototypowanie w większości odnosi się do procedur, które wytwarzają części formowane poprzez stopniowe tworzenie lub rozszerzanie mocnego materiału, w tym zakresie różniącym się na bardzo podstawowym poziomie od systemów kształtowania i wytwarzania z wypychaniem materiału . Innowacje AM można wykorzystać do produkcji części metalowych. Ten krok naprzód w zakresie innowacji montażowych umożliwia wytwarzanie nowych kształtów i geometrycznych akcentów. Chociaż wykonalność produkcji przykładowych części w tych procesach była przedmiotem kilku badań, krok naprzód w montażu nie został jeszcze poprzedzony osiągnięciami w procesie planowania. W dobie Przemysłu 4.0 większość sektorów prawdopodobnie będzie korzystała z AM, przy dalszej poprawie jakości produkowanych części.
AM w różnych branżach
Początkowo postrzegany jako proces modelowania koncepcji i szybkiego prototypowania, AM rozszerzył się w ciągu ostatnich pięciu lat, aby objąć aplikacje w wielu obszarach naszego codziennego życia. Od prototypowania i oprzyrządowania po bezpośrednią produkcję części w sektorach przemysłowych, takich jak architektoniczny, medyczny, dentystyczny, lotniczy, motoryzacyjny, meblarski i jubilerski, stale opracowywane są nowe i innowacyjne zastosowania. Można powiedzieć, że AM należy do klasy technologii przełomowych, rewolucjonizując sposób myślenia o projektowaniu i produkcji. Od towarów konsumpcyjnych produkowanych w małych partiach po produkcję na dużą skalę, zastosowania AM są ogromne. Rysunek przedstawia zastosowanie AM w różnych gałęziach przemysłu.
Przemysł motoryzacyjny i dostawcy
Producenci i dostawcy samochodów byli jednymi z pierwszych użytkowników AM, gdy pojawił się pod koniec lat 80., ponieważ dużo projektują i przeprojektowują, a także od dawna profesjonalnie obsługują systemy CAD 3D. W ten sposób przekazywanie nienagannych indeksów informacyjnych nie stanowi problemu dla producentów oryginalnego sprzętu samochodowego (OEM) i dostawców. W dzisiejszych czasach liczba prototypów wzrasta, ponieważ dywersyfikacja sprawia, że rozwój wariantów produktów jest znacznie ważniejszy. Części modelu są wykorzystywane do oceny wewnętrznej, aby pomóc w wymianie z dostawcami. Rosnące znaczenie dostosowywania rodzi problem bezpośredniego AM części, aby powstrzymać się od oprzyrządowania ze związanymi z tym wydatkami w czasie i gotówce.
Części samochodowe: wewnętrzne i zewnętrzne
Projekt wnętrza szczególnie dodaje charakteru pojazdowi, często podpowiadając i wpływając na ostatnią decyzję zakupową. W przeciwieństwie do planu zewnętrznego, na ogół składa się z wielu części, począwszy od dziesiątek dostawców. Większość części jest wreszcie tworzona przez formowanie wtryskowe z tworzywa sztucznego. Dlatego części AM są wykorzystywane głównie do testowania i wprowadzania pomysłów na pojazdy. Niemniej jednak, ponieważ serie stają się coraz mniejsze, a liczba odmian rośnie, coraz więcej części AM jest bezpośrednio wykorzystywanych w ostatecznym samochodzie. Chociaż wszystkie procedury AM można wykorzystać do produkcji wewnętrznych części samochodowych, spiekanie laserowe i polimeryzacja są najlepszym wyborem. Spiekanie laserowe zwykle podpowiada części nadające się do legalnego użytku, podczas gdy części stereolitograficzne lub strumienie polimerowe są zwykle wykorzystywane jako części asowe do opcjonalnej procedury. Specjalne edycje samochodów seryjnych często mają nie tylko mocniejsze silniki, ale także optycznie demonstrują ich osiągi za pomocą elementów zewnętrznych, takich jak spojlery przednie i tylne lub listwy progowe.
Przemysł lotniczy
Ze względu na małe serie i częste specjalne wymagania projektowe swoich klientów, branża awioniki stara się trzymać z dala od narzędzi i idealnie wykorzystuje beznarzędziowe procesy AM. Osiągnięciem do natychmiastowego stworzenia elementów wnętrz lotniczych było przedstawienie ognioodpornego materiału do spiekania laserowego, który obecnie jest dostępny również dla form polimeryzacji i wydalania. Wiele elementów wewnętrznych samolotów nie różni się szczególnie od części wykonanych dla pojazdów. W związku z tym części testowe do zastosowań samochodowych można traktować jako testy do zastosowań lotniczych. Tworzenie form metalowych i ceramicznych umożliwia natychmiastową produkcję specjalistycznych części zarówno ogniwa, jak i silnika.
Przemysł zabawkowy
Mimo że zabawki są również "materiałami konsumpcyjnymi", działalność związana z zabawkami jest zwykle rozpatrywana osobno. Zajmuje się nie tylko różnymi plastikowymi częściami zabawek dla dzieci, ale także coraz bardziej spersonalizowanymi modelami samochodów, samolotów i pociągów, nawet dla dorosłych. Modele te wymagają drobnych subtelności i delikatnego skalowania, dbając o małe subtelności wyjątkowo w przeciwieństwie do większych. W zależności od skali, różne formy AM są bardziej rozsądne niż inne.
Dobra konsumpcyjne
Dziś dobra konsumpcyjne nie tylko muszą spełniać swoje oczekiwane funkcje, ale muszą także podążać za określonym trendem. Powinny być skoncentrowane na potrzebach wyjątkowego spotkania kupujących, w tym preferowanym kierunku struktury. Elementy stylu życia charakteryzują kolejny dobrze zapowiadający się sektor biznesu. Ponieważ sposób życia szybko się zmienia, zaleca się badanie wzorców i testowanie rynku przed pokoleniem. W związku z tym wymagane są modele. Miski, pojemniki, światła i inne coraz bardziej rozjaśniające się przedmioty są ulubionymi przedmiotami twórców, którzy wykorzystują nową możliwość konfiguracji zapewnianą przez AM, aby pokonać ograniczenia geometryczne. Biorąc pod uwagę AM, trójwymiarowa percepcja informacji geodezyjnych będzie stanowić ramę rozwijającej się prezentacji specjalistycznej. W przypadku tego rodzaju modeli, procedura druku 3D firmy Z-Corporation jest cenna, ponieważ części mogą być barwione w sposób ciągły, co pozwala uniknąć pracy ręcznej. Biorąc pod uwagę AM, można stworzyć lepsze podejście do gablotek geodezyjnych. Modele globu przedstawiające część lądową i morską część ziemi z przesadnym skalowaniem linii topograficznych gór i dna oceanu w celu wskazania szczegółów . Aby powierzchownie uformować drobne subtelności, wybrano stereolitografię. Następnie należy zastosować cieniowanie ręczne. Umożliwia klientowi zaaranżowanie preferowanego skalowania. Im bardziej przedmiot zbliża się do jednostki ludzkiej, tym intensywniejsza staje się interakcja między nimi i tym bardziej wymagane są indywidualne cechy. Aby wyprodukować wymagane części, produkcja form i matryc nie ma już zastosowania. To otwiera ciekawostki dla AMforms, które mogą tworzyć ogromne ilości różnych części w jednej formie, niezależnie od tego, czy każda z nich wyróżnia się indywidualnymi podświetleniami.
Odlewnictwo i odlewanie
Odlewnie wykorzystują procedury AM, aby uzyskać modele i testy późniejszego elementu (obrazowanie 3D) lub aby wykonać centra i wnęki do produkcji. Jeśli wymagana jest tylko część demonstracyjna, można zastosować wszystkie ulepszenia AM. Druk 3D jest preferowany, jeśli część nie jest precyzyjnie ułożona i wymagany jest skromny i szybko dostępny przykład. Poziom aplikacji to szybkie prototypowanie/silne obrazowanie. AM oferuje nowe siły napędowe głównie do rzucania piaskiem i rzucania venture, ponieważ wymagane utracone centra i otwory można wykonać szybko i skutecznie. Ulepszona nieprzewidywalność części AM pozwala na uznanie geometrii, których nie można wykonać fizycznie ani za pomocą specjalnych narzędzi. Ze względu na podstawowe skalowanie części AM, utracone centra i wgłębienia można skutecznie usprawnić. W zastosowaniach związanych z rzucaniem piasku wykorzystuje się spiekanie laserowe lub drukowanie 3D piasku odlewniczego, podczas gdy utracone centra do rzucania spekulacyjnego są tworzone przez polimeryzację rozpuszczalnych lub zdolnych do rozpuszczania termoplastycznych wosków lub gum. Utracone egzemplarze są produkowane z polistyrenu metodą spiekania laserowego. W przypadku penetracji woskiem można również wykorzystać części do drukowania 3D. Ponieważ centra i zagłębienia są wykorzystywane do tworzenia, poziom aplikacji to szybki montaż/bezpośrednie oprzyrządowanie. Utracone centra i przykłady można również wytwarzać przez wlew wosku do silikonowych form nabytych od ekspertów AM. Wszystkie innowacje AM mogą być zastosowane po prawidłowym zakończeniu.
Medycyna
Ludzie to nadal jednostki, które potrzebują indywidualnego leczenia, w tym pomocy dostosowanych do potrzeb, takich jak implanty, epistezy, ortezy (podpory nóg) i inne. Aby uzyskać prawidłowe dopasowanie, informacje 3D należy uzyskać za pomocą procedur obrazowania odtwórczego, na przykład zarejestrowanej tomografii komputerowej lub ultradźwiękowej. Typową konfiguracją dla obrazów terapeutycznych jest DICOM. Nadzwyczajne programowanie umożliwia określenie rozsądnego limitu i reprodukcję 3D, która daje założenie wielu informacji w standardowym języku trójkątów (STL), które można przygotować w dowolnej maszynie AM. Ze względu na doskonałą jakość powierzchni i generowanie punkt po punkcie, stereolitografia laserowa i latanie polimerami są idealnie wykorzystywane do tworzenia modeli odtwórczych, na przykład czaszek i innych ludzkich struktur kostnych. Wewnątrz pustych struktur, na przykład, za pomocą tych zabiegów można najlepiej odtworzyć zatokę czołową lub filigranową strukturę kości podczaszkowej. W każdym razie spiekanie laserowe, drukowanie 3D, połączone wytwarzanie warstw (wyrzucanie, modelowanie osadzania stopionego (FDM)) lub wytwarzanie nakładek warstwowych (LLM) również przenoszą modele medyczne i są tak często wykorzystywane z tego powodu. Do spiekania i FDM dostępne są wyjątkowe, potwierdzone materiały do wykorzystania odtwórczego, które można zdezynfekować. Druk 3D otwiera interesujące możliwości przed anaplastologami i różnymi ekspertami, którzy wytwarzają wyłącznie uformowane części do rozstrzygającego rzutu. Informacje o brakujących narządach lub częściach narządów są pobierane z obrazowania rekonstrukcyjnego, przerabiania 3D, a następnie demonstracji 3D poprzez programowanie, na przykład sensowne. Ta informacja jest idealnie oparta na refleksji. Idealny podrobiony narząd musi być dostosowany niezależnie do okoliczności każdego pacjenta. Aby skrócić ten system i umożliwić anaplastologowi skupienie się na ich centralnych zdolnościach, ustrukturyzowaną część wykonuje się za pomocą drukowania 3D.
Architektura i architektura krajobrazu
Architekci zwykle prezentują swoje pomysłowe myśli za pomocą modeli w skali. Ponieważ pracują z projektami konfiguracji 3D, informacje 3D wymagane dla AM są łatwo dostępne, a tworzenie modeli można zasadniczo poprawić, wykorzystując modele AM lub komponenty modelu. Bardzo złożona, cienkościenna konstrukcja o swobodnym kształcie nie mogła być wykonana przy pomocy tradycyjnego modelarstwa, ale musi być zbudowana przy użyciu AM. Spiekanie laserowe zostało wybrane, aby stworzyć drobiazgowy model, gwarantujący funkcjonalny stopień wytrzymałości, który chroni go przed uszkodzeniem przez kontakt. Chociaż elementy w postaci bloków były spiekane, można je było również wytwarzać ogólnie przez przetwarzanie wzdłuż tych linii, co czyni je domniemanym modelem mieszanki. Model został w zasadzie wykorzystany do otwartego wprowadzenia do zadania. Poza wyświetlaniem pojedynczych struktur lub ich części, rozwijającą się aplikacją jest tworzenie modeli domów, miast i scen. Wiele z nich wymaga cieniowania, aby zwrócić uwagę na zalety inwestycji lub pokazać kamienie milowe. Informacje mogą być pozyskiwane z aGIS lub bardzo dobrze mogą być odseparowane od Internetu, na przykład z Google Earth lub centrum dystrybucji 3D i pokazane w 3D z wykorzystaniem różnych form AM. AM może między innymi przedstawiać trójwymiarowe prezentacje każdego domu, starej dzielnicy lub witryny towarzysza, rzucających się w oczy konstrukcji, rusztowań, a to tylko wierzchołek góry lodowej.
Różne materiały stosowane w AM
Obecnie AM pozwala na obróbkę materiałów każdej klasy materiałów, w szczególności tworzyw sztucznych, metali i ceramiki. Spiekanie tworzyw sztucznych i metali można postrzegać jako szeroko stosowane standardowe procedury, podczas gdy formy do usuwania metali lub materiałów wypełnionych gliną są nadal opracowywane. Ilość różnych materiałów w każdej klasie materiałów jest nadal bardzo ograniczona, chociaż w ostatnich latach liczba ta wzrosła całkowicie i stale rośnie dzięki międzynarodowej działalności badawczej. Celem ustalonej liczby materiałów jest to, że w zasadzie wymagane jest synchroniczne zaawansowanie materiału i procedury. Na przykład materiał do spiekania laserowego tworzyw sztucznych nie może być wyłącznie lokalnie topliwy, ale łatwy do ponownego powlekania, co wymaga dostosowania krawędzi.Dodane substancje i subtelności procedury, na przykład ochrona gazu i podgrzewanie, tłumienie zanikania sąsiedztwa, utlenianie i inne efekty międzyprocesowe i interakcje ze środowiskiem. To jedna z przyczyn, dla których materiały proszkowe do spiekania laserowego nie są takie same jak proszki do pokrywania spiekanego, mimo że są bardzo porównywalne pod względem organizacji składu. Głównie dla materiałów do spiekania laserowego tworzyw sztucznych i stereolitografii rozwijają się niezależne rynki. Proszki metali są zasadniczo takie same jak proszki do pokrywania laserowego i spawania i pod tym względem od dawna są doskonałe. Klient może wybierać spośród szerokiego asortymentu, ale musi zakwalifikować proces, który pociąga za sobą zaawansowanie karty informacyjnej materiału. Z drugiej strony można wykorzystać materiały dopuszczone przez producenta maszyny, akceptując ograniczoną liczbę materiałów i poziom wartości. Niektóre kwestie związane z AM są stopniowo wyjaśniane i pojawiają się w zasadzie podczas asemblacji, ponieważ obecnie nie ma długoletniego doświadczenia w AM. Najważniejszymi problemami są dojrzewanie i stabilność UV w przypadku tworzyw sztucznych i korozja, pogorszenie, sedymentacja i utlenianie w przypadku proszków metali, a także pory i wtrącenia we wszystkich procesach AM. Rysunek przedstawia rodzaje materiałów stosowanych w AM o różnych zastosowaniach dla różnych produktów.
Tworzywa sztuczne
Tworzywa sztuczne były pierwszą grupą materiałów przetwarzanych przez AM i nadal dostarczają największą część materiałów. Materiałami do stereolitografii są gumy akrylowe lub epoksydowe, które muszą wspomagać polimeryzację fotograficzną. Dziś przyczepne i kruche materiały z połowy lat 90. zastępują materiały naśladujące materiały do formowania wtryskowego tworzyw sztucznych. Udało się to osiągnąć poprzez wypełnienie smoły nanocząstkami w celu uzyskania odchylenia temperatury i zabezpieczenia mechanicznego. Co więcej, różnorodność materiałów została rozszerzona i zawiera teraz proste i nieproste, wszechstronne, utwardzone i wiele coraz bardziej zróżnicowanych materiałów. Do spiekania laserowego tworzyw sztucznych preferowanymi materiałami są poliamidy. Pomimo faktu, że poliamidy są jedną z najbardziej znanych rodzin materiałów termoplastycznych do formowania infuzyjnego, co daje zaufanie do tego materiału, poliamidy AM i te używane do kształtowania infuzji tworzyw sztucznych zasadniczo kontrastują ze sobą. Wypaczanie i zniekształcenie były poważnymi problemami we wczesnych dniach AM, jednak obecnie są one ograniczone do minimum dzięki podgrzewaniu wstępnemu i ulepszonym strategiom skanowania. Dostępny jest obszerny i stopniowo rozszerzający się asortyment materiałów proszkowych na bazie poliamidu do spiekania laserowego. Obejmuje to właściwości ognioodporne, wypełnione aluminium, które można sterylizować. Lepsze właściwości mechaniczne zapewniają proszki napełnione szkłem, chociaż termin ten jest mylący, ponieważ w celu umożliwienia ponownego powlekania wykorzystuje się koła i cząstki uformowane w ziarna ryżu, a nie pasma. Dają one wyższą wytrzymałość w przeciwieństwie do właściwości bez wypełnienia, ale nie osiągają właściwości, które mogą być normalne w przypadku materiałów formowanych infuzyjnych wypełnionych włóknem. Obecnie przynajmniej każdy poziom jest reprezentowany przez AMmateriał i procedurę, poza stopniem materiałów irydyzowanych. Poliimidy są niezwykle fascynującym zbiorem wyjątkowo wytrzymałych i odpornych na ciepło i chemikalia polimerów, które byłyby naprawdę atrakcyjne do wykorzystania jako materiały AM.
Metale
Najczęściej stosowanymi technikami dla AMof metali są spiekanie w odmianie selektywnego topienia laserowego i stapiania. Materiał występuje w postaci proszku o zasadniczej wielkości cząsteczek 20-30 mm. Ponieważ odległość słupa lasera w poprzek, grubość warstwy i szerokość toru są w podobnym zakresie rozmiarów, struktura kontrolna na górze jest nie do pomylenia. Materiały są zasadniczo takie same jak materiały używane do pokrywania laserem lub spawania z materiałem wypełniającym. Chociaż można stosować różne proszki sprzedawane na rynku, należy wziąć pod uwagę, że zdolność materiału musi być wykonana lub ewentualnie oceniane we własnym zakresie. Z drugiej strony, proszki dostarczane przez producentów maszyn AM towarzyszą arkuszom informacji o materiałach w zależności od zademonstrowanych parametrów, które również konsolidują zaawansowane procedury wyjściowe. W przypadku AM metali dostępna jest stal hartowana, stal aparatowa, związki CoCr, tytan, magnez, aluminium, a także cenne metale, takie jak złoto i srebro. Zakres materiałów metalowych jest znacznie szerszy, a ich właściwości znacznie lepiej niż tworzywa podszywają się pod materiały stosowane do montażu konwencjonalnego.
Ceramika
AM z wykorzystaniem materiałów ceramicznych jest jednak uzależniony od specjalizacji w zakresie zaawansowania wytwarzania warstw. Materiały są dostępne w całym zakresie produkcji wyrobów ceramicznych, na przykład tlenek glinu, Al2O3; dwutlenek krzemu lub krzemionka, SiO2; tlenek cyrkonu lub cyrkon, ZrO2; węglik krzemu, SiC; oraz azotek krzemu, Si3N4. Przedmioty to pełna ceramika, głównie z kanałami przepływowymi i konstrukcjami obciążonymi wysoką temperaturą, na przykład wymiennikami ciepła. Charakterystyczne porowatości o dużej skali, które pomagają w łączeniu wkładek, są niezwykłym celem sprzedaży wchłanialnej bioceramiki. Porowatości na małą skalę zachęcają do wytwarzania mikroreaktorów.
Kompozyty
Kompozyty w sensie lekkich wzmocnionych struktur są mało znane w AM. Składają się one z więcej niż jednego materiału i podobnie można je traktować jako materiały recenzowane. Kompozyty są zwykle używane do wytwarzania lekkich przedmiotów, które mają jednolitą strukturę i są izotropowe, a jeśli nie, izotropowe pod scharakteryzowanymi krawędziami obciążenia. Ogólnie rzecz biorąc, produkcja laminatów warstwowych może tworzyć części kompozytowe o skoordynowanych pasmach lub teksturach, jeśli te wzmocnienia są dostępne jako prepregi lub poziome półwykończone materiały, które można zintegrować z procesem. Specjalnie dostosowany proces wytwarzania wzmocnionych zakrzywionych części z włókna ceramicznego (SiC) pozwala uniknąć cięcia włókien. Może układać warstwy pod charakterystycznymi, ale różnymi krawędziami, aby dostosować konstrukcję do normalnego obciążenia. Ponadto część może mieć (nieco) zagiętą powierzchnię, aby wykonać podstawowe elementy i zachować strategiczną odległość od stopni schodów równoległych do terenu hałdy.
Globalna ewolucja AM
Obecnie wokół branży druku 3D (lub AM) toczy się wiele dialogów. Jest on regularnie łączony z mechaniczną autonomią, cyfryzacją i ogromną ilością informacji w ramach wizji "Przemysłu 4.0" lub "czwartej rewolucji przemysłowej", jako przyszłej fabryki. Taka jest intensywność medialnych zaawansowanych marzeń o drukowanej w 3D przyszłości. Jednak ogół społeczeństwa jest ignorantem, że druk 3D nie jest niczym nowym. Innowacja istnieje od bardzo dawna - podstawowe ramy biznesowe były dostępne pod koniec lat 80-tych. Rysunek przedstawia ewolucję AM z perspektywy globalnej.
Wczesne etapy
Współczesne badania systemowe proponują, aby w cyklu istnienia przedsięwzięć wyróżnić cztery fazy - wprowadzenie, wzrost, dojrzałość i upadek. Okres początkowy jest opisywany przez małą sprzedaż, niskie stopy penetracji rynku, wysokie koszty i niską jakość. AM zainwestowała w tę fazę sporo czasu, a granice rozwoju obejmowały postęp w całej branży, który był utrudniony przez ograniczenia patentowe i trudności z obniżeniem kosztów maszyn.
Etapy wzrostu
SektorAM znajduje się obecnie w fazie wzrostu. Na tym etapie obserwuje się szybką infiltrację rynku w miarę spadku kosztów. Raport Wohlera z 2018 r. mówi nam, że światowe przychody z produktów AM w 2017 r. wyniosły łącznie 3,133 mld USD, co stanowi wzrost o 17,4% w porównaniu z 2,669 mld USD w 2016 r. Mało kto kwestionowałby, że branża się rozwija i to w szybkim tempie. Ogromne roczne przyrosty przychodów wciąż przyciągają entuzjazm z różnych działów (finanse, produkcja). Dla niektórych firm etap wzrostu wynika ze standaryzacji innowacji (ułatwienie transakcji i rozpowszechniania oraz tworzenie ekonomii skali w toku). AM obejmuje wiele procedur (wytłaczanie materiału, strumieniowanie materiału, strumieniowanie spoiwa, laminowanie arkuszy, fotopolimeryzacja w kadzi, fuzja w łożu proszkowym, ukierunkowane osadzanie energii) i materiałów (polimery, metale, ceramika, kompozyty i inne). Na przykład, tworzenie metalowych implantów dentystycznych jest napędzane przez proces syntezy w łożu proszkowym (selektywne topienie laserowe) wykorzystujący tytan. Na tym etapie wzrostu, AMbusiness szybko się profesjonalizuje. Nie oznacza to, że firma nie była biegła we wczesnej fazie, raczej rozmiar i zakres działalności firmy wzrasta i wymaga wkładu usług wspierających, takich jak zasoby ludzkie i zarządzanie biznesem. Wiele firm AM jest kontrolowanych przez specjalistów, którzy założyli te organizacje. Oczywiście, organizacje te są wspierane przez przedsiębiorców. Obecnie coraz częściej obserwujemy napływ talentów biznesowych i menedżerskich z innych sektorów, które wypełniają ważne role w kierownictwie wyższego szczebla, operacjach łańcucha dostaw i konsultingu.
Etapy dojrzałości
Podczas gdy elementy dojrzałości można dostrzec wAM, na przykład w takich zastosowaniach jak części zamienne i prototypowanie, ogólne działy biznesowe wciąż pozostają nieruchomo w fazie wzrostu. Punktem zwrotnym będzie prawdopodobnie szersze wykorzystanie osiągnięć AM w produkcji masowej. W każdym razie wydaje się, że AM nie da się dopasować do istniejących modeli rozwoju przemysłu. Na przykład, etap dojrzałości jest przedstawiany przez efektywność kosztową poprzez siłę kapitałową, biegłość skali i niskie koszty wejściowe. Jest mało prawdopodobne, aby dotyczyło to AM, ponieważ w rzeczywistości użyteczność i zastosowanie AM w produkcji jest sprzeczne z tym rozumieniem logiki projektowania i produkcji. AM nie wyprze zwyczajowych rodzajów produkcji (formowanie wtryskowe, metody subtraktywne), będzie je uzupełniać. Co więcej, opiera się na modelu biznesowym, który w szerszym ujęciu uwzględnia wartość i oszczędność kosztów. W fazie dojrzałości obserwuje się dodatkowo przenoszenie produkcji, najpierw do krajów nowo uprzemysłowionych, a następnie do krajów rozwijających się. AM może ewentualnie drastycznie zmienić sposób wytwarzania przedmiotów i miejsce ich wytwarzania. Minie jeszcze sporo czasu zanim przemysł AM dojrzeje. Musimy ponownie przemyśleć, czym jest "dojrzałość" przemysłu dla segmentu AM i jego wpływ na produkcję oraz dla osób obserwujących rozwój części. Jak na razie istnieje niewiele ostatecznych danych dotyczących części AM. Gdy AM osiągnie dojrzałość, większe i swobodnie dysponowane firmy będą się rozwijać. To da więcej informacji na temat sprzętu, materiałów i sprzedaży usług, głębsze zrozumienie korzyści. W zasadzie biznes AM realizował do tej pory konwencjonalny kierunek rozwoju przemysłu. Niemniej jednak, w miarę osiągania dojrzałości, AM prawdopodobnie rzuci wyzwanie modelom. Tradycyjne rozumienie różnych komponentów wymaganych do rozwoju firm powinno się zmienić, zwłaszcza, że rozszerzający się wybór AM podobnie zmieni rozwój tych przedsięwzięć, w których jest on stosowany. jest stosowany.
Przyszły kierunek rozwoju AM
AM jest nową technologią, która jest bardzo bliska stania się pełnoprawną metodą wytwarzania metodą wytwarzania. W tej chwili, jeśli część została zaprojektowana np. do frezowania, to nie ma nie ma sensu drukować jej w 3D (wyższy koszt, gorsza jakość). Potrzebny jest nowy zestaw narzędzi, aby zbadać co można uzyskać z AM, potrzebna jest metoda projektowania, która pozwoli wygenerować najbardziej optymalny, lekki projekt. Tego nie da się zrobić ręcznie. W przyszłości. pojawią się procedury komputerowe, które pozwolą Ci tylko ustalić ramy i pozwolą i pozwolić, aby problem został rozwiązany za Ciebie. Ta metoda wykracza daleko poza optymalizację. Projektowanie generatywne wykorzystuje sztuczną inteligencję do generowania najlepszego możliwego obiektu i dostarcza projekt, który jest najbardziej optymalny dla druku. Skraca to proces projektowania z tygodni lub miesięcy do godzin. Wspaniałą częścią tego nowego oprogramowania jest to, że nie potrzeba już żadnych eksperci nie są już potrzebni. W ten sposób, podstawowe zrozumienie będzie nadal wymagane w przyszłości, ale projektowanie inżynierskie będzie dostępne dla szerszego grona osób. Patrząc na wzrost znaczenia projektowania generatywnego, nie jest zaskoczeniem, że 90% przychodów w Segment oprogramowania do druku 3D pochodzi z oprogramowania do projektowania. To jest dokładnie to, gdzie wartość będzie w przyszłości. Gdy druk 3D będzie już dobrze rozwinięty, a metody produkcji wszystkie metody są równe, wygra osoba, która zaprojektuje najlepszy produkt.
Wnioski
Podsumowując, AM otwiera nowe możliwości dla projektowania i wytwarzania w różnych przedsiębiorstwach. W porównaniu z tradycyjnymi technikami, coraz bardziej złożone struktury i geometrie mogą być osiągnięte przy użyciu niestandardowego projektowania, większej wydajności, wyższej wydajności i lepszego zrównoważenia środowiskowego. AM odgrywa ważną rolę w przemyśle. Technologie AM wkrótce doprowadzą do kolejnej wielkiej rewolucji przemysłowej. AM odgrywa kluczową rolę w Przemyśle 4.0, oszczędzając czas i koszty, decydując o wydajności procesu i zmniejszając jego złożoność, umożliwiając szybkie prototypowanie i wysoce zdecentralizowane procesy produkcyjne. Dlatego w innowacji obserwuje się rozszerzoną recepcję przeszłości prototypowania i oprzyrządowania w kierunku generowania części końcowych i dodatkowych. AM ma zatem do wykonania istotne zadanie w zakresie technik montażu. Firmy mogą wdrożyć do ewolucji swoich produktów w odpowiedzi na potrzeby rynku. Co ważne, wraz z ciągłym doskonaleniem innowacji, AM zmienia się z problematycznej innowacji wykorzystywanej wyłącznie przez pionierów do typowej strategii tworzenia centrów
Przetwarzanie w chmurze w rewolucji przemysłowej 4.0
Przemysł również ewoluował znacznie od 1700 roku. Od XVIII wieku nastąpiły cztery rewolucje przemysłowe. Pierwsza rewolucja przemysłowa w 1780 roku dotyczyła silników parowych, przemysłu tekstylnego i inżynierii mechanicznej. Drugi w 1840 r. dotyczył przemysłu stalowego. Trzecia w 1900 r. dotyczyła elektryczności i samochodów, podczas gdy czwarta rewolucja przemysłowa dotyczyła branży IT i ogólnie przyjmuje się, że czwarta rewolucja przemysłowa dopiero się rozpoczęła. W związku z tym termin "Przemysł 4.0" został przypięty przez rząd niemiecki w 2011 roku. Przemysł 4.0 lub czwarta rewolucja przemysłowa dotyczy Internetu rzeczy i usług (IoTS), systemów cyber-fizycznych (CPS) oraz interakcji i wymiany dane za pośrednictwem Internetu lub chmury obliczeniowej. W 1960 roku jeden system może jednocześnie wykonywać tylko jedno zadanie. Wiele systemów potrzebnych do jednoczesnego uruchamiania wielu zadań. Przechodząc do obecnego roku 2022, jeden system może wykonać wiele zadań w ciągu kilku sekund. Taka technologia jest osiągana dzięki postępom naukowym, takim jak Internet, usługi sieciowe, Internet rzeczy i przetwarzanie w chmurze. Podobnie jak rewolucje przemysłowe, nastąpiło kilka ulepszeń i postępów w zakresie obliczeń, przetwarzania i dostępu do przechowywanych danych. Ewolucję informatyki przedstawiono na rysunku

Chmura obliczeniowa
'Przetwarzanie w chmurze to dostarczanie na żądanie zasobów IT, takich jak dane, przechowywanie i zasilanie przez Internet, zamiast kupowania, posiadania i utrzymywania fizycznych centrów danych i serwerów''. W uproszczeniu przetwarzanie w chmurze to dystrybucja lub dostarczanie rezerw między sobą za pomocą Internetu
.
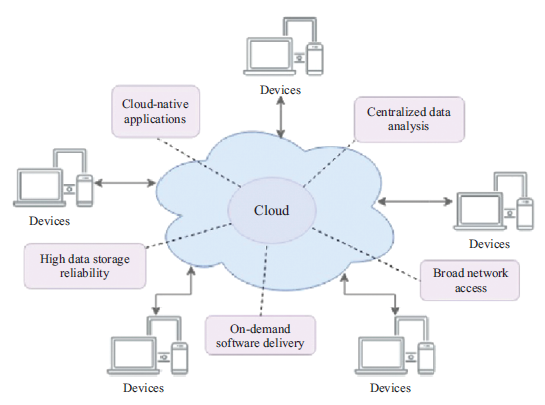
Każde małe, średnie, duże przedsiębiorstwa, organizacje, firmy, branże i fabryki używają przetwarzania w chmurze do różnych celów, takich jak przechowywanie danych, tworzenie kopii zapasowych danych, analiza danych, poczta e-mail, maszyny wirtualne (VM) i aplikacje internetowe to tylko niektóre
Korzyści z przetwarzania w chmurze
Każda branża, organizacja i firma korzysta z przetwarzania w chmurze. Nawet osoby fizyczne, wiedząc lub nie, korzystają z przetwarzania w chmurze. Cloud computing stoi za usługą online, usługą e-mail, transmisją strumieniową, grami, przechowywaniem w chmurze itp. Ogólne korzyści z przetwarzania w chmurze obejmują następujące funkcje. Agility - szybki dostęp do zasobów, instalacja i konfiguracja nowych technologii w ciągu kilku minut. Elastyczność - skalowanie zasobów w zależności od potrzeb. Marnotrawstwo zasobów lub opóźnienia w podejmowaniu decyzji są ograniczone. Oszczędność kosztów - dużą kwotę można zaoszczędzić na wydatkach kapitałowych i przekierować na wydatki zmienne. Możliwość rozbudowy - biznes można łatwo rozszerzyć na nowe usługi naziemne, aby dotrzeć do użytkowników końcowych. Produktywność - można odrzucić wymagania czasowe związane z konfiguracją sprzętu i oprogramowania w nowej lokalizacji. Wydajność - usługi przetwarzania w chmurze zmniejszają opóźnienia w sieci niż tradycyjna konfiguracja sieci lokalnej. Niezawodne przetwarzanie w chmurze podlega regularnej konserwacji, takiej jak tworzenie kopii zapasowych danych i dublowanie danych, dzięki czemu dane użytkownika można odzyskać nawet w przypadku awarii. Bezpieczeństwo - dostawcy usług w chmurze oferują zestaw zasad i mechanizmów kontrolnych, które chronią dane użytkownika przed zagrożeniami
Rodzaje przetwarzania w chmurze
Usługi w chmurze są dostarczane konsumentom w oparciu o różne architektury przetwarzania w chmurze. Trzy główne architektury przetwarzania w chmurze to:
Chmura publiczna - chmury publiczne są dostarczane i obsługiwane przez zewnętrznego dostawcę. Dostarczają swoje zasoby i zasoby swoich partnerów, na przykład Microsoft Azure. Zapewniają wsparcie IT w zakresie sprzętu i oprogramowania. Użytkownik może uzyskać dostęp do tych wsparcia za pomocą aplikacji lub przeglądarki internetowej.
Chmura prywatna - chmury prywatne są dostarczane, obsługiwane i utrzymywane przez jedną organizację. Zasoby znajdują się w siedzibie organizacji. Dostęp do niego mają tylko jego oddziały zlokalizowane w różnych miejscach geograficznych.
Chmura hybrydowa - chmury hybrydowe to połączenie chmury publicznej i prywatnej. Na przykład, gdy organizacja pobiera dane ze swojej chmury prywatnej i udostępnia dane do swojej chmury prywatnej z chmury publicznej, nazywa się to chmurą hybrydową.
Rodzaje usług w chmurze
Usługi przetwarzania w chmurze są ogólnie podzielone na trzy główne kategorie. Są to infrastruktura jako usługa (IaaS), platforma jako usługa (PaaS) i oprogramowanie bezserwerowe jako usługa (SaaS). IaaS to najbardziej podstawowa usługa w chmurze. Oferuje infrastruktury IT, takie jak serwery, maszyny wirtualne, dedykowany sprzęt, pamięć masowa i sieci. Zapewnia wysoki poziom elastyczności w biznesie IT. PaaS to usługa skierowana do programistów IT. PaaS oferuje programistom środowisko do tworzenia, testowania i zarządzania aplikacjami, w których infrastruktura IT na miejscu nie ma znaczenia. Dzięki SaaS dostawca usług w chmurze zarządza i utrzymuje całą infrastrukturę IT związaną ze sprzętem i oprogramowaniem oraz zapewnia użytkownikowi końcowemu w pełni rozwinięty produkt przez Internet. Wraz z postępem technologicznym w ostatniej dekadzie przetwarzanie w chmurze stało się bardziej zaawansowane i nastąpiło podróż w kierunku użytkownika końcowego poprzez inne formy przetwarzania, takie jak przetwarzanie mgły i przetwarzanie brzegowe. Te dwa są podzbiorami przetwarzania w chmurze.
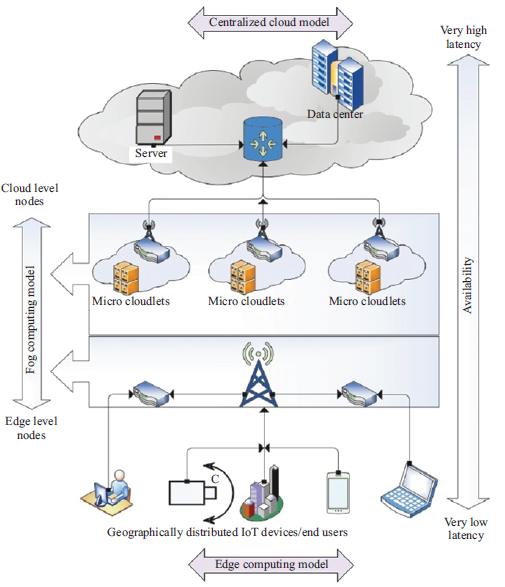
Ponieważ zarówno mgła, jak i przetwarzanie brzegowe wykorzystują pośredni poziom przetwarzania i przechowywania, konsumenci używają go zamiennie. W przypadku przetwarzania mgły sieć lokalna działa jako brama, podczas gdy przetwarzanie odbywa się na inteligentnych urządzeniach za pomocą programowalnych sterowników automatyki w obliczeniach brzegowych
Fog computing
W przeciwieństwie do scentralizowanego przetwarzania w chmurze, zdecentralizowane przetwarzanie, w którym zasoby są przechowywane w logicznych lokalizacjach między miejscem narodzin danych a chmurą, określane jest jako mgła obliczeniowa. Przetwarzanie mgły zmniejsza wymaganą przepustowość w porównaniu z przetwarzaniem w chmurze, tworząc sieć o niskim opóźnieniu.
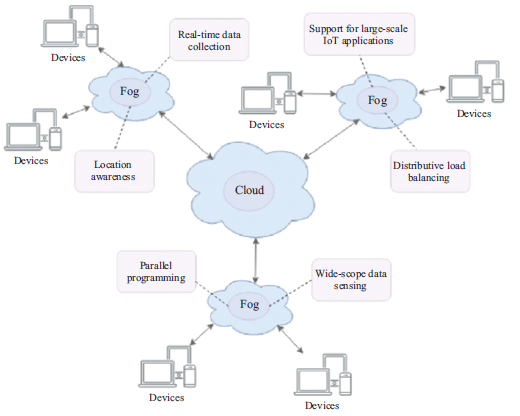
Fog computing jest stosowany w samojezdnych samochodach, w których dane są przesyłane do producent do diagnostyki i konserwacji, inteligentnych miast i sieci elektrycznych, w których systemy użyteczności publicznej muszą działać wydajnie, analizy w czasie rzeczywistym, w których odbywa się podejmowanie decyzji. Wadą przetwarzania mgły jest to, że w dużym stopniu opiera się na transporcie danych, co z kolei wymaga szerokopasmowego lub szybkiego dostępu do Internetu.
Przetwarzanie brzegowe
Każdy rodzaj przetwarzania, który jest wykonywany w źródle lub bardzo blisko źródła, jest określany jako przetwarzanie brzegowe. Zmniejsza również opóźnienia i wykorzystanie przepustowości. Klasycznym przykładem wyjaśniającym przetwarzanie brzegowe byłaby kamera wyposażona w czujnik wykrywania ruchu. Ten typ kamery wykonuje wewnętrzne obliczenia, nagrywa i wysyła materiał na serwer tylko w przypadku wykrycia ruchu. Wykorzystuje mniejszą przepustowość i pamięć masową. Natomiast kamera bez czujnika wykrywania ruchu nagrywa wideo przez bardzo długi czas, wykorzystuje dużą przepustowość i większą pamięć masową. Przetwarzanie brzegowe charakteryzuje się niskim zużyciem serwera, opóźnieniami i dodatkową funkcjonalnością. Przetwarzanie brzegowe ma również wadę. Jest bardziej podatny na złośliwe ataki i potrzebuje dodatkowego lokalnego sprzętu. Porównanie chmur, mgły i krawędzi na ich cechach przedstawiono w tabeli
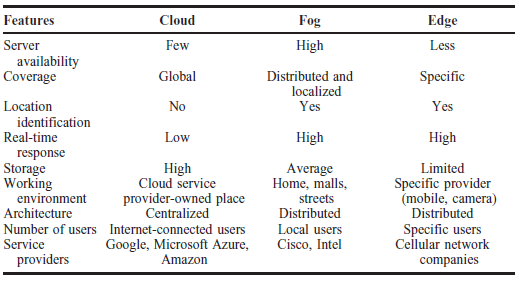
Kwestie bezpieczeństwa i prywatności
Szybki rozwój technologii otworzył nowy wymiar technologii przechowywania danych. W ostatnim czasie pamięć masowych danych wzrosła z formy fizycznej do formy wirtualnej. Istnieją pewne spory dotyczące wirtualnych centrów danych dotyczących ich prywatności, bezpieczeństwa, wydajności, kopii zapasowych i kosztów. W tej sekcji opisano problemy z zabezpieczeniami i rozwiązania dotyczące przetwarzania w chmurze, mgły i przetwarzania brzegowego. Niektóre typowe ataki na komputery to odmowa usługi - wysyłanie ogromnej liczby wiadomości do sieci w celu uwierzytelnienia z nieprawidłowego adresu zwrotnego, aby uniemożliwić innym dostęp do sieci, wstrzykiwanie złośliwego oprogramowania w chmurze - wstrzykiwanie złośliwego oprogramowania lub maszyny wirtualnej do serwera, atak typu side-channel - inżynieria wsteczna kryptografii urządzenia, przejmowanie sesji - przechwytywanie i przejmowanie sesji użytkownika, podsłuchiwanie - nielegalny użytkownik ukrywa swoją obecność i monitorowanie autoryzowanego użytkownika, manipulowanie danymi - manipulowanie danymi podczas komunikacji lub przechowywania oraz przechwytywanie komunikacji - nielegalny użytkownik wykorzystywanie komunikacji między dwoma legalnymi użytkownikami
Przetwarzanie w chmurze w rewolucji przemysłowej 4.0
Platforma oparta na chmurze odgrywa ważną rolę w rewolucji przemysłowej 4.0 (IR 4.0), łącząc Internet i dział produkcji. Chmura może zintegrować kilka CPS i usług cyfrowych w celu wytwarzania fizycznych części lub komponentów w środowisku internetowym. Rudolph i Emmelmann w 2017 roku przedstawili koncepcję wykorzystania chmury obliczeniowej w produkcji addytywnej w ramach IR 4.0. Opracowali strukturę i zintegrowany algorytm, w którym kluczowymi elementami są przygotowanie danych, wytwarzanie przyrostowe, przetwarzanie końcowe i dostarczanie. Zgodnie z ramami klient może przesłać geometrię wymaganej części przez Internet w formacie STL lub CAD, co jest uważane za domyślny format dla wytwarzania przyrostowego. Projekty, objętość, wymiary, materiał, liczba sztuk, wytyczne i wymagania przesłanej geometrii są dokładnie sprawdzane przez producenta. Uwzględniono również koszt materiałów, koszt produkcji, przetwarzanie wstępne i końcowe. Wstępne przetwarzanie obejmuje przygotowanie danych i konfigurację maszyny.
Obróbka końcowa obejmuje obróbkę cieplną, cięcie drutu, piaskowanie i usuwanie konstrukcji wsporczych. Na ich podstawie powstaje automatyczna wycena lub oferta. Klient może go zaakceptować lub odrzucić. Wdrożenie tych ram w branżach produkcyjnych zapewni znaczny wzrost efektywności realizacji zamówień. Ta struktura obsługuje również funkcję, dzięki której klient może przeglądać i śledzić status swojego zamówienia przez Internet. W 2019 r. O′Donovan i in. porównali opóźnienia i niezawodność interfejsów cyber-fizycznych w aplikacjach inżynierskich Industry 4.0 z wykorzystaniem przetwarzania w chmurze i mgły. Ich badania koncentrowały się na zdecentralizowanej inteligencji, bliska wydajność w czasie rzeczywistym, prywatność danych przemysłowych, otwartość i interoperacyjność. W swoim badaniu wykorzystali podstawowe i standardowe konfiguracje CPS w chmurze i mgle. Komputer testowy został skonfigurowany do obsługi JMeter, który został skonfigurowany z parametrami do wysyłania, odbierania i mierzenia transmisji zachodzących między każdym CPS. Na potrzeby tego badania utworzyli tymczasową sieć lokalną za pomocą routera Huawei z dwoma podstawowymi urządzeniami: (a) komputerem PC z JMeterem i (b) Raspberry Pi z silnikiem Openscoring, aby umożliwić punktację w czasie rzeczywistym. Po skonfigurowaniu sieci, za pomocą Amazon Web Services, skonstruowano oparty na chmurze interfejs cyber-fizyczny. Składał się z jednego wirtualnego procesora, 1 GB pamięci i systemu operacyjnego Linux. Cyber-fizyczny interfejs oparty na mgle został skonstruowany przy użyciu Raspberry Pi3 model B z 64-bitowym procesorem ARMv8 1,2 GHz, pamięcią 1 GB, wbudowanymi funkcjami Wi-Fi i systemem operacyjnym Linux. Odkryli, że zdecentralizowana, lokalna, autonomiczna topologia mgły może zapewnić większą spójność, prywatność, niezawodność i bezpieczeństwo dla aplikacji Przemysłu 4.0 niż chmura. Stwierdzono, że różnica w opóźnieniu między chmurą a mgłą waha się od 67,7% do 99,4%. Ponadto interfejs mgły wykazał 0% wskaźnik awaryjności i interfejs chmury z 0,11%, 1,42% i 6,6% przy różnym poziomie obciążenia. Doszli do wniosku, że aplikacje inżynierskie wymagające surowej wydajności mogą korzystać z przetwarzania w chmurze, podczas gdy aplikacje wymagające spójnego i niezawodnego wykonywania w czasie rzeczywistym mogą korzystać z obliczeń mgły. Niedawny systematyczny przegląd literatury dotyczący 77 artykułów wykazał pozytywny związek między przetwarzaniem w chmurze a łańcuchem dostaw. Mówiąc dokładniej, przetwarzanie w chmurze ma silny wpływ na integrację łańcucha dostaw, zwłaszcza na tworzenie i przepływy fizyczne. Stwierdzono również, że w przyszłości potrzebne są dalsze badania w zakresie projektowania, finansów, zakupów i integracji magazynów, aby lepiej zrozumieć relacje w chmurze obliczeniowej i integracji łańcucha dostaw. Khayer. przeprowadził badanie na temat adaptacji przetwarzania w chmurze i jego wpływu na wydajność małych i średnich przedsiębiorstw (MŚP) przy użyciu dwuetapowego podejścia analitycznego, łączącego modelowanie równań strukturalnych i sztuczne sieci neuronowe. Ich badanie ujawniło, że jakość usług, postrzegane ryzyko, wsparcie najwyższego kierownictwa, wpływ dostawców chmury, lokalizacja serwera, wydajność komputera i odporność na zmiany mają silny wpływ na przyjęcie przetwarzania w chmurze w MŚP. Odkryli również, że przetwarzanie w chmurze ma pozytywny wpływ na wydajność MŚP. Ooi przeprowadził krótkie badanie, w jaki sposób przetwarzanie w chmurze może wylądować w innowacyjności i wyniki firmy w przemyśle wytwórczym, proponując 11 hipotez. (1) Oczekiwana wydajność ma pozytywny wpływ na innowacyjność, (2) Oczekiwany wysiłek ma pozytywny wpływ na wyniki firmy, (3) Oczekiwany wysiłek ma pozytywny wpływ na oczekiwane wyniki, (4) Wsparcie najwyższego kierownictwa ma pozytywny wpływ na firmę wydajność, (5) wsparcie najwyższego kierownictwa ma pozytywny wpływ na oczekiwany wysiłek, (6) wielkość firmy pozytywnie wpływa na innowacyjność, (7) wielkość firmy pozytywnie wpływa na wyniki firmy, (8) wielkość firmy pozytywnie wpływa na wysiłek oczekiwanie, (9) chłonność pozytywnie wpływa na innowacyjność, (10) chłonność pozytywnie wpływa na wyniki firmy, (11) innowacyjność pozytywnie wpływa na wyniki firmy. Do prowadzenia badań wykorzystali również modelowanie równań strukturalnych, sztuczną sieć neuronową i metodę najmniejszych kwadratów. Wyniki badań wykazały, że 7 z 11 hipotez zostało popartych. Oczekiwana wydajność, wielkość firmy i chłonność mają pozytywny istotny wpływ na innowacyjność i wydajność firmy. Niektóre MŚP wdrożyły zaawansowane systemy planowania i harmonogramowania (APS) w swoich jednostkach produkcyjnych. Jednak systemom APS brakuje elastyczności. Z tego powodu Liu i in. opracował oparty na chmurze system zaawansowanego planowania i harmonogramowania (CAPS) dla branży produkcji części samochodowych. CAPS zawiera pięć głównych modułów: szablon przypadku branżowego, interfejs użytkownika, podstawowe dane wejściowe, planowanie symulacji w chmurze i dane wyjściowe. Zastosowania CAPS w montażu samochodowym wykazały wysoką jakość planowania, niskie wdrożenie i niskie koszty konserwacji.
Przetwarzanie w chmurze w sektorze komunikacji
Wdrożenie jakości usług (QoS) w komunikacji opartej na chmurze wymaga rozwiązania trzech głównych problemów. Są to (1) współistnienie różnych protokołów bezprzewodowych, (2) interoperacyjność między systemami komunikacyjnymi oraz (3) inżynieria umożliwiająca adaptacyjne działanie fabryki. Aby pokonać te przeszkody, Kunst zaproponował architekturę współdzielenia zasobów, szczególnie w domenie Przemysłu 4.0. Ich architektura CPS miała dwie dodatkowe warstwy, a mianowicie warstwę sieciową i brokera zasobów. Warstwa sieciowa składa się z technologii sieciowych umożliwiających dostęp do chmury. Broker zasobów służy do zarządzania i kontrolowania zasobów sieciowych. Kunnst i in. wykorzystał MATLAB i metodologię oceny systemów firmy WiMAX do oceny i symulacji współistnienia trzech technologii bezprzewodowego Internetu: 5G, 4G i IEEE 802.11. Całkowita symulacja składała się z trzech różnych ruchów. Stanowią one (1) 60% protokołu HTTP do kontroli nadzorczej i akwizycji danych, (2) 20% dostrajania manipulatora opartego na VoIP oraz (3) 20% kontroli jakości produkcji opartej na wideo. Wyniki wykazały, że zarówno metryki opóźnienia, jak i fluktuacji QoS były poniżej progu. Przetwarzanie w chmurze pomaga nie tylko w produkcji i przechowywaniu danych, ale także w komunikacji Prowadząc biznes, zawsze istnieje potrzeba podróży i spotkań. Ze względu na wysokie koszty podróży trzeba znaleźć alternatywną drogę. Badanie Radwana i in. zaprezentowała nowe podejście, które konwertuje bieżące rozmowy wideo 2D na rozmowy wideo 3D przy użyciu przetwarzania w chmurze. Ich nowe podejście zaczyna się od (1) opracowania infrastruktury chmury do obsługi komunikacji wideo przy użyciu infrastruktury chmury OpenStack [29], (2) skonfigurowania połączenia wideo przy użyciu technologii webRTC, (3) przechwycenia wideo za pomocą urządzenia wejściowego wideo oraz (4) Wideo 3D jest tworzone przy użyciu technik przetwarzania obrazu, które można oglądać za pomocą okularów 3D. Radwan wykorzystał VM do przetestowania wydajności połączenia 3D i porównania go z tradycyjnym połączeniem peer-to-peer wideo rozmowy. Wyniki eksperymentów wykazały, że ich podejście zapewniło lepszą wydajność procesora w porównaniu z połączeniami wideo 3D typu peer-to-peer. Co więcej, ich nowe podejście ma lepszy stosunek sygnału do szumu o 0,991 dB w porównaniu do peer to peer.
Cloud computing w służbie zdrowia
Podobnie jak Przemysł 4.0 dla sektora produkcyjnego, poprzez włączenie Internetu Rzeczy (IoT), dużych zbiorów danych i przetwarzania w chmurze, sektor opieki zdrowotnej przechodzi do opieki zdrowotnej 4.0 lub e-zdrowia. Branże opieki zdrowotnej wykorzystują technologię chmury do projektowania i dostosowywania leczenia dla swoich pacjentów. Branża opieki zdrowotnej musi być na bieżąco, ponieważ od czasu do czasu mogą rozwijać się różne choroby. W ostatnim czasie wzrosło wykorzystanie Internetu Rzeczy do łączenia zasobów medycznych i świadczenia skutecznych usług opieki zdrowotnej dla pacjentów. Usługi opieki zdrowotnej generują duże ilości danych. Dane te muszą być przechowywane, przetwarzane i analizowane. W związku z tym zainteresowane strony wolą korzystać z przetwarzania w chmurze w sektorach opieki zdrowotnej. Ale towarzyszy temu problem. Ogromna ilość danych IoT z usług zdrowotnych wymagała obsłużenia przy dłuższym czasie wykonywania, takim jak opóźnienie oczekiwania i czasu realizacji oraz duże wykorzystanie zasobów. Później, w 2018 roku, Elhoseny i in. zaproponował hybrydowy model IoT i przetwarzania w chmurze do zarządzania big data w usługach zdrowotnych. Architektura proponowanego modelu hybrydowego zawiera cztery główne komponenty. Są to urządzenie interesariuszy, żądanie interesariuszy, broker chmury i administrator sieci. Aby ulepszyć wybór maszyn wirtualnych, wykorzystano trzy optymalizatory, a mianowicie algorytm genetyczny, optymalizator roju cząstek i optymalizator roju cząstek równoległych. Przeprowadzono zestaw eksperymentów dotyczących czasu wykonania, przetwarzania danych i wydajności systemu wśród tych trzech optymalizatorów. Wyniki pokazały, że proponowany model hybrydowy przewyższa najnowocześniejsze modele, a wydajność systemu została również znacznie poprawiona o 5,2%. Dokonano przeglądu literatury [37] dotyczącej określenia czynników wpływających na akceptację wdrożenia chmury obliczeniowej w sektorze opieki zdrowotnej. Przeanalizowali 55 artykułów i uzyskali 21 czynników w oparciu o metodę analizy tematycznej. Są to kompatybilność, wsparcie najwyższego kierownictwa, względna przewaga, bezpieczeństwo, złożoność, presja zewnętrzna, wiedza informatyczna, koszty, zaufanie, możliwość testowania, regulacje i wsparcie rządowe, innowacyjność, ekspertyza zewnętrzna, dzielenie się i współpraca, doświadczenia użytkowników, świadomość, wielkość firmy, społeczne wpływ, zadania, wsparcie dostawcy i ciągłość biznesowa.
Artykuły naukowe w chmurze obliczeniowej
Na całym świecie kilku badaczy prowadzi badania nad IR 4.0, jego komponentami i publikuje swoje wyniki. Wyniki te są cytowane przez innych badaczy. Stosunek liczby otrzymanych rocznych cytowań ogółem do oczekiwanej łącznej liczby cytowań w oparciu o średnią w danej dziedzinie nazywa się Field Weighted Citation Impact (FWCI).
Wniosek
Koncepcja rewolucji przemysłowej została zaproponowana w 2011 r. Nawet w 2020 r. koncepcja ta jest nadal popularna, ale nie jest do końca wdrażana globalnie. Rządy i organizacje prywatne powoli rozumieją teorię przetwarzania w chmurze. Rządy rządzące muszą zapewnić uproszczone warunki, które są zarówno zorientowane na rząd, jak i na prywatność, aby zwiększyć liczbę dostawców usług w chmurze, tak aby jakość usług uległa poprawie. Dzięki większej świadomości i wsparciu wkrótce można osiągnąć rewolucję przemysłową 4.0
Cyberbezpieczeństwo w kontekście Przemysłu 4.0: tło, problemy i kierunki na przyszłość
Pojawia się i rozwija się nowa rewolucja zwana Industry 4.0 (I4.0), w której systemy przemysłowe składające się z licznych czujników, siłowników i inteligentnych elementów są połączone i zintegrowane z inteligentnymi fabrykami za pomocą technologii komunikacji internetowej. I4.0 jest obecnie napędzany przełomowymi innowacjami, które obiecują stworzyć możliwości tworzenia nowych wartości we wszystkich głównych sektorach rynku. Cyberbezpieczeństwo jest powszechnym wymogiem w każdej technologii internetowej, dlatego pozostaje głównym wyzwaniem dla użytkowników I4.0. Ten rozdział zawiera krótki przegląd szeregu kluczowych komponentów, zasad i paradygmatów technologii I4.0 dotyczących cyberbezpieczeństwa. Ponadto w tym rozdziale przedstawiono istotne dla branży luki w zabezpieczeniach, zagrożenia, zagrożenia i środki zaradcze wraz z przykładami głośnych ataków (np. BlackEnergy, Stuxnet), aby pomóc czytelnikom docenić i zrozumieć stan wiedzy. Na koniec, rozdział próbuje naświetlić otwarte kwestie i przyszłe kierunki komponentów systemu w kontekście cyberbezpieczeństwa dla I4.0.
Wprowadzenie: tło i motywacja
W odniesieniu do paradygmatów Przemysłu 4.0 (I4.0) coraz więcej firm łączy zakłady i fabryki z Internetem, zwanym również Internetem Przemysłowym, w celu poprawy ich efektywności i wydajności. Kwestie cyberbezpieczeństwa są jednym z najważniejszych wyzwań, którym należy sprostać w przypadku urządzeń przemysłowego Internetu rzeczy (IIoT). I4.0 to aktualny trend technologii automatyzacji produkcji, obejmujący głównie technologie aktywne, takie jak systemy cyber-fizyczne (CPS), Internet ofIntroduction: tło i motywacja. W odniesieniu do paradygmatów Przemysłu 4.0 (I4.0) coraz więcej firm łączy zakłady i fabryki z Internetem, zwanym również Internetem Przemysłowym, w celu poprawy ich efektywności i wydajności. Kwestie cyberbezpieczeństwa są jednym z najważniejszych wyzwań, którym należy sprostać w przypadku urządzeń przemysłowego Internetu rzeczy (IIoT). I4.0 to obecny trend technologii automatyzacji produkcji, obejmujący głównie technologie aktywne, takie jak systemy cyber-fizyczne (CPS), Internet rzeczy (IoT) i
przetwarzanie w chmurze. Przyjmując nowy paradygmat Internetu Rzeczy, ludzie mogą stworzyć inteligentny świat z głównymi osiągnięciami mikroelektroniki i technologii komunikacyjnych. Branża IoT obejmuje również aplikacje (znane również jako IIoT) . IIoT przyjął IoT w celu poprawy produktywności, wydajności, bezpieczeństwa, inteligencja i niezawodność w kontekście systemu połączeń wzajemnych. I4.0 został wymyślony w Niemczech i został wykorzystany do zidentyfikowania nowej propozycji dotyczącej przyszłości niemieckiej polityki gospodarczej po raz pierwszy w 2011 roku. W dzisiejszych branżach istnieje duże zapotrzebowanie na łączność między komponentami, przy jednoczesnym zachowaniu podstawowych potrzeb, takich jak ciągłość działania i wysoka dostępność. Wymaga to nowych, inteligentnych procesów produkcyjnych, lepiej dostosowanych do potrzeb produkcyjnych oraz procesów z bardziej efektywną alokacją zasobów. Rysunek ilustruje rewolucję I4.0, która jest osią czasu ewolucji produkcji i sektora przemysłowego w ogóle.
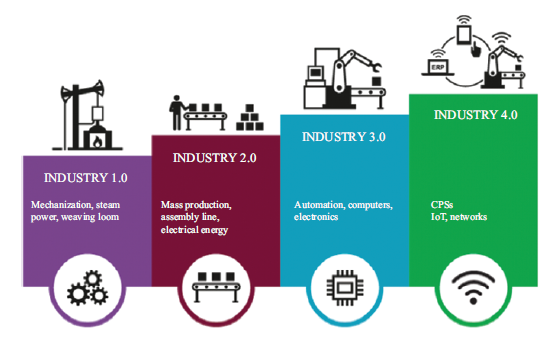
W ten sposób nadeszła nowa rewolucja przemysłowa znana jako czwarta rewolucja przemysłowa. I4.0 składa się z trzech głównych etapów: po pierwsze, cyfrowe zapisy są uzyskiwane za pomocą czujników aktywów przemysłowych, które gromadzą dane w ścisłej imitacji ludzkich uczuć i pomysłów. Nazywa się to fuzją czujników. Po drugie, zdolność analityczna zebranych danych realizowana jest poprzez analizę i wizualizację danych za pomocą czujników. Wykonywanych jest wiele różnych operacji w tle, od przetwarzania sygnałów po optymalizację, wizualizację, obliczenia poznawcze i obliczenia o wysokiej wydajności. Chmura przemysłowa wspiera system usługowy w zarządzaniu ogromną ilością danych. Po trzecie, zagregowane informacje muszą zostać przekształcone w znaczące wyniki, w tym produkcję addytywną, autonomiczne roboty, projektowanie cyfrowe i symulacje, aby przełożyć informacje na działanie. Surowe dane są przetwarzane za pomocą aplikacji do analizy danych w chmurze przemysłowej, a następnie przekształcane w wiedzę praktyczną. Fizyczne terminale wejściowe I4.0 są wyposażone w IoT i dlatego są ostatecznie podatne na cyberataki. Chociaż ta dodatkowa łączność przyczynia się do zwiększenia produktywności, stanowi ucztę dla cyberprzestępczości w sieci. Wrażliwość takich sieci jest dobrze znana cyberprzestępcom, w przypadku których udane ataki mogą wywołać druzgocące skutki, takie jak utrata dochodów, spadek rentowności, nieodwracalne szkody w wyniku pożaru lub dewastujące zagrożenie dla ludzi i mienia. Opracowanie kompleksowej strategii dla cyberryzyka ma kluczowe znaczenie dla łańcuchów wartości, ponieważ łączą one technologię operacyjną i samą siłę napędową IT-I4.0. Obecna technologia internetowa jest jednak nękana przez problemy cybernetyczne, które są znaczące wyzwania i przeszkody stojące przed użytkownikami I4.0 stają przed tradycyjnymi problemami z cyberbezpieczeństwem wraz z jego unikalnymi, samowystarczalnymi wyzwaniami w zakresie bezpieczeństwa. W przypadku braku odpowiedniego rozwiązania tych wyzwań, I4.0 może nie osiągnąć swojego prawdziwego potencjału
Charakterystyka cyberbezpieczeństwa I4.0
Zasoby systemowe (komponenty systemu) Przemysłowego Internetu Rzeczy należy najpierw określić przed zajęciem się zagrożeniami bezpieczeństwa. Zasób to cenny i wrażliwy zasób w branży firmy. Głównymi komponentami każdego systemu IoT są sprzęt systemowy, oprogramowanie, usługi i dane usługowe (w tym budynki, maszyny itp.). .0) można uzyskać następujące korzyści:
1. Zdefiniowanie nieodłącznych podatności systemów mających wpływ na ich bezpieczeństwo;
2. Zdefiniowanie cyberzagrożeń dla systemów;
3. Identyfikacja zagrożeń związanych z cyberatakami;
4. Środki zaradcze do rozwiązywania problemów cyberbezpieczeństwa.
Luki w cyberbezpieczeństwie
Luki w zabezpieczeniach to słabości projektowe, które umożliwiają intruzowi wykonanie poleceń, dostęp do nieautoryzowanych danych i/lub przeprowadzenie ataków typu "odmowa usługi" (DoS). Luki znajdują się w różnych komponentach I4.0. Istnieje kilka luk w zabezpieczeniach: infrastruktura protokołów komunikacyjnych i sieciowych, serwery aplikacji, serwery baz danych, interfejsy człowiek-maszyna, sterowniki logiki programowej, zdalne jednostki terminalowe w każdym elemencie systemu nadzoru i akwizycji danych (SCDA). Mogą to być awarie sprzętu lub oprogramowania systemu, słabości zasad, procedury systemowe i słabości użytkowników. Luki mogą być zidentyfikowane jako zdalny dostęp, oprogramowanie i sieci lokalne (LAN), a także mogą być powiązane zarówno wirtualne zasoby chmury, jak i maszyny systemów IT. Istnieją różne rodzaje luk w zabezpieczeniach systemów CPS i przemysłowych systemów sterowania (ICS); te nieznane (tj. luki dnia zerowego) są bardzo powszechne; są one umieszczane między różnymi komponentami każdego interfejsu, w którym następuje wymiana informacji. Dowody wskazują, że urządzenia IoT są zagrożone dla botnetów (np. liczba urządzeń podłączonych do Internetu), ponieważ bezpieczeństwo wielu producentów nie jest priorytetem. Wynika to z powszechnego używania domyślnych haseł i otwartych portów; brak zintegrowanego systemu do automatycznego odbierania aktualizacji oprogramowania; a oprogramowanie układowe jest często zapominane po zainstalowaniu (właściciele nie wiedzą, czy ich urządzenie jest wykorzystywane do złośliwych celów lub konieczności aktualizacji oprogramowania układowego). Jansen identyfikuje następujące powody komponentów większości urządzeń przemysłowych:
• W wielu zakładach urządzenia działają przez tygodnie lub miesiące bez żadnych narzędzi zabezpieczających i antywirusowych;
• Różne kontrolery sieci ICS mogą być zakłócane przez zniekształcony ruch sieciowy, a nawet duże natężenie ruchu, ponieważ zostały zaprojektowane w czasie, gdy cyberbezpieczeństwo nie stanowiło problemu;
• Kilka sieci ICS ma wiele sposobów na wchodzenie w zagrożenia cyberbezpieczeństwa, z pominięciem istniejących środków cyberbezpieczeństwa (np. laptopy uruchamiane i wyłączane z systemów lub pamięci USB działające na wielu komputerach bez odpowiedniego sprawdzania złośliwego oprogramowania);
• Prawie wszystkie sieci ICS są nadal wdrażane jako duża, płaska i niepowiązana sieć bez fizycznej lub wirtualnej izolacji (umożliwia rozprzestrzenianie się złośliwego oprogramowania nawet do odległych lokalizacji).
Aby rozwiązać te problemy, firmy powinny przeprowadzić proces oceny podatności w celu zidentyfikowania i oceny potencjalnych podatności systemu. Narodowy Instytut Standardów i Technologii (NIST) definiuje ocenę podatności jako systematyczną ocenę ICS lub produktu, identyfikowanie słabych punktów bezpieczeństwa, dostarczanie danych, na podstawie których można przewidzieć skuteczność proponowanego działania zabezpieczającego oraz potwierdzenie przydatności takich działań po ich realizacji. Oceny podatności są zwykle przeprowadzane przy użyciu metody sieciowej lub opartej na hoście, przy użyciu zautomatyzowanych narzędzi skanujących w celu wykrywania, testowania, analizowania i raportowania systemów i podatności. Luki techniczne, fizyczne i oparte na zarządzaniu można również zidentyfikować metodami ręcznymi.
Zagrożenia cyberbezpieczeństwa
Zagrożenie to działanie, które czerpie korzyści i ma negatywny wpływ na słabości zabezpieczeń w systemie. Zagrożenia mogą wynikać z dwóch głównych źródeł: ludzi i przyrody . Zagrożenia dla komputerów mogą być poważne, w tym straszne trzęsienia ziemi, huragany, pożary, powodzie i inne. Niewiele zabezpieczeń przed klęskami żywiołowymi można wdrożyć i nikt nie jest w stanie im zapobiec. Schematy odzyskiwania po awarii, takie jak wsparcie i plany awaryjne, są najlepszym sposobem ochrony systemów przed naturalnymi zagrożeniami. Zagrożenia ze strony ludzi są spowodowane przez ludzi, takich jak złośliwe zagrożenia wewnętrzne (ktoś ma autoryzowany dostęp) lub zagrożenia zewnętrzne (osoby lub organizacje pracujące poza siecią ) dążących do wykorzystania i zakłócenia systemu. Poniżej przedstawiono kategorie zagrożeń ludzkich:
• Zagrożenia nieustrukturyzowane składające się głównie z osób niedoświadczonych, które korzystają z łatwo dostępnych narzędzi hakerskich.
• Zagrożenia strukturalne mogą wspierać, rozwijać i wykorzystywać skrypty i kody, tak jak ludzie wiedzą o lukach w systemie. Przykładem zagrożenia strukturalnego są zaawansowane zagrożenia trwałe (APT). APT oferuje zaawansowany atak sieciowy, którego celem jest wysokiej jakości informacje w firmach i organizacjach rządowych dla przemysłu produkcyjnego, finansowego i obrony narodowej. Ataki na połączone systemy fizyczne mogą charakteryzować trzy wymiary:
1. Rodzaj napastnika (tj. wtajemniczony lub zewnętrzny);
2. Cele i zadania napastnika (tj. zniszczenie na dużą skalę lub określony cel);
3. Tryb ataku (np. aktywny lub pasywny).
W odniesieniu do kontekstów I4.0 niemiecki Federalny Urząd ds. Bezpieczeństwa Informacji (BSI) wymienia następujące kluczowe kategorie cyberzagrożeń.
• Ataki z zewnętrznym dostępem bezpośrednim;
• Ataki pośrednie na systemy informatyczne dostawcy usług, które przyznały dostęp z zewnątrz;
• Nieznane wektory ataków bez możliwości wykrycia luk (lub exploitów zeroday);
• Nieukierunkowane złośliwe oprogramowanie, które infekuje komponenty i wpływa na ich funkcjonalność;
• Wtargnięcie do pobliskich sieci lub obszarów sieciowych (np. bieżąca sieć biurowa).
W trybie ataku ataki aktywne mają na celu zmianę zasobów systemowych lub wpływanie na operacje systemu (w tym ataki rozproszonej odmowy usługi (DDoS) i ataki z użyciem złamanego klucza), podczas gdy ataki pasywne mają na celu naukę i/lub korzystać z informacji o systemie, zamiast zmieniać system. Nieautoryzowany dostęp do systemów informatycznych i poufnych danych może na ogół mieć miejsce, gdy cyberzagrożenia okażą się skuteczne. Może to skutkować nieautoryzowanym użyciem, ujawnieniem, awarią, modyfikacją lub zniszczeniem krytycznych danych i/lub interfejsów danych oraz DoS przez sieć i komputer (w najgorszym przypadku może to prowadzić do zmniejszenia dostępności systemu).
Zagrożenia cyberbezpieczeństwa
Ryzyko odnosi się do "poziomu wpływu na działalność organizacji (w tym misję, funkcjonowanie, wizerunek lub reputację), majątek firmy lub osoby powstałe w przypadku działania systemu informatycznego, biorąc pod uwagę potencjalny wpływ i potencjalne ryzyko zagrożeń ". Zagrożenia bezpieczeństwa związane z systemami informatycznymi opierają się na utracie poufności, integralności lub dostępności informacji lub systemów informatycznych. Poufność w szczególności oznacza, że nieuprawnieni użytkownicy mogą zachować informacje w tajemnicy; w ten sposób dane mogą zostać ujawnione ze względu na brak poufności. Integralność, co oznacza ochronę poufności danych lub zasobów, może prowadzić do nieautoryzowanych modyfikacji, o ile nie zostanie zachowana. W takim przypadku istnieje ryzyko uszkodzenia lub modyfikacji rekordów, danych i danych. Dostępność sprawia, że system jest dostępny i użyteczny na żądanie. W konsekwencji atak DoS może wystąpić, jeśli istnieje gwarancja dostępności systemu, powodując brak produktywności systemu fizycznego. Zagrożenia są wysoce spowodowane ekspozycją i atakami
Narażenie
Ujawnienie to problem lub błąd w konfiguracji systemu, który umożliwia atakującemu wykonywanie czynności związanych z gromadzeniem informacji. Odporność na ataki fizyczne jest jednym z najtrudniejszych problemów w IoT. Urządzenia mogą pozostać bez nadzoru w większości aplikacji IoT i prawdopodobnie będą bezpośrednio dostępne dla atakujących. Takie ujawnienie pozwala atakującemu przechwycić urządzenie, usunąć sekrety, zmienić jego oprogramowanie lub zastąpić je złośliwym urządzeniem, które jest pod kontrolą atakującego.
Ataki
Ataki są podejmowane przy użyciu różnych technik i narzędzi, które uszkadzają system lub przerywają normalne działanie, wykorzystując luki w zabezpieczeniach. Atakujący wykonują ataki dla dowolnego osiągnięcia lub korzyści. Koszt ataku jest nazywany pomiarem nakładu pracy pod względem wiedzy, zasobów i motywacji napastnika. Aktorzy atakujący to ludzie którzy stanowią zagrożenie dla cyfrowego świata. Mogą to być hakerzy, przestępcy i rządy . Na wiele sposobów mogą wystąpić ataki, w tym aktywne ataki sieciowe w celu monitorowania ruchu z poufnymi informacjami, ataki pasywne, takie jak niezabezpieczona komunikacja sieciowa i słabe szyfrowanie informacji uwierzytelniających, zamknięcie, działanie wewnętrzne i tak dalej. Typowe rodzaje cyberataków to:
1. DoS: Ten typ ataku ma na celu uniemożliwienie żądanym użytkownikom korzystanie z komputera lub zasobu sieciowego. Większość urządzeń IoT jest podatna na ataki energetyczne z powodu małej ilości pamięci i ograniczonych zasobów obliczeniowych.
2. Ataki fizyczne: Ten typ ataku na komponenty sprzętowe polega na sabotażu. Ze względu na nienadzorowany i rozproszony charakter IoT większość urządzeń znajduje się zazwyczaj w środowiskach zewnętrznych, które są bardzo narażone na fizyczne ataki.
3. Ataki na prywatność: Ochrona prywatności IoT staje się coraz większym wyzwaniem, ponieważ duże ilości informacji są łatwo dostępne za pomocą mechanizmów zdalnego dostępu. Najczęstsze ataki to:
4. Ataki oparte na hasłach: Intruzi próbują zduplikować prawidłowe hasło użytkownika. Próbę można podjąć na dwa sposoby: (1) atak słownikowy, który próbuje możliwych kombinacji liter i cyfr w celu stworzenia hasła; (2) atak z brutalną siłą wykorzystuje narzędzia do łamania haseł, aby znaleźć wszystkie możliwe kombinacje haseł.
• Śledzenie: Unikalny numer identyfikacyjny urządzenia służy do śledzenia ruchów użytkownika. Śledzenie lokalizacji użytkownika pozwala na jego identyfikację w anonimowych sytuacjach.
• Podsłuchiwanie: polega na podsłuchiwaniu rozmowy dwóch stron.
• Cyberszpiegostwo: obejmuje szpiegowanie lub uzyskiwanie tajnych informacji od osób, organizacji lub rządów za pomocą łamania zabezpieczeń i złośliwego oprogramowania.
• Eksploracja danych: umożliwia atakującym odnalezienie danych w określonych bazach danych.
5. Ataki rozpoznające: obejmują wykrywanie i mapowanie nieautoryzowanych systemów, usług i luk w zabezpieczeniach. Ataki rozpoznające obejmują skanowanie portów sieciowych, sniffery pakietów, analizę ruchu i wysyłanie zapytań o adresy IP.
6. Ataki dostępu: Nieuprawnione osoby mają prawo do dostępu do sieci i urządzeń. Dostępne są dwa różne rodzaje ataków dostępu: pierwszy to dostęp fizyczny, w którym intruz ma do dyspozycji fizyczne urządzenie. Drugi to zdalny dostęp do urządzeń połączonych IP.
7. Destrukcyjny atak: Przestrzeń jest wykorzystywana do zakłócania i niszczenia życia i mienia na dużą skalę. Terroryzm i ataki zemsty to przykłady destrukcyjnych ataków.
8. Kontrola nadzorcza i akwizycja danych (SCADA) Ataki: SCADA jest podatny na wiele cyberataków, tak jak każdy inny system TCP/IP. System można zaatakować w taki czy inny sposób:
• Zamknij system za pomocą DoS. Na przykład BlackEnergy3 (BE3) brała udział w cyberatakach na Ukrainie w 2015 r., które doprowadziły do przerw w dostawie prądu. BE3 został wykorzystany w okresie poprzedzającym atak do zbierania informacji o środowisku ICS i prawdopodobnie został wykorzystany do złamania danych uwierzytelniających użytkownika przez operatorów sieci, chociaż nie odgrywał bezpośredniej roli w odcinaniu zasilania. W przeciwieństwie do poprzednich incydentów związanych z wariantami Black Energy, BE3 zostało dostarczone ukraińskim firmom energetycznym za pośrednictwem e-maili typu spear-phishing i uzbrojonych dokumentów Microsoft Word.
• Przejmij kontrolę nad systemem za pomocą trojanów lub wirusów. Na przykład w 2008 roku wirus o nazwie Stuxnet został zaatakowany w irańskim obiekcie nuklearnym w Natanz.
9. Cyberprzestępczość: Internet i inteligentne obiekty są wykorzystywane do wykorzystywania użytkowników i danych, takich jak kradzież IP, kradzież tożsamości, kradzież marki i oszustwa, do celów materialnych.
Środki zaradcze w zakresie cyberbezpieczeństwa
Środki zaradcze to zestaw działań, sprzętu, procedur i technik służących do zwalczania zagrożeń, luk w zabezpieczeniach lub ataków poprzez zapobieganie zagrożeniom lub ich usuwanie, minimalizowanie lub zgłaszanie szkodliwych skutków. Poniższe trzy wysokopoziomowe podejścia do zagwarantowania bezpieczeństwa przemysłowych systemów sterowania są opisane przez Jansena:
1. Utwardzić obszar, co oznacza odizolowanie sieci zakładu od sieci biurowej, stosując w stosownych przypadkach zapory ogniowe i strefę zdemilitaryzowaną;
2. Głęboka ochrona, wykorzystująca różne warstwy ochrony w całej sieci w celu zatrzymania i powstrzymania złośliwego oprogramowania, które przełamuje barierę.
3. Dostęp zdalny, jeden z najczęstszych sposobów penetracji zapory. W takim przypadku wirtualna sieć prywatna jest zalecana w oddzielnym obszarze zdemilitaryzowanym w celu odizolowania użytkowników zdalnych.
Ponadto wdrożone mechanizmy bezpieczeństwa powinny być na bieżąco aktualizowane (instalacja nowej łaty bezpieczeństwa) na poziomie urządzenia, na poziomie sieci (aktualizacja sygnatur nowych zapór ogniowych zagrożeń) oraz na poziomie zakładu/przemysłu (monitorowanie i analiza rzeczywiste źródła dzienników). Innymi słowy, skuteczne systemy przemysłowe powinny chronić przed nieuprawnionym dostępem lub zmianą informacji dla upoważnionych użytkowników, czy to podczas przechowywania, handlu, tranzytu i odmowy świadczenia usług, w tym środków wymaganych do identyfikacji, dokumentowania i przeciwdziałania zagrożeniom w ramach Komitetu Bezpieczeństwa Narodowego Systemy (CNSS). Kankanhalli i in. zgłosić, że działania prewencyjne obejmują wdrożenie najnowocześniejszego oprogramowania zabezpieczającego lub kontrole bezpieczeństwa zasobów przemysłowych, takie jak zaawansowana kontrola dostępu, wykrywanie włamań, zapora ogniowa, systemy monitorowania i generowanie raportów o wyjątkach. Działania odstraszające obejmują opracowanie polityki i wytycznych bezpieczeństwa, szkolenia dla użytkowników oraz rozwój doświadczonych audytorów systemów przemysłowych.
Zasady bezpieczeństwa I4.0
Aby odnieść sukces we wdrażaniu skutecznego bezpieczeństwa przemysłowego IoT, należy zapewnić pewne zasady, aby zapewnić bezpieczeństwo w całym systemie Przemysłowego IoT. Zgodnie z Narodową Strategią Bezpieczeństwa Cybernetycznego (NCSS) oraz CNSS , aby zapewnić wydajne środowisko IoT, należy uwzględnić następujące sześć zasad ponieważ IoT szybko się rozwija.
Poufność
Poufność jest ważną cechą bezpieczeństwa Przemysłowego Internetu Rzeczy, ale w niektórych sytuacjach, gdy dane są publikowane, może nie być obowiązkowa. Dzięki temu informacje i dane nie są ujawniane z wewnątrz lub na zewnątrz systemu żadnej nieupoważnionej osobie lub stronie. Poufność danych i informacji jest utrzymywana poprzez zastosowanie algorytmów szyfrowania przechowywanych i przesyłanych danych oraz ograniczenie dostępu do lokalizacji danych. Na przykład informacje o pacjentach, dane biznesowe i/lub informacje wojskowe, a także dane uwierzytelniające i tajne klucze muszą być ukryte przed nieautoryzowanymi podmiotami.
Uczciwość
Integralność jest w większości przypadków obowiązkową funkcją bezpieczeństwa zapewniającą użytkownikom IoT niezawodne usługi. Istnieją różne wymagania dotyczące integralności różnych systemów Industrial IoT. Jest również w stanie utrzymać dane w ich obecnej formie i zapobiegać nieuprawnionej manipulacji. Innymi słowy, dane muszą być trzymane z dala od zewnętrznych i wewnętrznych, którzy próbują go modyfikować. Tak więc miejsce docelowe otrzymuje błędne dane i uważa, że są one dokładne. Na przykład system zdalnego monitorowania pacjenta ma wyjątkowo wysoką kontrolę integralności pod kątem błędów losowych ze względu na wrażliwość informacji. Utrata lub manipulacja danymi może mieć miejsce z powodu komunikacji, która może prowadzić do śmierci.
Dostępność
To generalnie pozwala systemowi na terminowe dostarczanie usług i produkcję produktów. Dostępność każdego podsystemu oznacza, że może on funkcjonować poprawnie i działać na czas i w razie potrzeby [28]. Innymi słowy, dostępność gwarantuje prawidłowe funkcjonowanie wszystkich przemysłowych podsystemów IoT poprzez unikanie wszelkiego rodzaju uszkodzeń, w tym awarii sprzętu i oprogramowania, awarii zasilania i ataków DoS. Podobnie użytkownik urządzenia (lub samo urządzenie), gdy jest to konieczne, musi mieć dostęp do usług. Aby świadczyć usługi nawet w obecności złośliwych podmiotów lub w niekorzystnych sytuacjach, różne komponenty oprogramowania i sprzętu muszą być niezawodne na urządzeniach IoT. Na przykład systemy monitorowania pożaru lub monitorowania stanu zdrowia byłyby prawdopodobnie bardziej dostępne niż czujniki przydrożne.
Autentyczność
Uwierzytelnianie wszechobecnej łączności IoT opiera się na naturze przemysłowych środowisk IoT, w których możliwa byłaby komunikacja między sprzętem i sprzętem maszyna-maszyna (M2M), między człowiekiem a urządzeniem i/lub między człowiekiem a człowiekiem. Różne wymagania dotyczące uwierzytelniania wymagają różnych rozwiązań systemowych. Wymagane są silne rozwiązania, takie jak uwierzytelnianie kart bankowych czy systemów bankowych. Właściwość autoryzacje umożliwia tylko upoważnionym podmiotom (dowolnemu uwierzytelnionemu podmiotowi) wykonywanie określonych operacji sieciowych. Jednak najważniejszym zadaniem jest bycie międzynarodowym, czyli e-Paszport, podczas gdy inni muszą być lokalni.
Niezaprzeczalność
W przypadkach, gdy użytkownik lub urządzenie nie mogą odmówić wykonania czynności, funkcja niezaprzeczalności dostarcza pewnych dowodów. Niezaprzeczalność nie może być uważana za główną funkcję bezpieczeństwa dla większości Przemysłowego Internetu Rzeczy. Może na przykład mieć zastosowanie w pewnych kontekstach, w których systemy płatności nie mogą zostać odrzucone przez użytkowników lub dostawców. W przypadku incydentu odrzucenia, podmiot zostałby prześledzony do jego działań przez proces rozliczalności, który może pomóc zweryfikować, co wydarzyło się w jego historii i kto był faktycznie odpowiedzialny.
Prywatność
Prywatność to prawo podmiotu do określenia, czy wchodzi w interakcję ze swoim środowiskiem i na jakim poziomie podmiot ten jest skłonny udostępniać informacje o sobie innym. Główne cele ochrony prywatności w przemyśle IoT to:
• Prywatność urządzenia: zależy od prywatności fizycznej i prywatności przełączania. W przypadku kradzieży lub utraty urządzenia lub odporności na ataki typu side-channel, poufne informacje mogą zostać uwolnione z urządzenia.
• Prywatność pamięci masowej: należy wziąć pod uwagę dwa czynniki, aby chronić prywatność danych przechowywanych na urządzeniach:
1. Urządzenia powinny przechowywać możliwą ilość potrzebnych danych.
2. Regulacja powinna zostać rozszerzona o zapewnienie ochrony danych użytkownika po zakończeniu użytkowania urządzenia (wymazywanie) w przypadku kradzieży, zagubienia lub nieużywania urządzenia.
• Prywatność komunikacji: zależy od dostępności urządzenia oraz jego integralności i wiarygodności. Aby odstąpić od komunikacji dotyczącej prywatności danych, urządzenia IoT powinny komunikować się tylko wtedy, gdy jest to konieczne.
• Prywatność przetwarzania: zależy od urządzenia i integralności komunikacji. Bez wiedzy właściciela danych dane nie powinny być ujawniane ani zatrzymywane przez osoby trzecie.
• Tożsamość prywatności: Tożsamość każdego urządzenia powinna być identyfikowana tylko przez upoważnioną osobę/urządzenie.
• Lokalizacja prywatności: tylko zatwierdzony podmiot powinien znajdować się w położeniu geograficznym odpowiedniego urządzenia (człowiek/urządzenie).
Komponenty systemu I4.0
Termin "Przemysł 4.0" jest nowy i wiąże się z rozwojem technologii informacyjno-komunikacyjnych (ICT), w szczególności z integracją ICT w procesach produkcyjnych. Do tej pory zgłoszono kilka incydentów w tych sektorach. Chociaż incydenty te uważane są za odosobnione, mogą być jednak niepokojące. Nowe zagrożenia cybernetyczne powstają dzięki wzajemnym połączeniom infrastruktur krytycznych, które muszą zostać zidentyfikowane, zbadane i rozwiązane przed zbyt wcześnie. W tej sekcji omówimy większość popularnych komponentów systemu w I4.0. W I4.0 eksperci ds. cyberbezpieczeństwa muszą teraz zmierzyć się z problemami cyberbezpieczeństwa. Przegląd standardów (seria ISO 27000, IEC 62541 OPC UA) i sieci Times Sensitive Nets (IEEE 17222016), które odnoszą się do tych wyzwań OPC UA, przedstawiły ogólny raport. Podobnie, zaprezentowano nowe zasady projektowania oceny ryzyka cybernetycznego IoT w odniesieniu do I4.0, aby umożliwić szybki i aktualny przegląd istniejącego i powstającego rozwoju I4.0 IoT. W ten sposób wielu badaczy jest zmotywowanych do wdrażania technik w sprawach przemysłowych. W tej sekcji skupimy się jednak na aplikacjach, które są integrowane i wdrażane w branży, takich jak uwierzytelnianie i podejścia do bezpieczeństwa.
Chmura obliczeniowa
Według NIST istnieją cztery typy modeli wdrażania chmury, które zostały szczegółowo omówione w kolejnych sekcjach.
Chmura publiczna
Ta infrastruktura chmury jest otwarta dla wszystkich, w tym dla pamięci masowej, aplikacji i innych usług, a użytkownicy płacą tylko za czas, w którym usługa jest używana do celów pay-peruse. Chmury publiczne są jednak mniej bezpieczne, ponieważ wszyscy użytkownicy mogą korzystać z aplikacji i danych. Przykład: Google App Engine, inteligentna chmura IBM. Korzyści z chmury publicznej: dostępność i niezawodność, płatność zgodnie z rzeczywistym użyciem i swoboda samoobsługi.
Prywatna chmura
Ta infrastruktura chmurowa jest wdrażana w ramach jednej organizacji i jest otwarta dla ograniczonej grupy użytkowników. Organizacja kontroluje swoje zasoby i aplikacje. Zwiększyło więc bezpieczeństwo chmury prywatnej. Przykład: Ubuntu Enterprise Cloud, Ubuntu PVC. Korzyści z chmury prywatnej: wysoki poziom bezpieczeństwa, wykorzystanie istniejących zasobów i pełna kontrola nad dostosowaniem.
Chmura społecznościowa
Chmura społecznościowa obejmuje dystrybucję w tej samej społeczności infrastruktury obliczeniowej między dwiema organizacjami. Infrastruktura chmury i zasoby komputerowe są dostępne wyłącznie dla co najmniej dwóch organizacji ze wspólnymi elementami prywatności, bezpieczeństwa i przepisów. Może to pomóc w obniżeniu kosztów kapitału na jego wdrożenie, ponieważ koszty są alokowane między organizacje. Przykład: "Gov Cloud" firmy Google. Chmura społecznościowa zapewnia niższe koszty niż chmura prywatna, ograniczona liczba użytkowników, wysokie bezpieczeństwo.
Obliczanie mgły
Fog computing to przede wszystkim rozszerzenie chmury obliczeniowej na obrzeżu sieci, które umożliwia nowe aplikacje i usługi IoT i I4.0. Jednak w wersji I4.0 wykorzystanie inteligentnych systemów CPS wykorzystujących komputery IoT, mobilne i w chmurze sprawia, że fabryki stają się coraz bardziej inteligentne i wydajne. Jednak prace autorów dotyczyły wdrażania systemów przetwarzania mgły w celu zminimalizowania kosztów instalacji przy ograniczeniach maksymalnej wydajności, maksymalnego opóźnienia, zasięgu i maksymalnej wydajności urządzenia. Opartą na mgle architekturę aplikacji I4.0 zbadano, aby zmniejszyć ogólne ograniczenie zużycia energii przez węzły IoT. Obecnie istnieje kilka badań, które wraz z I4.0 wprowadzają mgłę obliczeniową. W tej części prezentowane są te prace badawcze. Następnie zaproponowano DMGA z zaletami MA i GA.
Big data
Wraz z rosnącą liczbą źródeł danych i spadkiem cen pamięci masowej i zasobów komputerowych w ostatnich latach, gromadzenie i analizowanie dużych ilości danych stało się wykonalne. Rozwój tych metod poprawia efektywność operacyjną. Opracowano zintegrowaną platformę analizy danych big data do zarządzania ryzykiem w oparciu o dane, w której położono nacisk na dane z czujników do zastosowań w opiece zdrowotnej, aby zwiększyć skalowalność, bezpieczeństwo i wydajność systemu. Pod nazwą "big data" w I4.0 wiele zrobiono w różnych dyscyplinach, takich jak przewidywanie sprzedaży, planowanie produkcji czy eksploracja i klastrowanie relacji użytkowników. Na przykład został wprowadzony w trzech obszarach CPS, produkcji cyfrowej, postępu I4.0 i analityki Big Data. Podobnie podejście, które integruje heterogeniczne źródła danych, pozwala również na zautomatyzowaną ocenę ryzyka dużych zbiorów danych w I4.0]. Zbieranie, przetwarzanie, integracja, modelowanie, przechowywanie, bezpieczeństwo, poufność, analiza, cykl życia i prezentacja danych są szczegółowe. Ponadto proponuje się bezpieczną architekturę dla IIoT, mechanizm bezpieczeństwa zarządzania kluczami do ochrony dużych zbiorów danych w przemyśle wykorzystuje 4.0 do przechowywania i przetwarzania danych z czujników, które można sprzedać (big data) dla zastosowań medycznych. Przeprowadzono ankietę, aby skoncentrować się na tym krytycznym skrzyżowaniu. A w systemach cyber-fizycznych i Big Data wprowadzane są szczegółowe metody, aby pomóc czytelnikom zrozumieć ich rolę w I4.0
Interoperacyjność i przejrzystość
Zdolność systemów do wymiany danych o jednoznacznym znaczeniu to interoperacyjność. Jednak literatura definiuje interoperacyjność na różne sposoby, a ostatnio zaproponowano nowe modele oceny interoperacyjności. Chociaż skupienie się na interoperacyjności, jednej z zasad I4.0, podczas gdy standaryzacja jest niezbędna dla komunikacji, należy również pomóc w interpretacji znaczenia komunikacji przez maszyny i systemy, a tutaj jest interoperacyjność: znaczenie treści dane wymieniane w I4.0. Niedawno pokazaliśmy wzajemne powiązania między Industrial Internet Reference Architecture (IIRA) i referencyjnym modelem architektury dla przemysłu 4.0 (RAMI 4.0) oraz sposób, w jaki niektóre środowiska testowe zostały wdrożone w ramach IIC - w szczególności platformy testowe Infosys AE i IDT. Zbadano również obiecujące podejście do optymalizacji interoperacyjności CPS, zwane formalną analizą koncepcji w I4.0. Przeanalizowano literaturę dotyczącą interoperacyjności, aby znaleźć zautomatyzowane podejścia do interoperacyjności semantycznej, zwłaszcza w dynamicznych systemach CPS na dużą skalę . Ponadto pojawiło się ogólne wskazanie dla mapowania funkcjonalnego, a powiązanie modelowania interoperacyjności między koncepcją cyfrowego bliźniaka bliźniaczej architektury Internetu przemysłowego (IIRA) (RAMI 4.0 AS) zostało oznaczone jako RAMI 4. Integracja maszyna-maszyna w ramach I4. Proponowane w programie powinno umożliwiać maszynom komunikację, a maszyny muszą osiągać poziomy interoperacyjności zgodne z potrzebami systemu. Istnieje popularna aplikacja używana w projektowaniu przejrzystości danych, taka jak następujące punkty
Interfejs programu aplikacji
Interfejs programu aplikacji (API) to zestaw procedur, protokołów i narzędzi do tworzenia aplikacji. Ogólnie API wskazuje na interakcję między komponentami oprogramowania. Ponadto elementy graficznego interfejsu użytkownika są programowane za pomocą interfejsów API. Porządne API umożliwia tworzenie programu ze wszystkimi blokami projektowymi. Następnie programista składa klocki. W przypadku systemów operacyjnych, aplikacji lub witryn internetowych istnieje wiele różnych rodzajów interfejsów API. Windows, między innymi, ma wiele zestawów API, które są używane przez sprzęt i aplikacje - to API pozwala mu działać podczas kopiowania i wklejania tekstu z jednej aplikacji do drugiej. API wymienia Mapy Google, Twitter, YouTube, Flickr i Amazon Product Advertising jako jedne z najpopularniejszych interfejsów API.
GraphQL
GraphQL to język zapytań, który umożliwia użytkownikom API opisanie żądanych danych, pozwalając deweloperom API skupić się na relacjach danych i regułach biznesowych, zamiast martwić się różnymi ładunkami API. W tym opisie klient GraphQL może zażądać dokładnych informacji w pojedynczej aplikacji. Te typy są używane przez GraphQL, aby zagwarantować, że klienci proszą tylko o popełnienie jasnych i wartościowych błędów. Od czasu publicznego wydania GraphQL, wiele klientów GraphQL i środowiska uruchomieniowego rozwiązywania zapytań po stronie serwera zostało zaimplementowanych w systemach oprogramowania i językach programowania. Jak każdy program, implementacje te mogą być przedmiotem problemów funkcjonalnych i wydajnościowych. GraphQL to potężny język zapytań, który robi wiele poprawnie. GraphQL zapewnia bardzo elegancką metodologię, gdy jest prawidłowo zaimplementowana w celu odzyskiwania danych, stabilności zaplecza i zwiększonej wydajności zapytań. GraphQL pozwala również na wykonywanie zapytań dokładnie w dowolnym momencie. Jest to doskonałe do korzystania z interfejsu API, ale ma również złożone implikacje dotyczące bezpieczeństwa. Zamiast prosić o legalne i przydatne informacje, złośliwy gracz może przesłać kosztowne i zagnieżdżone zapytanie w celu przeciążenia serwera, bazy danych, sieci lub wszystkiego innego. W ten sposób otwiera się na atak DoS bez odpowiednich zabezpieczeń. Jednak autoryzacja jest mechanizmem, za pomocą którego system określa poziom dostępu do systemów kontrolowanych przez konkretnego (uwierzytelnionego) użytkownika. System zarządzania bazą danych można opracować, aby umożliwić niektórym osobom zbieranie informacji z bazy danych, ale nie zmieniać danych przechowywanych w bazie danych, jednocześnie umożliwiając innym osobom zmianę informacji, na przykład, które mogą być lub mogą nie być powiązane do scenariusza internetowego. Uwierzytelnianie może być przetwarzane z kontekstem zapytań. Podstawową ideą jest to, że do aplikacji można wstrzyknąć dowolny kod, który jest następnie przesyłany do żądania, dzięki czemu autoryzacja przez firmę deweloperską może być bardzo dokładnie kontrolowana. Jest to bardzo bezpieczny system, który jest prawdopodobnie znacznie silniejszy niż inne rozwiązania problemów wstrzykiwania SQL i Langsec. Jednak proponowana jest prosta, ale ekspresyjna technika zwana testowaniem odchyleń, która automatycznie wyszukuje anomalie w sposobie obsługi schematu. Technika wykorzystuje zestaw reguł odchyleń do wprowadzenia istniejącego przypadku testowego i automatycznie generuje wariacje z przypadku testowego. Celem testowania odchyleń jest zwiększenie pokrycia testami i wsparcie programistów w ich implementacjach GraphQL i API w znajdowaniu możliwych błędów. Dostępna jest nowa struktura koncepcyjna dostępu do danych przez Internet, która jest szeroko stosowana w różnych aplikacjach. Dzięki tej architekturze klient może uzyskać dane po stronie serwera, zmniejszając liczbę aplikacji sieciowych i unikając nadmiernego gromadzenia lub przechwytywania danych. Graficzne bazy danych zostały przedstawione przez autorów jako realne miejsce do przechowywania danych klinicznych i wykresów jako mechanizm filtrujący do egzekwowania lokalnych polityk dotyczących danych, co gwarantuje prywatność w transakcjach dotyczących danych medycznych.
Blockchain (rozproszone księgi)
Technologia Blockchain jest jedną z możliwych podstaw do zapewnienia stabilnego protokołu dla niezależnych działań biznesowych. Blockchain to kolejna technologia I4.0, która stała się bardzo popularna w innych dziedzinach, takich jak finanse, i ma potencjał, aby zapewnić wyższy poziom przejrzystości, bezpieczeństwa, zaufania i wydajności w łańcuchu dostaw oraz umożliwić korzystanie z inteligentnych kontraktów. Zakres tej sekcji dotyczącej technologii blockchain znajduje się w kontekście I4.0. Wielu badaczy wdrożyło ostatnio zdecentralizowane rozwiązanie blockchain, które chroni prywatność i przeprowadza audyty, aby zapewnić bezpieczną komunikację między agentami i pomóc w opracowaniu odpowiednich rozwiązań zmieniających warunki pracy. Ponadto blockchain służy do odbierania, walidacji i udostępniania danych inwentaryzacyjnych zebranych z bezzałogowych statków powietrznych (UAV) zainteresowanym stronom oraz organizowania bezpiecznej interakcji między niezależnymi agentami. W podobny sposób zwrócono uwagę na zmniejszenie obciążenia i opóźnienia pakietów oraz zwiększenie skalowalności BC w porównaniu z różnymi poziomami bazowymi, aby umożliwić rozwój odpornych, odpornych na awarie aplikacji IoT i oprogramowania pośredniczącego w łańcuchu bloków. Jednak autorzy zorganizowali system komunikacji między agentami w parze, wykorzystując zdecentralizowaną technologię blockchain ethereum i inteligentne kontrakty. Przedstawiono również architekturę komunikacyjną, która obejmuje zarówno blockchain, jak i inteligentne kontrakty, wraz z rozwojem UAV dla aplikacji inwentaryzacyjnych i identyfikowalności opartych na RFID. Dodatkowo rozwijane jest podejście BCT do traktowania wiarygodności firm w postaci inteligentnych kontraktów jako tekstu. Ponadto opracowywany jest model wykorzystujący systemy blockchain i wieloagentowe w sieci podmiotów do pomocy w reprezentowaniu podmiotu i wspomagania decyzji poprzez dostarczanie dodatkowej wiedzy. Aby zapewnić egzekwowanie szczegółowych zasad kontroli dostępu, zaprezentowano również oparty na blockchain system wzajemnego uwierzytelniania BSeIn. W ostatnich latach wprowadzono architekturę IoT opartą na blockchain, która zapewnia lekkie i zdecentralizowane bezpieczeństwo i prywatność. Autorzy zaproponowali również sposób zarządzania urządzeniami IoT za pomocą platformy komputerowej Ethereum. Praca , hierarchiczna struktura i rozproszone zaufanie w celu zachowania bezpieczeństwa i prywatności w BC, stanowi podstawę proponowanych ram i sprawia, że są one lepiej dostosowane do specyficznych wymagań Internetu Rzeczy. Proponuje się lekki, skalowalny BC dla IoT, algorytm konsensusu przyjazny dla IoT, który eliminuje potrzebę rozwiązania zagadki przed dodaniem bloku poprawy do BC. Struktura i funkcjonalność PlaTIBART, to platforma do rozwoju, wdrażania, wykonywania, zarządzania i testowania ITBA dla transaktywnych aplikacji blockchain IoT z wielokrotnym testowaniem. Ponadto obecne protokoły blockchain zaprojektowane dla sieci IoT są najnowocześniejsze. Wydajny zdecentralizowany mechanizm uwierzytelniania zwany bańkami zaufania. Ponadto w ramach prac przeanalizowano aktualne trendy w badaniach nad podejściami BC i wykorzystaniem technologii w środowisku IoT. Podobnie architektura umożliwiająca bezpieczne aktualizacje oprogramowania układowego w rozproszonej zaufanej sieci IoT przy użyciu łańcucha bloków.
Sieć definiowana programowo
Sieć definiowana programowo (SDN) to technologia, która może efektywnie zarządzać całą siecią i przekształcić złożoną architekturę sieci w prostą i łatwą w zarządzaniu. SDN oznacza, że jednostka sterująca sieci jest fizycznie oddzielona od urządzenia przekazującego, w którym płaszczyzna sterowania zarządza kilkoma urządzeniami. SDN będzie prawdopodobnie jedną z najważniejszych technologii w I4.0, umożliwiającą programowe monitorowanie architektury sieci, umożliwiając zmianę dostępu do sieci na żądanie. Różne badania wykazały, że SDN lub IIoT definiowany programowo ma wpływ na podejścia, a wiele badań jest prowadzonych przy użyciu sieci obsługujących SDN w celu tworzenia wysoce skalowalnych i elastycznych sieci przy jednoczesnym dostosowywaniu ich do zmian w środowisku sieciowym. Ponadto skrócono czas przesyłania danych i poprawiono wrażenia użytkownika w aplikacjach wrażliwych na opóźnienia. Ponadto zapory ogniowe ograniczają narażenie na przemysłowe urządzenia sterujące, dzięki czemu minimalizowane są zagrożenia bezpieczeństwa. Do zarządzania urządzeniami fizycznymi i zapewnienia interfejsu do wymiany informacji proponuje architekturę IIoT definiowaną programowo. Problemy skalowalności kontrolerów w architekturze SDN, organizuje dyskusję na temat płaszczyzny kontroli skalowalności na dwa szerokie podejścia: podejścia odnoszące się do topologii i podejścia odnoszące się do mechanizmów. Poza tym autorzy zaproponowali metaheurystyczny algorytm ewolucyjny (PACSA-MSCP), który jest oparty na równoległej wersji kolonii mrówek max-min, wykorzystującej asynchroniczny algorytm symulowanego wyżarzania. Metodologia wdrażania przemysłowego, energooszczędnego czujnika bezprzewodowego IIoT węzły z myślą o trójwarstwowej architekturze szkieletowej IIoT centrum danych. Podejście oparte na danych, które wykorzystuje niezmienniki wykrywania anomalii, zostało opracowane na stanowisku testowym uzdatniania wody, które ma identyfikować i wykrywać ataki integralności . Ponadto przedstawia kilka zagrożeń bezpieczeństwa rozwiązanych przez SDN oraz nowe zagrożenia wynikające z wdrożenia SDN. Praca autorów Hy-LP - hybrydowy protokół i framework dla sieci IIoT. Hy-LP umożliwia bezproblemową i lekką interakcję z inteligentnymi urządzeniami IIoT i między nimi w ramach wdrożeń międzydomenowych i wewnątrzdomenowych. Zdefiniowana programowo architektura IIoT proponuje, aby tryb adaptacyjny można było wybrać w obliczeniach mgły przy użyciu opartych na trybach obliczeniowych sekwencji wykonawczych CMS i ASTP. Złożone podejście do ochrony ataku IIoT Command przedstawiono w [86] poprzez opracowanie lekkiego schematu uwierzytelniania w celu zapewnienia tożsamości nadawcy. Autor [87] zaproponował platformę testową opartą na SDN i połączoną ontologię cyberbezpieczeństwa i odporności na ataki, które mają być wykorzystane w wymaganiach dotyczących przechwytywania etapów projektowania sieci wirtualnej. W [88] zaproponowano architekturę SDIN, która uwzględnia istniejące wady IIoT, na przykład wykorzystanie zasobów, przetwarzanie danych i kompatybilność systemu. Zaproponowano heterogeniczną, hierarchiczną i wielopoziomową architekturę komunikacji i inteligentną dystrybucję danych sterowaną krawędzią (ang. edge-driven Intelligent Data Distribution) Ponadto pewne prace wprowadziły pojęcie SDCM do promowania produkcji opartej na chmurze i innych filarów przemysłu 4.0 poprzez zwinność, elastyczność i zdolność adaptacji przy jednoczesnym minimalizowaniu różnych złożonych problemów. Infrastruktura definiowana programowo jest następnie używana w środowisku sieciowym w I4.0. Ponadto badacze ISD 4.0 badają SDN, ponieważ można go inteligentnie wykorzystać do automatyzacji wielu zadań, takich jak zarządzanie użytkownikami, routing, nadzór, kontrola, bezpieczeństwo i konfiguracja, nieograniczonych przez innych. Podobnie architektura sieci z obsługą SDN i MEC, obejmująca różne rodzaje technologii dostępowych, została zaproponowana w celu zapewnienia komunikacji o niskiej prędkości i wysokiej niezawodności. Ponadto wprowadzno nowy SDN Firewall, który automatycznie stosuje standardową architekturę, bez wpływu na elastyczność sieci.
Uwierzytelnianie wieloskładnikowe
Aby zapewnić bezpieczne środowisko w I4.0, aplikacje cyberbezpieczeństwa odgrywają ważną rolę w branżach, aby zapobiegać brakom właściwości bezpieczeństwa i przezwyciężać powszechne ataki (np. DoS, replay attack, MiTM). Niektóre z technik uwierzytelniania stosowanych w przemysłowym IoT omówiono w następujący sposób:
Kerberos
Kerberos to protokół do uwierzytelniania klienta i serwera przez niezabezpieczone połączenie sieciowe, w którym mogą się wzajemnie uwierzytelniać [90]. Jest to technologia, która umożliwia i zabezpiecza uwierzytelnianie w otwartych i rozproszonych sieciach. Kerberos zwrócono ostatnio uwagę na solidność zabezpieczeń dostarczaną przez wielu badaczy i bezpieczną komunikację, aby uniemożliwić atakującym dostęp do wielu komputerów. Był więc odporny na ataki i wydajny czas i przestrzeń, aby sprostać wymaganiom Internetu Rzeczy. Jednakże wynalazek dotyczy wielostopniowego systemu bezpieczeństwa i metodologii zaprojektowanej w celu ograniczenia nieautoryzowanego dostępu do danych w proponowanym środowisku sterowania przemysłowego]. Ponadto zaproponowano protokół uwierzytelniania dla celów biometrycznych Kerberos dla aplikacji m-commerce. Ramy inżynierii protokołów zostały również wprowadzone aby umożliwić ustrukturyzowaną, formalną i interoperacyjną definicję oprogramowania i sprzętu, architektury, projektowania i rozwoju, konfiguracji, dokumentacji i konserwacji. Ponadto autorzy opisali projekt i implementację przy użyciu trzypoziomowego uwierzytelniania Kerberos w celu zapewnienia uwierzytelniania systemu inteligentnego domu poprzez IoT. Protokół wykorzystywał AS i KDC, aby dodać do niego Expanded-Kerberos, zaproponowano wydajny i bezpieczny protokół do ochrony prywatności i wrażliwych danych użytkowników. Ponadto przedstawiono schemat uwierzytelniania stron trzecich, z którego korzysta Kerberos. Dzięki temu użytkownicy mogą sprawdzać autentyczność i integralność zapisanych danych w chmurze za pomocą protokołu Kerberos w zaprojektowanym schemacie. Ponadto, framework CoAP, który rozwiązuje drobnoziarnisty problem kontroli dostępu, wykorzystuje pomysły innych systemów kontroli dostępu, takich jak Kerberos i RADIUS, i integruje oba z protokołem CoAP w celu uzyskania ramy kontroli dostępu dla IoT. W tym samym kontekście bezpieczeństwa sieci zaproponowano mechanizm podwójnego uwierzytelnienia w systemie Kerberos.
Uwierzytelnianie dwuskładnikowe
Uwierzytelnianie dwuskładnikowe zazwyczaj wymaga, aby użytkownik dostarczył czynnik wiedzy lub dwa lub więcej (np. coś, co użytkownik wie, takie jak hasło, odpowiedź na pytanie), nieodłączny czynnik (np. wiedza użytkownika, taka jak odcisk palca, skan siatkówki , inne dane biometryczne) oraz współczynnik posiadania (np. coś, co posiada użytkownik, np. klucz, token) . Mechanizm ten jest uzasadniony z punktu widzenia bezpieczeństwa i użyteczności przy zachowaniu wysokiej wydajności dla wszystkich operacji oraz zapewnieniu uwierzytelniania typu end-to-end pomiędzy urządzeniami/aplikacjami IoT. Ponadto zapewnił dużą poufność, że adwersarze nigdy nie mogą namierzyć żadnego pojazdu. Zapewniono kilka podstawowych funkcji bezpieczeństwa, co wiąże się z niższymi kosztami przetwarzania, komunikacji i przechowywania. Ta sekcja ogólnie odnosi się do systemów uwierzytelniania, a dokładniej systemów i procesów zapewniających uwierzytelnianie dla systemów dwuskładnikowych w różnych typach infrastruktury i środowiskach
operacyjnych w infrastrukturze krytycznej. Niemniej jednak, nowy przyjazny dla użytkownika system uwierzytelniania dwuskładnikowego (DoubleSec) dla urządzeń mobilnych został również opracowany w celu projektowania architektury bezpieczeństwa, która łączy i wykorzystuje najlepsze praktyki w kryptografii i protokołach bezpieczeństwa. Zbyt wiele systemów, metod i nośników czytelnych dla komputera do dwuskładnikowego uwierzytelniania solidnego systemu w infrastrukturze operacyjnej również przedstawiono. Podobnie, trójstronne uzgadnianie dla dwukierunkowego uwierzytelniania między węzłami czujników i ustanowienie bezpiecznego kanału komunikacyjnego zostało zaproponowane i zaimplementowane . Ponadto autorzy przedstawili schemat uwierzytelniania dwuskładnikowego z wykorzystaniem połączenia QR, PIN-u i posiadania smartfona. Zaproponowano niedawno wydajny lekki schemat OTP dla dwuskładnikowego uwierzytelniania między urządzeniami, aplikacjami i komunikacją IoT, oparty na IDE (IBE ECC). Ponadto wprowadzono nowy,
oparty na chmurze, wdrażający IIoT schemat uwierzytelniania użytkowników oparty na biometrii (BP2UA). W dziedzinie badań dwuczynnikowych dla przemysłowych sieci czujników bezprzewodowych (WSN), autorzy poczynili znaczący krok naprzód w przełamaniu błędnego cyklu "break-fix break-fast". Nowy protokół uwierzytelniania dwuskładnikowego na współczynniku szumu PUF dla urządzeń IoT, jest również zachowany w odniesieniu do prywatności. Oprócz dwóch czynników uwierzytelniania IoT, autorzy przedstawili infrastrukturę biometrycznego kompleksowego rozwiązania bezpieczeństwa. Schemat uwierzytelniania 2FLIP został później zaproponowany w [102], wykorzystując dwie główne metody: decentralizację CA i decentralizację hasła biologicznego 2FA. Co więcej,zaproponowano SoundAuth, mechanizm 2FA, który może niezawodnie wykrywać kolokację obu użytkowników.
Uwierzytelnianie trójskładnikowe
Zaproponowano kilka schematów dla umów dotyczących uwierzytelniania i kluczy dla przemysłu, IoT i WSN. Jednak dane zbierane w czasie rzeczywistym w środowisku IIoT są przekazywane do kanału publicznego i w tym środowisku podnoszone są kwestie bezpieczeństwa i prywatności. Zapewnia bezpieczeństwo WSN, niemożność śledzenia użytkownika i wydajność obliczeniową dla usług mobilnych . Korzystając z uwierzytelniania trójskładnikowego, uwierzytelnianie użytkownika i tworzenie klucza sesji może zwiększyć bezpieczeństwo systemu i dodatkową funkcjonalność. W środowisku przemysłowym jest kilka prac. Schemat uwierzytelniania i uzgadniania kluczy o podwyższonym poziomie bezpieczeństwa w celu przezwyciężenia tych słabych punktów bezpieczeństwa przy użyciu informacji biometrycznych i kryptosystemu z krzywą eliptyczną. Firma Aluthors zaproponowała trójskładnikowy schemat uwierzytelniania i umowy klucza, który zapewnia niemożność wyśledzenia inicjatora. Podobnie trójskładnikowe uwierzytelnianie środowisk IoT dla sieci WSN, wykorzystujące dane biometryczne do zarządzania informacjami biometrycznymi, przyjmuje rozmyty schemat zobowiązań i koryguje kody błędów. Lekki protokół zdalnego uwierzytelniania użytkowników, wykorzystujący architekturę opartą na węźle bramy dla środowiska IoT, wymaga, aby użytkownik najpierw zarejestrował się za pośrednictwem węzła bramy. Ponadto, korzystając z koncepcji trójczynnikowej, schematu umów o kluczowanie uwierzytelnianych przez nowego użytkownika, tylko autoryzowani użytkownicy mogą uzyskać dostęp do usług określonych urządzeń wykrywających IoT zainstalowanych w środowisku IIoT. W innym artykule dokonano głównie przeglądu i analizy trzech protokołów czynników uwierzytelniania. Ulepszony protokół 3-AKE udowodnił swoje bezpieczeństwo w ulepszonym modelu bezpieczeństwa. Autorzy wprowadzają również trójskładnikowy przemysłowy protokół uwierzytelniania użytkowników WSN. Czwarta rewolucja przemysłowa, I4.0, to integracja z IIoT, która ma ujrzeć cyfrową transformację produkcji. Użycie wielu technik w I4.0 może prowadzić do ogromnych problemów, które mogą sprawić, że usługi będą nieistotne. Niektóre z napotkanych wyzwań wyjaśniono w poniższych akcjach.
Problemy z przetwarzaniem mgły
Przetwarzanie mgły to przede wszystkim rozszerzenie przetwarzania w chmurze na obrzeżach sieci, które umożliwia tworzenie nowych aplikacji i usług związanych z przemysłem 4.0. Ten nowy paradygmat obliczeniowy nie jest jeszcze w pełni zdefiniowany i należy wziąć pod uwagę kilka wyzwań, takich jak poniższe.
• DoS: DoS lub DDoS to kroki, przez które system lub aplikacja nie mogą zostać udostępnione. I4.0 opiera się na dużej liczbie połączonych systemów i procesów; w tych środowiskach ataki DoS stanowią bardzo poważne zagrożenie. Ponadto, ponieważ przetwarzanie w chmurze staje się popularne i szeroko stosowane w koncepcji inteligentnej fabryki, coraz więcej hakerów prawdopodobnie znajdzie nowe sposoby wykorzystania luk w systemie, takie jak zastosowanie DoS. Firma może ponieść wysokie koszty w wyniku cyberataku DoS. Atak ten powoduje szkody materialne (serwery i czujniki muszą zostać wymienione lub przywrócone do normalnej pracy; konieczne jest przeprogramowanie sieci; należy przeprojektować systemy), a także powoduje szkody finansowe i operacyjne (zakłócenia usług, złożone protokoły wznawiania, nowe szkolenia dla operatorów maszyn ). Należy zaproponować podejście do ataków DoS.
• Przemysłowa rzeczywistość rozszerzona (IAR): Oczekuje się, że rozwiązania IAR zapewnią dynamiczne, szybkie reakcje na żądanie ze zdalnych serwerów w fabryce I4.0. Takie informacje mogą również różnić się wielkością ładunku, ponieważ urządzenia IAR mogą żądać kilku megabajtów wideo z zaledwie kilku kilobajtów treści tekstowej. Dlatego systemy IAR muszą nie tylko zapewniać funkcjonalność rozszerzonej rzeczywistości (AR), ale także umożliwiać jak najszybszą wymianę i zarządzanie treścią.
Problemy z Big Data
Big data jest ważną kwestią dla badaczy w I4.0 i oferuje możliwości w każdej dziedzinie badań. Big data z różnymi systemami wiąże się z wieloma wyzwaniami, które opisano poniżej:
• Transformacja danych: Dane branżowe są generowane głównie przez dane maszynowe. Programowalny sterownik logiczny (PLC) odbiera i generuje dane elektryczne i fizyczne. Ponieważ w produkcji generowane są heterogeniczne dane, należy je przekształcić w odpowiednią formę interoperacyjności, aby wnioskować lub przewidzieć awarię maszyny na podstawie dużych archiwów. W celu komunikacji między procesami dane muszą być przekształcane i czyszczone w różnych sytuacjach w tym samym formacie. Aby zdalnie sterować zrobotyzowanymi maszynami online, dane muszą zostać przekształcone w formy wizualne dla operatorów maszyn. W I4.0 wykorzystanie inteligentnej technologii wymaga przekształcenia danych do formatu zgodnego z różnymi inteligentnymi urządzeniami. Wyzwaniem dla I4.0 jest zachowanie wszystkich tych danych przed i po transformacji.
• Integracja i modelowanie danych: interoperacyjność jest kluczową zasadą automatyzacji w I4.0, gdzie komunikuje się kilka typów urządzeń. Wyzwaniem jest zintegrowanie różnych typów danych generowanych na jednej platformie w celu szybkiej produkcji. Do procesów w czasie rzeczywistym, komunikacji i gromadzenia danych do integracji ze zdalnymi maszynami i CPS jest wymagane. Integracja danych to proces opóźniający w rozproszonym systemie pamięci masowej. Integracja danych, gdzie wymagane jest działanie w czasie rzeczywistym, jest ważna dla zdalnie zarządzanych i obsługiwanych maszyn. Projektowanie przemysłowych aplikacji 4.0 i przemysłowych aplikacji internetowych wymaga spójnych modeli danych, które są niezawodne, skalowalne i bezpieczne. Od zbierania danych do użytkowników końcowych, wszystkie atrybuty muszą być określone. Przemysł 4.0 jest trudny do kontrolowania, obsługi zautomatyzowanych procesów i szacowania kosztów produktu, integracji i modelowania przemysłowych dużych zbiorów danych.
• Dostęp w czasie rzeczywistym: I4.0 skupia się na dostępie w czasie rzeczywistym do przemysłowych dużych zbiorów danych. Dostęp w czasie rzeczywistym jest niezbędny dla cyber-fizycznych systemów czujników, siłowników i innych urządzeń. Potrzebny jest dostęp w czasie rzeczywistym do przemysłowych big data, aby obsłużyć je w jak najkrótszym czasie, aby inteligentnie tolerować błędy i wykrywać awarie. Przepustowość sieci musi być szybka i rozładowana. Gdy urządzenia fizyczne są zdalnie sterowane, jeśli są opóźnione, powoduje to problem dla kolejnych urządzeń fizycznych, ponieważ wszystkie siłowniki działają w określonej kolejności czasowej.
• Bezpieczeństwo i prywatność: Dwa główne problemy w świecie dużych zbiorów danych to bezpieczeństwo i prywatność. Szybko rosnąca ilość heterogenicznych danych I4.0 oraz przejście na chmurę zwiększają ryzyko bezpieczeństwa. Dane przed zagrożeniami zewnętrznymi muszą być zabezpieczone. Ze względu na zdalne sterowanie urządzeniami fizycznymi ryzyko danych przemysłowych jest wyższe niż w przypadku innych normalnych systemów danych. Haker może kontrolować maszynę fizyczną, ponieważ wszystkie rzeczy są zdalnie sterowane w I4.0 za pośrednictwem portalu internetowego. Kluczowymi problemami dla I4.0 są zatem uwierzytelnianie danych i prywatność.
• Analiza danych: od ostatniej dekady analiza dużych zbiorów danych jest kluczową dziedziną nauki o danych. Jest to połączenie informatyki, matematyki, statystyki i uczenia maszynowego. Ekstrakcja danych z przemysłowych big data zmusiła przedsiębiorców do wzięcia tego pod uwagę przy planowaniu i podejmowaniu decyzji w branży w przyszłości. Główne obszary związane z przemysłową analityką Big Data to analiza oszustw, systemy rekomendacji, wykrywanie awarii przemysłowych, eksploracja procesów, zarządzanie, dane maszynowe, transport oraz analiza rynku. Różne urządzenia fizyczne wymagają szybkiej analizy w czasie rzeczywistym heterogenicznego tworzenia danych. Niekompletność jest problemem w analizie w czasie rzeczywistym i wymaga algorytmów, które przed analizą wymagają wstępnego przetworzenia danych. Skalowalność analizy jest również wyzwaniem, ponieważ dane są zwiększane wraz z produkcją.
Problemy z interoperacyjnością
Ta sekcja traktuje interoperacyjność jako jedno z wymagań dla I4.0, aby promować "inteligentną interoperacyjność" dla urządzeń. Ten czynnik nie został jeszcze całkowicie osiągnięty, więc niektóre problemy nadal wymagają rozwiązania:
• Integracja: Spółdzielcze systemy produkcyjne obejmują dużą liczbę systemów informatycznych rozproszonych w odniesieniu do maszyn fizycznych za pośrednictwem dużych złożonych architektur sieciowych, takich jak Cooperative Enterprise Information Systems (CEIS), które mają dostęp do szerokiego zakresu informacji i muszą współdziałać, aby osiągnąć swój cel. Architekci i programiści CEIS mają trudny problem z interoperacyjnością. Rośnie zapotrzebowanie na ścisłą integrację takich systemów z pracami organizacyjnymi i produkcyjnymi, aby te systemy informatyczne mogły być w pełni, bezpośrednio i natychmiastowo wykorzystywane przez procesy między przedsiębiorstwami.
• Łańcuchy dostaw: Nieliczny zbiór czujników i elementów wykonawczych służy do optymalizacji ich łańcucha wartości zarówno na liniach produkcyjnych, jak i łańcuchach dostaw. Dlatego urządzenia odgrywają centralną rolę w tych liniach produkcyjnych, które są coraz bardziej złożone i wymagają ekstremalnego (jeśli nie niemożliwego) monitorowania i kontroli przez człowieka. Ten problem wymaga odpowiedniego rozwiązania
Problemy z GraphQL
Wrapper GraphQL musi zaimplementować niezbędne mechanizmy uwierzytelniania API. Zapewniamy obsługę (a) klucza API i podstawowego uwierzytelniania oraz (b) OAuth 2 i OpenID Connect w wrapperach GraphQL.
• Klucze API i podstawowe uwierzytelnianie: Przeglądarki uwierzytelniania umożliwiają przekazywanie użytkownikom informacji uwierzytelniających (klucze API, nazwa użytkownika i hasło). Typy przeglądarek są specyficznymi GraphQL (Input), które otaczają wszystkie inne typy obiektów GraphQL (Input), które wymagają uwierzytelnienia w swoich funkcjach rozpoznawania. Przeglądarki definiują obowiązkowe argumenty APIKey i hasło dla wszystkich zawartych typów podrzędnych i propagują ich wartości do funkcji rozpoznawania. W zapytaniach GraphQL widzowie umieszczają poufne dane uwierzytelniające, które wymagają dedykowanych mechanizmów bezpieczeństwa (tj. szyfrowania transportu).
• OAuth 2 i OpenID Connect: OAuth 2 to struktura autoryzacji, w której użytkownicy mogą uwierzytelniać i autoryzować określone działania aplikacji na serwerze usług OAUTH innej firmy. Aplikacje są rejestrowane na serwerze OAUTH, a użytkownicy są następnie przekierowywani na serwer. Użytkownicy uwierzytelniają się za pomocą serwera OAUTH, który zwraca tokeny dostępu do aplikacji. Tokeny służą do interakcji z chronionymi zasobami. OpenID Connect to warstwa powyżej OAuth 2, która zaleca użycie JSON Web Token dla opakowań GraphQL, równoważnych OAuth 2. Opisany powyżej przepływ jest niezależny od opakowania GraphQL, ale opiera się na aplikacji w celu uzyskania tokenów niezbędnych do aplikacja (np. serwer, na którym znajduje się wrapper GraphQL). Funkcje rozpoznawania opakowań GraphQL muszą (a) być w stanie uzyskać dostęp do tokena z aplikacji i (b) wysyłać te tokeny do docelowych żądań interfejsu API REST (podobnych), zazwyczaj umieszczając je w nagłówku autoryzacji.
Problemy z łańcuchem bloków
Wraz z pojawieniem się nowej rewolucji procesy przemysłowe stoją w obliczu poważnych zmian I4.0. Spełnione są warunki, aby przyspieszyć i ulepszyć koncepcje tej nowej rewolucji poprzez technologię blockchain zaimplementowaną w tym środowisku. Ale BC jest wciąż nową technologią i stoi przed wieloma wyzwaniami, takimi jak:
• Jakość usług: Nieodłączne zaufanie do wartości QoS nie jest dobrym pomysłem w rzeczywistych zastosowaniach. Istnieje również szereg wyzwań i zagrożeń dla scentralizowanych organów, w tym skalowalność, wysokie koszty utrzymania, zarządzanie atakami DDoS, pojedynczy punkt awarii, oszustwa i zaufanie. Rząd centralny również stoi przed szeregiem wyzwań i zagrożeń. Ponadto technologie EaaS IoT, SoA i Cloud rozszerzają wykładniczo usługi rozproszone geograficznie w Internecie. Zarządzanie certyfikatami cyfrowymi opartymi na atrybutach jest operacyjne i niedrogie, ponieważ wartości QoS są dynamiczne i wymagają aktualizacji i weryfikacji w czasie rzeczywistym.
• Ochrona prywatności i anonimowość: proste hasło uwierzytelniające, jak omówiono powyżej, nie może chronić prywatności prawdziwych tożsamości terminali, ponieważ złośliwa chmura może w trywialny sposób zidentyfikować terminal na podstawie codziennej aktywności poprzez interakcje .
• Precyzyjna kontrola dostępu: Integracja pewnych strategii, takich jak tabela mapowania ról użytkownika i tabela autoryzacji ról, zazwyczaj prowadzi do szczegółowej kontroli dostępu. Jednak ataki w chmurze są podatne na podejścia oparte na użyciu tych tabel, ponieważ chmura opiera się na tych podejściach.
• Integralność i poufność: Lokalna baza danych w chmurze rejestruje/przechowuje historię dostępu do terminali, jak omówiono wcześniej. Istnieje zatem ryzyko, że może nastąpić nieautoryzowany dostęp i modyfikacja takich baz danych. W związku z tym trudno jest osiągnąć identyfikowalność i możliwość kontroli rekordów dostępu.
• Komunikacja z wieloma agentami: liczba agentów autonomicznych znacznie wzrasta w procesach biznesowych, kosztach transakcji i ryzyku związanym z błędami przesyłania informacji między systemami informatycznymi. Rosną również koszty, ponieważ kontrola nad agentami jest scentralizowana, a awaria systemu lub schwytanie intruzów prowadzi do paraliżu pracy.
Problemy z SDN
Zakłada się, że maszyna produkcyjna "Pre-Industry 4.0" ma bardzo małą łączność z Internetem; dlatego mają bardzo ograniczone zastosowanie i nie spełniają wymagań bezpieczeństwa wymaganych do połączenia z Internetem.
• Bezpieczeństwo: I4.0 bada SDN, ponieważ może inteligentnie zautomatyzować różne zadania, takie jak administratorzy użytkowników, routing, kontrola, bezpieczeństwo i konfiguracja, ale nie tylko dla nich. Zadania te można wykonywać również przy użyciu tradycyjnych, własnych urządzeń sieciowych nie opartych na SDN, takich jak przełączniki i routery. Autorskie urządzenia sieciowe są statyczne w określonym obszarze sieci, niezbędne do skonfigurowania każdego z nich indywidualnie, złożone (część sprzętowa urządzenia zawiera miliardy bramek, a ponad 6000 standardowych dokumentów jest wdrażanych w części programowej sieci). systemów i aplikacji) i nie jest programowalny (nie zawiera otwartych/standardowych interfejsów API) i jest trudne do użycia.
• Monitorowanie w czasie rzeczywistym: Branże muszą być w stanie wykonywać liczne obliczenia, przesyłać dane z dużą szybkością oraz łatwo zarządzać wysoce wydajnymi i niezawodnymi danymi poprzez ogromne ilości przetwarzania danych i złożone operacje. Niezbędna jest infrastruktura monitorowania Big Data
Problemy z Kerberos
Jest to protokół uwierzytelniania, który umożliwia klientowi i serwerowi wzajemne uwierzytelnianie się za pośrednictwem niezaufanego połączenia sieciowego. Bezpieczeństwo, co oznacza zachowanie środowiska fizycznego, na przykład ludzi, infrastruktury, maszyn i urządzeń, jest prawie takie samo dla przemysłu IoT. Celem Industrial IoT jest zapewnienie szybkiego i aktualnego przeglądu bieżących zmian IoT w I4.0, w tym CPS, IoT, przetwarzania w chmurze i obliczeń kognitywnych. W tej sekcji przedstawiono aktualne i nowe technologie Kerberos. Schemat uwierzytelniania Kerberos był szeroko stosowany w wielu technologiach, takich jak WSN, Smart Home, przetwarzanie w chmurze i Internet. Tak więc niektóre problemy, takie jak poniższe, pozostają w schemacie.
• DoS: Ataki DOS nie zostały rozwiązane przez Kerberos. Dlatego DoS jest podatny na część internetową systemu. Tak więc Kerberos używany w sieciach internetowych był pilnie potrzebny do zapobiegania atakom DoS.
• Synchronizacja czasu: Każda zasada sieci musi mieć zegar, który jest luźno zsynchronizowany z innymi zasadami, aby koszty czasu protokołu Kerberos były wysoce określone i brane pod uwagę.
• Koszt obliczeń: ECC jest prymitywną operacją kryptograficzną, która jest używana do szyfrowania informacji użytkownika, ale jest znana z wysokich obliczeń podczas obliczania haszowania, parowania i mnożenia. W kryptografii krzywych. Dlatego koszty obliczeń muszą być efektywne.
• Transfer plików: Przy kosztach komunikacji kryptografii krzywych eliptycznych, transfer plików lub danych między podmiotami trwa dłużej, co oznacza, że transfer danych jest powolny, więc mechanizm musi pomóc w zwiększeniu transferu danych.
• Prywatność: Implementacja systemu Kerberos Protocol Intrusion Detection System może umożliwić atakującym manipulowanie danymi użytkownika i informacjami osobistymi. Modyfikacja może następnie zostać przechwycona i wykorzystana do złośliwego spersonalizowania użytkownika i zapewnienia prywatności użytkownika za pomocą dodatkowych metod.
• Duża liczba urządzeń: obciążenie bazowej infrastruktury sieciowej jest zwiększane przez dużą liczbę inteligentnych systemów wdrożonych w SG-IIoT. Aby osiągnąć zaufany przepływ danych w czasie rzeczywistym, infrastruktura komunikacyjna musi mieć niestandardowy paradygmat zarządzania siecią, który obsługuje interoperacyjność między różnymi urządzeniami inteligentnymi używanymi w systemach SG.
• Jednokrotne logowanie/hasło jednorazowe: Kerberos to ważna funkcja. Tylko raz klient musi wpisać hasło z jednokrotnym logowaniem (SSO). Bilety klienta, takie jak bilet przyznający bilet (TGT) i serwer przyznający bilet (SGT) są przechowywane na komputerze klienta w pamięci podręcznej. Nasze porównanie pokazuje, że większość istniejących systemów nie obsługuje OTP/SSO i dlatego należy wziąć pod uwagę rzeczy związane z IoT.
• Poufność: Poufność jest jednym z wymagań protokołu Kerberos. W każdym schemacie uwierzytelniania, który zależy od protokołu Kerberos, bardzo ważne jest, aby to rozważyć. Ostatnio zaproponowano wiele metod w zakresie bezpieczeństwa i prywatności, ale poufność środowiska sieciowego pozostaje ważnym wyzwaniem.
Problemy z uwierzytelnianiem dwuskładnikowym
Uwierzytelnianie dwuskładnikowe to popularna praktyka uwierzytelniania użytkownika przed zezwoleniem na dostęp do właściwego systemu. Uwierzytelnianie dwuskładnikowe zwykle wymaga, aby użytkownik dostarczył dwa lub dwa różne czynniki wiedzy (np. coś, co użytkownik znał, takie jak hasło, odpowiedź na pytanie), czynnik nieodłączny (np. coś, co użytkownik posiada, takie jak odcisk palca, skanowanie siatkówki, inne dane biometryczne). Podwyższony poziom bezpieczeństwa uwierzytelniania dwuskładnikowego, kontroli dostępu do wielu zasobów cybernetycznych w branżach infrastruktury (np. systemy komputerowe, bazy danych, sprzęt) pozostaje stosunkowo podstawowy.
• Podatny na ataki: Wiele istniejących dwóch schematów uwierzytelniania zapewnia bezpieczny system uwierzytelniania w literaturze. Jednak nie wszystkie z proponowanych systemów spełniają właściwości bezpieczeństwa środowisk IoT i przemysłowych, które są nadal podatne na wiele aktywnych ataków (Sinkhole, Sybil, Replay.MiTMs, Forward Secrecy, atak polegający na zgadywaniu hasła, DoS, atak fizyczny i ataki personifikacji).
• Zachowanie prywatności: Zachowanie prywatności oznacza zachowanie danych osobowych dotyczących poszczególnych użytkowników (np. tożsamości użytkownika, kluczy osobistych). Prywatność jest ważna dla zapewnienia braku możliwości powiązania, anonimowości i niewykrywalności w schematach uwierzytelniania dwuskładnikowego. Jednak tej technice nadal brakuje poufności i potrzebny jest skuteczny system, aby sprostać temu wyzwaniu.
• Uwierzytelnianie wzajemne: Odnosi się do dwóch podmiotów, które jednocześnie uwierzytelniają się nawzajem. W IoT, Industrial nie wystarczy tylko autoryzacja nadawcy względem odbiorcy, ale nadawca powinien również zapewnić, że ewentualny odbiorca danych wrażliwych jest zidentyfikowany i autoryzowany. Dlatego uwierzytelnianie powinno być prawdopodobnie wzajemnie uwierzytelniane, aby zapewnić bezpieczeństwo domeny. Istniejące systemy nie obejmują jeszcze wzajemnego uwierzytelniania; dlatego należy to uwzględnić w nadchodzących propozycjach.
• Synchronizacja czasu: Konieczna byłaby zatem szeroka synchronizacja czasu w sieci, wprowadzająca dodatkową złożoność i zużycie zasobów. A użycie znacznika czasu może być nawet poważnym problemem w bardziej zaawansowanych środowiskach, ponieważ awaria synchronizacji sprawia, że protokół jest podatny na ataki. W rezultacie wiele istniejących systemów nadal nie korzysta z synchronizacji czasu i należy się nimi zająć.
• Koszt obliczeń: w literaturze fakt korzystania z różnych metod zwiększania prywatności i bezpieczeństwa może zwiększyć koszty obliczeniowe systemu. Dlatego autorzy muszą wziąć pod uwagę obliczenia, ponieważ mogą one prowadzić do podatności systemu na ataki, takie jak DoS i inne dane użytkownika, które należy obsłużyć w celu osiągnięcia wysokiego zagęszczenia transportu lub złośliwych stron.
• Zaufana firma trzecia: Przeciwnicy, którzy mają dostęp do zaufanego urządzenia, mogą próbować wyodrębnić dane przechowywane na urządzeniu należącym do zaufanej firmy zewnętrznej. Przeciwnicy mogą również próbować wydobyć dane z czujników z nieakceptowalnego urządzenia. Dlatego w celu ochrony prywatności użytkowników należy korzystać z alternatywnej strony zaufanej.
• Formalna weryfikacja/analiza: Schemat nie jest formalnie zapewniony przez brak weryfikacji proponowanych schematów. Ze względu na solidność narzędzi kontroli formalnej, schematy muszą zapewniać ich poprawność. Dlatego uwierzytelnianie dwuskładnikowe wymaga formalnej weryfikacji/analizy w celu zapewnienia bezpieczeństwa systemu.
Problemy z uwierzytelnianiem trójskładnikowym
Uwierzytelnianie trzema czynnikami to rozbudowany pomysł na dwa czynniki uwierzytelniania i ogólnie: to, czego jesteś świadomy (tj. hasło), co masz (tj. karta inteligentna, telefon) i kim jesteś. Ustalono jednak, że pomysły na uwierzytelnianie trójskładnikowe pokonają wyzwania związane z uwierzytelnianiem dwuskładnikowym. Pomysł ten jest jednak wciąż we wczesnej fazie i może napotkać problemy. W tej sekcji wyjaśniono niektóre problemy.
• Podatny na ataki: Słabość istniejących systemów 3FA jest oczywiście podatna na nieużywane znaczne ataki w porównaniu z literaturą. Chociaż ich schemat ma wiele do zaoferowania, nadal ma pewne słabości, takie jak odchylenie, hasło wewnętrzne, podszywanie się, śledzenie ataków, uprzywilejowane ataki wewnętrzne, atak na hasło, aktualizacje biometryczne, atak na wykrywanie urządzeń, atak na sesję równoległą i atak słownikowy. Własność bezpieczeństwa jest zatem ważna dla ochrony systemu i konieczne są nowe modele przezwyciężania tych luk.
• Poufność przekazywania: jest to funkcja protokołów uzgadniania kluczy, która zapewnia, że klucz sesji nie zostanie naruszony, nawet jeśli zostanie naruszony klucz prywatny serwera. Wystarczy osiągnąć doskonałą tajność w systemach 3FA, aby nie mógł używać długoterminowych kluczy prywatnych do obliczania wcześniej ustalonych kluczy sesji. Jednak w większości obecnie stosowanych systemów brakuje PFS i wydajnej konstrukcji.
• Ochrona prywatności: Z punktu widzenia literatury zauważyliśmy, że poprzednie proponowane metody ucierpiały na identyfikowalności i łączności. Dlatego ważne i konieczne jest ulepszenie schematów, aby zapewnić prywatność każdego użytkownika (niemożność namierzenia, odłączenie i anonimowość).
• Odwołalność: Kiedy użytkownik został naruszony i usunięty z systemu, Gateway usuwa tożsamość wpisanego użytkownika ze swojej bazy danych. Jeśli niesubskrybowany użytkownik spróbuje uzyskać dostęp do węzłów bramy, weryfikacja nie zostanie przekazana. Zauważamy jednak, że obecny system jest podatny na odwołanie i nie został wdrożony. Pilnie potrzebny jest schemat, aby zapobiec odwołaniu, aby przejść kontrolę, jeśli użytkownik spróbuje ponownie się zalogować.
• Problem z synchronizacją zegara: Pod wieloma względami synchronizacja zegara była powszechna i takie użycie może prowadzić do poważnego zagrożenia. A to może jeszcze bardziej zwiększyć koszt obliczeń. Tego problemu można uniknąć dzięki ulepszeniu lub zaproponowanemu modelowi.
Przyszłe kierunki
Ta sekcja przedstawia krótkie wskazówki z literatury, aby złagodzić problemy programistów, badaczy, przemysłu/fabryk w różnych dziedzinach I4.0.
Wskazówki dla dewelopera/projektanta
Ze względu na rozwój I4.0 przyszłe kierunki pomagają w opracowywaniu rozwiązań przez programistów i projektantów z problemami technicznymi w użytkowaniu różnych urządzeń I4.0. Jednak wykorzystanie prototypu Big Data może być wykorzystane w praktycznych scenariuszach przypadków użycia do dalszego zbadania jego wydajności i zbadania jego potencjału. W związku z tym można wykorzystać metody eksploracji danych i uczenia maszynowego do automatycznego uczenia się wzorców . Aby uzyskać więcej komponentów i usług związanych z bezpieczeństwem, w przyszłych projektach przemysłowych należy wykorzystać innowacyjną platformę, nie mówiąc już o I4.0. Oprócz filtrowania czasowego Transparent Firewall wdraża system kontroli dostępu oparty na standardzie OPC UA i przeprowadza testy bezpieczeństwa w celu sprawdzenia wykonalności propozycji. Oczywiście potrzebne są dalsze badania, aby opracować takie rozwiązania, które są wystarczająco przejrzyste i niezawodne, aby można było im zaufać w systemach automatyki i technologii operacyjnej, ale jest to interesująca okazja do opracowania rozwiązania, które będzie miało zastosowanie w wielu dziedzinach normalizacji. Należy również opracować prototypową implementację lekkiego łańcucha bloków (LSB), aby uzyskać jej wydajność w warunkach rzeczywistych. Należy zaprojektować zastosowanie BC do rozwiązania problemu wymiany danych i handlu, które muszą zostać wdrożone.
Wskazówki dla badaczy
Ta sekcja przedstawia badaczom kierunki badawcze w określonych obszarach I4.0. W I4.0 przyszłe badania nad szerszymi obszarami problemowymi powinny dotyczyć bardziej wydajnych algorytmów z zaawansowanymi technikami, takimi jak koewolucja, optymalizacja wielocelowa i rozkład. Badania powinny dotyczyć wyzwań zidentyfikowanych w aplikacjach, które są trudne lub niemożliwe do rozwiązania w modelu procedury analizy cyberbezpieczeństwa Algorytm może być wykorzystany do skutecznego wykrywania cyberataków na systemy I4.0 i może być połączony z aktywnymi mechanizmami reagowania w celu powstrzymania prawdziwych cyberataków . Więcej badań powinno koncentrować się na dodatkowych eksperymentach i wdrożeniu konkretnego łańcucha bloków za pomocą inteligentnych kontraktów opartych na IoT. Ponadto badania muszą określić, w jaki sposób zarządzać ograniczonymi zasobami obliczeniowymi i energetycznymi niektórych urządzeń przemysłowych, które stają się krytycznym problemem, jeśli blockchain jest używany w systemach przemysłowych w wyniku procesu wydobywczego. Należy również zintegrować wydajny framework z systemem zarządzania procesami biznesowymi (BPM), aby zautomatyzować ocenę i weryfikację wiarygodności w doborze i kompozycji usług, dodatkowo implementacja mechanizmu blockchain w symulatorze wraz z odpowiednimi algorytmami i modelem matematycznym jest odpowiedni. W przyszłych badaniach należy również zbadać zdolność uproszczonej architektury chmury definiowanej programowo do indukowania nowych rodzajów cyberbezpieczeństwa w systemach I4.0. Jeśli chodzi o filtrowanie przestrzenne, w standardowej usłudze OPC Discovery Service brakowało informacji o wykrywaniu dla aplikacji klienckich, dlatego należy przeprowadzić dalsze badania w celu automatycznego generowania list dostępu. Badacz powinien zbadać mechanizm, który w pełni wspiera wykorzystanie zdecentralizowanych serwerów AAA. Można przeprowadzić inne badanie w celu ulepszenia OPL, aby uczynić go bardziej naturalnym dla ludzkich czytelników i odwołaj się do niego. Badacz powinien również ulepszyć trzypoziomowe uwierzytelnianie Kerberos, aby mogło być szybsze. Dodatkowe badania powinny również przeanalizować i wyodrębnić specyficzne wymagania dotyczące bezpieczeństwa i prywatności aplikacji opartych na IoT. Całkowicie zdecentralizowany .Należy zająć się schematem uwierzytelniania VANET, zachowując odpowiednią wydajność. Ponieważ WSN jest ważne w wielu inteligentnych środowiskach, takich jak inteligentna sieć, inteligentna opieka zdrowotna i inteligentne systemy transportowe, naukowcy muszą zbadać systemy bezpieczeństwa IoT.
Dojazd do branż/fabryk
W tej części przedstawiono ważne kierunki dla przemysłu i fabryk w różnych obszarach badawczych. Większość kierunków dotyczy bezpieczeństwa, prywatności i technologii komunikacji bezpieczeństwa I4.0. Dalsze badania powinny zapewnić odpowiedź o niskim opóźnieniu poprzez zmieszanie elementów obu paradygmatów obliczeniowych, co może umożliwić opracowywanie przyszłych aplikacji IAR dla I4.0 w czasie rzeczywistym. Potrzebne są dalsze badania, aby rozwiązania były wystarczająco przejrzyste i niezawodne, aby opierać się na automatyzacji i technologii operacyjnej, ale jest to ważna okazja do opracowania rozwiązania, które można zastosować w trakcie normalizacji. W zintegrowanym systemie, takim jak sposób, w jaki niektóre urządzenia przemysłowe zarządzają ograniczonymi zasobami obliczeniowymi i energetycznymi, staje się to krytycznym problemem, gdy blockchain jest stosowany w systemach przemysłowych w wyniku procesu wydobywczego. Konieczne są dalsze badania w celu zaprojektowania lekkiego, solidnego i skalowalnego schematu haseł jednorazowych (OTP) na prawdziwej platformie IoT. Dla uprzywilejowanego dostępu roota i dostęp zdalny, wymagane są uwierzytelnienia dwuskładnikowe. Eliminuje to słabe hasła lub konta zdefiniowane przez użytkownika w celu uzyskania dostępu. W zintegrowanym systemie, takim jak sposób, w jaki niektóre urządzenia przemysłowe zarządzają ograniczonymi zasobami obliczeniowymi i energetycznymi, staje się to krytycznym problemem, gdy blockchain jest stosowany w systemach przemysłowych w wyniku procesu wydobywczego. Konieczne są dalsze badania w celu zaprojektowania lekkiego, solidnego i skalowalnego schematu haseł jednorazowych (OTP) na prawdziwej platformie IoT. Dla uprzywilejowanego dostępu roota i dostęp zdalny, wymagane są uwierzytelnienia dwuskładnikowe. Eliminuje to słabe hasła lub konta zdefiniowane przez użytkownika w celu uzyskania dostępu
Wniosek
Ta część analizuje problemy cyberbezpieczeństwa w kontekstach I4.0, stosując ustrukturyzowane podejście do przeglądu literatury poprzez analizę jakości treści ostatnich badań. Ocena koncentruje się w szczególności na pięciu obszarach analitycznych: (1) definicji podatności systemu, cyberzagrożeń, ryzyka, ekspozycji, ataków i środków zaradczych w kontekście scenariuszy I4.0; (2) określenie głównych celów bezpieczeństwa i prywatności; (3) definicja technik w I4.0, zintegrowana w tych dziedzinach; (4) klasyfikować zagadnienia w I4.0; oraz (5) kategoryzować przyszłe kierunki w środowisku. Zapotrzebowanie na cyberbezpieczeństwo w I4.0 rozszerzy się w przyszłości nie tylko na kilka infrastruktur, ale także na obszar konsumencki z przemysłowym IoT, gdzie prywatność i ochrona fizyczna mają większe znaczenie, zwłaszcza tam, gdzie przeciwnicy mogą uzyskać do nich fizyczny dostęp. W tej sekcji przedstawiliśmy przegląd i tło dotyczące cyberbezpieczeństwa I4.0. Przedstawiono również otwarte zagadnienia i przyszłe kierunki związane z cyberbezpieczeństwem I4.0.
Oparty na IoT system monitorowania akwizycji danych dla panelu fotowoltaicznego
Internet rzeczy (IoT) jest znany jako rozszerzenie łączności internetowej dla urządzeń fizycznych, które jest używane na co dzień. Dzięki tej przewadze technologia IoT jest szeroko stosowana w wielu zastosowaniach, a ta, która jest szeroko wdrażana, dotyczy układu słonecznego. Ponieważ technologia systemów słonecznych rozwinęła się w kierunku skutecznego monitorowania w czasie rzeczywistym, elementy takie jak zbieranie danych i monitorowanie są bardzo ważne dla głębokiego zrozumienia zainstalowanego systemu słonecznego. Aby skutecznie monitorować zainstalowany układ słoneczny w czasie rzeczywistym, ważne jest również indywidualne monitorowanie każdego elementu, takiego jak panel fotowoltaiczny, kontroler ładowania, system falownika i inne. Dlatego te badania wyjaśniają oparty na IoT system monitorowania akwizycji danych dla słonecznego panelu fotowoltaicznego dla systemu słonecznego. Oparty na IoT system monitorowania akwizycji danych dla panelu fotowoltaicznego składa się z czterech jednostek czujników termoparowych (TC) zintegrowanych ze wzmacniaczem MAX31855, jednej jednostki czujnika prądu/napięcia INA 219 i urządzenia Raspberry Pi Zero Wireless jako menedżera urządzeń. Proponowany system monitorowania akwizycji danych oparty na IoT został opracowany w celu wykrywania, pomiaru i obliczania prądu, napięcia, mocy i temperatury. Informacje te są przechowywane na karcie SD Raspberry Pi Zero Wireless, znanej jako menedżer urządzeń. Przechowywane informacje o prądzie, napięciu, mocy i temperaturze na karcie SD Raspberry Pi Zero Wireless są następnie przesyłane bezprzewodowo do pamięci w chmurze. Informacje te są następnie wyodrębniane do samodzielnie opracowanej witryny internetowej. Informacje można łatwo przeglądać na stronie internetowej i pomagają konsumentom monitorować zainstalowaną instalację fotowoltaiczną, zwłaszcza wydajność panelu fotowoltaicznego. Monitorowanie panelu fotowoltaicznego w czasie rzeczywistym za pomocą systemu monitorowania gromadzenia danych opartego na IoT może skutecznie ułatwić konserwację na poziomie systemu i natychmiastowe wykrywanie usterek.
Projektowanie i rozwój systemu
Tu wyjaśniono proces metodyczny projektowania, integracji i instalacji proponowanego systemu projektowego. Ta metodologia projektu jest podzielona na dwie sekcje: (a) projektowanie i rozwój systemu sprzętowego oraz (b) projektowanie i rozwój oprogramowania. Podczas projektowania i rozwoju systemu sprzętowego wyjaśniana jest metodologia projektu, począwszy od koncepcji koncepcyjnej, aż do realizacji systemu sprzętowego. W przypadku projektowania i rozwoju oprogramowania wdrażana jest architektura IoT w celu gromadzenia wymaganych informacji, a interfejs użytkownika oparty na chmurze jest projektowany i rozwijany w celu monitorowania wszystkich informacji lub wytworzonych danych wyjściowych z opracowanego systemu sprzętowego.
Koncepcyjne rozmieszczenie czujników TC, projekt systemu, integracja i instalacja
Rysunek przedstawia widok z góry koncepcyjnego rozmieszczenia czujnika TC, projektu systemu, integracji i instalacji na module panelu słonecznego.
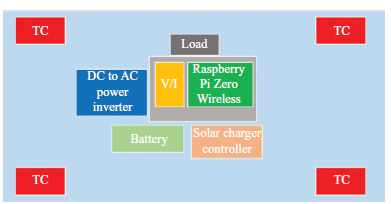
Cały system składa się również z falownika prądu stałego na prąd zmienny, akumulatora jako systemu magazynowania energii (ESS), kontrolera ładowania słonecznego (SCC) i obciążenia w celu przetestowania funkcjonalności systemu. Odnosząc się do rysunku pwyżej i tabeli 15.1,

cztery jednostki czujników TC są zintegrowane ze wzmacniaczem MAX 31855, który ma poprawić czułość i mierzyć temperaturę modułu panelu słonecznego. Czujnik napięcia i prądu, znany również jako czujnik prądu stałego, jest zintegrowany z wyjściowym modułem panelu słonecznego, zwłaszcza z dodatnim przewodem modułu panelu słonecznego, aby wykrywać i mierzyć napięcie i prąd wyjściowy modułu panelu słonecznego. Raspberry Pi Zero Wireless, znany jako system jednopłytkowy, integruje wszystkie cztery czujniki TC zintegrowane ze wzmacniaczem MAX 31855 i czujnikiem prądu DC (czujnik napięcia i prądu). Dane dotyczące temperatury, napięcia i prądu ze zintegrowanych czujników są rejestrowane na karcie micro SD Raspberry Pi Zero Wireless przed przesłaniem tych danych do systemu przechowywania w chmurze. Rysunek przedstawia ogólny projekt architektury systemu, który ma cztery czujniki TC zintegrowane ze wzmacniaczem MAX 31855 i czujnikiem prądu INA 219 DC.
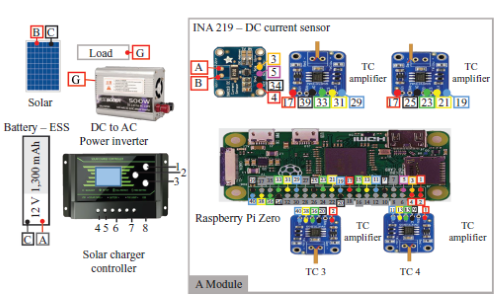
Inne podłączone urządzenia to SCC, przetwornica DC-AC, akumulator - ESS. Tabela przedstawia kolory okablowania systemu pokazanego na rysunku powyżej.
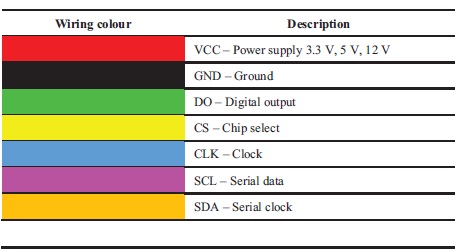
Tabela przedstawia numerację portów dla modelu SCC Z10 pokazanego na rysunku powyżej.
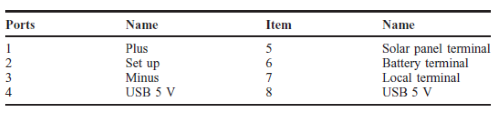
Numeracja portów w modelu SCC Z10 ma umożliwić łączność SCC z akumulatorem - ESS i obciążeniem. W tej sekcji opisano szczegółowe wyjaśnienie połączeń każdego komponentu, odnosząc się do rysunku powyższego. Wyjście +12 V portu B modułu panelu słonecznego jest wprowadzane do portu B w czujniku prądu INA 219 DC, a port wyjściowy A w czujniku INA 219 DC jest podłączony do portu wejściowego A akumulatora - ESS. -12 V port C akumulatora - ESS jest podłączony do ujemnego portu C modułu panelu słonecznego. Tabela wyjaśnia podłączenie wyjścia czujnika napięcia/prądu INA 219 do Raspberry Pi Zero Wireless.
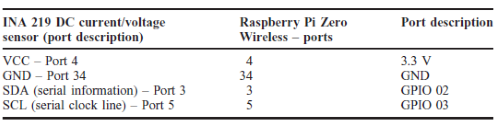
Numeracja portów w czujniku napięcia/prądu INA 219 odnosi się do portów w Raspberry Pi Zero Wireless. Dlatego port 4 - VCC i port 34 GND w czujniku napięcia/prądu INA jest podłączony do portu 4 -3,3 V i portu 34 - GND w Raspberry Pi Zero Wireless. Port 3 - SDA (informacje szeregowe) i port szeregowy linii zegarowej (SCL) w czujniku napięcia/prądu INA 219 jest podłączony do portu 3 - GPIO 02 i portu 5 - GPIO 03 w Raspberry Pi Zero Wireless.
Sprzęt: projektowanie, integracja i instalacja systemu czujników
Tabela wyjaśnia czujniki TC (TC1, TC2, TC3 i TC4) zintegrowanych z łącznością portów wyjściowych wzmacniacza MAX31855 z portami Raspberry Pi Zero Wireless. Zgodnie z rysunkiem 15.2, czujniki TC1, TC2, TC3 i TC4 TC są podłączone do portów wejściowych wzmacniacza MAX31855. Zgodnie z tabelą , porty 33, 31, 29 wzmacniacza TC1 MAX31855 są podłączone do portów 33 (GPIO 22), 31 (GPIO 27) i 29 (GPIO 17) w Raspberry Pi Zero Wireless. Porty wzmacniacza TC2 MAX31855 23, 21 i 29 są podłączone do portów 23 (GPIO 11), 21 (GPIO 09) i 29 (GPIO 10) w Raspberry Pi Zero Wireless. Porty wzmacniacza TC3 MAX31855 23, 21 i 29 są podłączone do portów 36 (GPIO 23), 38 (GPIO 24) i 40 (GPIO 18) w Raspberry Pi Zero Wireless. Porty wzmacniacza TC4 MAX31855 23, 21 i 29 są podłączone do portów 15 (GPIO 07), 13 (GPIO 12) i 9 (GPIO 08) w Raspberry Pi Zero Wireless.

Projektowanie i rozwój oprogramowania
W tej sekcji omówiono projektowanie i rozwój oprogramowania dla proponowanego systemu sprzętowego oraz graficznego interfejsu użytkownika (GUI). Dla proponowanego systemu sprzętowego opracowano dwa rodzaje oprogramowania. Jednym z nich jest wbudowany projekt oprogramowania opracowany dla fizycznego systemu sprzętowego. Projekt oprogramowania wbudowanego to program lub znany również jako system operacyjny dla proponowanego sprzętu, aby działał zgodnie z potrzebami. Łączy również wszystkie inne komponenty podrzędne z płytą Raspberry Pi Zero Wireless. Inne oprogramowanie jest znane jako tworzenie stron internetowych, które ma na celu stworzenie GUI i stworzenie zaangażowania między użytkownikami a proponowanym systemem sprzętowym.
Integracja z wbudowanym oprogramowaniem - system sprzętowy i strona internetowa Raspberry Pi Zero Wireless
Oprogramowanie wbudowane jest ważnym aspektem tworzenia połączenia pomostowego między opracowanym sprzętem a opracowanym GUI. Właściwe zaprojektowanie wbudowanego oprogramowania zarówno do obsługi sprzętu, jak i interfejsu GUI na stronie internetowej może wydobyć wymagane informacje, takie jak temperatura, prąd i napięcie panelu fotowoltaicznego. Dlatego do tych badań wykorzystywana jest trójwarstwowa architektura IoT.
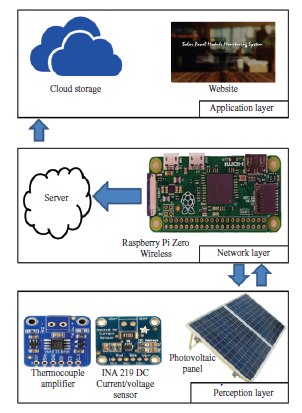
Te trzy warstwy to: (a) percepcja, (b) sieć i (c) zastosowanie. Trójwarstwowe architektury IoT są ogólnie używanymi strukturami zapewniającymi odpowiednią kontrolę nad urządzeniami, przechowywaniem danych i kontrolą zarządzania procesami. Warstwa percepcji to pierwsza warstwa. Warstwa percepcyjna wyjaśnia, jak działają czujniki akwizycji danych, wzmacniacz TC MAX31855 i prąd/napięcie INA 219 DC. Wszystkie czujniki są połączone i sterowane przez menedżera urządzeń, którym jest Raspberry Pi Zero Wireless. Karta sieciowa w Raspberry Pi Zero Wireless służy do tworzenia łączności sieciowej z warstwą sieciową w celu przesyłania danych. Warstwa percepcyjna składa się z czterech czujników TC zintegrowanych ze wzmacniaczem MAX31855, jednego czujnika prądu/napięcia INA219 DC. W warstwie sieciowej Raspberry Pi Zero Wireless łączy proponowany system z Internetem, aby zabezpieczyć połączenie z serwerem pamięci masowej w chmurze. Łączność sieciowa musi mieć moc 2,4 GHz i stabilna.
Projektowanie oprogramowania wbudowanego
W tej sekcji wyjaśniono konstrukcję wbudowanego oprogramowania opracowanego do obsługi czujników i systemu sprzętowego na rysunku wcześnejszym. Odnosząc się do rysunku
,
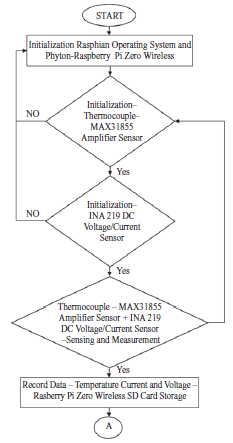
zaprojektowane oprogramowanie wbudowane dla Raspberry Pi Zero Wireless zainicjowało system operacyjny Raspbian. Następnie, do opracowania wbudowanego oprogramowania dla systemu wejścia i wyjścia Raspberry Pi Zero Wireless, używany jest język programowania phyton. Korzystając z języka programowania Phyton, wszystkie czujniki (czujniki TC i prąd/napięcie DC INA 219) są wewnętrznie podłączone (jako wejście) do Raspberry Pi Zero Wireless w celu przeprowadzenia pomiaru i pomiaru temperatury, prądu i napięcia. Zmierzone wartości temperatury, prądu i napięcia są zapisywane na karcie SD Raspberry Pi ZeroWireless. Rysunek przedstawia ciągłą pracę z rysunku wcześniejszego; operacja na rysunku wyjaśnia działanie ekstrakcji danych z systemu przechowywania kart SD Raspberry Pi Zero Wireless do systemu przechowywania w chmurze i strony internetowej.
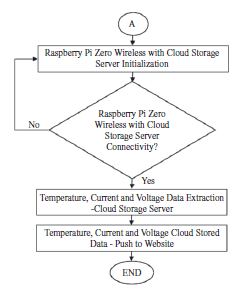
Początkowo system Raspberry Pi Zero Wireless zainicjował łączność z serwerem pamięci masowej w chmurze. Po ustabilizowaniu łączności między Raspberry Pi Zero Wireless a serwerem pamięci masowej w chmurze, informacje o temperaturze, prądzie i napięciu zapisane w pamięci karty SD Raspberry Pi Zero Wireless są następnie wysyłane i zapisywane na serwerze pamięci masowej w chmurze. W przeciwnym razie połączenie zostanie zakończone i wymagana jest ponowna inicjalizacja. Przechowywane informacje o temperaturze, prądzie i napięciu na serwerze przechowywania w chmurze są następnie przesyłane do witryny w celu wyświetlenia. Na stronie internetowej konsumenci mogą indywidualnie monitorować wydajność każdego z paneli fotowoltaicznych. Wszelkie nieprawidłowości można łatwo wykryć, a konsumenci mogą złożyć raport zespołowi konserwacyjnemu w celu przeprowadzenia konserwacji lub wymiany. W tej sekcji wyjaśniono projekt metodologiczny i opracowany sprzęt systemu monitorowania akwizycji danych opartego na IoT w celu analizy wydajności paneli fotowoltaicznych. Proces projektowania i rozwoju rozpoczyna się od pomysłu koncepcyjnego, a następnie rozszerzamy go na rzeczywisty projekt i rozwój sprzętu. Po zakończeniu faktycznego opracowywania sprzętu rozpoczyna się projektowanie oprogramowania wbudowanego do obsługi oprogramowania sprzętowego, przechowywania w chmurze i witryny internetowej. Najpierw opracowywany jest program operacyjny oprogramowania wbudowanego dla sprzętu, a następnie po utworzeniu programu operacyjnego oprogramowania wbudowanego inicjowane jest oprogramowanie wbudowane dla witryny internetowej. Cały ten rozwój odbywa się etapami, ponieważ każdy etap musi działać zgodnie z oczekiwaniami, zanim wszystkie etapy będą mogły zostać zintegrowane w jeden system. Na koniec, po sprawdzeniu poprawności działania każdego etapu, wszystkie etapy są łączone, a ogólne działanie i funkcjonalność systemu jest analizowane i weryfikowane na podstawie zarejestrowanych wyników. Dlatego w kolejnym rozdziale przedstawiono wyniki i omówienie całościowego działania i funkcjonalności systemu
Wyniki i dyskusja
W tej sekcji przedstawiono uzyskane wyniki w oparciu o opracowany system monitorowania gromadzenia danych oparty na IoT w celu analizy wydajności paneli fotowoltaicznych.
Projektowanie i rozwój systemu sprzętowego
Tabela przedstawia ponumerowane komponenty na rysunku

Rysunek przedstawia rozmieszczenie komponentów w celu opracowania systemu monitorowania akwizycji danych opartego na IoT. Rysunek przedstawia opracowany system monitorowania akwizycji danych oparty na IoT z podłączonymi przewodami.

Rysunek przedstawia w pełni rozwinięty, oparty na IoT, system monitorowania gromadzenia danych do analizy panelu fotowoltaicznego.

Kompletne oprogramowanie pokazane na rysunku zawiera wszystkie podłączone przewody i jest gotowe do testów w terenie.
Projektowanie i rozwój oprogramowania wbudowanego
Rysunek pokazuje przechwycone wyniki czujników TC i czujnika prądu/napięcia INA 219 DC przy użyciu powłoki Phyton w systemie operacyjnym Raspbian Raspberry Pi Zero Wireless.
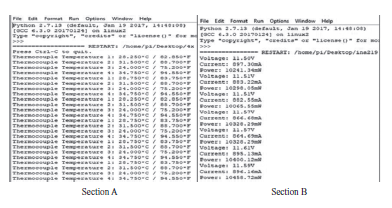
Istnieją dwie sekcje, Sekcja A i Sekcja B, pokazane na rysunku. Sekcja A przedstawia zmierzoną temperaturę i odczyt z czujników TC, podczas gdy sekcja B przedstawia odczyt prądu i napięcia z czujnika prąd/napięcie INA 219 DC. Moc jest obliczana na podstawie wartości prądu i napięcia w sekcji B. Rysunek i tabela przedstawiają odczyt temperatury zarejestrowany 1 maja 2019 r. dla wszystkich czterech czujników TC.
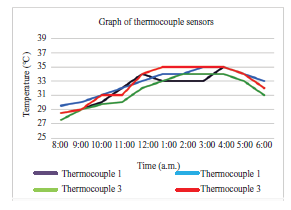
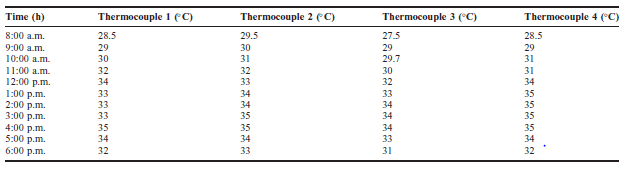
W oparciu o odczyt z wykresu na rysunku, istnieją trzy zmieniające się fazy. Pierwsza faza trwa od 8:00 do 13:00. Temperatura powoli wzrastała w zależności od wzrostu temperatury w warunkach pogodowych. Druga faza jest od 13:00. do 16, a temperatura jest stała, ponieważ temperatura pogodowa osiągnęła szczyt. A ostatnia faza jest od 16:00. do 18:00 gdzie temperatura powoli spada ze względu na warunki zachodzącego słońca. Analiza temperatury jest ważnym czynnikiem pozwalającym zrozumieć maksymalny prąd i napięcie wyjściowe, gdy słońce wytwarza najwyższą możliwą temperaturę. Zostało to przeanalizowane w następnej sekcji. Rysunki oraz Tabela pokazują mierzone i mierzone wartości prądu i napięcia przy użyciu czujnika prądu/napięcia INA 219 DC.
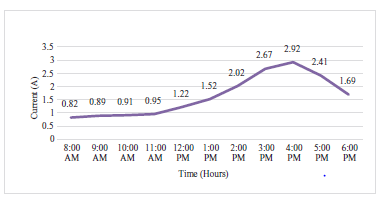
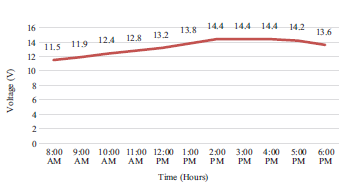
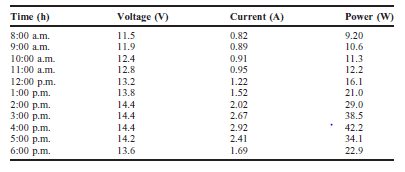
Rysunek 15.
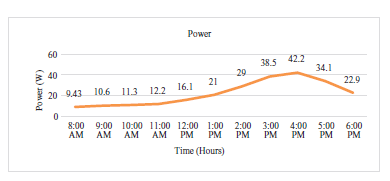
i powyższa Tabela pokazują moc obliczoną przy użyciu oprogramowania wbudowanego. Na podstawie danych wykreślonych zmierzona wartość prądu wynosi od 0,8 A do 2,92 A. Pokazuje to, że rano system fotowoltaiczny wytwarza niski prąd ze względu na niskie natężenie światła słonecznego; podczas gdy intensywność światła słonecznego wzrasta, wzrasta również prąd panelu fotowoltaicznego. Prąd zmniejsza się ponownie, gdy słońce zaczyna zachodzić wieczorem. Pokazuje to, że czujnik prądu/napięcia INA 219 DC może skutecznie wykrywać i mierzyć prąd i napięcie wyjściowe panelu fotowoltaicznego. Na koniec moc jest obliczana za pomocą (15,1). Napięciex (V) x prąd (A) = moc (W)
System monitorowania chmury/bazy danych
Rysunek przedstawia główny interfejs bazy danych, który zawiera informacje o temperaturze, prądzie, napięciu i mocy.
Odnosząc się do rysunku, sekcja wyróżniona niebieskim prostokątem jest znana jako sekcja localhost, która ma na celu utworzenie nazwy parametrów, takich jak temperatura, prąd, napięcie i moc. Sekcja wyróżniona czerwonym prostokątem, jak pokazano na rysunku, to tabele utworzone do przechowywania wartości temperatury, prądu, napięcia i mocy. Rysunek 15.15 przedstawia sekcję bazy danych temperatur, która zawiera tabelę do rejestracji czasu, temperatury czujnika 1 (Temp 1), temperatury czujnika 2 (Temp 2), temperatury czujnika 3 (Temp 3) i temperatury czujnika 4 (Temp 4).
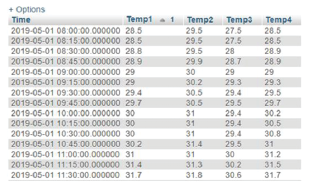
.Odczyt temperatury zarejestrowany w bazie danych, które są przechowywane na karcie SD systemu Raspberry Pi Zero Wireless Rysunek pokazuje zmierzony prąd, napięcie i obliczoną moc w sekcji bazy danych prądu, napięcia i mocy.
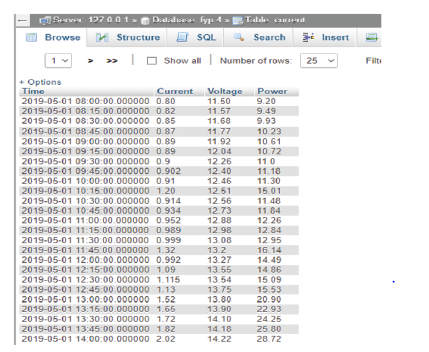
Prąd i napięcie są wykrywane i mierzone przez czujnik prądu/napięcia INA 219 DC podłączony do opracowanego systemu monitorowania akwizycji danych opartego na IoT, podczas gdy moc jest obliczana za pomocą.
Strona internetowa systemu monitorowania akwizycji danych opartego na IoT -localhost
Rysunek przedstawia stronę GUI dla systemu monitorowania akwizycji danych opartego na IoT do analizy prądu, napięcia, mocy i temperatury paneli fotowoltaicznych.
Strona GUI służy do prezentacji wykrytych, zmierzonych i zarejestrowanych informacji o prądzie, napięciu, mocy i temperaturze panelu fotowoltaicznego. Wszystkie informacje o prądzie, napięciu, mocy i temperaturze są przechowywane na karcie SD systemu Raspberry Pi Zero Wireless. Następnie informacje te są bezprzewodowo przesyłane do hosta lokalnego komputera, na którym host lokalny działa jako serwer przechowujący te informacje. Lokalny host jest również wyposażony w stronę internetową, jak pokazano na rysunku , która umożliwia konsumentom monitorowanie lub sprawdzanie wydajności paneli fotowoltaicznych. Strona główna strony internetowej pokazuje sekcję temperatury i prądu/napięcia, do których można łatwo uzyskać dostęp. Konsumenci mogą kliknąć sekcję temperatury lub prądu/napięcia, aby wyświetlić temperaturę panelu fotowoltaicznego, a konsumenci mogą również kliknąć sekcję prądu/napięcia, aby wyświetlić prąd, napięcie i moc panelu fotowoltaicznego. Całkowite dane dotyczące temperatury dla wszystkich czterech czujników TCs przedstawiono na rysunkach
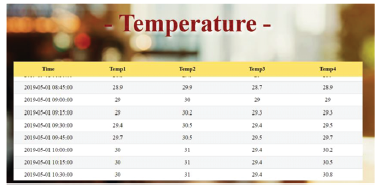
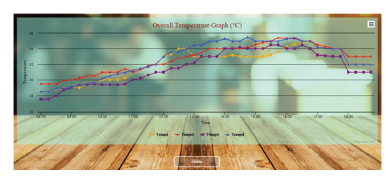
, natomiast poszczególne dane temperaturowe przedstawiono na rysunkach.
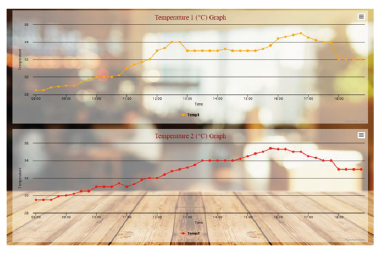
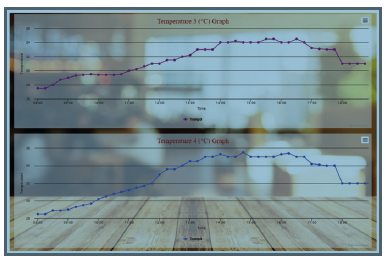
Konsumenci mogą zawsze zdecydować się na sprawdzenie indywidualnej temperatury lub mogą przyjrzeć się ogólnej temperaturze panelu fotowoltaicznego. Druga sekcja to sekcja prąd/napięcie. Konsumenci mogą kliknąć sekcję prąd/napięcie, aby sprawdzić lub wyświetlić wydajność prądową i napięciową panelu fotowoltaicznego. Informacje przedstawione na rysunkach 15.22-15.24 to informacje przechowywane na karcie SD Raspberry Pi Zero Wireless.
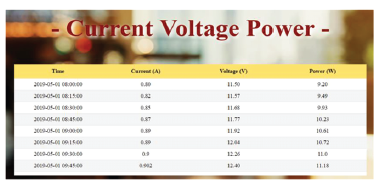
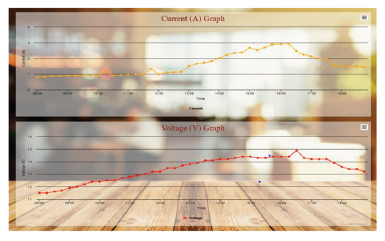
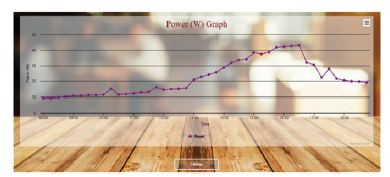
Na podstawie informacji dostępnych na stronie internetowej konsumenci mogą określić wydajność paneli fotowoltaicznych i ogólnie zrozumieć wydajność zainstalowanego systemu
Wniosek
Zaproponowany, oparty na IoT system monitorowania gromadzenia danych do analizy słonecznego panelu fotowoltaicznego został pomyślnie opracowany, przetestowany i zweryfikowany pod kątem jego funkcjonalności i działania. Cała opracowana integracja sprzętu i oprogramowania wyjaśniła wszystkie funkcje systemu monitorowania akwizycji danych opartego na IoT. Zastosowany w systemie Raspberry Pi Zero Wireless to jeden z maleńkich nowoczesnych procesorów, które mogą służyć do sterowania pracą w celu zbierania danych ze zintegrowanych czujników. Baza danych Localhost służy jako platforma do gromadzenia danych z Raspberry Pi Zero Wireless, a zebrane dane są prezentowane na przyjaznych konsumentom stronach internetowych. Czujniki Adafruit TC i czujnik napięcia/prądu INA 219 DC służą do wykrywania i pomiaru temperatury, prądu i napięcia każdego odpowiedniego panelu fotowoltaicznego. Wartości temperatury, prądu i napięcia są zapisywane na karcie SD Raspberry Pi Zero Wireless. W skrócie, prezentowany system dostarcza również dokładnych informacji w czasie rzeczywistym o temperaturze, prądzie i napięciu zainstalowanego panelu fotowoltaicznego. Innymi słowy, wszelkie nieprawidłowe informacje zarejestrowane i pobrane z Raspberry Pi Zero Wireless mogą natychmiast wskazywać na niespójność systemu.
Aplikacja Internetu Rzeczy (IoT) do rozwoju inteligentnego systemu zarządzania energią w budynku
Budynki są głównym konsumentem energii elektrycznej. Odpowiadają za 60% całkowitego zużycia energii elektrycznej na świecie. Na przykład w Malezji 70% zużycia energii elektrycznej w ciągu roku pochodzi z budynków. Nawet w innych krajach budynki znane są z wysokiego zużycia energii elektrycznej. Jednak wyczerpujące dane i liczby nie są w pełni dostępne z powodu ograniczonych informacji i wskaźników. Stąd duży nacisk położono na analizę i formułowanie środków efektywnego zarządzania energią elektryczną w budynkach za pomocą efektywnych systemów zarządzania energią. Zasadniczo Internet rzeczy (IoT) to platforma, która łączy urządzenia za pośrednictwem Internetu, pozwala im rozmawiać ze sobą, a także z ludźmi, ułatwiając w ten sposób realizację wymaganych celów kontekstowych, takich jak monitorowanie stanu (np. wykrywanie usterek klimatyzacji i wentylacji mechanicznej (ACMV), oszczędności energii (na przykład planowanie systemu ACMV na podstawie zajętości) oraz konserwacja predykcyjna (na przykład serwisowanie filtrów powietrza w systemach ogrzewania, wentylacji i klimatyzacji (HVAC)) [ 1]. Ponieważ IoT prawdopodobnie zmieni przyszłość systemu zarządzania energią, ten rozdział ma na celu przedstawienie streszczenia aplikacji IoT w tworzeniu inteligentnego systemu zarządzania energią dla budynków
Wstęp
IoT odnosi się do idei wszechobecnych urządzeń i obiektów terminalowych, przesiąkniętych centralną inteligencją urządzeń mobilnych, czujników, systemów automatyki budynkowej, systemów przemysłowych, systemów monitoringu wideo, instalacji inteligentnego domu, pojazdów, osobistych przenośnych terminali bezprzewodowych i innych inteligentnych gadżetów, środki różnych bezprzewodowych lub przewodowych sieci komunikacyjnych krótkiego lub dalekiego zasięgu w celu osiągnięcia integracji aplikacji oraz interoperacyjności. Wykorzystując odpowiednie systemy bezpieczeństwa informacji w intranecie (tj. sieci), ekstranecie (sieć prywatna) lub ekosystemie internetowym, oferuje bezpieczne, zorganizowane, osobiste i w czasie rzeczywistym śledzenie lokalizacji, monitorowanie online, dowodzenie, powiązanie alarmów, kontrolę procesu , zarządzanie planami, wymiar bezpieczeństwa procesów, bezpieczeństwo, raportowanie statystyczne, aktualizacja online, wspomaganie decyzji, usługi i funkcje zarządzania. Stworzenie opartego na IoT systemu informacyjnego centrum danych jako centrum ma kluczowe znaczenie dla rozwiązywania problemów związanych z zarządzaniem energią w budynkach. Powinna sprzyjać tworzeniu mechanizmu wsparcia podecyzyjnego, poprawiać podstawy nowoczesnego zarządzania i stanowić bazę dla perspektywicznego planowania i podejmowania decyzji. Można to połączyć z innymi systemami informatycznymi, które pełnią rolę agregacji danych i pomagają we wspomaganiu zdolności i skuteczności zarządzania. Oparte na technologii IoT mechanizmy monitorowania środowiska wewnętrznego budynków, a także zużycia energii, łączą wszystkie urządzenia zużywające energię, aby uczynić konstrukcję energooszczędną. Technologia stanowiąca jego rdzeń to sieć czujników i komputerowe przetwarzanie informacji, mające na celu budowa nowoczesnej, potężnej platformy pozyskiwania i przetwarzania informacji. Mechanizm jest odpowiedni dla różnych istniejących i nowych konstrukcji. Jest to najbardziej odpowiedni system przesyłania danych w środowisku wewnętrznym budynków oraz mechanizmy monitorowania zużycia energii
Budowanie środowiska wewnętrznego
Jakość środowiska wewnętrznego (IEQ) w budynkach obejmuje jakość powietrza w pomieszczeniach (IAQ), komfort cieplny, akustykę i oświetlenie. Jak określono we wcześniejszych badaniach i standardach, uznaje się, że niski IEQ ma niekorzystny wpływ na zdrowie zawodowe i produktywność, zwłaszcza jeśli chodzi o dzieci i osoby starsze. Środowiska życia we wnętrzach obejmują wiele rodzajów miejsc pracy i przestrzeni, takich jak hospicja, biura, placówki użyteczności publicznej, biblioteki, szkoły, przestrzenie rekreacyjne i kabiny pojazdów. Zazwyczaj ogromna liczba mieszkańców, czas spędzany w pomieszczeniach oraz większa gęstość zaludnienia racjonalizują potrzebę formułowania automatycznych mechanizmów nadzoru w celu zapewnienia pełnowartościowego i produktywnego miejsca pracy dla nauczycieli, uczniów i personelu szkolnego. Budynki odpowiadają za 60% światowego zużycia energii i 30% emisji CO2. Zapewnienie komfortu cieplnego dotyczy znacznej części podanego zużycia energii. Poparcie dla spersonalizowanych mechanizmów kondycjonowania jest najwyraźniej spójnym podejściem do zwiększania zadowolenia użytkownika z warunków termicznych otoczenia, ponieważ komfort termiczny jest złożonym tematem z wieloma powiązanymi ze sobą czynnikami, które należy interpretować. Podstawowym pojęciem IoT jest wszechobecność wielu rodzajów urządzeń posiadających umiejętności współpracy i komunikacji między nimi, aby osiągnąć wspólny cel. IoT nie tylko poprawi codzienne zachowania i zadania w różnych dziedzinach, takich jak wspomagane środowiska życia, inteligentne domy i inteligentne zdrowie, ale także zapewni pionierskie dane i środki obliczeniowe do tworzenia innowacyjnych rozwiązań programowych. Odgrywałby kluczową rolę w monitorowaniu środowiska wewnętrznego budynków. Szybki rozwój technologii informacyjno-komunikacyjnych (ICT) oraz rozprzestrzenianie się IoT stwarzają znaczne perspektywy, ponieważ wciąż istnieją pewne wyzwania związane z zapewnieniem bezpieczeństwa, ochrony i prywatności jeśli chodzi o tworzenie aplikacji. W odniesieniu do systemów monitoringu, zdalne urządzenia informacyjne to narzędzia, które w czasie rzeczywistym dostarczają dane o wilgotności powietrza, temperaturze, jakości, oświetleniu, stężeniu CO2 i poziomie hałasu. Sugerują również, jakie działania podjąć, gdy użytkownik napotka nieoptymalne warunki. Takie urządzenia można zainstalować w domu lub w miejscu pracy w celu uzyskania dokładnych i aktualnych danych o mikroklimacie wewnętrznym, łączących subiektywny stan człowieka z obiektywnymi warunkami otoczenia. Na przykład, aby ocenić wpływ jakości powietrza i temperatury na poczucie senności w trakcie spotkania należy mierzyć poziom hałasu wywołujący zaburzenia lub obniżający produktywność, regulować temperaturę oraz miejsce i czas wentylacji pomieszczeń. należy określić środowiska. Niektóre sterowniki zbierają dane z różnych czujników oświetlenia, temperatury, lokalizacji i kontaktu, aby w czasie rzeczywistym informować użytkownika o każdym zdarzeniu, które ma miejsce w domu, takim jak otwarcie drzwi, zalanie piwnicy lub wyłączenie urządzenia. Przeprowadzono badania dotyczące wykrywania jakości powietrza w pomieszczeniach w różnych miejscach publicznych, takich jak metro, domy towarowe, szkoły i biura. System opracowany przez Paulosa i in. może mierzyć i monitorować jakość powietrza w biurze, badając wydajność pracy i środowisko powietrza w biurze. Ogólna wydajność pracy pracowników poprawiła się, gdy system był kontrolowany przez bezprzewodową sieć czujników, która była połączona z urządzeniami mobilnymi. Kanjo, Lohani i Acharya opracowali system monitorowania informacji o środowisku, który wykorzystuje środki ostrożności, takie jak redukcja drobnego pyłu w pomieszczeniach, za pośrednictwem mobilnej bezprzewodowej sieci LAN. Autorzy zauważyli, że poziom zadowolenia pracowników poprawia się wraz ze środowiskiem pracy. Hwang i Yoe przeprowadzili monitorowanie i analizę informacji o środowisku wewnętrznym za pośrednictwem telewizji przemysłowej i informacji o środowisku publicznym za pomocą interfejsu programowania aplikacji. Ponadto opracowali system kontroli środowiska wewnętrznego, który opiera się na automatycznym rozpoznawaniu sytuacji. Wang i inni oraz Pötsch opracowali system monitoringu środowiska wewnętrznego, który opiera się na bezprzewodowym czujniku. Można to wykorzystać odpowiednio do zielonych budynków i stosu LoRaWAN. System może wizualizować zebrane dane dotyczące pozycji pomiarowej i środowiska wewnętrznego, a także może być używany do rozmieszczenia czujnika temperatury w różnych miejscach w docelowej przestrzeni. Ponadto temperatura jest komunikowana w każdej przestrzeni za pomocą schodkowego wykresu kolorów. autorzy obliczyli odległość od okna. Autorzy umieścili również czujniki na trzech poziomach poza punktem poziomym. Ich system przedstawia zebrane dane w postaci trójwymiarowej mapy kosmicznej opartej na rozkładzie przestrzennym. W celu zbadania systemu monitorowania jakości powietrza w pomieszczeniach naukowcy podzielili wartości pomiaru stężenia drobnego pyłu na rzucie pomieszczenia i podzielili je na wiele pomieszczeń. Zostały one następnie wyrażone w dwóch lub trzech wymiarach. Ponadto system posiada prostą konstrukcję umożliwiającą intuicyjne uzyskiwanie stanu środowiska wewnętrznego, co umożliwia porównanie stężenia pyłu na podstawie przestrzeni. W innym opracowaniu Salamone i in. przeprowadził badania, w których wykorzystano prostsze, opracowane przez siebie narzędzia eksperymentalne. Inteligentna lampa typu open source została zainstalowana w rzeczywistym środowisku biurowym. Zbadano również niezawodność sprzętu IoT. Salamone i in. wykonał ocenę skuteczności wentylacji w oparciu o metodę wentylacji przestrzeni wewnętrznej techniką obliczeniowej dynamiki płynów (CFD)
Zarządzanie energią budynku
Wraz z kilkoma nowymi certyfikatami i regulacjami energetycznymi, wymogiem zmniejszenia zużycia energii i emisji gazów cieplarnianych oraz koniecznością finansową radzenia sobie z rosnącymi wydatkami na energię, efektywność zużycia energii stała się istotnym aspektem w zarządzaniu budynkiem zużycie energii. Zarządzanie energią w budynku obejmuje rozmieszczenie i eksploatację jednostek wytwarzania i zużycia energii. Cele koncentrują się na zachowaniu zasobów, ochronie środowiska i oszczędności kosztów, a konsumenci mają stały dostęp do potrzebnej im energii. Jest również ściśle powiązany z zarządzaniem środowiskiem, zarządzaniem wytwarzaniem, logistyką i innymi zwyczajowymi operacjami biznesowymi. Wraz z postępem w najnowszej technologii dostępna jest nowa, tania generacja czujników podłączonych do sieci WWW, która pozwala zmniejszyć zużycie energii w budynku. Systemy te mogą być stosowane we wszystkich rodzajach budynków i są w stanie inteligentnie monitorować zmienne środowiskowe w pomieszczeniach lub zużycie energii przez gniazdka elektryczne lub poszczególne urządzenia, dostarczając konsumentom dane w czasie rzeczywistym na telefonie komórkowym, do których można uzyskać dostęp z dowolnego miejsca. System obejmuje również wysyłanie powiadomień SMS lub e-mail wraz z ewentualnymi alertami lub ostrzeżenia o awariach sprzętu. Połączenie systemów wykrywania i automatycznego wyzwalania ze śledzeniem przez Internet służy do optymalizacji zużycia energii. Jednym z rozwiązań jest integracja technologii IoT z urządzeniami oświetleniowymi i możliwość połączenia się z dostawcą energii, aby efektywnie zrównoważyć produkcję energii i zużycie energii. Taki proponowany system może również oferować konsumentom możliwość zdalnego zarządzania swoimi urządzeniami lub zarządzania nimi centralnie za pośrednictwem usługi opartej na chmurze oraz umożliwiać zaawansowane operacje, takie jak planowanie. Inne modele związane z zarządzaniem energią w budynkach to zielone budynki i inteligentne budynki, które są również tematami obecnie istotnymi w inżynierii i architekturze. Wśród obu koncepcji zielone budynki mogą oszczędzać wodę, oszczędzać energię, chronić klimat i umożliwiać użytkownikom zapewnienie zrównoważonego postępu, podczas gdy inteligentne budynki mogą być postrzegane jako zielone budynki o doskonałej wydajności energetycznej osiągniętej dzięki integracji IoT, ICT i innych zaawansowanych technologii . Na przykład sterowanie oświetleniem jest zwykle używane w celu obniżenia kosztów energii. Zarządzanie oświetleniem lub zaawansowane zarządzanie obciążeniem może zmniejszyć zapotrzebowanie na oświetlenie, gdy energia jest bardzo droga. Ręczne ściemniacze, które umożliwiają mieszkańcom regulację poziomu światła zgodnie z ich potrzebami, stały się tańsze. Udowodniono, że systemy sterowania oświetleniem zmniejszają zużycie energii na oświetlenie o co najmniej 35% w nowych budynkach io 50% w budynkach konwencjonalnych. Poza odczytywaniem danych, niektóre systemy umożliwiają korzystanie z funkcji czasu rzeczywistego, za pomocą smartfona, na urządzeniach gospodarstwa domowego, zarządzając harmonogramem włączania i wyłączania lub regulując poziomy aktywności zgodnie z wymaganiami. Obiekty można uznać za samorozpoznawalne i uzyskiwać inteligencję ze względu na ich zdolność do przekazywania informacji na ich temat oraz uzyskiwania dostępu do zbiorczych informacji innych urządzeń. Na przykład inteligentne termostaty monitorują wyjazd i przyjazd pasażerów, aby w razie potrzeby regulować temperaturę, a inteligentne oświetlenie włącza się i wyłącza automatycznie po długiej nieobecności ze względów bezpieczeństwa. Wszystkie obiekty odgrywają aktywną rolę, komunikując się z Internetem. Celem IoT jest przedstawienie świata rzeczywistego w świecie elektronicznym, zapewniając elektroniczną tożsamość miejscom i rzeczom w świecie rzeczywistym. Miejsca i artykuły wyposażone w etykiety identyfikacji radiowej (RFID) lub kody QR obecnie przekazują dane do urządzeń mobilnych, takich jak smartfony lub do sieci. W szczególności wzrosło zainteresowanie tym, jak można wykorzystać IoT do efektywnego zużycia energii. Instalując sieci inteligentnych, połączonych urządzeń, które stale gromadzą, oceniają i udostępniają dane, IoT może zapewnić głęboki wgląd w to, jak ogromne budynki, fabryki, obiekty i przedsiębiorstwa użyteczności publicznej zużywają energię. Takie spostrzeżenia z kolei mogą umożliwić opracowanie strategii systemów zarządzania energią, które prowadzą do optymalizacji zasobów i coraz bardziej autonomicznej poprawy.
Podejście IoT do zbierania danych i informacji
Zbieranie informacji i danych odbywa się w celu zebrania danych o budynku. Obejmuje warunki wewnętrzne i komfort użytkowania. Łącząc IoT i system zbierania danych, dane te mogą być dostępne zdalnie. Wynika to z cech IoT, które przenoszą informacje ze świata rzeczywistego do świata elektronicznego. Dane przechowywane na serwerze mogą być dostępne i odczytywane w dowolnym momencie w wielu celach, na przykład do analizy i monitorowania. Integracja systemu gromadzenia danych i Internetu Rzeczy zwiększyła wiarygodność i skuteczność informacji i danych gromadzonych w ten sposób. Im szybszy proces zbierania i oceny danych, tym szybciej można wygenerować wyzwalacz, aby zoptymalizować stan budynku.
Monitorowanie środowiska wewnętrznego
Monitorowanie środowiska wewnętrznego odnosi się do systemu, który wskazuje środowisko wewnątrz budynku. Optymalny stan środowiska wewnętrznego to stan, w którym najemcy czują się zdrowo i komfortowo. Warunki te to natężenie światła, komfort akustyczny, IAQ i cieplny budynku. Są to aspekty uważane przez naukowców za ważne przy pomiarze poziomu komfortu pasażerów
Przepływ pracy IoT
Aby uzyskać ogólną ideę integracji IoT i systemu monitorowania, przyjrzyjmy się najpierw przepływowi pracy systemu. Przepływ pracy systemu można podzielić na pięć etapów: czujniki, mikroprocesor, brama, baza danych i użytkownik końcowy.
Etap pierwszy (czujnik): Sercem systemu jest czujnik, zwykle rodzaj wybranego czujnika decyduje o tym, który system zostanie zaproponowany do opracowania. Dostępnych jest kilka rodzajów czujników. Generalnie w systemie zintegrowanym z platformą IoT stosowane są czujniki elektryczne. Ten rodzaj czujnika jest wybierany, ponieważ staje się możliwe przesyłanie danych zebranych przez czujnik do platformy IoT. Ponieważ sama platforma kojarzy się z przeniesieniem czegoś fizycznego do świata elektronicznego, najlepszym wyborem jest czujnik elektryczny.
Drugi etap (mikroprocesor/mikrokontroler): Mimo że otrzymaliśmy odczyt czujnika, nie możemy bezpośrednio odczytać danych z czujnika. Ponadto niektóre czujniki wymagają zasilania do działania zewnętrznego źródła. Dlatego potrzebujemy do tego mikroprocesora/mikrokontrolera. Mikroprocesor/mikrokontroler działa jako źródło zasilania i interpreter czujnika. Mimo że sygnały elektryczne są wytwarzane przez czujnik elektryczny, można je podzielić na dwa sygnały: sygnał analogowy i sygnał cyfrowy. Różnica między tymi dwoma sygnałami polega na tym, że sygnał cyfrowy jest sygnałem dyskretnym o wartości 0 i 1, podczas gdy sygnał analogowy stale się zmienia w czasie. Większość mikrokontrolerów/mikroprocesorów może tylko interpretować sygnały cyfrowe, a więc mikrokontrolery, takie jak Arduino UNO, mają na swojej płytce konwerter. Ponieważ sygnał analogowy może być przetworzony na sygnał cyfrowy, ten typ czujnika może być wykorzystany w systemie cyfrowego zbierania danych.Mikrokontroler będzie zbierał i odszyfrowywał sygnał czujnika i konwertował dane do postaci takiej jak wartość liczbowa, którą można przechowywane (rysunek 16.4). Istnieje wiele różnic między mikrokontrolerem a mikroprocesorem w odniesieniu do czynników takich jak słabość i siła. Dlatego wybór mikroprocesora lub mikrokontrolera odbywa się w zależności od projektu systemu, który ma być zastosowany.
Trzeci etap (brama): Brama odnosi się do "bramy", która jest również ścieżką dla informacji i danych, które zostały zebrane i odszyfrowane przez mikroprocesor/mikrokontroler, które mają być wysyłane i przechowywane w internetowej bazie danych. Brama ma zazwyczaj postać routera, który łączy bezpośrednio system z bazą danych online. Na podstawie projektu, projektant systemu ma samodzielną decyzję, czy łączyć się przez komputer, czy bezpośrednio do routera. W projekcie, w którym system jest podłączony bezpośrednio przez router, wymaga zestawu anten bezprzewodowych. Ten zestaw anten bezprzewodowych umożliwi bezprzewodową transmisję danych do internetowej bazy danych.
Czwarty etap (baza danych online): Baza danych, która jest online, jest również nazywana chmurą lub serwerem. Jest to miejsce, w którym przechowywane są wszystkie informacje uzyskane z czujnika. Serwer ma duży potencjał, choć to od umiejętności projektanta zależy układ bazy danych. Ten serwer może być używany jako nośnik interaktywny do przechowywania, aby pokazać odczyt w czasie rzeczywistym z graficzną prezentacją. Ta metoda przechowywania nie tylko zapewnia niepowtarzalność reprezentacji danych, ale także ułatwia dostęp do informacji i bazy danych z dowolnego miejsca, w którym jest dostęp do Internetu.
Piąty etap (zbieranie danych): Dane przechowywane na serwerze są teraz dostępne dla użytkownika. Użytkownik nie musi zbliżać się do czujnika, aby uzyskać dostęp do informacji i je przeanalizować. Dane przechowywane na serwerze mogą być przeglądane przez osobę upoważnioną do monitorowania budynku i jego otoczenia. Najlepszą częścią korzystania z frameworka IoT jest to, że monitorowanie informacji może być przeprowadzane przez system automatycznie. Jest to inteligentny system zaprojektowany w taki sposób, aby ostrzegał użytkownika, jeśli wartość parametru przekracza zdefiniowane kryteria.
Znaczenie monitorowania środowiska wewnętrznego
Znaczenie satysfakcjonującego nadzoru nad obszarem wewnętrznym zostało docenione na całym świecie. Niektóre z ostatnich badań omawiają przyczyny znaczenia monitorowania przestrzeni wewnętrznej. W poprzednim badaniu Mishry podkreślono, że 40% globalnego zapotrzebowania na energię pochodzi z budynków. Jednak chcąc uczynić budynek "zielonym", musimy zadbać o komfort jego mieszkańców. Mishra wspomniał, że podstawową cechą komfortu mieszkańców jest ich komfort termiczny. Komfort cieplny obejmuje temperaturę, przepływ powietrza i wilgotność, które, jak stwierdzono, mają bezpośredni wpływ na produktywność i percepcję mieszkańców. Ponadto w 2018 roku Li i Jin w swoich badaniach podkreślali znaczenie nadzorowania jakości powietrza w pomieszczeniach, gdyż może ono być przyczyną poważnych schorzeń. Zaprojektowany w badaniu model obejmuje dwie funkcje: ocenę i predykcję poziomu jakości powietrza wewnętrznego. Dzięki zastosowaniu hybrydowego projektu optymalizacji poziom zanieczyszczenia powietrza jest przewidywany automatycznie, podczas gdy przeprowadzana jest ocena w celu określenia jakości powietrza. Projekt okazał się niezawodny i bardziej skuteczny w dużym mieście, które jest silnie zanieczyszczone. Inną sprawą alarmującą dla jakości powietrza wewnętrznego jest pył zawieszony (PM), również cały kurz. Ten pył jest tak mały, że wnika w płuca i powoduje problemy zdrowotne . Junaid wspomniał również, że długotrwałe narażenie na ten niehigieniczny stan może powodować przewlekłe choroby układu oddechowego, a także może powodować infekcje. Co ciekawe, stężenie PM może również wskazywać na obłożenie pokoju . Jeon znalazł sposób na powiązanie stężenia PM z obłożeniem pokoju. W badaniach wykorzystujących framework Arduino, SEN0177 (czujnik PM) i platformę IoT, liczbę osób przebywających w pomieszczeniu można ustalić nawet bez fizycznej obecności w pomieszczeniu. Ponadto system może rozpoznać działania mieszkańców. Byłoby to niezmiernie pomocne, ponieważ działania mieszkańców wpływają również na atmosferę i komfort pomieszczenia. Rabiyanti stwierdził, że charakterystyka akustyczna pomieszczenia wpływa również na komfort osoby. Zgodnie z Rabianti poziom hałasu nie może przekraczać 55 dBA, aby środowisko sprzyjało procesowi uczenia się. Tymczasem D'Oca przeprowadziła w 2018 roku ankietę, która wskazała na znaczenie komfortu widzenia dla osiągnięcia komfortowego środowiska wewnętrznego . D′Oca wspomniał również, że regulacja warunków oświetlenia w pomieszczeniu pomaga w zmniejszeniu dodatkowego olśnienia i zwiększeniu produktywności. Podczas gdy D'Oca zastosował manualne podejście do przeprowadzania kwestionariusza, Zhao i inni wykorzystali kwestionariusz internetowy wraz ze znacznikiem czasu. Wyniki tej metody są bardziej wiarygodne, ponieważ monitorowane jest również otoczenie pomieszczenia. Dostępność znacznika czasu umożliwia analizę zmiany lub reakcji na zmianę sytuacji. System tworzy również szacunki wymagań dotyczących zmiany poziomu temperatury na podstawie reakcji mieszkańców. Monitorowanie jakości atmosfery w pomieszczeniach jest istotne, ponieważ wpływa na lokatora, a w przypadku niskiej jakości powoduje, że lokator czuje się niekomfortowo. Dlatego też, łącząc IoT i system monitorowania wnętrz, można przeprowadzić rzetelną i skuteczną ocenę oraz podjąć kroki naprawcze, aby w ten sposób osiągnąć lepsze środowisko wewnętrzne.
Ocena efektywności energetycznej
Ocena charakterystyki energetycznej to system, który ocenia zużycie energii w budynku. Obejmuje chłodzenie, ogrzewanie i energię elektryczną. W Malezji podstawowym zużyciem energii podlegającym ocenie jest zużycie energii elektrycznej. Inteligentne liczniki wydane niedawno przez malezyjską firmę dostarczającą energię Tenaga Nasional Berhad (TNB) są przykładem systemu, który łączy ocenę wydajności energetycznej z Internetem Rzeczy. Wynajmowane pokoje i hostele, które są wyposażone w liczniki dołączone do każdego pokoju, wdrażają systemy podobne do tych omówionych powyżej. Dzięki temu można zmierzyć energię zużytą przez pojedynczą jednostkę. Zmniejszy to obciążenie mieszkańców, ponieważ będą musieli płacić tylko za ilość zużywanej energii. Instalacja liczników dzielonych zmniejszy ilość energii zużywanej przez mieszkańców, ponieważ będą oni mogli zaoszczędzić pieniądze, zużywając mniej energii.Inteligentny budynek, taki jak biuro Suruhanjaya Tenaga, ma lepszą ocenę wydajności energetycznej w porównaniu z budynkami z licznikami. System klasyfikuje zużycie według podłogi i celu wykorzystania energii. Zapewnia dokładny zarys oceny charakterystyki energetycznej. W tym budynku systemy są zintegrowane z IoT, który codziennie przesyła dane do Singapuru, gdzie eksperci analizują je tak, aby zachować przyznanie zielonego znaku struktury platynowej. Jest to zaleta korzystania z Internetu Rzeczy i umożliwia dostęp do danych z dowolnego miejsca. Na rynku dostępnych jest kilka narzędzi, które ułatwiają użytkownikom monitorowanie, regulowanie i optymalizację zużycia energii. Fotopoulos et al. [19], który oferuje zindywidualizowane monitorowanie energii i urządzenia uświadamiające, które są dopasowane do działań mieszkańców. Ponadto dostępne są produkty renomowanych firm wdrażających framework IoT, który umożliwia zarządzanie danymi związanymi ze zużyciem energii. Oto kilka dostępnych produktów tych firm:
Siemens SyncoTM może funkcjonować jako system regulacji budynku komputerowego systemu, który może regulować HVAC budynku. System umożliwia również monitorowanie wielu lokalizacji. Wreszcie twierdzi, że jest w stanie zdalnie monitorować rozliczenia i zużycie energii.
Rozwiązanie Schneider electric BMS to szkielet do automatycznego budowania. System nie tylko zarządza profilem energetycznym, ale może również regulować i prowadzić użytkownika w zakresie zasilania, pożaru, HVAC i kontroli dostępu.
System zarządzania budynkiem Honeywell to otwarty system zarządzania, który jest dostosowany do prawie wszystkich otwartych, samowystarczalnych systemów budynków. System jest w stanie monitorować zużycie pary, energii elektrycznej, oleju, gazu i wody.
Energia czynna Cylon może dostosować się do każdego rodzaju budynku, niezależnie od zainstalowanego rozwiązania pomiarowego lub systemu zarządzania energią budynku. Jest to system monitorowania energii budynku z możliwością monitorowania i regulowania kilku lokalizacji. Jest również w stanie ocenić i zarekomendować konkretne rozwiązanie dotyczące zużycia energii, co jest mocną zaletą systemu.
Zarządzanie energią DEXCell to niezależny sprzętowo i oparty na chmurze system, który integruje zaawansowane monitorowanie, ocenę, sygnały alarmowe i przechowywanie informacji w skalowalnym i łatwym w użyciu rozwiązaniu SaaS.
Platforma zarządzania energią eSight wykorzystuje IoT, który wyświetla kluczowe dane dotyczące energii za pomocą regulowanych pulpitów nawigacyjnych, które na pierwszy rzut oka pokazują ważne informacje i wspierają zaangażowanie. Komponent śledzenia projektu eSight ocenia możliwości oszczędzania energii, monitoruje postęp i weryfikuje oszczędności za pomocą intuicyjnego pulpitu nawigacyjnego typu "wszystko w jednym". Jest również zdolny do tworzenia i obiegu rachunków rozwiązujących problemy mieszkańców budynku.
Predykcyjna optymalizacja energetyczna jest produktem platformy programowej Building IQ, której celem jest poprawa efektywności energetycznej dużych i skomplikowanych konstrukcji.
Oprogramowanie do systematycznego zarządzania energią Enerit przedstawia najlepsze praktyki zarządzania zużyciem energii, zapewnia pełną zgodność z normą ISO 50001 i jest zgodne z normą Energy STAR i oświadczeniem o wydajności energetycznej (SEP).
Na rynku dostępnych jest znacznie więcej systemów, które dostarczają narzędzi do zarządzania i monitorowania zużycia energii. Niektóre z wyżej wymienionych narzędzi to systemy monitoringu energii zintegrowane z systemem automatyki budynkowej z możliwością regulacji budynku w celu poprawy wydajności zużycia energii w budynku. Istnieją również inne narzędzia do modelowania, które zapewniają pomoc i sugestie dotyczące optymalizacji zużycia energii. Dlatego omówiliśmy kilka dostępnych systemów, które wykorzystują IoT do oceny wydajności energetycznej. Zazwyczaj systemy te analizują trend zużycia i opracowują sposób optymalizacji zużycia energii. Efektywny system może zmniejszyć zużycie energii nawet o 40% w ogromnym budynku. Automatyzacja budynku umożliwia również regulację systemu klimatyzacji budynku tak, aby działał jak najefektywniej.
Wniosek
Pojawienie się platformy IoT świadczy o znacznym postępie w transformacji sfery systemu zarządzania zużyciem energii w budynkach, niemniej, jak każda nowatorska i złożona technologia, istnieje ryzyko powolnej transformacji i niemożności czerpania największych potencjalnych korzyści. W przyjęciu technologii IoT (takich jak inteligentne urządzenia MEMS i urządzenia ubieralne) jednym z wyzwań dla poprawy zużycia energii w budynkach jest dynamiczna złożoność ich otoczenia. Powszechnie wiadomo, że struktura ma złożoną dynamikę (komfort cieplny, obciążenie cieplne, zajętość osób itp.). Ta złożoność utrudnia urządzeniom IoT zrozumienie takiej dynamiki w celu regulacji i poprawy wydajności budynku. W związku z tym należy przeprowadzić dalsze badania, które koncentrują się na modelowaniu komfortu i jakości powietrza, przewidywaniu i wykrywaniu zajętości, na przykład przy użyciu technologii IoT. Potrzebna jest również innowacyjna struktura, aby zintegrować urządzenia IoT z obecnymi systemami budynkowymi czujników i elementów sterujących. Ponieważ z urządzeń IoT wytwarzana jest ogromna ilość danych, do interpretacji i wykorzystania danych potrzebny jest inteligentny sprzęt i urządzenia przetwarzające. To wymaganie jest jeszcze większe, gdy mamy do czynienia z obliczeniami w czasie rzeczywistym. Kolejnym wyzwaniem jest kwestia prywatności, w której należy podjąć środki bezpieczeństwa cybernetycznego, aby rozwiązać ten problem. Ogólnie rzecz biorąc, wykorzystanie technologii IoT odegrało ważną rolę w zaawansowanym projektowaniu i wdrażaniu systemu zarządzania energią w budynku.Wdrożenie to okazało się bardzo korzystne dla poprawy systemu i nadal potrzebne są dalsze badania, aby poradzić sobie z problemami inne problemy, jak omówiono powyżej.
Specjalistyczny system diagnostyki usterek klimatyzacji budynków wentylacji mechanicznej
Gwałtowne zużycie energii na całym świecie spowodowało niedobór paliw i nadmierną konsumpcję źródeł energii, pogarszając tym samym wpływ na środowisko. Całkowite zużycie energii w budynkach mieszkalnych i komercyjnych w krajach rozwiniętych osiągnęło od 20% do 40%. Liczba ta przekroczyła wartości w sektorze przemysłowym i transportowym. Wzrost liczby ludności, rosnące zapotrzebowanie na usługi budowlane i poziom komfortu oraz coraz dłuższy czas spędzany w budynkach wskazują, że zapotrzebowanie na energię będzie nadal rosło w przyszłości. Z tego powodu efektywność energetyczna budynków jest głównym celem polityki energetycznej na całym świecie. Szczególnie istotne jest zużycie energii w systemach klimatyzacji i wentylacji mechanicznej (ACMV), które wynosi 50% zużycia budynków i 20% całkowitego zużycia w Stanach Zjednoczonych. Stwierdzono, że ACMV zużywa około 60% całkowitego zużycia energii typowego budynku komercyjnego. Konserwacja i serwisowanie systemów klimatyzacji wymaga wysoko wykwalifikowanych i doświadczonych techników i inżynierów. Eksperci z tej dziedziny mogą nie być dostępni przez cały czas, gdy jednostki klimatyzacyjne ulegają awarii lub gdy konieczna jest konserwacja. Gdy systemy klimatyzacyjne psują się nieoczekiwanie, zwykle powstają wysokie koszty. Ponadto, gdy systemy klimatyzacji nie działają tak wydajnie, jak powinny, może to prowadzić do wysokich rachunków za prąd. Niestety, regularnej konserwacji i inspekcji nie można wykonać, ponieważ eksperci techniczni nie zawsze są łatwo dostępni. Innymi słowy, nastąpi utrata wiedzy eksperckiej, gdy wiedza ekspercka jest niedostępna. Opisujemy zastosowanie powłoki systemu eksperckiego do diagnozowania wadliwego problemu instalacji klimatyzacji budynku. Eksperci są kosztowni i bardzo potrzebni do konserwacji budynku, serwisu i konserwacji systemu klimatyzacji. Stąd głównym celem opracowanego systemu, czyli systemu ekspertowego, jest diagnoza systemu klimatyzacji budynku. Za pomocą systemu ekspertowego proces diagnozy systemu klimatyzacji budynku będzie bardziej ujednolicony i dokładniejszy w porównaniu z konwencjonalną droga. Ograniczone wartości dla tego opracowanego eksperckiego systemu diagnostyki usterek są oparte na projekcie systemu klimatyzacji budynku i doświadczeniach ekspertów.
Wstęp
Cyfryzacja w Budownictwie 4.0 ma ogromny wpływ na branżę budowlaną w zakresie poprawy jej produktywności. Potencjał cyfryzacji w branży budowlanej można dostrzec zgodnie z Przemysłem 4.0 w czterech głównych aspektach: dane cyfrowe, dostęp cyfrowy, automatyzacja i łączność. Dane cyfrowe to zbiór elektroniki i analiza danych, aby uzyskać każdy nowy wgląd w każde ogniwo łańcucha wartości, a następnie dobrze wykorzystać te nowe spostrzeżenia, podczas gdy dostęp cyfrowy obejmuje mobilny dostęp do Internetu i sieci wewnętrznych. Automatyzacja to najnowsza technologia, która tworzy autonomiczne i samoorganizujące się systemy. Łączność bada możliwości łączenia i synchronizowania dotychczas oddzielnych działań. Czwarta rewolucja przemysłowa leży w sile niemieckiej produkcji i jest szeroko przyjęta przez kraje takie jak Chiny, Indie i inne kraje azjatyckie poprzez integrację Internetu Rzeczy i Internetu Usług ze środowiskiem produkcyjnym. Jednak w Budownictwie 4.0 firmy budowlane będą miały silną globalną sieć, aby połączyć swoje materiały transportowe, załatwiać sprawy, sprzątać, zmieniać aranżację placu budowy i szukać materiałów i sprzętu. Przyniesie to ogromną poprawę procesów przemysłowych i budowlanych w zakresie inżynierii, wykorzystania materiałów, łańcuchów dostaw i zarządzania cyklem życia produktu. Jest więc całkowicie zrozumiałe, że wiele firm widzi potrzebę optymalizacji w budownictwie 4.0. W przypadku budownictwa i usług, które na wzór budownictwa 4.0, to nadchodzący trend, w którym firmy budowlane koncentrują się obecnie na cyfryzacji planowania, budowy i logistyki z modelowaniem informacji o budynku (BIM). BIM to modelowanie 3D, które może zapewnić profesjonalne projektowanie budynków, budowę, obsługę operacyjną obiektów i charakterystykę fizyczną miejsc. Za pomocą technologii BIM konstruowany jest cyfrowo dokładny wirtualny model budynku. Pomaga architektom, inżynierom i konstruktorom wizualizować, co ma zostać zbudowane w symulowanym środowisku, aby zidentyfikować wszelkie potencjalne problemy projektowe, konstrukcyjne lub operacyjne. Stosowanie modelowania informacji o budynku (BIM) jest obowiązkowe do 2020 roku dla każdej infrastruktury publicznej w Niemczech, Holandii, Danii, Finlandii i Norwegii. W przypadku Malezji, kierowanej przez Radę Rozwoju Przemysłu Budowlanego (CIDB) w ramach planu generalnego budowy na lata 2016-2020, mamy nadzieję, że większy nacisk na przyjęcie technologii w całym cyklu życia projektu spowoduje wyższą produktywność. Z drugiej strony energia jest niezbędnym elementem rozwoju kraju, ponieważ jest niezbędna w różnych gałęziach przemysłu. Obecnie zasoby nieodnawialne na całym świecie kurczą się w alarmującym tempie, aby zaspokoić podstawowe potrzeby ludzkości. Zgodnie z badaniem, klimatyzacja zużywa najwięcej energii w budynkach, gospodarstwach domowych, a nawet stanowiskach pracy biurowej. Klimatyzacja w budynkach i stanowiskach pracy biurowej jest wymagającym trendem, ponieważ zapewnia użytkownikom komfortowe warunki poprzez obniżenie temperatury w pomieszczeniach. Ponieważ ludzie są w dużym stopniu uzależnieni od tego urządzenia chłodzącego, zwłaszcza w krajach o tropikalnej pogodzie, zwykle musi ono działać przez dłuższy czas. W związku z tym awaria urządzenia lub awaria systemu może wystąpić w dowolnym momencie. Gdy system klimatyzacji ulegnie awarii, zatrudnienie techników do przeprowadzenia napraw może być bardzo kosztowne. Dlatego działania zapobiegawcze są lepsze niż prace naprawcze, ponieważ później kosztują więcej pieniędzy i czasu. Dzięki temu opracowany system ekspercki znacznie obniża koszty utrzymania klimatyzacji, a także promuje proaktywne rozwiązania. Regularne konserwacje i naprawy systemów klimatyzacji są zazwyczaj wykonywane przez doświadczonych techników i inżynierów. Eksperci ACMV budynków nie są dostępni przez cały czas, aby doradzać i przeglądać możliwe referencje i dane w przypadku awarii jednostek. Innymi słowy, gdy nie będzie dostępna ludzka wiedza specjalistyczna, nastąpi utrata wiedzy eksperckiej. Tak więc, aby na stałe zachować wszystkie informacje i dane z dziedziny, wymagany jest system ekspercki. System ekspercki to komputer, który naśladuje zachowanie ludzkich ekspertów w dobrze zdefiniowanej, wąskiej dziedzinie wiedzy. System ekspercki dostarcza wskazówek i zaleceń w zależności od sytuacji w oparciu o wiedzę i doświadczenie inżynierskie. Poza tym system ekspercki jest jedną z technologii sztucznej inteligencji, która została opracowana na podstawie badań i może symulować ludzkie zdolności poznawcze w celu rozwiązywania problemów. System ekspercki oparty na wiedzy to oprogramowanie komputerowe, które może przezwyciężyć problemy dzięki rozwiązaniom eksperckim. Dlatego opracowywany jest system ekspercki z przydatnymi informacjami związanymi z systemami klimatyzacji. Przy pomocy systemu eksperckiego można skrócić czas na zdiagnozowanie głównych czynników awarii układu klimatyzacji. Ponadto system będzie również w stanie przedstawić zalecenia na podstawie sytuacji.
Ogólny opis systemu
Oparty na wiedzy system (KBS) do diagnostyki usterek klimatyzacji został opracowany w oparciu o reguły heurystyczne oraz doświadczenie specjalistów od klimatyzacji. Rozwój KBS obejmował cztery główne etapy.
Przegląd literatury: Przegląd literatury jest pierwszym krokiem, który należy wykonać przed rozpoczęciem jakichkolwiek prac badawczych. Wiedza i informacje związane z wykonaną pracą zostaną przestudiowane i odnotowane. W pierwszej kolejności gromadzone są czasopisma informacyjne, książki i Internet. Informacje obejmowały systemy klimatyzacyjne, elementy i funkcje systemów klimatyzacyjnych, metodykę tworzenia systemu ekspertowego, informacje o powłoce systemu ekspertowego oraz oprogramowanie Kappa-PC. Informacje były potrzebne do osiągnięcia celów pracy badawczej.
Pozyskiwanie wiedzy: Rozwój KBS jest trudnym etapem, ponieważ wymagana wiedza ekspercka jest heurystyczna i trudna do zebrania. Ekspert dziedzinowy omówiony w sekcji poniżej jest głównym źródłem projektu. Istnieją dwa główne źródła pozyskiwania wiedzy, którymi są (i) spotkania z ekspertami oraz (ii) instrukcje obsługi producenta.
Spotkanie z ekspertami : Celem było jeden starszy inżynier (pan Nizam), jeden inżynier kierownika obiektu (pan Hisham), dwóch specjalistów technicznych ACMV (pan Wong i pan Surah) oraz trzech starszych techników (pan Nazri, pan Amirul i pan Shah). ekspertów dziedzinowych, którzy byli zaangażowani w proces pozyskiwania wiedzy. Wspólne usterki i problemy uzyskano dzięki dyskusjom na temat problemów ACMV oraz regularnym spotkaniom z ekspertami dziedzinowymi. Poza tym odwiedzenie kilku witryn związanych z ACMV było również ważne, aby uzyskać informacje o witrynie. Odwiedzane miejsca obejmują wieżę PJD znajdującą się w Jalan Tun Razak w Kuala Lumpur i Putri Park Hotel w Chow Kit w Kuala Lumpur.
Instrukcje obsługi producenta : Informacje techniczne dotyczące systemu klimatyzacji i jego instrukcje obsługi są zwykle wyraźnie podane w instrukcjach obsługi poszczególnych producentów. Podręcznik zawiera szczegółową wiedzę i wiedzę techniczną domeny. Zawiera również ogólne procedury diagnostyki usterek, procedury rozruchu maszyny, procedury operacyjne, harmonogram konserwacji i szczegółowe specyfikacje. W miejscu wskazanym w instrukcjach obsługi producenta przeprowadzono również studia przypadków, aby zweryfikować poprawność systemu eksperckiego.
Projekt : Zbierając i gromadząc całą wiedzę od eksperta domeny, kluczowy jest wybór techniki reprezentacji wiedzy. Powstaje prototypowy system w celu walidacji badań i dostarczenia wskazówek dla przyszłych prac. Kompletny i pomyślnie opracowany system ekspercki musi zaczynać się od kroku (a) do kroku (f) i szczegóły jak poniżej.
Wybór narzędzia do tworzenia prototypów : Narzędzie programistyczne KBS musi być w stanie oszczędzić czas i spełniać wszystkie kryteria. Wybór narzędzia musi spełniać następujące warunki:
• Wspieranie hybrydowych technik reprezentacji wiedzy.
• Zależy od funkcji wnioskowania.
• Wsparcie dobrych udogodnień interfejsu z zewnętrznymi programami i systemami.
Jako narzędzie KBS wybrano powłokę systemu eksperckiego Kappa-PC (1997), ponieważ spełniała wszystkie powyższe kryteria. Kappa-PC ma silne możliwości obiektowe i pozwala na reprezentację wiedzy regułami produkcyjnymi. Baza wiedzy ma być budowana z wykorzystaniem informacji heurystycznych i dodatkowych obliczeń związanych z ACMV. Zapewnia również wiele opcji dla użytkownika.
Wybór techniki reprezentacji wiedzy : W systemie eksperckim wymagana była technika reprezentacji wiedzy, która idealnie pasuje do problemów związanych z klimatyzacją. Dlatego system oparty na regułach jest wymagany przez podejście:
Jeśli (X) Wtedy(Y)
Jeżeli warunek reguły zostanie spełniony, jako wynik zostanie ustawione zakończenie reguły.
Wybór techniki sterowania: W tym projekcie badawczym zastosowano metodę łańcuchów wstecznych, ponieważ ekspert najpierw rozważa wnioski, a następnie próbuje to udowodnić za pomocą wszystkich informacji pomocniczych.
Opracowanie prototypu: Do opracowania systemu wykorzystano powłokę systemu eksperckiego. Opracowany prototyp jest modelem finalnego systemu.
Opracowanie interfejsu : System ekspercki powinien zapewniać funkcję wyjaśniającą, która opisuje użytkownikowi rozumowanie systemu. Interfejs użytkownika jest ważnym modułem oprogramowania, który zawiera objaśnienia dla użytkownika. Interfejs użytkownika został opracowany w taki sposób, aby był łatwo dostępny i przyjazny dla użytkownika.
Rozwój produktu: Stworzony system powinien odświeżyć lub zaktualizować system, gdy dostępne będą nowe normy lub procedury. Informacje dotyczące konserwacji i serwisowania klimatyzatorów są przechowywane w bazie wiedzy. Silnik wnioskowania za pomocą narzędzia Kappa-PC jest odpowiedzialny za skanowanie informacji w bazie wiedzy poprzez zastosowanie reguł "jeśli-to-to" w celu uzyskania najlepszego rozwiązania problemu z usterkami ACMV.
Testowanie i walidacja
Opracowany system ekspercki jest testowany i oceniany, aby zagwarantować, że wykonanie oprogramowania jest odpowiednie dla celów niniejszego badania. Walidacja systemu i akceptacja użytkownika są ważnymi kryteriami określającymi, czy system ekspercki osiągnął główny cel. Walidacja systemu jest ważna, aby ustalić, czy system wykonuje zadanie w sposób zadowalający, podczas gdy akceptacja użytkownika dotyczy tego, jak dobrze system odpowiada na potrzeby użytkownika. Na koniec, opracowany system zostanie wdrożony w środowisku pracy, a dziesięciu techników zostało poproszonych o użycie systemu eksperckiego do rozwiązywania problemów z systemem ACMV w budynku. Celem testów terenowych było ustalenie, czy system ekspercki spełnia rzeczywistą diagnozę błędów i rozwiązań.
Konserwacja
Konserwacja systemu jest ważna, chociaż jest to ostatnia faza tych badań. Jest to wymagane, ponieważ większość informacji w bazie wiedzy musiałaby być aktualizowana w miarę upływu czasu. Firmy mogą zmienić nowe komponenty ACMV lub opracować nowe procedury operacyjne po pewnym czasie, a ekspercki system musi być regularnie aktualizowany. W każdym razie ten zmieniający się stan wymaga odpowiednich modyfikacji systemu.
Rozwój systemu
W tej sekcji opisano kroki do opracowania systemu ekspertowego przy użyciu oprogramowania Kappa-PC. Do opracowania systemu ekspertowego wykorzystywane jest oprogramowanie Kappa-PC. Główną cechą tego systemu jest możliwość kliknięcia i wybrania swoich wymagań z okna. System zaproponuje wówczas rozwiązanie, które zaspokoi potrzeby użytkowników. System do tworzenia aplikacji Kappa-PC to prawdziwie hybrydowe narzędzie PC, które łączy kluczowe technologie niezbędne do szybkiego tworzenia tanich aplikacji biznesowych o dużym wpływie (Kappa-PC). Rozwiązania stworzone w środowisku Kappa-PC wykazały wysoki zwrot z inwestycji w szeroką gamę aplikacji komputerowych, w tym help desk, przetwarzanie zamówień, wsparcie sprzedaży, kontrolę zapasów i produkcję. Kappa-PC nadaje się do opracowywania i dostarczania potężnych aplikacji, które stają się terminowymi i ekonomicznymi rozwiązaniami krytycznych problemów. Kappa-PC dostarcza szeroką gamę narzędzi do konstruowania i wykorzystywania aplikacji. Główne okno systemu Kappa-PC służy jako interfejs użytkownika do zarządzania rozwojem aplikacji. Pierwszym krokiem w tym programie jest utworzenie klasy i slotu za pomocą przeglądarki obiektów. Następnie tworzona jest instancja globalna. Po wykonaniu tych kroków tworzona jest funkcja systemu. Po utworzeniu funkcji kolejnym krokiem jest stworzenie reguły dla systemu. Po ustaleniu reguły tworzony jest kolejny cel dla systemu. Po utworzeniu celu i reguły tworzony jest interfejs systemu. Po wykonaniu wszystkich kroków system jest testowany pod kątem interfejsu użytkownika. Gdy interfejs użytkownika przejdzie pomyślnie test, a system zostanie uruchomiony pomyślnie, program uznaje się za zakończony. Jeśli system zakończy się niepowodzeniem, program należy napisać od nowa. Rozwój systemu przy użyciu oprogramowania Kappa-PC dzieli się na dwa główne etapy:
(a) Rozwój KBS
(b) Obliczanie i przeliczanie jednostek
Rozwój KBS
Po opracowaniu bazy danych systemu zapewnia to rozwój systemu. Ogólnie struktura KBS składa się z użytkowników, interfejsu użytkownika, informacji o procesie, bazy danych, bazy wiedzy, silnika wnioskowania i danych wyjściowych.
Silnik wnioskowania i baza wiedzy
Silnik wnioskowania jest ważną częścią systemu eksperckiego, który działa w oparciu o reguły. Silnik wnioskowania skanuje i sprawdza warunek podany w regułach w zależności od procesu tworzenia łańcucha zdefiniowanego w rozumowaniu. Proces rozumowania dzieli się na dwa, a mianowicie łańcuchowanie wstecz lub w przód. Reguły są skanowane, dopóki nie zostanie znaleziona, gdy wartości ograniczenia pasują do danych wprowadzonych przez użytkownika. Skanowanie zostanie wznowione, a wyniki zostaną wywnioskowane. Ostateczne wyniki są raportowane użytkownikowi. Proces trwa do momentu dokonania ostatecznego wyboru. Dane są dostarczane tłumaczowi za pośrednictwem interaktywnego dialogu przez użytkownika. Baza wiedzy proponowanego systemu składa się z czterech odrębnych grup danych dotyczących człowieka, materiału, maszyny i metody. Szczegółowe informacje związane z klimatyzacją zamieszczone są w bazie wiedzy. Wszystkie informacje są połączone ze sobą na wykresie hierarchicznym. Każdy element modelu analitycznego jest reprezentowany jako rama lub obiekt. Gdy użytkownik wprowadza wymagane informacje za pośrednictwem interfejsu użytkownika, wywoływany jest aparat wnioskowania. Następnie silnik wnioskowania spróbuje wyszukać informacje z bazy wiedzy. W KBS baza wiedzy i baza danych współpracują ze sobą. Silnik wnioskowania przetworzy podane informacje z interfejsu użytkownika na podstawie procesu wnioskowania zdefiniowanego w bazie danych wnioskowania. Następnie silnik wnioskowania spróbuje dopasować informacje do danych z bazy wiedzy i bazy danych. Jeśli warunek części reguły w bazie wiedzy jest zgodny z informacją podaną przez użytkownika, jako wynik ustalana jest konkluzja tej reguły.
Tworzenie klas, podklas i instancji
Rysunek
przedstawia główne menu oprogramowania Kappa-PC. Okno zawiera Przeglądarkę obiektów, Sesję, Narzędzia edycji, Interpreter KAL, Debuger widoku KAL, Znajdź zastąp, Relacje reguł, Śledzenie reguł i Przeglądarkę wnioskowania. Przeglądarka obiektów umożliwia przeglądanie i modyfikowanie obiektów oraz ich relacji w aplikacji. Przedstawia graficzny widok hierarchii obiektów. Po lewej stronie znajduje się korzeń klasy, który zawsze jest częścią bazy wiedzy. Podklasy katalogu głównego (takie jak Menu, DDE, Image i KWindow) pojawiają się po jego prawej stronie, połączone z katalogiem głównym liniami ciągłymi, a Global linią przerywaną. Wszelkie obiekty klasy ze zdefiniowanymi, lecz ukrytymi podklasami są wyświetlane z ramką otaczającą je; jeśli instancje są ukryte, a następnie obiekty są otoczone elipsą. Rysunek
przedstawia przeglądarkę obiektów Kappa-PC. W systemie Kappa-PC klasy i instancje są wyświetlane w oknie przeglądarki obiektów. Klasy i instancje w oknie przeglądarki obiektów pokazują ogólny przegląd struktury bazy wiedzy, jej hierarchizacji i tworzenia bazy wiedzy systemu. Każdy z obiektów klasy i instancji zawiera sloty i są to miejsca, w których przechowywane są informacje o rzeczach lub pojęciach, które są ważne w domenie wiedzy. Ponadto każdy z obrazów tworzących interfejs użytkownika jest reprezentowany przez obiekty klasy i instancji. Obiekty mogą być klasami lub instancjami w klasach. Klasa jest bardziej ogólnym obiektem. Może to być grupa lub kolekcja, taka jak ACMV. Instancja to bardziej konkretny obiekt. Jest to konkretny przedmiot lub wydarzenie. Przykładami konkretnych obiektów są: centrale klimatyzacyjne, chłodnie kominowe, wentylatory osiowe, chillery i inne. Aby utworzyć klasę, kliknij prawym przyciskiem myszy klasę nadrzędną i wybierz "Dodaj podklasę". Następnie pojawi się małe okno i wymaga od użytkownika wpisania nazwy klasy. Następnie naciśnij przycisk "OK", a w hierarchii pojawi się podklasa. W tym rozwiniętym systemie utworzono trzydzieści cztery klasy. Aby utworzyć instancję, kliknij prawym przyciskiem myszy klasę nadrzędną i wybierz "Dodaj instancję". Następnie pojawi się okno wymagające od użytkownika wpisania nazwy instancji. Następnie naciska się przycisk "OK", a instancja pojawia się w hierarchii. W tym rozwiniętym systemie utworzono łącznie 325 instancji.
Sloty i wartość slotów dla klas i instancji
Szczeliny reprezentują ważne właściwości obiektu lub klasy. Każde miejsce w klasie opisuje charakterystykę klasy. Aby określić charakterystykę, do gniazda można przypisać wartość lub tekst. Zazwyczaj sloty są tworzone na najwyższym poziomie, a podklasa i instancja dziedziczą te sloty poprzez dziedziczenie technik programowania obiektowego.
Funkcje pisania
KAL to język programowania używany w systemie eksperckim Kappa-PC. Jest to język interpretowany przeznaczony do szybkiego prototypowania. Opracowany system diagnostyki usterek klimatyzacji dzieli się głównie na funkcję główną i podfunkcje, takie jak funkcja uruchamiania, funkcja zakończenia, funkcja wyświetlania i funkcja resetowania. Do opracowania funkcji wykorzystano język programowania KAL. Funkcję można rozwijać za pomocą edytora funkcji. Funkcje są najbardziej elastycznym narzędziem w KAL. Wszystko, co użytkownik może zrobić w Kappa-PC, od dodania obiektu do aktywacji przycisku, można zrobić łatwo, szybko i wydajnie za pomocą funkcji KAL. Za pomocą funkcji można zdefiniować wyrażenie lub zdefiniować inne funkcje, łącząc funkcje standardowe. Funkcja służy do określenia akcji, jaką ma podjąć system, gdy użytkownik kliknie przycisk w interfejsie użytkownika. Funkcja w Kappa-PC jest w języku programowania C. Edytor funkcji służy do definiowania, badania i modyfikowania funkcji. Edytor funkcji posiada trzy pola do tworzenia programów użytkowych. Argumenty zawierają nazwy każdej funkcji oddzielone spacjami. Treść zawiera wyrażenie KAL definiujące akcje, które funkcja powinna wykonać. Komentarze zawierają statyczne informacje tekstowe o funkcji. Posiada pasek menu do tworzenia, edycji i modyfikacji funkcji. Aktywuje się ją w oknie narzędzia edycyjnego za pomocą opcji edytuj lub nowych. Niektóre typowe funkcje tworzone w tym systemie to funkcja Reset i funkcja Back. Poza tym istnieje kilka funkcji stworzonych do różnych celów.
Główna funkcja
Funkcja główna obejmuje funkcję uruchamiania, funkcję podrzędną, funkcję zakończenia, funkcję wyświetlania i funkcję resetowania. Gdy główna funkcja jest wykonywana, pod-funkcja zostanie wykonana krok po kroku.
Zamknij funkcję
Funkcja podsumowania służy do określenia diagnozy usterek układu klimatyzacji, takich jak przyczyny i zalecenia dla konkretnej sytuacji.
Funkcja wyświetlania
Funkcja wyświetlania służy do pokazywania wyników użytkownikowi.
Funkcja resetowania
Funkcja resetowania usunie instancje, takie jak wartości, podklasy, sloty i inne w przeglądarce obiektów. Ponadto funkcja resetuje również całą wartość slotu w instancji "Global".
Utwórz regułę
Reguły w Kappa-PC są w zasadzie logicznym wyrażeniem z If i Then. Jeśli określa warunki dla silnika wnioskowania do wyszukiwania reguł, które spełniają dane wejściowe użytkownika. Użycie "I" i "Lub" jest dozwolone na liście warunków JEŻELI. Jeśli warunek musi być poprzedzony średnikiem. Następnie określi cel, który zostanie zastosowany, gdy aparat wnioskowania potwierdzi, że reguły są prawdziwe. Jeśli istnieje więcej niż jeden wniosek, linie w polu THEN muszą być ujęte w nawiasy klamrowe, a po nich średnik. Edytor reguł służy do definiowania, badania i modyfikowania reguł. Edytor reguł jest aktywowany z narzędzi edycyjnych. Edytor reguł zawiera pięć pól, które są wzorcami, priorytetem, jeśli, to i komentarzem. Wzorce zawierają listę wszystkich wzorców obiektów, które mają być dopasowane w ramach tej reguły. Jeśli jest kilka wzorców, należy je oddzielić spacjami. Priorytet zawiera liczbę, której aparat wnioskowania używa do rozwiązywania konfliktów między regułami. Domyślny priorytet to zero. Pola if i then zawierają wyrażenie KAL. IF określa warunek reguły i THEN określa wniosek, że silnik wnioskowania powinien działać, jeśli reguła zostanie wyzwolona. Komentarz odnosi się do komentarzy dotyczących reguły. Ten komentarz służy do wyjaśnienia. Aby utworzyć regułę dla systemu, użytkownik musi wybrać metodę wnioskowania, która może być łańcuchem w przód lub w tył. Reguła, która biegnie od przesłanek do zakończenia, nazywana jest łańcuchem do przodu. Tymczasem łańcuchowanie wstecz wymaga wstępnie zdefiniowanego celu, który można zapisać w Edytorze celów. Proces łańcucha wstecznego stara się stale osiągać cel. Aby utworzyć regułę, użytkownik musi kliknąć narzędzie "Reguła" w oknie narzędzia edycji i wybrać "Nowa". Użytkownik będzie wówczas musiał zdefiniować nazwę reguły. Po nazwaniu reguły "cfault1" i kliknięciu przycisku "OK", pojawi się okno edytora reguł. W oknie edytora reguł znajdują się dwa pola, a mianowicie JEŻELI i TO. Do zdefiniowania warunku reguły używane jest pole IF. Z drugiej strony, pole THEN służy do określenia zakończenia reguły. Warunek reguł składa się z różnych zestawów wartości atrybutów, podczas gdy na zawarcie reguł składa się możliwy typ wyposażenia. W celu spisania reguł warunku należy przygotować rozumowanie logiczne. Wszystkie te reguły są ważne, gdy przeglądarka wnioskowania jest wyświetlana po przeprowadzeniu sesji interfejsu w celu określenia śladów reguł i ich relacji. W systemie tym opracowano łącznie 38 reguł.
Bramka
Kappa-PC jest dość restrykcyjny w używaniu bramek. Cel ogólnie odnosi się do wartości boksu i tego, czy jego wartość została wywnioskowana lub ustawiona na konkretną wartość. Na przykład treścią prawidłowego celu może być:
Znana wartość? (Imię osoby);
W tym systemie eksperckim cel jest generowany za pomocą metody łańcuchów wstecznych. Silnik wnioskowania będzie szukał reguł w oparciu o metodę zorientowaną na cel. Wygenerowany cel zostanie następnie zapisany w slocie "Wnioski" w klasie o nazwie "Wyniki". W tym rozwiniętym systemie tworzony jest tylko jeden cel.
Interfejs użytkownika
Istnieją dwa sposoby pracy z obrazami, a mianowicie za pomocą graficznych narzędzi programistycznych w oknach sesji oraz za pomocą funkcji graficznych KAL. Okno sesji to miejsce, w którym tworzysz obrazy, które umożliwiają użytkownikom interakcję z bazą wiedzy. Okno sesji jest głównym interfejsem użytkownika końcowego aplikacji Kappa-PC. Kappa-PC pozwala programiście aplikacji dostosować to okno za pomocą różnych opcji graficznych i wyświetlacza, tworząc interfejs, który upraszcza użytkownikowi końcowemu zadanie interakcji z aplikacją. Okno sesji ma dwa tryby do dwóch różnych celów. Tryb układu służy do manipulowania obrazami graficznymi za pomocą interfejsu myszy i menu. Tymczasem tryb runtime służy do prezentowania interfejsu aplikacji użytkownikowi końcowemu. W opracowanym systemie utworzono łącznie dwadzieścia okien sesji. Poszczególne obiekty graficzne nazywane są obrazami. Przykładami obrazów są linia wykresu, bitmapy, pola stanu i liczniki. Niektóre obrazy wyświetlają informacje o stanie aplikacji dla użytkowników końcowych; niektóre pozwalają również użytkownikom na wprowadzanie informacji do aplikacji. Możemy tworzyć, usuwać, ukrywać, wyświetlać, nakładać lub przenosić obrazy w dowolnym momencie, gdy aplikacja jest uruchomiona. Na przykład, aby utworzyć tekst, użytkownik musi wybrać obraz tekstu na pasku narzędzi obrazu i kliknąć żądany punkt, w którym użytkownik ma umieścić tekst. Następnie użytkownik powinien dwukrotnie kliknąć tekst i pojawi się okno opcji tekstu. W tytule okna opcji tekstu użytkownicy mogą wpisać tekst. Interfejsy użytkownika są połączone ze sobą za pomocą funkcji. Te same kroki zostaną użyte do utworzenia przycisków "EXIT" i "HELP" w polu tytułowym. Jednocześnie wpisz "EXIT" i "HELP" w polu akcji. Po utworzeniu tego pojawi się okno sesji. Kontynuuj te same kroki dla innych przycisków, które są obecne w nadchodzącej sesji okna. Aby zmodyfikować sesję frontową, można również wstawić zdjęcie powiązanego tematu. Te same kroki zostaną podjęte w celu modyfikacji sesji frontowej. Użyj żółtej palety obrazu interfejsu użytkownika, który właśnie się pojawił, lub kliknij przycisk "Wybierz" w oknie sesji. Następnie kliknij "Obraz" i wybierz "Opcja mapy bitowej" z podmenu. W oknie sesji pojawi się krzyżyk. Przenieś go w odpowiednie miejsce w oknie sesji. Teraz upewnij się, że kursor znajduje się w fioletowym polu, które się pojawiło i kliknij dwukrotnie. Następnie utwórz pola obrazu bitmapowego, aby wstawić obraz w oknie sesji. Przycisk "Wyjdź" umożliwia użytkownikowi zamknięcie systemu. Po kliknięciu przycisku "Wyjdź" pojawi się okno. Użytkownik może wybrać zamknięcie całego okna sesji i zachowanie aplikacji Kappa-PC, zamknięcie Kappa-PC lub anulowanie funkcji.
Okno debugera widoku KAL
Debuger widoku KAL, jak pokazano na rysunku 17.9, służy do ostrzegania użytkowników o błędach w funkcjach i metodach. Okno debuggera widoku KAL jest podzielone na trzy części, które obejmują okno kodu źródłowego, okno wartości i okno obserwacyjne. Okno kodu źródłowego wyświetla źródło aktualnie badanej funkcji. Okno wartości służy do wyświetlania wartości zwracanej przez każdą instrukcję podczas przechodzenia przez wykonanie funkcji. Wyświetla również różne komunikaty. Okno obserwacji wyświetla wartości obserwowanych zmiennych lub slotów. Posiada pasek menu umożliwiający dostęp do wszystkich funkcji, za pomocą których można aktywować debugger widoku KAL.
Znajdź i zamień okno
Okno Znajdź i zamień służy do zastąpienia atomu, który pojawia się w bazie wiedzy. Aby znaleźć atom, należy wpisać atom w polu Znajdź. Ponieważ Kappa-PC rozróżnia wielkość liter, atom, który ma zostać zastąpiony, powinien być wpisany poprawnie. Atom, który ma zostać zastąpiony należy wpisać w polu zamień. Dla opracowanego systemu okno Znajdź/Zamień nie zostało użyte do zastąpienia żadnych atomów w bazie wiedzy. Wynika to z tego, że wszystkie obiekty są odpowiednio klasyfikowane według klasy, podklasy, instancji i slotów. Nie ma potrzeby zastępowania wystąpień atomów, ponieważ wszystkie obiekty zostały ułożone w dobrze zorganizowanym środowisku.
Okno reguł
Trzy narzędzia, w tym okno relacji reguły, okno śledzenia reguły i przeglądarka wnioskowania, są częścią okna reguł w Kappa-PC. Można go odwołać z paska menu. Okno śledzenia reguł umożliwia użytkownikom przeglądanie reguł wywoływanych przez aparat wnioskowania w formie transkrypcji. Pozwala również użytkownikom śledzić wpływ rozumowania na poszczególne miejsca w bazie wiedzy. Aby wykonać śledzenie reguł podczas wnioskowania opartego na regułach, śledzenie i łamanie powinno być wykonane z określonymi regułami lub przedziałami przed rozpoczęciem procesu wnioskowania. Pomaga użytkownikom śledzić proces rozumowania, który może być procesem łańcuchowym w przód lub w tył. Pozwala również użytkownikom śledzić wpływ rozumowania na poszczególne miejsca w bazie wiedzy. Aby przeprowadzić śledzenie reguł podczas wnioskowania opartego na regułach, śledzenie i łamanie powinno być wykonane z określonymi regułami lub przedziałami przed rozpoczęciem procesu wnioskowania. Pomaga użytkownikom śledzić proces tworzenia łańcucha wstecznego. Posiada rozwijane menu do wykonania wymaganej funkcji. Przeglądarka wnioskowania pokazana na rysunku 17.13 wyświetla powiązania łańcuchowe między regułami w sposób graficzny. Przeglądarka wnioskowania służy również do śledzenia źródła błędów w aplikacji KBS.
Streszczenie
Ta część zawiera podsumowanie podstawowych pojęć i wiedzy na temat rozwoju systemu oprogramowania Kappa-PC. Oprogramowanie Kappa-PC wykorzystuje reguły produkcji, ale podstawową wartością reprezentacji wiedzy jest obiekt. Obiekty Kappa-PC mogą mieć postać klas, podklas, a nawet instancji. Ogólnie rzecz biorąc, opracowany system ekspercki kodyfikuje wiedzę w postaci funkcji, reguł, obiektów, celów i innych w dostarczaniu szerokiego zakresu zastosowań.
Zielona integracja Lean w produkcji Przemysłu 4.0
W ostatnich latach w wielu wiodących światowych firmach wdrożono programy mające na celu opracowanie efektywnych systemów produkcji szczupłej. Wiele z nich odniosło duże sukcesy w zwiększaniu wydajności, obniżaniu kosztów, skróceniu czasu reakcji klientów i przyczynianiu się do poprawy jakości, większej rentowności i poprawa wizerunku publicznego. Niektóre firmy zobowiązały się do ograniczenia negatywnego wpływu swojej działalności na środowisko. "Zielone" systemy spowodowały ogromne zmniejszenie zużycia energii, wytwarzania odpadów i wykorzystywanych materiałów niebezpiecznych. Dodatkowo podkreślany jest wizerunek firm jako organizacji odpowiedzialnych społecznie. Kilka prac badawczych wskazuje, że szczupłe firmy wykazują znaczną poprawę ochrony środowiska dzięki większej zaradności i efektywności energetycznej. Niektóre badania pokazują również, w jaki sposób szczupłe i ekologiczne systemy wykorzystują wiele tych samych najlepszych praktyk, aby zmniejszyć ich ilość odpadów. Jednak zgodnie z panującym poglądem te dwa systemy mają tendencję do działania niezależnie, zarządzanego przez wyraźnie różniący się personel, nawet w obrębie tego samego zakładu produkcyjnego.
Zielony
Obecna definicja zieleni to pojęcie "pomagania w utrzymaniu środowiska dla przyszłych pokoleń". Chociaż ostatecznie to prawda, pilne potrzeby w chwili obecnej wymagają bardziej natychmiastowych i konkretnych zwrotów w celu uruchomienia projektów w najbliższej przyszłości. Obecnie zwroty, takie jak dodatni przepływ środków pieniężnych, zmniejszenie kosztów energii, materiałów i kosztów operacyjnych, mogą zrujnować lub zepsuć firmę.
Lean green
Zielona jest podzbiorem zrównoważonego rozwoju (a zatem zielona produkcja jest podzbiorem zrównoważonej produkcji). W ramach szczupłych badań ekologicznych próbowano wypełnić lukę pomiędzy niewystarczającymi narzędziami i metodami dla inicjatyw środowiskowych w porównaniu z wystarczającymi narzędziami i metodami w produkcji. Ricoh zdefiniował zrównoważony rozwój w kategoriach rozwoju i postępu w następujący sposób: "Dążymy do stworzenia społeczeństwa, którego wpływ na środowisko jest poniżej poziomu, z jakim może sobie poradzić zdolność środowiska naturalnego do samodzielnej naprawy". Ponadto podają prosty przykład: "cel redukcji emisji CO2 jest generalnie oparty na poziomie emisji z 1990 r., ale w przyszłości musimy ograniczyć emisje w oparciu o szacowany poziom emisji, aby zdolność Ziemi do samoregeneracji radzić sobie z." W związku z tym definicja ta wskazuje na kluczowe elementy, że oprócz zwykłego nacisku na biznes i ochronę środowiska istnieje silny komponent społeczny (zwykle definiujemy trzy "nogi" do zrównoważonego rozwoju jako korzyści ekonomiczne, korzyści środowiskowe i korzyści społeczne), istnieje porównanie z "zrównoważonym poziomem", który ma naturalne korzenie (np. zdolność środowiska do akomodacji wkładu/wpływu, jaki na nie wywieramy) oraz potrzebę dostosowania naszego poziomu wpływu, aby był z tym spójny. Poza tym Ricoh zilustrował potrzebę dostosowania celu, aby zapewnić, że utrzymamy się na akceptowalnym poziomie wpływu - to znaczy dostosować naszą definicję poziomu zrównoważonego rozwoju, na który jest nastawiony. Stawia to przed inżynierami prawdziwe wyzwania, zwłaszcza w zakresie wytwarzania i wytwarzania towarów. Obecnie, jeśli nie działamy na "zrównoważonym poziomie" (pomyśl o przykładzie Ricoh i poziomie energii/materiałów/wody/innych zasobów wykorzystywanych do produkcji lub wpływów produkcji), musimy dostosować nasze procesy, systemy i przedsiębiorstwa z czasem osiągnąć ten poziom. Nie jest to łatwe ze wzrostem liczby ludności i towarzyszącym mu popytem na wzrost, po prostu "biznes jak zwykle", co zwiększy niezrównoważone trendy. Dlatego potrzebujemy spotęgowanej redukcji naszego wpływu/wykorzystania, która uwzględnia zarówno wzrost popytu, jak i różnicę między zrównoważonym i niezrównoważonym poziomem konsumpcji/wpływu. To niedopasowanie to tzw. klin, na który zwrócił uwagę znakomity artykuł o klinach stabilizacyjnych. Ekologiczna produkcja zajmuje się technologiami i rozwiązaniami, które zapewniają te kliny - pomagają "odwrócić supertankowiec", jeśli chcesz, a najlepiej, gdy przy wystarczającej liczbie klinów przejdziemy od zwykłego biznesu do zrównoważonego poziomu wpływu/zużycia. Dlatego naszym założeniem jest to, że można to zrobić dla naszej przewagi konkurencyjnej i z zyskiem. Rosnąca strategia integracji zarówno szczupłej, jak i zielonej produkcji jest potencjalnym podejściem do osiągania celów biznesowych, takich jak zysk, wydajność i zrównoważenie środowiskowe
Integracja lean i green
Lean zintegrowane z zielonym dotyczą trzech sekcji: szczupłego systemu zarządzania, szczupłej techniki redukcji odpadów oraz szczupłych wyników biznesowych.
Potrzeby Lean green
Ekologia to ważny trend w erze odpowiedzialności za środowisko. W przeciwieństwie do produkcji odchudzonej, która koncentruje się na sposobach usprawnienia operacji i redukcji odpadów z perspektywy klienta, inicjatywy ekologiczne skupiają się na sposobach eliminacji odpadów z perspektywy środowiska. Przy obecnym napiętym rynku kredytowym, wysokich kosztach surowców i transportu, ostrej globalnej konkurencji i słabego dolara, szczupła i ekologiczna produkcja może zapewnić przewagę konkurencyjną i rentowność, której poszukuje wielu producentów. Poza tym siedem form marnotrawstwa Taiichi Ohno jest również jednym z powodów, dla których integracja jest potrzebna w green lean, co należy zidentyfikować i wyeliminować w dążeniu do zielonych systemów biurowych i biznesowych, podobnie jak w produkcji. Oto siedem form marnotrawstwa wprowadzonych przez Ohno:
1. Korekta
2. Konieczna nadprodukcja
3. Ruch
4. Ruch materiału
5. Czekam
6. Inwentarz
7. Proces.
COMMWIP to akronim [z angielskiego], który został opracowany, aby pomóc ludziom zapamiętać siedem form odpadów (uwaga: formularze COMMWIP są takie same, jak te wprowadzone przez naukowca Toyoty, Ohno, ale z innymi słowami i porządkiem). Dobrą wiadomością jest to, że walka z siedmioma formami odpadów staje się podstawą do ograniczenia tradycyjnych odpadów związanych z bezpieczeństwem i środowiskiem:
1. Korekta to wady, które są równoznaczne z urazami i chorobami, a także zmarnowane materiały, które mają negatywny wpływ na środowisko. Redukcja defektów zmniejsza narażenie ludzi i środowiska.
2. Nadprodukcja może zwiększyć ryzyko ergonomiczne pracowników i spowodować konieczność utylizacji przestarzałych materiałów bez ich użycia.
3. Wnioski, które nie dodają wartości, często powodują stres i napięcie dla pracowników. Sięganie, zginanie i skręcanie nie dodaje wartości klientowi, ale zwiększa ryzyko obrażeń pracowników.
4. Ruch materiałów zwiększa narażenie na przemieszczanie się materiałów na hali produkcyjnej iw mniejszym stopniu w biurze. Zmniejszenie narażenia zmniejsza ryzyko dla pracowników i potencjalne wycieki mające wpływ na powietrze, wodę lub odpady stałe.
5. Czekanie powoduje stres w systemie, czy to na hali produkcyjnej, czy za biurkiem. Niezrównoważone obciążenia pracą przyczyniają się do stresu fizycznego i psychicznego.
6. Zapasy zwiększają ryzyko potknięć i martwych punktów, a także możliwość złomowania materiału w pewnym momencie.
7. Odpady procesowe często tworzą dodatkowe kroki i błędy w systemie bez wartości dodanej. Proces jest często główną przyczyną urazów, chorób i marnotrawstwa środowiskowego.
Należy jednak pamiętać, że globalizacja wymaga większej konkurencyjności firm prywatnych i publicznych, która powinna być skoncentrowana nie tylko na tematach związanych z efektywnością systemów produkcyjnych, ale również na tych czynnikach produkcji, które wiążą się z zachowaniem środowiska. W białej księdze opisano myślenie stojące za zmianą paradygmatu na przejście na ekologię oraz zwiększenie działalności i zysków, jakie może ona wygenerować. Jak każda zmiana, zmiana paradygmatu, będą ci, którzy ją przyjmą i ci, którzy się jej sprzeciwią. Znajomość powodów zmiany w kierunku bardziej ekologicznego sposobu bycia, jak widać w przypadku biznesowym, a następnie posiadanie sprawdzonego, systematycznego podejścia do ekologicznego podejścia, takiego jak podejście ekologicznego strumienia wartości, zapewnia wsparcie potrzebne do rozpoczęcia tej zmiany. Wczesne wprowadzenie zmian zapewni organizacji miejsce jako dochodowego lidera w coraz bardziej globalnym ruchu w kierunku zrównoważonego rozwoju środowiska.
Korzyści Lean Green
Stosowanie Lean Green w produkcji przynosi wiele korzyści. Wiele firm wykorzystuje lean green, aby osiągnąć swoją misję i odnieść większy sukces. Tutaj omówiono sześć korzyści. Jednak korzyści w zakresie działalności gospodarczej, które zwiększa konkurencyjność. Istnieją bezpośrednie oszczędności kosztów, większa lojalność i atrakcyjność klientów, większa atrakcyjność i utrzymanie pracowników, zdolność do wzrostu, innowacyjność i rozwój nowych technologii oraz zwiększony zysk i wartość dla akcjonariuszy. W biznesie lean green jest stosowany do bezpośrednich oszczędności kosztów podczas prowadzenia działalności. Obniżone zostają koszty surowcowe, operacyjne i administracyjne. Lepiej jest zużywać mniej surowców, poddawać recyklingowi lub ponownie wykorzystywać je w celu uzyskania pozytywnego wpływu na środowisko, co pozwala zaoszczędzić pieniądze. Ponadto, jeśli zużyje się mniej energii i wody, będzie wytwarzanych mniej śmieci i mniej podróżowania na odległość. W ten sposób można zaoszczędzić ogromne ilości materiałów, a także zmniejszyć koszty operacyjne i administracyjne. Wiele firm już zbiera te oszczędności, które są dodawane do wyniku finansowego. To prosty, prawdziwy i logiczny pomysł, który można zaakceptować. W dzisiejszych czasach biznes i wszystkie transakcje odbywają się na całym świecie. W związku z tym firmy będą miały trudności z pozyskiwaniem nowych klientów do współpracy z nimi, a także z penetracją rynków. Firma powinna starać się wejść w globalny biznes i konkurować z innymi firmami. Jednocześnie na rynku internetowym lub globalnym możliwe jest przyciągnięcie stałych klientów, a także uczynienie z rynku wyboru klientów. Wszystkich klientów należy docenić, zapewniając im dobre usługi. Podobnie te same procedury można zastosować do dostawców, aby stworzyć dobre wartości dla biznesu. Jednak przyciąganie nowych klientów powinno być traktowane priorytetowo, a nie istniejących klientów. Badanie z lutego 2008 r. przeprowadzone przez Cone Inc. we współpracy z Boston College Center for Corporate Citizenship potwierdziło to twierdzenie. W tym badaniu około 59% z 1080 uczestników jest zaniepokojonych czynnikami środowiskowymi i zmienia swoje nawyki zakupowe. Z tej ankiety 66% uczestników stwierdziło, że faktycznie wiedzą i dokładnie rozważają, kiedy coś kupują. Jednak 68% z nich stwierdziło, że ich działanie w celu zakupu produktu lub usługi zależy od reputacji firmy w trosce o środowisko. Jeśli firma stale stosuje zielone, firma jest znacznie lepsza w przyciąganiu nowych klientów i utrzymywaniu dotychczasowych klientów. Ten sposób jest znacznie lepszy w porównaniu z innymi firmami, które nie stosują zieleni. firma. Dlatego pracodawcy muszą skoncentrować się na powiązanych aspektach, które wykazują wrażliwość w zakresie zatrudniania, utrzymywania i przekwalifikowania ich wszystkich. Globalna konkurencja musi podejmować ryzyko związane z zatrzymaniem i przyciągnięciem dobrych pracowników. Skupienie się na kwestiach ekologicznych lub związanych ze zrównoważonym rozwojem, podejmowanych przez organizację, pomoże sprostać temu wyzwaniu, ponieważ pracownicy zostaną dłużej w firmie, która ich zdaniem potraktowała ich dobrze i uczciwie . Spośród 28% respondentów z ankiety Cone Inc. Millennia (omawianej wcześniej), którzy pracowali w pełnym wymiarze godzin, 79% z nich chciało pracować dla firmy, która dba o to, jak wpływa lub przyczynia się do społeczeństwa . Jednak 64% jest lojalnych wobec swojej firmy ze względu na działania społeczne i środowiskowe firmy, a kolejne 68% stwierdziło, że nie chce pracować, jeśli firma nie dba o obowiązki społeczne i środowiskowe. Krótko mówiąc, jeśli firmy mają zamiar zatrzymać swoich dobrych pracowników, a jednocześnie starają się przyciągnąć swoich pracowników, mogą rozważyć zastosowanie ekologii i uniknąć bycia ominiętym przez swoich konkurentów, którzy już stosują tę zasadę. Kolejną korzyścią jest możliwość rozwoju. Firma może rozwijać się, prowadząc, rozwijając i zwiększając rozmiar firmy, podążając za rosnącym zapotrzebowaniem na coś. Można to wyjaśnić bardziej szczegółowo, określając, które koszty należy obniżyć w zależności od ceny wspólnotowej lub rządowej, na przykład ceny ropy naftowej. Firma będzie poszukiwać i znajdować przyjazne dla środowiska alternatywy, jeśli skoncentruje się głęboko na wpływie swoich istniejących produktów na środowisko. W ten sposób można wyeliminować nieunikniony wzrost kosztów materiałowych przez pozostałą część życia produktów. Inny przykład dotyczy operacji energochłonnych. Nieustanne koncentrowanie się na oszczędzaniu energii przy jednoczesnym wspieraniu alternatywnych źródeł czystej energii pomoże w zwiększeniu kosztów energii. Skupienie się na poprawie wpływu firmy na środowisko spowoduje, że pomysły dotyczące redukcji zużycia energii będą płynąć od pracowników, aby zapewnić ciągłe podejmowanie właściwych decyzji dotyczących energii. Zbieranie materiałów lub zasobów naturalnych szybciej niż one się regenerują lub używanie materiałów, których nie można zregenerować, w pewnym momencie zahamuje wzrost i ograniczy produkcję. Niezbędne jest, aby firma, aby utrzymać wzrost, musiała rozpocząć podróż w kierunku zrównoważonego rozwoju środowiska, zanim będzie za późno, a przy planowaniu należy wziąć pod uwagę wszystkie elementy łańcucha dostaw. Koncentrując się na ekologii, wraz z lean, ciągłe doskonalenie firm będzie stałym problemem i stanie się częścią codziennego życia. Innowacje będą podkreślane, gdy wyzwanie sprowadza się do tego, jak można zrobić inaczej i lepiej, aby zmniejszyć wpływ na środowisko. Poprzez ciągłe dążenie do robienia rzeczy lepiej, innowacja staje się kluczem do sukcesu. Dzięki zaangażowaniu w szczupłe i ekologiczne praktyki, narzędzia i innowacyjne procesy myślenia staną się wysokim priorytetem. Lean będzie jednym z najsilniejszych sojuszników, a w połączeniu z zielonym podejściem będzie napędzać innowacje. Nie jest tajemnicą, że innowacyjność jest kluczowym czynnikiem sukcesu każdej organizacji, ponieważ pozwala firmie obniżyć koszty i czas realizacji oraz zwiększyć wydajność. Wszystkie te elementy docenią klienci. Bycie innowacyjnym odnosi się do rozwijania umiejętności robienia rzeczy inaczej. Wymaga to wdrożenia lean thinking i środowiska pracy bez winy, które opiera się na szacunku i myśleniu procesowym. Te cechy w połączeniu z otwartą komunikacją, szczupłym przywództwem i znaczącym zaangażowaniem pracowników doprowadzą do oszczędności kosztów i innych korzyści płynących z przejścia na ekologię. Inne zalety to zwiększona produktywność i pojemność, skrócony czas realizacji, co prowadzi do większych oszczędności, korzyści i rzeczywistej wartości dla klientów. Na przykład użycie mniejszej ilości materiału prowadzi do mniejszego przetwarzania, co skutkuje obniżonymi kosztami procesu. Jeśli w grę wchodzi mniej transportu, to również przyczyni się do skrócenia czasu realizacji, a także będzie mniej śmieci do przenoszenia i zajmowania się oraz więcej czasu na zbudowanie produktu i przyspieszenie dostawy do klientów. Skupienie się na ekologii i lean sprawi, że pracownicy będą myśleć nieszablonowo, doświadczając z pierwszej ręki, w jaki sposób mogą pomóc klientom zmniejszyć ich wpływ na środowisko poprzez korzystanie z produktów i usług firmy. Skupienie się na lean i green będzie dodatkowo zachęcać do innowacji, które mogą prowadzić do rozwoju nowych technologii, których oczekują klienci, co z kolei może pomóc firmom w zmniejszeniu ich śladu środowiskowego. Łatwo zauważyć, w jaki sposób dążenie do ekologii napędza doskonalenie procesów i rozwój nowych technologii. Rynek nowych zielonych technologii, zarówno na poziomie business-to-business, jak i business-toconsumer, rośnie wykładniczo i będzie rósł tylko w miarę, jak świat szuka sposobów na zmniejszenie wpływu na środowisko. Skupienie się na ekologii będzie napędzać rozwój nowych i bardziej ekologicznych technologii, które pozwolą oferować rozwiązania, których szukają klienci, i zapewnią zdolność do zaspokojenia potrzeb klientów obecnie iw przyszłości. To ostatnia zaleta chudego zieleni. Jednak lean green może być postrzegany jako platforma dla firmy do zwiększania zysków i jednoczesnego uzyskiwania ogromnych oszczędności poza pierwotnymi założeniami. Nie jest niczym niezwykłym, że przechodząc na zielono firmy zwiększają swoje zyski o 35% lub więcej w czasie krótszym niż 5 lat. Badanie wykazało, że duże przedsiębiorstwo może w ciągu 5 lat przynosić zysk rzędu 38%. Badanie Willarda wykazało również, że mniejsze przedsiębiorstwa mogą uzyskiwać jeszcze wyższy odsetek, a niektóre osiągają ponad 50%. Ten wzrost zysku jest zwykle pochodną ciągłego doskonalenia rozwoju kultury, zaangażowania w dany proces i produktywności pracowników, zużycia materiałów i kosztów operacyjnych. Wielkość sukcesu będzie zależeć od stopnia zaangażowania każdego pracownika i dostosowania do ogólnej wizji i celów biznesowych. Dodatkowym czynnikiem będą zwiększone przychody od nowych i lojalnych dotychczasowych klientów. Sukces jest widoczny nie tylko w badaniach empirycznych, ale także w zimnych, twardych wynikach finansowych, które podlegają audytowi zwłaszcza ze spółek notowanych w Dow Jones Sustainability Index (DJSI). Ten indeks śledzi wyniki finansowe wiodących firm na całym świecie, kierujących się zrównoważonym rozwojem, które konsekwentnie przewyższają resztę rynku. W oczach akcjonariuszy jest to wartość, której poszukują inwestorzy.
Wady Lean Green
Wraz ze wzrostem regulacji rządowych i wzrostem świadomości społecznej w zakresie ochrony środowiska, obecnie firmy po prostu nie mogą ignorować kwestii środowiskowych, jeśli chcą przetrwać na globalnym rynku. Oprócz przestrzegania przepisów dotyczących ochrony środowiska dotyczących sprzedaży produktów w niektórych krajach, firmy muszą wdrażać strategie dobrowolnego ograniczania wpływu ich produktów na środowisko. Integracja wyników środowiskowych, ekonomicznych i społecznych w celu osiągnięcia zrównoważonego rozwoju jest głównym wyzwaniem biznesowym nowego stulecia. Cztery rodzaje wskaźników, z których każdy wyraża inny rodzaj wpływu na stan zasobów naturalnych, to:
(a) Ścieki. Wskaźniki te obejmują całkowite zużycie wody i niektóre określone krytyczne odpady wodne (dwutlenek węgla, całkowity azot, fosfor, rozpuszczone sole) z zakładów dostawcy.
(b) Emisje do powietrza. Zanieczyszczenie powietrza występuje, gdy w powietrzu znajdują się gazy takie jak SO2, NH3, CO, HC1, pył i spaliny w szkodliwych ilościach. Ilość emisji do powietrza może być szkodliwa dla zdrowia lub komfortu człowieka, co może spowodować uszkodzenie roślin i materiałów.
(c) Odpady stałe. Odpady stałe to wszelkie wyrzucone (porzucone lub uznane za odpady) materiały. Odpady stałe mogą być materiałem stałym, płynnym, półstałym lub gazowym w kontenerach. Przykładami odpadów stałych są złom metalowy, zużyte urządzenia i pojazdy, odpady domowe i niezanieczyszczony zużyty olej. Materiał jest wyrzucany, jeśli został porzucony przez wyrzucenie lub spalenie.
(d) Zużycie energii. Wykorzystanie energii jako źródła ciepła lub mocy lub jako wsadu surowcowego do procesu produkcyjnego, takie jak wskaźnik, wskazuje na całkowite zużycie energii przez dostawcę w ciągu roku.
Elementy integrujące lean green
Cele ekologicznej produkcji to ochrona zasobów naturalnych dla przyszłych pokoleń. Zaletą ekologicznej produkcji jest stworzenie świetnej reputacji w społeczeństwie, obniżenie kosztów oraz promowanie badań i projektowania. Ekologiczna produkcja ma kilka procesów, przez które trzeba przejść, aby utrzymać nasze środowisko w czystości. "Zajmuje się inteligentnym projektowaniem produktów, procesów, systemów, organizacji i wdrażaniem inteligentnych strategii zarządzania, które skutecznie wykorzystują technologię i pomysły, aby uniknąć problemów środowiskowych, zanim się pojawią". Innymi słowy, firmy tworzą "czystsze procesy i produkty", aby stworzyć lepsze środowisko. Różne zagrożenia i odpady powstające podczas produkcji oznaczają utracone pieniądze i niepotrzebne ryzyko odpowiedzialności. Wyeliminowanie tych dwóch czynników z kolei zwiększy popyt konsumentów na produkty ekologiczne, a korporacja zyska przewagę na konkurencyjnym rynku dzięki czystszym produktom. Istnieje siedem elementów integracji Lean Green:
1. Skoncentruj się na kliencie i eliminuj marnotrawstwo: Eliminację marnotrawstwa należy postrzegać z perspektywy klienta, a wszystkie działania, które nie dodają im wartości, powinny być dokładnie przestudiowane i wyeliminowane lub ograniczone. W kontekście integracji klient odnosi się do wewnętrznego sponsora lub grupy w organizacji, która korzysta ze zintegrowanych możliwości, korzysta z nich lub za nie płaci.
2. Ciągłe doskonalenie: Oparty na danych cykl hipotez - walidacja - wdrożenie powinien być wykorzystywany do napędzania innowacji i ciągłego doskonalenia procesu od końca do końca. Przyjmowanie i instytucjonalizacja wyciągniętych wniosków oraz utrzymywanie wiedzy o integracji to powiązane koncepcje, które ułatwiają ustanowienie tej zasady.
3. Wzmocnij zespół: Tworzenie wielofunkcyjnych zespołów i dzielenie się zobowiązaniami między jednostkami wzmacnia zespoły i osoby, które dobrze rozumieją swoje role i potrzeby swoich klientów. Zespół jest również wspierany przez kierownictwo wyższego szczebla, aby wprowadzać innowacje i wypróbowywać nowe pomysły bez obawy o porażkę.
4. Zoptymalizuj całość: Przyjmij całościową perspektywę całego procesu i zoptymalizuj całość, aby zmaksymalizować wartość klienta. Czasami może to wymagać wykonania poszczególnych kroków i czynności, które wydają się nieoptymalne, gdy patrzy się na nie w oderwaniu, ale pomagają w usprawnieniu procesu od końca do końca.
5. Zaplanuj zmiany: stosowanie technik masowego dostosowywania, takich jak wykorzystanie zautomatyzowanych narzędzi, ustrukturyzowanych procesów oraz wielokrotnego użytku i sparametryzowanych elementów integracji, prowadzi do redukcji kosztów i czasu zarówno na etapie tworzenia, jak i uruchamiania cyklu życia integracji. Inną kluczową techniką jest warstwa usług oprogramowania pośredniego, która przedstawia aplikacjom trwałą abstrakcję danych za pośrednictwem znormalizowanych interfejsów, które umożliwiają zmianę podstawowych struktur danych bez konieczności wpływania na aplikacje zależne.
6. Automatyzacja procesów: Automatyzacja zadań zwiększa zdolność reagowania na duże projekty integracyjne równie skutecznie, jak drobne zmiany. W swojej ostatecznej postaci automatyzacja eliminuje zależności integracyjne z krytycznej ścieżki realizacji projektów.
7. Wbudowana jakość: kładzie się nacisk na doskonałość procesu, a jakość jest wbudowana, a nie kontrolowana. Kluczowym wskaźnikiem dla tej zasady jest wartość procentowa od pierwszego razu, która jest miarą tego, ile razy proces od końca do końca jest wykonywany. wykonywane bez konieczności wykonywania jakichkolwiek przeróbek lub powtarzania któregokolwiek z kroków.
Oto korzyści płynące z przyjęcia praktyk integracji Green Lean:
1. Wydajność: Typowe ulepszenia to poprawa wydajności pracy o 50% i skrócenie czasu realizacji o 90% dzięki ciągłym wysiłkom na rzecz wyeliminowania marnotrawstwa.
2. Sprawność: Komponenty wielokrotnego użytku, wysoce zautomatyzowane procesy i samoobsługowe modele dostarczania poprawiają sprawność organizacji.
3. Jakość danych: poprawia się jakość i wiarygodność danych, a dane stają się prawdziwym atutem.
4. Zarządzanie: Ustala się wskaźniki, które napędzają ciągłe doskonalenie.
5. Innowacje: Innowacje są ułatwiane dzięki podejściu opartemu na faktach.
6. Morale pracowników: personel IT jest zaangażowany w wysokie morale, co prowadzi do oddolnych ulepszeń.
Narzędzia Lean Green
Istnieją różne narzędzia Lean Green, a mianowicie kaizen, 5S, produkcja komórkowa, just-intime (JIT), całkowita konserwacja produkcyjna (TPM) i sześć sigma. Narzędzia te zostały przedstawione na początku tego rozdziału. Poza tymi narzędziami, 3P, znane również jako planowanie przedprodukcyjne, jest jednym z najpotężniejszych i najbardziej transformujących zaawansowanych narzędzi produkcyjnych i zwykle jest używane tylko przez organizacje, które mają doświadczenie we wdrażaniu innych metod lean. Podczas gdy kaizen i inne metody lean przyjmują proces produkcyjny i dążą do wprowadzania ulepszeń, 3P koncentruje się na eliminacji marnotrawstwa poprzez projektowanie produktów i procesów.
Proces przygotowania produkcji (3P)
Eksperci Lean zazwyczaj postrzegają 3P jako metodę spełniania wymagań klientów, zaczynając od czystego planu rozwoju produktu, aby szybko tworzyć i testować potencjalne projekty produktów i procesów, które wymagają najmniej czasu, materiałów i zasobów kapitałowych. Ta metoda zazwyczaj angażuje zróżnicowaną grupę osób w wielodniowy proces twórczy, aby zidentyfikować kilka alternatywnych sposobów zaspokojenia potrzeb klienta przy użyciu różnych projektów produktów lub procesów. 3P zazwyczaj skutkuje produktami, które są mniej złożone, łatwiejsze w produkcji (często określane jako projekt pod kątem możliwości wytwarzania) oraz łatwiejsze w użyciu i utrzymaniu. 3P może również zaprojektować procesy produkcyjne, które eliminują wiele etapów procesu i wykorzystują domowy sprzęt o odpowiedniej wielkości, który lepiej spełnia potrzeby produkcyjne. Ostatecznie metoda 3P reprezentuje radykalne odejście od ciągłego, przyrostowego doskonalenia istniejących procesów poszukiwanych za pomocą zdarzeń kaizen. Zamiast tego 3P oferuje potencjał do dokonania "skoku kwantowego" ulepszeń projektowych, które mogą poprawić wydajność i wyeliminować marnotrawstwo do poziomu, który można osiągnąć poprzez ciągłe doskonalenie istniejących procesów. Zespoły spędzają kilka dni (ze szczególnym naciskiem na wydarzenie 3P) pracując z 3P w celu opracowania wielu alternatyw dla każdego procesu i oceny każdej alternatywy pod kątem kryteriów produkcyjnych (np. wyznaczony czas trwania taktu) i preferowanego kosztu. Celem jest zazwyczaj opracowanie projektu procesu lub produktu, który spełnia najlepsze wymagania klienta w "najmniejszej ilości odpadów". Typowe kroki w turnieju 3P są następujące:
1. Zdefiniuj cele/potrzeby dotyczące projektu produktu lub procesu: zespół stara się zrozumieć podstawowe potrzeby klienta, które należy spełnić. Jeśli produkt lub prototyp produktu jest dostępny, zespół projektowy dzieli go na części składowe i surowce, aby ocenić funkcję, którą każdy z nich pełni.
2. Tworzenie diagramów: diagram rybich kości lub inny rodzaj ilustracji jest tworzony w celu zademonstrowania przepływu od surowca do gotowego produktu. Następnie zespół projektowy analizuje każdą gałąź diagramu (lub każdą ilustrację) i przeprowadza burze mózgów słowa kluczowe (np. rolka, obracanie, formowanie, zginanie), aby opisać zmianę (lub "transformację") dokonaną w każdej gałęzi.
3. Znajdź i przeanalizuj przykłady w naturze: Zespół projektowy następnie próbuje znaleźć przykłady każdego słowa kluczowego procesu w świecie przyrody. Na przykład formowanie można znaleźć w naturze, gdy ciężkie zwierzę, takie jak słoń, chodzi w błocie lub gdy ciśnienie wody kształtuje skały w rzece. Podobne przykłady są pogrupowane, a przykłady, które najlepiej ilustrują słowo kluczowe procesu, są analizowane, aby lepiej zrozumieć, w jaki sposób przykłady występują w naturze. Tutaj członkowie zespołu kładą duży nacisk na to, jak i dlaczego działa natura w przykładach. Po zbadaniu unikalnych cech naturalnego procesu członkowie zespołu omawiają, w jaki sposób można zastosować naturalny proces na danym etapie produkcyjnym.
4. Nakreśl i oceń proces: Tworzone są podzespoły, a każdy członek podzespołu musi narysować różne sposoby realizacji danego procesu. Każdy ze szkiców jest oceniany i wybierany jest najlepszy (wraz z dobrymi cechami ze szkiców, które nie zostały wybrane) do makiety.
5. Zbuduj, zaprezentuj i wybierz prototypy procesu: zespół tworzy prototypy, a następnie ocenia wybrany proces, spędzając kilka dni (jeśli to konieczne) pracując z różnymi odmianami makiety, aby upewnić się, że spełni ona docelowe kryteria.
6. Przeprowadź przegląd projektu: Po wybraniu koncepcji do dodatkowego udoskonalenia jest ona prezentowana większej grupie (w tym projektantom oryginalnych produktów) w celu uzyskania opinii.
7. Opracuj plan realizacji projektu: Jeśli projekt zostanie wybrany do kontynuowania, zespół wybiera lidera realizacji projektu, który pomaga określić harmonogram, proces, wymagania dotyczące zasobów i podział odpowiedzialności za ukończenie.
Odchudzone sieci dostawców dla przedsiębiorstw
Lean Manufacturing może pociągać za sobą istotne zmiany organizacyjne i technologiczne w działalności produkcyjnej firmy. Dzięki tym zmianom i możliwości uzyskania znaczących zysków, firmy często mogą stwierdzić, że bardziej produktywna będzie współpraca z dostawcami, którzy również przyjęli techniki lean i którzy mogą przekazać wynikające z tego oszczędności finansowe i lepiej dostosować się do harmonogramów odchudzonej produkcji "klienta". . Zasadniczo szczupłe sieci dostawców obejmują stosowanie technik szczupłej produkcji u wielu partnerów łańcucha dostaw w celu dostarczania produktów o odpowiednim projekcie i ilości we właściwym miejscu i czasie, co skutkuje wzajemnymi korzyściami w zakresie redukcji kosztów i odpadów dla wszystkich członków sieci. Leaning może wymagać radykalnej zmiany w sposobie myślenia i organizacji produkcji wśród dostawców, dlatego ścisła współpraca z istniejącymi dostawcami w celu bezpośredniego lub pośredniego ułatwienia Lean jest lepsza niż groźba zmiany dostawców, jeśli nie opierają się oni sami . Pierwszym krokiem w tworzeniu szczupłych sieci dostawców (i próbie wprowadzenia szczupłej sieci dostawcom, którzy nie są jeszcze narażeni na szczupłą pracę) jest przekazanie oczywistych korzyści wynikających z lean - nie tylko sieci, ale także każdemu indywidualnemu uczestnikowi. Następnym krokiem jest pomoc dostawcom w "odchudzonej transformacji" poprzez wysłanie doświadczonych trenerów do pracy z dostawcami (bezpłatnie) i/lub wyrażenie zgody na dzielenie się z nimi ostatecznymi oszczędnościami [6]. Bardziej szczegółowe opcje są następujące:
• Pomoc techniczna sieci: Często najskuteczniejszym podejściem jest wysłanie przez ubogiego "klienta" w sieci własnego zespołu oszczędnej produkcji do współpracy z dostawcami. Eksperci mogą przeprowadzać zarówno sesje szczupłego nauczania, jak i sesje "nauki przez działanie" dla dostawców, a także przeprowadzają okresowe wizyty powrotne w celu zapewnienia dokładnego zrozumienia i wdrożenia.
• Sieciowe wymiany lean: tam, gdzie członkowie sieci już zaczęli wdrażać lean, ale mogą korzystać z mądrości swoich partnerów w łańcuchu dostaw, firmy mogą "zamieniać" ekspertów technicznych Lean i innych pracowników oraz uczyć się nawzajem z doświadczeń.
• Konsultanci Lean: Firmy, które chcą, aby dostawcy stali się Lean, mogą zatrudnić zewnętrznych konsultantów z doświadczeniem w swojej branży, aby pomóc w transformacji.
• Stowarzyszenia dostawców: Stowarzyszenia dostawców stanowią kolejny sposób na uzyskanie korzyści ze wspólnych doświadczeń Lean. Takie stowarzyszenia mogą być zorganizowane według "poziomu" (gdzie wszyscy dostawcy pierwszego poziomu są zbierani, aby uczyć się od siebie). Stowarzyszenia te mogą następnie połączyć swoje zasoby, aby skoncentrować się na wspieraniu dostawców drugorzędnych. Tabela przedstawia korzyści środowiskowe płynące z metod szczupłych. Przedstawiono łącznie osiem metod lean wraz z odpowiadającymi im potencjalnymi korzyściami dla środowiska.
Metoda Lean: Potencjalne korzyści środowiskowe
Kaizen :
• Kultura ciągłego doskonalenia skupiająca się na eliminacji marnotrawstwa
• Odkrywaj i eliminuj ukryte odpady i działania generujące odpady
• Szybkie, trwałe wyniki bez znacznych inwestycji kapitałowych
5S :
• Zmniejszenie oświetlenia, zapotrzebowania na energię podczas czyszczenia okien i sprzęt jest pomalowany na jasne kolory
• Szybko zauważ rozlania i przecieki
• Zmniejsz ryzyko wypadków i wycieków dzięki wyraźnemu oznaczeniu i arterii bez przeszkód
• Zmniejszenie zanieczyszczenia produktów skutkujące mniejszą ilością wad produktów , co zmniejsza zapotrzebowanie na energię i zasoby (unika marnotrawstwa)
• Zmniejszenie powierzchni potrzebnej do operacji i przechowywania, potencjał zmniejszenia zapotrzebowania na energię
• Mniejsze niepotrzebne zużycie materiałów i chemikaliów, gdy sprzęt, części i materiały są uporządkowane, łatwe do znalezienia, mniejsza potrzeba utylizacji przeterminowanych chemikaliów
• Wskazówki wizualne mogą zwiększyć świadomość procedur postępowania z odpadami lub zarządzania odpadami, zagrożeń w miejscu pracy i procedur reagowania w sytuacjach awaryjnych
Produkcja komórkowa:
• Wyeliminuj nadprodukcję, zmniejszając w ten sposób odpady oraz zużycie energii i surowców
• Mniej defektów związanych z przetwarzaniem i zmianami produktów, zmniejszając zapotrzebowanie na energię i zasoby (unika marnotrawstwa)
• Szybko zauważaj usterki, zapobiegając marnotrawstwu
• Mniejsze zużycie materiałów i energii (na jednostkę produkcji) dzięki sprzętwi odpowiedniej wielkości
• Mniej potrzebnej powierzchni, potencjalne zmniejszenie zużycia energii i mniejsza potrzeba budowy nowych obiektów
• Łatwiejsze skoncentrowanie się na konserwacji sprzętu, zapobieganiu zanieczyszczeniom
JIT:
• Wyeliminuj nadprodukcję, zmniejszając w ten sposób odpady oraz zużycie energii i surowców
• Mniej potrzebnych zapasów w trakcie i poprocesowych, co pozwala uniknąć potencjalnych odpadów z uszkodzonych, zepsutych lub zepsutych produktów
• Częste obroty magazynowe mogą wyeliminować potrzebę odtłuszczania części metalowych
• Mniej potrzebnej powierzchni, potencjalne zmniejszenie zużycia energii i mniejsza potrzeba budowy nowych obiektów
• Może ułatwić usprawnienia procesów kierowane przez pracowników
• Mniejsze nadwyżki zapasów, zmniejszenie zużycia energii związanej z transportem i reorganizacją niesprzedanych zapasów
TPM :
• Mniej defektów, zmniejszenie zapotrzebowania na energię i zasoby (unikanie marnotrawstwa)
• Zwiększenie żywotności sprzętu, zmniejszenie zapotrzebowania na sprzęt zastępczy i związanego z tym wpływu na środowisko (energia, surowce itp.)
• Zmniejszenie liczby i nasilenia wycieków, przecieków i warunków zakłócających - mniej stałych i niebezpiecznych odpadów
Six sigma:
• Mniej defektów, zmniejszenie zapotrzebowania na energię i zasoby (unikanie marnotrawstwa)
• Skoncentruj uwagę na ograniczeniu warunków powodujących wypadki, wycieki i awarie, zmniejszając tym samym ilość stałych i niebezpiecznych odpadów
• Popraw trwałość i niezawodność produktu, zwiększając jego żywotność, zmniejszając wpływ na środowisko w celu zaspokojenia potrzeb klientów
3P :
Eliminacja odpadów na etapie projektowania produktu i procesu, podobnie jak w przypadku metod "Projektowania dla środowiska"
• Natura (z natury bezodpadowa) jest wykorzystywana jako model projektowy
• Sprzęt o odpowiedniej wielkości obniża wymagania materiałowe i energetyczne do produkcji
• Zmniejszenie złożoności procesu produkcyjnego ("projektowanie pod kątem wykonalności") może wyeliminować lub usprawnić etapy procesu, procesy wrażliwe na środowisko mogą być kierowane do wyeliminowania, ponieważ często są zasobożerne i kapitałochłonne
• Mniej złożone projekty produktów mogą wykorzystywać mniej części i mniej rodzajów materiałów, co ułatwia demontaż i recykling
Sieci dostawców Lean Enterprise:
• Zwiększenie korzyści dla środowiska płynących z szczupłej produkcji (zmniejszenie odpadów dzięki mniejszej liczbie wad, mniejszej ilości odpadów, mniejszemu zużyciu energii itp.) w całej sieci
• Urzeczywistniaj korzyści środowiskowe, wprowadzając lean do istniejących dostawców, zamiast znajdować nowych, już szczupłych dostawców
Ekologiczne standardy Lean
Zielony standard służy do standaryzacji systemu zarządzania środowiskiem na świecie. Zawiera szereg dokumentów dotyczących gospodarowania odpadami bez wpływu na środowisko. Jak dotąd, zielony nie ma pełnego standardu implementacji. Jednak serie ISO 14000 mają fundamentalne znaczenie w stosowaniu systemu zarządzania środowiskowego. Seria norm ISO 14000 została zaprojektowana, aby pomóc przedsiębiorstwom w spełnianiu ich potrzeb w zakresie systemu zarządzania środowiskowego, rozwijanego przez ISO od 1991 roku. Składają się one z zestawu dokumentów, które definiują kluczowe elementy zarządzania systemu, który pomoże organizacji rozwiązać problemy środowiskowe. System zarządzania obejmuje ustalenie celów i priorytetów, przypisanie odpowiedzialności za ich realizację, pomiar i raportowanie wyników oraz zewnętrzną weryfikację roszczeń. Mimo że pierwsze normy z tej serii zostały opublikowane dopiero pod koniec 1996 roku, wiele organizacji wdraża system przy użyciu wersji roboczych od połowy 1995 roku. Na całym świecie istnieje duże zainteresowanie tymi standardami. Jednak często brakuje jasnego zrozumienia, czym one są i jaką rolę mogą odegrać. Ponadto normy ISO 14000 zostały opracowane, aby pomóc organizacji we wdrożeniu lub udoskonaleniu systemu zarządzania środowiskowego. Standardy nie określają wartości wydajności, ale zamiast tego zapewniają sposób na systematyczne ustalanie i zarządzanie zobowiązaniami dotyczącymi wydajności. Oznacza to, że są zainteresowani ustaleniem "jak" osiągnąć cel, a nie "jaki" cel powinien być. Oprócz podstawowych standardów systemów zarządzania istnieje również szereg wytycznych, które zapewniają narzędzia wspierające. Obejmują one dokumenty dotyczące audytu środowiskowego, oceny efektywności środowiskowej i oznakowania środowiskowego oraz oceny cyklu życia. Prezes i Dyrektor Generalny Międzynarodowego Instytutu na rzecz Ekorozwoju stwierdził, że za dekadę możemy uznać normy ISO 14000 za jedną z najważniejszych międzynarodowych inicjatyw na rzecz zrównoważonego rozwoju. ISO 14000 definiuje dobrowolny system zarządzania środowiskowego. Stosowane są standardy wraz z odpowiednimi celami i zaangażowaniem kierownictwa w celu poprawy wyników firmy. Stanowią obiektywną podstawę do weryfikacji roszczeń firmy dotyczących jej wyników. Jest to szczególnie ważne w odniesieniu do handlu międzynarodowego, gdzie obecnie prawie każdy może wypowiadać się na temat wyników w zakresie ochrony środowiska, a środki pozwalające na rozwiązanie problemu prawdziwości są ograniczone. Konsumenci, rządy i firmy w łańcuchu dostaw poszukują sposobów na zmniejszenie swojego wpływu na środowisko i zwiększenie długoterminowego zrównoważonego rozwoju. Dla firm kluczowymi celami są zwiększenie wydajności - uzyskanie większej wydajności na jednostkę wkładu - przy jednoczesnym osiąganiu zysków i utrzymaniu zaufania interesariuszy. Pomogą w tym dobrowolne normy ISO 14000. Należy zauważyć, że ISO 14000 norm same w sobie nie określają celów w zakresie efektywności środowiskowej. Muszą one być ustalane przez samą firmę, biorąc pod uwagę wpływ standardów na środowisko oraz poglądy interesariuszy firmy. Wdrożenie podejścia opartego na systemie zarządzania pomoże firmom skupić uwagę na kwestiach środowiskowych i wprowadzić je w główny nurt podejmowania decyzji korporacyjnych. ISO 14000 ma na celu zapewnienie klientom uzasadnionej pewności, że deklaracje wydajności firmy są dokładne. W rzeczywistości ISO 14000 pomoże zintegrować systemy zarządzania środowiskowego firm, które prowadzą ze sobą handel na całym świecie. Proces ISO nie obejmuje w pełni wszystkich krajów lub poziomów działalności. Niektórzy konsumenci i organizacje ekologiczne mogą być sceptycznie nastawione do dobrowolnych standardów. Aby ten system działał dobrze, na całym świecie potrzebna jest duża ilość budowania zdolności. Wreszcie, zrównoważony rozwój wymaga, aby kwestie dobrostanu ludzkiego zostały włączone do polityki środowiskowej i gospodarczej. Podczas gdy zrównoważony rozwój wprowadzany jest w ramach norm ISO 14000, szczegółowe dokumenty dotyczą prawie wyłącznie kwestii środowiskowych.
Podsumowanie
Lean green, termin określający wykorzystanie szerokiej gamy narzędzi lean dla zrównoważonego rozwoju, przyniósł ogromne korzyści dla środowiska poprzez zmniejszenie marnotrawstwa zarówno zasobów, jak i energii. Wraz ze zmniejszeniem ilości odpadów oszczędzane są większe koszty bezpośrednie. Chociaż chuda zieleń może nie mieć jeszcze sztywnego standardu, obecnie stosowana jest seria ISO 14000. Lean green jest atutem dla świata, ponieważ może stanowić wytyczne dla bardziej ekologicznego środowiska w kierunku Przemysłu 4.0.
Lean Government w poprawie wyników sektora publicznego w kierunku Przemysłu 4.0
System rozwoju ludzi
W dzisiejszym konkurencyjnym świecie sukces rozwoju społecznego zależy od kompetentnego, dobrze funkcjonującego rządu i sektora publicznego. Żadna organizacja w biznesie, a nawet w sektorze publicznym w krajach rozwijających się nie może sobie jednak pozwolić na ograniczenie i eliminację zasobów odpadów, gdy staje przed wyzwaniem świadczenia szerokiego zakresu usług niezbędnych dla rozwoju - od infrastruktury i usług socjalnych po funkcjonowanie system i egzekwowanie praw własności - wszystko to stanowi wyzwanie, jak uzyskać "właściwe" zarządzanie. W obu organizacjach najbardziej niewykorzystanym zasobem są ich ludzie. Dobre zarządzanie zawsze było ważne w organizacjach, nawet zanim stało się modne, gdzie ludzie są jednym z niewielu wpływowych zasobów. Niemniej jednak zarządzanie jest złożone, zarówno jako idea, jak i praca potrzebna do urzeczywistnienia dobrego zarządzania w trakcie jego przenikania do naszej zbiorowej świadomości i przenikania sposobu, w jaki mówimy o zarządzaniu w biznesie, organizacjach społecznych lub administracji publicznej. Jakość instytucji zarządzających ma również istotny wpływ na wzrost gospodarczy. Niestety, większość krajów rozwijających się uważa, że centralnie regulowana polityka usług publicznych jest przeszkodą w skutecznym świadczeniu usług publicznych w nowoczesnych scenariuszach globalnej konkurencji . Jednym z powodów jest to, że rządy zawsze projektują usługi publiczne w oparciu o model uniwersalny, który ostatecznie prowadzi do przekonania, że standardowa usługa oferuje ekonomię skali. W rzeczywistości rządy, które inwestują w tę politykę, stają się bardziej wydajne, elastyczne i reagujące oraz mają większe szanse na osiągnięcie swoich celów w odniesieniu do tej części gospodarki, której dotyczy świadczenie podstawowych usług rządowych. Usprawnienie funkcjonowania rządu oznacza nie tylko poprawę efektywności i opłacalności funkcji i operacji sektora publicznego, ale także poprawę efektywności całego sektora publicznego, tak aby polityki i programy rządowe działały sprawnie, osiągały zamierzone cele, traktowały odbiorców z szacunkiem i godnością i pozytywnie wpływać na ludzi, w których są wyznaczeni, aby zminimalizować wszelkie negatywne, zniekształcające skutki uboczne. Co więcej, rządy na całym świecie znajdują się pod presją zmniejszenia wielkości sektora publicznego, budżetów i wydatków (czasem szczególnie w sektorze socjalnym), a jednocześnie poprawiają swoje ogólne wyniki, a potem pojawiają się wyzwania dla rządu , w szczególności poprzez znalezienie właściwej równowagi między odpowiedzialnością a zwiększoną elastycznością. Zakres zagadnień związanych z poprawą świadczenia i jakości sektora publicznego obejmuje tworzenie usług publicznych tam, gdzie są one potrzebne, a ich brak, natomiast w przypadkach, w których takowe istnieją, zwiększanie ich efektywności w celu osiągnięcia lepszych wyników. Powodem jest to, że sektory publiczne są częścią kontrolowaną przez społeczeństwo, gdzie świadczą również usługi, z których osoby niepłacące nie mogą skorzystać z usług przynoszących korzyści społeczeństwu, a nie tylko osobom korzystającym z usług, które zachęcają do równych szans. Sektory publiczne to podmioty będące własnością i/lub kontrolowane przez rząd, a także podmioty i relacje, które są finansowane, regulowane i obsługiwane wyłącznie lub częściowo przez rząd. Jednak najważniejsze i mocno krytykowane kwestie związane z różnymi ograniczeniami sektora publicznego są następujące:
• Brak motywacji. Pracownicy organizacji publicznych są częściowo przygotowani do podjęcia większego nakładu pracy i uważają, że stawiane im wymagania są raczej za małe niż za duże
• Urzędnicy stanu. Zbyt ściśle określony status determinuje brak elastyczności, a to przede wszystkim nie pozwala na optymalne wykorzystanie możliwości kadrowych, a tym samym uniemożliwia urzędnikom publicznym poszukiwanie kariery kadrowej w sektorze publicznym
• Brak możliwości kontynuowania kariery i rozwijania umiejętności
• Automatyczna aktualizacja pozycji
• Ograniczone możliwości w doborze personelu.
Wdrażanie lean w sektorze publicznym
Większość badań dotyczących oczekiwań związanych z doświadczeniami zakupowymi i konsumenckimi konsumentów na rynkach prywatnych jest teoretycznie wysoce adekwatna do doświadczeń ludzi z usługami publicznymi, chociaż wymagają modyfikacji do wykorzystania w kontekście sektora publicznego. Dr Zoe Radnor i pan Paul Walley, badacze z Warwick Business School, odkryli metodę stosowaną przez Toyotę w tworzeniu "odchudzonego" systemu produkcyjnego, który można zastosować w usługach sektora publicznego. Stosowanie "odchudzonego" sektora publicznego będzie miało pozytywny wpływ na morale pracowników, satysfakcję klientów i wydajność procesów, ponieważ organizacja poprawi czas oczekiwania klientów, wydajność usług, czas przetwarzania, przepływ klientów i jakość, osiągając więcej za mniej , generując lepsze zrozumienie procesu, lepszą wspólną pracę, lepsze wykorzystanie danych dotyczących wyników, większą satysfakcję i pewność personelu oraz lepszą kulturę ciągłości . W skrócie, technika lean opiera się na założeniu, że wszystkie organizacje składają się z wielu procesów organizacyjnych w poszukiwaniu wyznaczników wartości klienta. Bhatia i Drew stwierdzili, że podejście lean ma kluczowe znaczenie dla sektora publicznego, ponieważ przełamuje dominujący pogląd, że musi istnieć kompromis między jakością usług publicznych a kosztami ich świadczenia. Termin "szczupła" wywodzi się z bestsellera z lat 90. "Maszyna, która zmieniła świat: historia szczupłej produkcji". Autorzy książki, Daniel Jones i James Womack, zidentyfikowali pięć podstawowych zasad Lean w następujący sposób:
• Określ wartość pożądaną przez klienta.
• Zidentyfikuj strumień wartości dla każdego produktu, który zapewnia wartość i wyzwanie wszystkich zmarnowanych kroków.
• Spraw, aby produkt lub usługa "płynęła" w sposób ciągły w strumieniu wartości.
• Wprowadzić "ciągnięcie" między wszystkimi etapami, w których ciągły przepływ jest niemożliwy.
• Dąż do perfekcji, aby liczba kroków oraz ilość czasu i informacji potrzebnych do obsługi klienta stale spadała.
Read skomentował, że proces szczupłej produkcji może być wykorzystywany przez departamenty rządowe do poprawy koncentracji na kliencie i uniknięcia niektórych typowych pułapek biznesowych, ponieważ koncepcja szczupłej produkcji zachęca usługi do rozważenia trzech głównych elementów:
• Żądanie niepowodzenia (jaka dodatkowa praca jest tworzona z powodu niepowodzenia procesów)
• Usuń procesy, które nie dodają wartości (jakie prace można usunąć, ponieważ nie dodają wartości dla większości klientów)
• Zmniejszenie przepływu pracy między działami (ograniczenie "podwójnej" obsługi lub więcej pracy w punkcie kontaktu).
Dlatego, aby odnieść sukces, organizacje sektora publicznego muszą znaleźć sposób na dostosowanie swojej strategii rozwoju - dostarczanie nowych i lepszych usług przy ograniczonych kosztach - z uwzględnieniem interesów swoich pracowników, oprócz ciągłej optymalizacji kosztów, jakości i obsługi klienta. Stosując zasady lean, firmy biznesowe i rząd mogą dostosować swoje organizacje i inwestować w rozwój liderów zespołów. Chociaż różnią się wartością zasobów (zdolności i środowisk) oraz implikacjami dla projektowania i wdrażania strategii, takie organizacje sektora prywatnego i publicznego dążą do tworzenia wartości dla interesariuszy w swoim środowisku poprzez wdrażanie zasobów i zdolności. Bridgman stwierdził, że zgodność z kosztami jest znaczącą i obowiązkową inwestycją. Chociaż sama zgodność jest niewystarczająca do osiągnięcia wysokiej wydajności lub dobrego zarządzania, zrozumienie związku między zgodnością, wydajnością i dobrym zarządzaniem zwiększa szanse na osiągnięcie zwrotu z inwestycji. Strategia umożliwia jasne wdrożenie polityki i koncentrację wysiłków, co z kolei umożliwia zwiększenie zdolności procesu i wykorzystanie nowych możliwości. Aby stać się w pełni lean, organizacja musi rozumieć lean jako długoterminową filozofię, w której właściwe procesy przyniosą właściwe wyniki, a wartość może zostać dodana do organizacji poprzez ciągły rozwój ludzi i partnerów, przy jednoczesnym ciągłym rozwiązywaniu problemów w celu stymulowania organizacyjnego uczenia się. Chociaż nie ma dokładnej definicji w pełni szczupłej organizacji, ważne jest, aby organizacja zrozumiała i stosowała wszystkie praktyki i zasady. Ważne jest również, aby zrozumieć, że szczupłe myślenie, które wpływa na cały model biznesowy, jest kluczem, a nie tylko szczuplejszą produkcją, w której stosuje się tylko części całej filozofii szczupłej.
Pomiar wyników w doskonaleniu sektora publicznego
Obecnie mierzenie wyników jest kluczowe dla nowego zarządzania publicznego, które charakteryzuje się jako globalny ruch odzwierciedlający zarządzanie wyzwoleniem i zarządzanie oparte na rynku. Zarządzanie wyzwoleniem obejmuje menedżerów sektora publicznego, którzy są otoczeni mnóstwem nieporęcznych i niepotrzebnych zasad i regulaminów. Zamiast kontrolowania czynników wejściowych, głównym celem powinny być pomiary wyników. Sektory publiczne mają głównie charakter instytucjonalny, a ich skuteczność może się różnić w zależności od kontekstu kulturowego i historycznego, ram prawnych i instytucji, a także różnic w poziomach rozwoju społeczno-gospodarczego między krajami o wysokich, średnich i niskich dochodach. Niektóre formy organizacyjne nie są zgodne z administracją publiczną; poza tym skala organizacji wpływa na jej zdolność do realizacji złożonych działań zarządczych. Duże agencje mogą sobie pozwolić na koszty organizacyjne silnej zgodności i działań związanych z wydajnością, podczas gdy mniejsze mogą mieć trudności z pokryciem tych kosztów ogólnych. Ale jeśli skala ułatwia znajdowanie zasobów, może również utrudnić rządzenie, ponieważ większości jednostek rządowych przydziela się budżet w ramach scentralizowanego procesu. Ma to ważne implikacje i wskazuje na różnice w porównaniu z innymi sektorami. Dlatego pomiar wyników może dostarczyć danych o tym, jak skutecznie i wydajnie świadczone są usługi publiczne. W sektorach publicznych pomiar wyników przyczynił się do zmiany wartości zamówienia na różnych poziomach. W każdym razie zarządzanie i mierzenie wyników były kluczowymi czynnikami napędowymi reformy sektora publicznego w ostatnich latach. Mierniki wydajności są niezbędne, aby być konkurencyjnym w stosunku do sektora prywatnego. Oto kilka przykładów działań praktykowanych przez sektor prywatny:
• Głos i odpowiedzialność (w Chinach obywatele prowincji Lioning uczestniczą w lokalnych przesłuchaniach przeciwko poważnym przypadkom korupcji i przekierowaniu środków publicznych)
• Uproszczenie administracji (gminy i organy doradcze gmin, np. KGSt lub Kommunale zemeinschaftsstelle fu¨r Verwaltungsvereinfachung, które współpracują z radami samorządowymi i są organem doradczym niemieckich samorządów (miast, gmin i krajów). nowy model sterowania, który wykorzystuje model Tilburga jako schemat referencyjny pomiaru wydajności)
• Punkty kompleksowej obsługi (na Łotwie w administrację publiczną w celu zmiany priorytetów administracji publicznej, tak aby intencją było służenie ludziom i każdemu, kto uczęszcza do właściwej instytucji tylko raz, mógł otrzymać niezbędną usługę)
• Strategiczne zarządzanie personelem (w Kownie na Litwie w zarządzaniu personelem poprzez nowe zarządzanie publiczne)
• Odrzucenie oczekiwań, zakotwiczenie oczekiwań i proces dostarczania (w Anglii w przeciwieństwie do usług i zbiórki odpadów z gospodarstw domowych)
• Kompleksowe zarządzanie jakością (w Malezji)
• Inicjatywa zarządzania zorientowanego na wyniki (w Ugandzie)
• Prywatyzacja i redukcja rozmiarów (w Wielkiej Brytanii i Nowej Zelandii w przekształcaniu działów usługowych w niezależne agencje lub przedsiębiorstwa, zarówno w służbie cywilnej, jak i poza nią).
Zarządzanie ukierunkowane na rynek ma na celu stworzenie wewnętrznej i zewnętrznej konkurencji o zasoby budżetowe w celu zmniejszenia nieefektywności X i maksymalizacji budżetu. Cłaarnieniu et al. [15] skomentował, że aby organizacja stała się "wysoka wydajność", organizacja publiczna musi skoncentrować się na następujących aspektach swojej organizacji:
• Wizja, misja i cel ukierunkowane na ciągłe doskonalenie
• Preferencja do pracowników o wielu kwalifikacjach
• Bardziej płaska i bardziej elastyczna hierarchia zastępuje wysoką i sztywną hierarchię organizacyjną
• Wzbogacenie pracy i rozproszone podejmowanie decyzji, wynikające z promowania ciągłego uczenia się na wszystkich poziomach organizacji
• Kontrola zarządcza jest w mniejszym stopniu utrzymywana przez sprawowanie władzy formalnej.
Krytyczne czynniki sukcesu muszą być spełnione w następujący sposób:
• (Rozwijająca się) Gotowość organizacyjna
• Kultura organizacyjna i własność
• Zaangażowanie i możliwości kierownictwa
• Odpowiednie zasoby finansują wstępne zmiany i zewnętrzną wiedzę fachową, które będą tworzyć trwałe wewnętrzne umiejętności i kompetencje
• Jasny proces komunikacji i zaangażowanie
• Strategiczne wdrażanie i zarządzanie działaniami lean (podejście strategiczne)
• Wsparcie zewnętrzne
• Praca zespołowa
• Czas.
System kontroli wyników może służyć dwóm celom: mierzeniu i motywowaniu. Firma staje się tym, co mierzy. Pomiar stał się tak akceptowanym podejściem w organizacjach, że wiele wysiłku wkłada się w określenie "co" można zmierzyć i "jak" to zmierzyć. Każda czynność pomiarowa wiąże się z kosztami zarówno w zakresie wdrażania, jak i utrzymania. Kilka indywidualnych pomiarów wydajności zostanie zintegrowanych z systemem pomiaru wydajności.
Problemy Lean Implementation w sektorze publicznym
Oczywiście są przeszkody do pokonania. Stosowanie lean jest trudne w sektorze prywatnym, a jeszcze bardziej w publicznym. Największym wyzwaniem stojącym przed wdrożeniem Lean w organizacjach jest uwolnienie zasobów z istniejących działań, aby przeznaczyć je na nowe inicjatywy, ponieważ menedżerom sektora publicznego czasami brakuje umiejętności, doświadczenia i nastawienia do wprowadzenia takiego podejścia. Sztywność organizacyjna oraz silosowe struktury i myślenie utrudniają współpracę i komunikację między agencjami, gdzie znalezienie niezbędnych zasobów staje się znacznie bardziej skomplikowane. Dlatego twórcy szczupłego systemu powinni zidentyfikować kompleksowe procesy z perspektywy klienta, a następnie zaprojektować i zarządzać systemem, aby zapewnić płynny przepływ informacji i materiałów przez te procesy. Gdy pomiar wydajności jest wykorzystywany przede wszystkim do pomocy administratorom w zarządzaniu agencjami, zadanie ich rozwijania jest bardziej postrzegane jako inwestycja. Jednakże, gdy rozwój pomiaru wyników jest narzucany z zewnątrz, może to pomóc w odpowiedzialności wewnętrznej, ale jest środkiem do zapewnienia odpowiedzialności zewnętrznej, a zatem może napotkać opór. Problemy te wynikają z charakteru metryk lub instrumentów wykorzystywanych do analizy porównawczej i ocena zmian w wynikach, kontekst polityczny działania agencji oraz możliwe dysfunkcje pomiaru wyników . Lean w sektorze publicznym nie jest szybkim rozwiązaniem, przynoszącym stałe wyniki w długim okresie wdrażania. Tak czy inaczej, istnieje potrzeba, aby wiele organizacji, które natychmiast stosują lean, uzyskały doświadczenie w zarządzaniu zmianą lub właściwy styl przywództwa, aby natychmiast dokonać transformacji, ponieważ większość organizacji publicznych nie ma zwinności ani możliwości reagowania na zmieniające się wymagania swoich klientów. Dzieje się tak, ponieważ klienci często nie mają wyboru dostawców. Kluczową cechą organizacji szczupłej jest jej zdolność do ciągłego doskonalenia się poprzez ujawnianie problemów i rozwiązywanie ich, a następnie system maskuje problemy leżące u podstaw wielu organizacji, które utrzymują wysoki "poziom wody" i radzą sobie z problemami, kierując publicznie menedżerów często są pokusą dodania czegoś do systemu (np. instalacji kosztownych systemów IT), przy czym te pokusy mogą być awariami. Ogromne korzyści byłyby prawdopodobnie bardziej prawdopodobne nawet bez nowych systemów informatycznych, gdyby menedżerom rządowym udało się uporać z podstawowymi problemami. Udane transformacje lean muszą zamknąć lukę w zakresie zdolności na wczesnym etapie procesu, aby menedżerowie i pracownicy mogli przejść na nowy sposób pracy. Dzieje się tak, ponieważ lean wymaga czegoś więcej niż odwagi, aby odkryć głęboko zakorzenione problemy organizacyjne; może wymagać również umiejętności radzenia sobie z utratą pracy. Proces Alean wymaga systemu śledzenia wydajności, który dzieli cele najwyższego poziomu na jasne, mierzalne cele, które pracownicy na każdym poziomie muszą zrozumieć, zaakceptować i spełnić. Nadrzędnym celem szczupłego systemu jest konfiguracja zasobów, zasobów materiałowych i pracowników w sposób, który poprawia przepływ procesów z korzyścią dla klientów, jednocześnie minimalizując straty spowodowane marnotrawstwem, zmiennością i brakiem elastyczności. Aby stać się w pełni lean, organizacja musi rozumieć lean jako długoterminową filozofię, w której właściwe procesy przyniosą właściwe wyniki, a wartość można dodać do organizacji poprzez ciągły rozwój ludzi i partnerów, a jednocześnie rozwiązywanie problemów w celu napędzania organizacyjnego uczenia się. Chociaż nie ma dokładnej definicji w pełni szczupłej organizacji, ważne jest, aby organizacja zrozumiała i stosowała wszystkie praktyki i zasady. Poza tym szczupłe myślenie, które wpływa na cały model organizacji, jest kluczem, a nie tylko szczuplejszą produkcją, w której stosuje się tylko fragmenty całej filozofii lean. Jednak głównymi trudnościami, jakie napotyka organizacja, próbując zastosować lean, jest brak ukierunkowania, planowania i sekwencjonowania projektów, ponieważ od dziesięcioleci koncepcje lean były postrzegane jako sprzeczna z intuicją alternatywa dla proponowanego tradycyjnego modelu produkcji [28]. Pojęcie marnotrawstwa nie zostało jeszcze skutecznie rozszerzone na autodestrukcyjne zachowania jednostek i grup ludzi w miejscu pracy. Pullin podkreślał, że aby czerpać pełne korzyści, musimy postrzegać lean nie jako abstrakcyjną filozofię, ale taką, która obejmuje oba pojęcia - filozofię i praktyki, narzędzia lub procesy. Ponadto Toni i Tonchia argumentowali, że w szczupłej produkcji zarządzanie przez procesy jest metodą organizacyjną, mającą na celu jednoczesne wykonanie kilku wyników, w tym ich ciągłe doskonalenie, za pomocą przepływów operacyjnych struktury organizacyjnej zorientowanych na wyniki i elastyczność w zakresie zmian. Famholtz stwierdził, że zaangażowane są cztery kluczowe obszary, w których wszystkie organizacje muszą zarządzać swoją kulturą lub wartościami:
• traktowanie klientów
• traktowanie własnych ludzi lub kapitału ludzkiego organizacji
• standardy działania organizacji
• pojęcia odpowiedzialności.
Barnes stwierdził, że kluczowa zmiana dla organizacji w coraz bardziej konkurencyjnym środowisku operacyjnym dotyczy zwiększonego nacisku na koncepcje modernizacji i różnej konceptualizacji tego, co oznacza wartość dla firmy produkcyjnej. Ponadto Parker zapewniał, że wprowadzaniu szczupłej produkcji często towarzyszą modyfikacje oparte na lokalnych orientacjach. Ponadto szczupła organizacja może również różnić się pod względem implementacji. Gates i Cooksey stwierdzili, że konwencjonalne podejścia, które nadmiernie opierają się na jednopętlowym procesie uczenia się, który ignoruje dynamiczną złożoność kondycji ludzkiej i systemu organizacji, nie uwzględniają bardziej wymagającej, empirycznej strony uczenia się i rozwoju człowieka, która może być równie ważna. jako racjonalne podejście, które tak często oddaje program realizacji. Co ważne, zapotrzebowanie na nowe umiejętności nie jest już wyłącznie umiejętnościami technicznymi. Obecnie kładzie się silny nacisk na rozwój "miękkich" umiejętności, które są wymagane do zwiększenia pracy zespołowej z akceptacją zwiększonej odpowiedzialności oraz nowego nacisku na komunikację i przekazywanie wiedzy i pomysłów zarówno wewnątrz, jak i na zewnątrz organizacji. Emiliani zdefiniował powtarzające się błędy jako kolejny podstawowy rodzaj marnotrawstwa i argumentował, że firma, która nie jest w stanie nauczyć się i zmienić swojego zachowania, "bez wątpienia zaryzykuje przyszłą egzystencję całego przedsiębiorstwa, które jest obecnie zarządzane". W organizacji lean uczenie się trwa, ponieważ "lean to ciągłość, a nie stan ustalony"
Wniosek
Rozwój pomiaru wyników w stosunku do sektorów publicznych, który jest narzucony jako część wdrożenia lean, może napotkać opór. Dlatego poprawa wyników w szeregu czynników biznesowych, technicznych i ludzkich w sektorach publicznych zależy od najwyższych menedżerów, którzy prowadzą transformację lean poprzez bezpośrednią partycypację i konsekwentne stosowanie obu zasad: "ciągłe doskonalenie" i albo bezpośrednio, albo pośrednio " szacunek dla ludzi", gdzie menedżerowie bezpośrednio uczestniczą w kaizen i innych działaniach usprawniających procesy. Jeśli koncentrujemy się na doskonaleniu ludzi, prawdopodobnym rezultatem jest to, że ci ludzie będą posiadać odpowiedni zestaw umiejętności, aby kontynuować działania doskonalące w innych procesach, mimo że te zróżnicowane podejścia do efektywnych i behawioralnych aspektów Lean są w dużej mierze równie ważne jak jego wymiar poznawczy, gdy chodzi o jego wdrożenie, ponieważ wdrożenie Lean w sektorze publicznym nie jest szybkim rozwiązaniem, a samo Lean jest długoterminową filozofią, która napędza uczenie się organizacji w zakresie umiejętności rozwiązywania problemów.
Dominacja Lean w usługach Przemysł 4.0
Lean to system stosowany w przemyśle wytwórczym. Jest to systematyczna eliminacja marnotrawstwa oraz wdrażanie koncepcji ciągłego przepływu i ściągania klientów. Lean wywodzi się z Toyota Production System autorstwa Henry&pprime;ego Forda i został zastosowany w samochodach Forda. Lean to najlepszy system zarządzania zapewniający satysfakcję klientów w zakresie dostawy, jakości i ceny. W Bowen i Youngdahl sektor produkcyjny zazwyczaj przewodził sektorowi usług w opracowywaniu sposobów rozwiązywania kompromisów między niskimi kosztami, niezawodnością, jakością i elastycznością, które, jak się zakłada, istnieją we wczesnych badaniach nad strategią produkcji. Lean jest powszechnie stosowany przez firmy produkcyjne, ale obecnie ludzie zaczynają stosować odchudzoną branżę usługową.
Definicja
Chociaż w branży usługowej definicja lean w usługach jest nadal taka sama jak lean w produkcji, lean manufacturing jest strategią operacyjną ukierunkowaną na osiągnięcie jak najkrótszego czasu cyklu poprzez eliminację marnotrawstwa. W branży usługowej lean jest również strategią operacyjną, która ukierunkowana jest na osiągnięcie jak najkrótszego czasu cyklu serwisowego poprzez eliminację marnotrawstwa i zwiększenie zysku. W branży usługowej lean jest wykorzystywany do wspierania strategii rozwoju firmy: firmy świadczące usługi finansowe, aby przywrócić właściwy kierunek fuzji, firmy energetyczne, aby obniżyć koszty, firmy telekomunikacyjne, aby poprawić obsługę klienta, sprzedawcom detalicznym w celu zwiększenia wydajności przy jednoczesnej poprawie obsługi klienta w sklepie. To przykłady zalet zastosowania lean w branży usługowej. Guarraia stwierdził, że istnieją pewne kroki w stosowaniu lean w usługach. Kroki w stosowaniu lean w obsłudze to:
1. Mapowanie strumienia wartości przedsiębiorstwa (VSM). Początkowo opracowywana jest mapa procesów operacyjnych i kosztów z nimi związanych. Następnie przedsiębiorstwo jest skanowane, a jego podstawowe procesy są mapowane w celu zidentyfikowania największych możliwości obniżenia kosztów poprzez zmniejszenie straconego czasu i materiałów.
2. Analiza porównawcza. Wydajność procesów jest mierzona w oparciu o wewnętrzne i zewnętrzne wzorce w celu oceny niedociągnięć i ustalenia celów doskonalenia.
3. Ustalanie priorytetów. Zespół określa, które usprawnienia procesu przyniosą najlepsze rezultaty, gdy zastosuje się lean. Tradycyjny pięcioetapowy DMAIC - definiuje, mierz, analizuje, ulepszaj i kontroluj. (define, measure, analyze, improve, i control) Proces można rozpocząć na docelowym obszarze.
Transformacja w szczupłych usługach
Lean to podejście, które służy do zarządzania działalnością w celu zmniejszenia, maksymalizacji lub zminimalizowania strat, opóźnień, a głównym celem jest usprawnienie działań w celu zaspokojenia ludzkiego priorytetu. Dawno temu Lean został ustanowiony w sektorze motoryzacyjnym jako działanie Lean. Następnie, w połowie lat 90-tych, Lean rozpoczęła działalność jako Lean Manufacturing. Główny rozwój koncepcji Lean można zaobserwować w japońskim producencie samochodów Toyota. Bitner i in. stwierdził, że usługi stanowią obecnie większość pracodawców i źródło dochodu rozwiniętych gospodarek, stanowiąc około trzech czwartych produktu krajowego brutto w USA i Wielkiej Brytanii . Mimo że usługa stanowi większość pracodawców i źródeł, Dickson zasugerował, że poziom jakości usług w rzeczywistości spada, a lata pracy uległy znacznemu pogorszeniu. Wielu badaczy i praktyków powtórzyło swoje apele o przyjęcie lean w usługach Bowen i Youngdahl stwierdzili, że podejścia lean, takie jak przeprojektowanie pracy, przyrost szkolenia i mapowanie procesów w handlu detalicznym, liniach lotniczych i zarządzaniu szpitalami, mogą generować pozytywny, ale bardziej ogólny zestaw zasad zmian , z których wiele ma cechy wspólne z niektórymi aspektami szczupłego myślenia. Korzyści płynące z zastosowania lean w usługach mogą stać się potencjalnym priorytetem konkurencyjnym dla wszystkich organizacji. Poza tym w usługach lean transformacja koncentrowała się nie na obsłudze produktów komercyjnych, ale na obsłudze pacjentów, takich jak system opieki zdrowotnej. Jednym z celów badań jest skupienie się na elementach łańcucha zakupów lub dostaw do systemu opieki zdrowotnej, przy zastosowaniu szczupłego partnerstwa w dostawach i podejścia do redukcji zapasów w celu poprawy szybkości reakcji i kosztów. Według Womacka i Jonesa zidentyfikowano pięć zasad lean, które mają kierować organizacjami w sektorach gospodarki, które obejmują usługi w ramach transformacji lean, którymi są:
• Wartość jest określana przez to, co klient ceni (konkretnie, za co jest gotów zapłacić) w produkcie lub usłudze.
• Odwzorowanie stanu strumienia wartości (z mapą procesu lub strumienia wartości), w jaki sposób dostarczana jest wartość. Użyj tego jako podstawy do wyeliminowania wszystkiego, co nie dodaje wartości.
• Przepływ musi zapewniać płynny przepływ produktów i informacji od początku do końca strumienia wartości. Następnie usuń inwentaryzacje lub strefy buforowe za pomocą narzędzi strukturalnych, takich jak konstrukcja modułowa, obróbka komórkowa, maszyny ogólnego przeznaczenia i pracownicy o wielu kwalifikacjach.
• Dostarczaj tylko to, czego faktycznie żąda (wyciąga) klient, a nie dostarczaj z zapasów lub buforów.
• Nieustannie dąży się do perfekcji, aby usprawnić proces i system zgodnie z powyższymi zasadami, dążąc do perfekcji.
Osiem odpadów lean
Sarkar wspomniał, że wszystko, co nie dodaje wartości klientowi, jest marnotrawstwem. Określany przez Taichi Ohno, ojca Toyota Production System, jako osiem odpadów Lean Manufacturing, ma uniwersalne zastosowanie, w tym w branży usługowej. Tabela przedstawia rodzaj odpadów, ich znaczenie oraz przykłady dla branży usługowej. W tabeli wymieniono osiem rodzajów odpadów: nadprodukcja, wady, zapasy, nadmierne przetwarzanie, transport, oczekiwanie, zbędny ruch i niewykorzystana siła robocza.
Rodzaj odpadów : Znaczenie : Przykłady
Odpady z nadprodukcji : Przetwarzanie zbyt wczesne lub zbyt duże niż wymagane :
• Informacje wysyłane automatycznie, nawet jeśli nie są wymagane
• Drukowanie dokumentów, zanim będą potrzebne
• Przetwarzanie przedmiotów, zanim będą potrzebne kolejnej osobie w procesie
Marnotrawstwo wad: Błędy, pomyłki i poprawki:
• Odrzucenia w aplikacjach sourcingowych
• Nieprawidłowe wprowadzenie danych
• Nieprawidłowe imię i nazwisko wydrukowane na karcie kredytowej
• Błędy chirurgiczne
Odpady inwentarza : Inwentarz gospodarstwa (materiał i informacje) większy niż wymagany :
• Pliki i dokumenty oczekujące na przetworzenie
• Nadmiar materiałów promocyjnych wysłany na rynek
• Za dużo leków w szpitalu
• Więcej serwerów niż jest to wymagane
Strata nadmiernego przetwarzania Przetwarzanie większe niż wymagane, przy czym wystarczyłoby proste podejście
• Za dużo papierkowej roboty na kredyt hipoteczny
• Te same dane wymagane w liczbie miejsc w formularzu zgłoszeniowym
• Dalsze działania i koszty związane z koordynacją
• Za dużo zatwierdzeń
Marnotrawstwo transportu : Przemieszczanie przedmiotów przekraczające wymagania skutkujące stratami wysiłków i energii oraz zwiększeniem kosztów :
• Przenoszenie plików i dokumentów z jednej lokalizacji do drugiej
• Nadmiar załączników e-mail
• Wielokrotne przekazanie
Marnotrawstwo czekania: Czekający pracownicy i klienci;
• Klienci oczekujący na obsługę przez contact center
• Kolejki w sklepie spożywczym
• Pacjenci oczekujący na lekarza w przychodni
• Przestój systemu
Marnotrawstwo ruchu: Ruch ludzi, który nie dodaje wartości:
• Poszukiwanie danych i informacji
• Poszukuję narzędzi chirurgicznych
• Przemieszczanie się osób tam iz powrotem z segregatorów, faksów i kserokopiarek
Odpady niewykorzystanych ludzi: Pracownicy nie wykorzystujący własnego potencjału:
• Ograniczone uprawnienia i odpowiedzialność
• Wspólni menedżerowie
• Osoba podjęła niewłaściwą pracę
Narzędzia lean w branży usługowej
Narzędzia Lean to procesy i strategie, które służą do identyfikacji problemów w produkcji towarów lub usług oraz zwiększenia efektywności działania. Wiele narzędzi używanych do oceny sytuacji i pomagania w minimalizowaniu marnotrawstwa i utorowaniu drogi do większych zysków. Narzędzia lean, które są używane w branży usługowej, to Poka Yoke, 5S, Kanban i VSM. Pozytywny wpływ tych narzędzi zostanie przedstawiony i omówiony wraz z kilkoma przykładami udanych wdrożeń przez kilka firm.
Elementy krytyczne w lean service
Lean service to zastosowanie koncepcji lean manufacturing w operacjach serwisowych. Większość ludzi stosunkowo łatwo rozumie wartość zasad Lean, zwłaszcza gdy przedstawia się je z kilkoma dobrymi przykładami. Krytyczne czynniki, które zostały określone jako sukces wdrożenia koncepcji szczupłej produkcji w MŚP, to m.in. przywództwo, zarządzanie, finanse i umiejętności organizacyjne oraz wiedza specjalistyczna, wśród innych czynników, które są klasyfikowane jako czynniki najbardziej krytyczne dla udanej produkcji szczupłej w środowisku MŚP. W kolejnych podrozdziałach opisano istotne elementy, które zostały znalezione dla sukcesu w lean service.
Przywództwo i zarządzanie
Metody, rewolucje i progi, które trzeba przekroczyć, aby konkurować na globalnym rynku, nie mogą być realizowane oddolnie. Muszą zacząć od góry do dołu. Przywództwo będzie reprezentować sukces lub porażkę każdej firmy. Bill Selby, który w 1996 roku przeszedł na emeryturę jako wiceprezes Boeinga, był zaangażowany w tak wiele prac przygotowawczych do poprawy produktywności i doskonalenia pracowników. Bill Selby powiedział: "Umieszczam menedżerów w trzech kategoriach".
• Są ludzie, którzy naprawdę chcą się zmienić.
• Są tacy, którzy siedzą na płocie i czekają, aby zobaczyć, jak się sprawy mają.
• Są ludzie, którzy uważają, że zmiana jest zła i że powinniśmy pracować w tradycyjny sposób.
v
Liderzy muszą wierzyć, że stworzenie światowej klasy systemu produkcyjnego jest nie tylko ważne, ale i ważne, niepodlegające negocjacjom i że musi zacząć się już teraz, nawet jeśli jego osiągnięcie zajmuje wiele lat. Przywództwo jest uważane za ważną cechę sukcesu w szczupłej obsłudze.
Orientacja na klienta
Klienci są najważniejsi we wszystkim, co robisz. Klienci, podobnie jak pracownicy, wnoszą wkłady, które wpływają na produktywność organizacji zarówno poprzez ilość, jak i jakość tych nakładów oraz wynikającą z nich jakość generowanych wyników. Na przykład, wnosząc informacje i wysiłek w diagnozę swoich dolegliwości, pacjenci organizacji opieki zdrowotnej są częścią procesu produkcji usług. Jeśli dostarczą dokładnych informacji na czas, lekarze będą bardziej wydajni i dokładniejsi w stawianiu diagnoz. Tak więc jakość informacji dostarczanych przez pacjentów może ostatecznie wpłynąć na jakość wyniku. Co więcej, w większości przypadków, jeśli pacjenci zastosują się do zaleceń lekarza, będą mniej skłonni do powrotu na dalsze leczenie, co jeszcze bardziej zwiększy produktywność organizacji opieki zdrowotnej.
Wzmocnienie zatrudnienia
Zaangażowanie pracowników to podstawa. Bez niej nie da się zbudować szczupłego, światowej klasy systemu produkcyjnego. Bez pracownika nie osiągnie się sukcesu w żadnej dziedzinie firmy. Istnieją trzy kroki do sukcesu w usługach i produkcji:
1. Uzyskanie udziału i wsparcia najwyższego kierownictwa. Sukcesy naznaczone są aktywnym uczestnictwem w zarządzaniu, a porażki brakiem.
2. Ostrożność w badaniach i planowaniu.
3. Pełne zaangażowanie w szkolenia i zaangażowanie pracowników. Pracownicy muszą rozumieć cele i być ich częścią.
Jakość
Jakość często definiuje się jako spełnienie norm, specyfikacji lub tolerancji na akceptowalnym poziomie zgodności. Ten akceptowalny poziom jest różnie definiowany, np. zero defektów, Six Sigma i Lean Six Sigma, wadliwe części na milion. To zarządzanie jakością nie jest kontrolą jakości ani zapewnieniem jakości, ale w rzeczywistości jest to właściwe określenie, aby przekazać, że cel, jakim jest osiągnięcie i poprawa jakości, jest obszarem zainteresowania i odpowiedzialności kierownictwa. Istnieją trzy polityki szczupłego biznesu opracowane przez systemy zarządzania jakością:
1. Dążenie do jakości jest strategicznym celem firmy.
2. Najwyższe kierownictwo jest zaangażowane i aktywnie zaangażowane w osiąganie celów jakościowych.
3. Utrzymywany jest stały, zorganizowany w całej firmie wysiłek w celu ciągłej poprawy jakości procesu produkcyjnego, w tym szkolenia i pomiary.
Najbardziej podstawowa definicja produktu wysokiej jakości to taka, która spełnia oczekiwania klienta. Jednak nawet ta definicja jest zbyt wysoka, aby można ją było uznać za adekwatną. Aby opracować pełniejszą definicję jakości, należy wziąć pod uwagę niektóre kluczowe wymiary produktu lub usługi wysokiej jakości. Istnieje osiem kluczowych wymiarów produktu lub usługi wysokiej jakości: wydajność, cechy, niezawodność, zgodność, trwałość, łatwość serwisowania, estetyka i percepcja.
Wymiar 1, Wydajność (Czy produkt lub usługi robią to, co powinny, w ramach swoich określonych tolerancji?) Wydajność jest często źródłem niezgody między klientami a dostawcami, szczególnie gdy produkty nie są odpowiednio zdefiniowane w specyfikacjach. Wydajność produktu często wpływa na rentowność lub reputację użytkownika końcowego. W związku z tym wiele umów lub specyfikacji zawiera szkody związane z nieodpowiednim wykonaniem.
Wymiar 2, Funkcje (Czy produkt lub usługi posiadają wszystkie określone funkcje lub są wymagane do zamierzonego celu?) Chociaż ten wymiar może wydawać się oczywisty, specyfikacje wydajności rzadko określają funkcje wymagane w produkcie. Dlatego ważne jest, aby dostawcy projektujący produkt lub usługi na podstawie specyfikacji wydajności znali jego zamierzone zastosowania i utrzymywali bliskie relacje z użytkownikami końcowymi.
Wymiar 3, Niezawodność (Czy produkt będzie stale działał zgodnie ze specyfikacjami?) Niezawodność może być ściśle powiązana z wydajnością. Na przykład specyfikacja produktu może określać parametry czasu sprawności lub akceptowalne wskaźniki awaryjności. Niezawodność jest głównym czynnikiem wpływającym na wizerunek marki lub firmy i jest uważana przez większość użytkowników końcowych za podstawowy wymiar jakości
Wymiar 4, Zgodność (Czy produkt lub usługa są zgodne ze specyfikacją?) Jeśli zostały opracowane w oparciu o specyfikację wydajności, czy działają zgodnie ze specyfikacją? Jeśli jest opracowywany w oparciu o specyfikację projektową, czy posiada wszystkie zdefiniowane cechy?
Wymiar 5, Trwałość (Jak długo produkt będzie działał lub będzie działał iw jakich warunkach?) Trwałość jest ściśle związana z gwarancją. Wymagania dotyczące trwałości produktu są często zawarte w umowach o zamówienia i specyfikacjach. Na przykład samoloty myśliwskie są zamawiane do działania od lotniskowców, uwzględniając kryteria projektowe mające na celu poprawę ich trwałości w wymagającym środowisku morskim.
Wymiar 6, Serwisowalność (Czy produkt jest stosunkowo łatwy w utrzymaniu i naprawie?) Ponieważ użytkownicy końcowi są bardziej skoncentrowani na całkowitym koszcie posiadania niż na prostych kosztach zakupu, serwisowalność (jak również niezawodność) staje się coraz ważniejszym wymiarem jakości i kryteriów Wybór produktu.
Wymiar 7, Estetyka (Wygląd produktu jest ważny dla użytkowników końcowych). Estetyczne właściwości produktu przyczyniają się do tożsamości firmy lub marki. Wady lub wady produktu, które zmniejszają jego właściwości estetyczne, nawet te, które nie zmniejszają lub nie zmieniają innych wymiarów jakości, są często przyczyną odrzucenia.
Wymiar 8, Postrzeganie (Postrzeganie jest rzeczywistością.) Produkt lub usługa może posiadać odpowiednie lub nawet lepsze wymiary jakości, ale nadal paść ofiarą negatywnego postrzegania przez klientów lub opinię publiczną. Na przykład produkt wysokiej jakości może zyskać reputację niskiej jakości ze względu na słabą obsługę przez instalatorów lub techników terenowych. Jeśli produkt nie jest prawidłowo zainstalowany lub konserwowany i w rezultacie ulegnie awarii, awaria jest często związana z jakością produktu, a nie z jakością usług, które otrzymuje. Najbardziej podstawowa definicja produktu wysokiej jakości to taka, która spełnia oczekiwania klienta. Jednak nawet ta definicja jest zbyt wysoka, aby można ją było uznać za adekwatną. Aby opracować pełniejszą definicję jakości, należy wziąć pod uwagę niektóre kluczowe wymiary produktu lub usługi wysokiej jakości.
Wyzwania w szczupłych usługach
Jak wiemy, kiedy mówimy o zarządzaniu, zaangażowane są wszystkie systemy, które obejmują człowieka, operacje i inne. Głównym wyzwaniem dla Lean jest marnotrawstwo, ponieważ odpady to termin, od którego zaczyna się koncepcja Lean. Na przykład, robiąc coś lub organizując jakąś działalność w branży, zasadniczo ludzie nie będą postrzegać swojej pracy jako marnotrawstwa, chyba że mają dobre powody.Z tabeli widać, że wyzwania w branży usługowej wymagają dużego zestawu umiejętności, przywództwa i wsparcia, aby je pokonać. Wszystkie te wyzwania często pojawiają się, gdy wdrażane jest podejście szczupłe ponieważ ludzki błąd jest naturalną rzeczą, która się pojawia. Aby wdrożyć usługę lean, ludzie lub ludzkie emocje nie wzrastają, gdy nie rozumieją w pełni koncepcji lean, ale można z nimi obchodzić się z wielką ostrożnością. Wyzwaniom tym można jednak uniknąć, jeśli wiele umiejętności, przywództwa i wsparcia ze strony wszystkich organizacji w obszarze zostanie udoskonalone zgodnie z koncepcją zasad lean service in lean.
Zastosowanie Lean w usługach
Następnie pokazano i omówiono zastosowanie lean w branży usługowej, takiej jak hotelarstwo, szpital, budownictwo i biura.
Odchudzony hotel
Lean hotel to branża usługowa, w której na produktywność duży wpływ ma wydajność i dbałość o szczegóły osób pracujących ręcznie z narzędziami lub sprzętem operacyjnym (Mekong Capital). Zastosowania niektórych podstawowych zasad lean, które są powszechne w produkcji, często zawodzą w branży usługowej z powodu niepowodzeń organizacji usługowych, polegających na niezmienianiu ich sposobu myślenia. Zmiana myślenia, jak dowiedziała się Heidi, może skierować organizację w zupełnie innym kierunku w hotelu Marriot. Branża hotelarska składa się z firm z branży gastronomicznej, noclegowej, rekreacyjnej i rozrywkowej. Ta branża to branża warta kilka miliardów dolarów, która w większości zależy od dostępności czasu wolnego i dochodu rozporządzalnego. Wspólna jednostka w branży hotelarskiej, taka jak restauracja lub hotel, składa się z wielu grup, takich jak:
• Utrzymanie obiektu
• Operacje bezpośrednie
• Zarządzanie
• Marketing
• Zasoby ludzkie.
Wdrożenie i narzędzie
1,5S
W pomieszczeniu gospodarczym wzmianki o miejscach przechowywania są umieszczane na półkach, aby personel wykonujący przyjazną pracę. Rysunek 20.2 przedstawia pamięć masową przed i po wdrożeniu 5S. Oznaczają nie tylko "co" gdzie jest, ale także "ile", co jest kluczowym punktem dla półek i lokalizacji magazynowych 5S-ing .
2. Poka-yoke
W branży usługowej, takiej jak hotele, Poka-yoke służy do zapobiegania uszkodzeniom wyposażenia lub mebli w hotelach. Wiele pokoi hotelowych teraz ma telewizory LCD. Stare ciężkie telewizory lampowe prawdopodobnie nie będą wyciągane do przodu i zdejmowane z szafki lub stołu. Ale wyświetlacze LCD mogą być. W hotelu nie wywiesza się brzydkiego znaku z napisem "Uwaga: nie zdejmuj telewizora ze stołu!" Tak więc Poka-yoke nadaje się do zastąpienia tego znaku.
Odpady w hotelu?
Problemem są odpady. Istnieje wiele ogólnych kategorii odpadów. Na przykład siedem odpadów Taiichi Ohno, w tym nadprodukcja, oczekiwanie, transport, przetwarzanie, zapasy, przemieszczanie i wytwarzanie wadliwych produktów. W tabeli przedstawiono marnotrawstwo w hotelach.
Nr : Odpady : Wyjaśnienie
1. : Nadprodukcja: Nadprodukcja niepotrzebnie produkuje więcej niż jest to wymagane lub produkuje ją zbyt wcześnie, zanim będzie potrzebna. Nadmierna produkcja żywności w kawiarni lub restauracji w hotelu stanie się odpadem nadprodukcji. Zwiększa to koszty zarządzania hotelem.
2. : Oczekiwanie : Oczekiwanie to czas bezczynności dla gościa lub pracownika z powodu wąskich gardeł lub nieefektywnego przepływu zarządzania hotelem. Oczekiwanie obejmuje również niewielkie opóźnienia między przetwarzaniem jednostek. Oczekiwanie powoduje znaczne koszty, ponieważ zwiększa koszty pracy i koszty amortyzacji na jednostkę produkcji.
3. : Zapasy : Hotele mają tendencję do ponoszenia wielu wydatków na materiały. Ponieważ jest to hotel 5-gwiazdkowy, prawdopodobnie wydatki na materiały będą wyższe niż w przypadku hoteli 3-gwiazdkowych lub 4-gwiazdkowych, ponieważ zapewnią one klientom więcej udogodnień, co spowoduje większe zużycie materiałów i zasobów.
Istnieją trzy typowe źródła odpadów w hotelach: kuchnia, pokoje gościnne/pracownicze i ogród. Każde z tych źródeł ma swój własny skład odpadów. Na przykład odpady z ogrodu zawierają dużo liści i ścinków drzewnych, podczas gdy w odpadach kuchennych jest więcej odpadów warzywnych i owocowych.
Korzyści z szczupłego hotelu?
Zadowalający poziom klientów jest bardzo ważny w branży usługowej. Zastosowanie szczupłych systemów może wyeliminować znaczny poziom marnotrawstwa lub nieefektywności. W wyniku zastosowania lean do hotelu Marriot, w ciągu <1 roku wynik obsługi hotelu wzrósł o 10 punktów do 87 i przesunął się z dolnej połowy do górnych 10% w swoim odpowiedniku Grupya. Ten lepszy wynik nie tylko pozytywnie wpływa na gości hotelowych, ale także wpływa na wyniki finansowe hotelu poprzez powtarzające się pobyty klientów. Inne korzyści to:
1. Przebuduj każdy proces pracy z perspektywy klienta, aby zaoszczędzić koszty pracy i sfinansować poprawę obsługi klienta.
2. Wprowadzaj usprawnienia "odgórne" i eliminuj lub upraszczaj zadania, które są niewidoczne dla klientów.
3. Wzmocnienie standardowych podejść do benchmarkingu za pomocą rygorystycznych narzędzi do zarządzania wydajnością w celu porównywania wskaźników operacyjnych i finansowych oraz osiągnięcia poprawy wydajności.
Czystsze miejsce pracy poprzez bycie świadomym odpadów stało się rutynową częścią życia wielu ludzi, więc większość pracowników oczekuje, że ich miejsce pracy zapewni programy mające na celu ograniczenie, ponowne wykorzystanie i recykling odpadów. Mądrość odpadów stwarza pracownikom możliwość współpracy w celu zmniejszenia ilości odpadów dzięki praktycznym wskazówkom i czynnościom, które mogą z łatwością wykorzystać w codziennej pracy.
Lean w szpitalu
Obecnie opieka zdrowotna jest bardzo droga. Koszty rosną, a ludzie na całym świecie padają ofiarą błędów medycznych. Nie jest to naprawdę zachęcająca historia do poznania. Każdego dnia pracownicy szpitala, tacy jak pielęgniarki, lekarze i pielęgniarki, są często zirytowani tym samym problemem, z którym się borykają. Z tego powodu wielu z nich wraca do domu wyczerpanych lub kończy z tym zawodem. W szpitalu zdarza się wiele cudów, a gdy życie toczy się jeszcze, dzieje się coś wspaniałego. Jednak te rzeczy zaciera niekompetencja administratora szpitala z powodu pewnych problemów. Lean to zestaw narzędzi, system zarządzania i filozofia, która może zrewolucjonizować sposób organizacji i zarządzania szpitalami. Lean to metodologia, która pozwala szpitalowi poprawić jakość opieki nad pacjentem poprzez skrócenie czasu błędu i oczekiwania. Jego podejście może wspierać pracowników i lekarzy, eliminując przeszkody i pozwalając im skupić się na zapewnieniu opieki. Lean to system do długoterminowego wzmacniania organizacji szpitali poprzez redukcję kosztów i ryzyka, a także ułatwianie rozwoju i ekspansji. Pomaga również przełamać barierę między innymi oddziałami we współpracy z korzyścią dla pacjentów. Ktoś może zapytać, w jaki sposób technika lean może pomóc w rozwiązaniu codziennego, dokuczliwego problemu, który tak wiele komisji i zespołów próbowało już rozwiązać. Lean wyróżnia się tym, że metodologia pokazuje ludziom, jak patrzeć przez ludzi, którzy wykonują pracę, zamiast polegać na ekspertach, którzy dokładnie im powiedzą, co mają robić. Pomaga także liderom dostrzec i zrozumieć, że to nie jednostki są zepsute, ale sam system. Takie podejście wymaga również ciągłego uczenia się: ciągłego doskonalenia (Kaizen) i rozwoju zawodowego pracowników, dla ich dobra i samej organizacji.
Narzędzia i wdrożenie
Visual Management (VM), 5S, Kanban (Signboard), Kaizen (Wall of Fame), VSM i Heijunka Box to narzędzia, które pomagają zmniejszyć marnotrawstwo.
Odpady w szpitalu
Obecnie szpitale borykają się również z poważnym niedoborem kluczowych wykwalifikowanych pracowników, w tym pielęgniarek, farmaceutów i technologii medycznych. Odchudzona poprawa dzięki standaryzacji pracy, rozmieszczeniu i poprawie przepływu oraz 5S zmniejszają marnotrawstwo i czas bez wartości dodanej, zmniejszając zapotrzebowanie na pracę lub pozwalając opiekunom spędzać więcej czasu z pacjentami. Typowe szczupłe rodzaje odpadów są spotykane w szpitalach. Odpady te są takie same jak w innych sektorach, jednak w ramach własnego działu. Idee nie są takie same, chociaż znaczenia są takie same. Tabela 20.6 przedstawia siedem typowych odpadów Lean w szpitalach.
Korzyści z lean hospital
Lean przynosi korzyści pacjentom (poprzez skrócenie czasu oczekiwania), pielęgniarkom, a nawet lekarzowi, gdzie nie tylko ratują życie, ale poprawiają życie (świadomość siebie). Szpital i jakość opieki zdrowotnej ulegają poprawie, gdzie pacjenci będą mieli pewność, że poświęcą swoje życie i być może można je uratować. Lekarze również odniosą korzyści dzięki zwiększonej produktywności, która przekłada się na wyższe wynagrodzenie poprzez zmniejszenie lub wyeliminowanie potrzeby wielomilionowej ekspansji. Lean hospital to coś więcej niż tylko wdrażanie metod narzędziowych i technicznych. Lean obejmuje również zmianę kulturową i system zarządzania, transformację, która wymaga czasu, wysiłku i wytrwałości.
Odchudzona konstrukcja
Lean construction to podejście do realizacji projektów oparte na zarządzaniu produkcją. To także nowy sposób projektowania i budowy obiektów kapitałowych. Kiedy percepcja szczupłej produkcji została po raz pierwszy zaadaptowana z przemysłu wytwórczego, problemem było wyabstrahowanie podstawowych zasad szczupłej produkcji, a następnie dopasowanie ich do branży budowlanej. Wyzwaniem było zatem, jak przyjąć zasady szczupłej konstrukcji i wprowadzić je w życie. Potrzebny był nowy system realizacji projektów, który obejmuje wszystkie podstawowe zasady szczupłego budownictwa. Nie miał to jednak być schematyczny system dostarczania, ponieważ szczupła konstrukcja nie ma standardowego zestawu narzędzi. Lean Project Delivery System (LPDS) to taki, który jest zorganizowany, kontrolowany i ulepszony w celu maksymalizacji wartości dla właścicieli i niezawodności przepływu pracy na placach budowy. Rysunek 20.6 przedstawia przykładowy obraz budowy szopy. LPDS to koncepcyjne ramy opracowane przez Ballarda i Zabelle, aby kierować wdrażaniem szczupłej konstrukcji w systemach produkcyjnych opartych na projektach [17], tj. strukturach, które budują. Rysunek 20.7 opisuje LPDS. LPDS został opracowany jako zestaw współzależnych funkcji (poziom systemu), zasady podejmowania decyzji, procedury wykonywania funkcji oraz pomoce i narzędzia wdrożeniowe, w tym oprogramowanie, w stosownych przypadkach. Zarządzanie szczupłą produkcją spowodowało rewolucję w projektowaniu produkcji, dostawach i montażu. Lean, zastosowany w budownictwie, zmienia sposób wykonywania pracy w całym procesie dostawy. Lean construction wychodzi od celów szczupłego systemu produkcyjnego - maksymalizacji wartości i minimalizacji strat do określonych technik i zastosowania ich w nowym procesie realizacji projektu. Rysunek 20.7 przedstawia schemat LPDS.
Na rysunku objaśnienie schematu jest pokazane w następujący sposób:
• Faza definiowania projektu składa się z modułów: określenie potrzeb i wartości, kryteria projektowe oraz projekt koncepcyjny.
• Projekt szczupły składa się z projektu koncepcyjnego, projektu procesu i projektu produktu.
• Odchudzona dostawa obejmuje projektowanie produktu, szczegółową inżynierię oraz produkcję/logistykę.
• Lean montaż obejmuje produkcję/logistykę, instalację na miejscu oraz testowanie/obrót.
• Kontrola produkcji składa się z kontroli przepływu pracy oraz kontroli jednostki produkcyjnej.
• Strukturyzacja pracy i ocena po zajęciu to jak dotąd tylkomoduły.
Czym jest odchudzona konstrukcja? Prosta, nie uproszczona definicja jest taka, że odchudzona konstrukcja to "sposób projektowania systemów produkcyjnych w celu zminimalizowania strat materiałów, czasu i wysiłku w celu wygenerowania maksymalnej możliwej wartości". Inna definicja mówi, że lean construction to holistyczna filozofia projektowania i dostarczania obiektów, której nadrzędnym celem jest maksymalizacja wartości dla wszystkich interesariuszy poprzez systematyczne, synergiczne i ciągłe doskonalenie ustaleń umownych, projektu produktu, projektu procesu budowy i doboru metod, łańcucha dostaw i niezawodność przepływu pracy w miejscu pracy.
Realizacja
W ciągu ostatnich 10 lat lean został przyjęty przez branżę budowlaną z konsekwentnie rosnącym entuzjazmem i skutecznością. Na początku w branży istniał wysoki poziom oporu z często słyszanym komentarzem: "może to działać w przypadku produkcji, ale konstrukcja jest inna". Tego typu stwierdzenia okazały się zarówno prawdziwe, jak i fałszywe. Prawdą jest, że trzeba było opracować nieco inne podejście lean dla środowiska budowlanego opartego na projektach. Fałszywe jest to, że gdy ramy i metody systemów planowania szczupłego (patrz ostatni planista) i logistyki szczupłej zostaną ukończone, zastosowanie wszystkich innych zasad i metod szczupłych jest skutecznie wykorzystywane do uzyskania dramatycznych wyników, które były powszechne w produkcji dla wielu lat. Dodatkowo, podejście lean construction zapewnia efektywne zarządzanie biznesem firmom budowlanym, które często cierpią na przypadkowe i niezdyscyplinowane metody zarządzania (lean construction delivery system). Budownictwo to prawdopodobnie ostatnia granica dla lean. Chociaż wydajność produkcji poprawiła się w ciągu ostatnich 40 lat, branża budowlana doświadczył niewielkiego spadku. Mimo że świat budownictwa przyjął zaawansowane technologicznie narzędzia, nadal zarządzamy projektami w taaki sam sposób, jak zawsze i nadal osiągamy te same słabe wyniki. Mniej niż 30% projektów przychodzi na czas, w ramach budżetu i specyfikacji. Odpowiedzi w zakresie poprawy wydajności konstrukcji nie można znaleźć w większej ilości oprogramowania lub technologii. Odpady są wszędzie w budownictwie i to od setek lat. To nie jest stwierdzenie winy, ale po prostu fakt. To tak bardzo styl życia, że większość kierowników budowy przeocza ten fakt. Przyjmują marnotrawstwo jako nieuniknione i nie do uniknięcia i dodają je do kosztów pracy. W ten sposób klient za to płaci. Wdrażanie szczupłego budownictwa niesie ze sobą korzyści nie tylko wykonawców, ale także architekta i właściciela, którzy na tej praktyce wiele zyskają. Jednak niektóre firmy budowlane nie postrzegają odpadów jako niezbędnej części działalności.
Narzędzia
Narzędzia i ich implementację wymieniono i opisano w tabeli.
Nr : Narzędzia : Opis/wykonanie
1: 5S: Proces 5S (czasami określany jako wizualne miejsce pracy) dotyczy "miejsca na wszystko i wszystko na swoim miejscu". Ma pięć poziomów sprzątania, które mogą pomóc w wyeliminowaniu marnotrawnych zasobów. Masaaki Imai powiedział: "Jeśli ktoś nie robi 5S, to nie robi Lean". W budownictwie z dużym powodzeniem zastosowano w sklepie 5S (tradycyjnie tłumaczone jako "sortuj", "uporządkuj", "połysk", "standaryzuj" i "podtrzymuj").
2: Kanban: W budownictwie zastosowano podstawowe podejście Kanban, zarówno w terenie, jak i w sklepie, aby zasygnalizować potrzebę uzupełnienia materiałów eksploatacyjnych. Na przykład, gdy jeden pojemnik na śruby lub wkręty jest pusty, zastępuje go drugi pojemnik. Pusty kosz staje się sygnałem do jego uzupełnienia poprzez umieszczenie go w wyznaczonym miejscu. W dolnej części pojemnika znajduje się karta, która zawiera typ śruby, numer części, ilość do zamówienia oraz dane kontaktowe dostawcy.
3: Kaizen: "Jakość budynku w Veridian Homes" w wydaniu Quality Progress z października 2006 r. Denisa Leonarda szczegółowo opisuje wydarzenia Kaizen (tj. ograniczanie ilości odpadów), które zostały z powodzeniem wykorzystane w budownictwie. Veridian Homes, z siedzibą w Madison w stanie Wisconsin, wykorzystuje wydarzenia, które nazywa Kaizen redline, do przeglądu wszystkich swoich planów domowych. Pomaga to Veridianowi w opracowywaniu planów, które są bardziej konstruktywne. Firma ma 50 różnych planów, a zaangażowanie ludzi, którzy projektują i budują te modele, doprowadziło do znacznych ulepszeń. Podczas tych wydarzeń Kaizen redline zespół analizuje każdą część projektu, szukając sposobów na uproszczenie, ograniczenie duplikowania wysiłków i standaryzację prac instalacyjnych. Wydarzenie składa się z dwóch części. Najpierw zespół przedstawicieli z działu projektowania, budowy i obsługi klienta dokonuje przeglądu konkretnego planu. Obejmuje to kluczowych podwykonawców. Następnie zespół przedstawia swoje wnioski i wątpliwości dotyczące tego planu wszystkim osobom zajmującym się projektowaniem, budową, zarządzaniem i obsługą klienta na 90-minutowym comiesięcznym spotkaniu.
4: VSM: Niektóre firmy budowlane używają VSM do poprawy sposobu dostarczania projektu i projektu, na podstawie Petera Dumonta, PE, z Lean Engineering, w prezentacji przedstawionej na warsztatach Lean Project Delivery w dniu 11 kwietnia 2007 r. Boldt Co., wykonawca usług budowlanych z siedzibą w Appleton w stanie Wisconsin, wykorzystał VSM do skrócenia zobowiązań z 87 do 67 dni. Tracer Industries Canada Ltd. z siedzibą w Edmonton, Alberta, specjalizuje się w dostarczaniu systemów zarządzania "pod klucz" dla projektów przemysłowych i komercyjnych. Firma zastosowała VSM i skróciła całkowity czas projektowania inżynieryjnego z 20 do 1,2 dnia. Bezpośrednie koszty pracy przypadające na jeden rysunek spadły i wygenerowały roczny wzrost zarobków o 1,3 miliona USD przed odliczeniem odsetek i podatków.
Narzędzia Lean są bardzo przydatne w usprawnianiu zarządzania budową, zwłaszcza narzędzia takie jak VSM, Kaizen i praca standaryzowana. Poza tym narzędzia lean, takie jak Six Sigma i Kanban, umożliwiają zrównoważony rozwój w branży budowlanej .
Odpady w budownictwie
Odpady (znane również jako śmieci, śmieci, śmieci, śmieci i śmieci) to niechciany lub bezużyteczny materiał. Ściółka to odpad, który został niewłaściwie usunięty w organizmach żywych; odpady to niechciane substancje lub toksyny, które są z nich wydalane. Odpady są bezpośrednio związane z rozwojem człowieka, zarówno pod względem technologicznym, jak i społecznym. W tabeli 20.8 przedstawiono osiem rodzajów odpadów łatwo występujących w budownictwie.
Nr: Rodzaj odpadu: Opis
1: Wady: Każdy w budownictwie rozumie ten rodzaj odpadów. Obejmuje to niewłaściwe wykonanie instalacji, wady produkcyjne i błędy w listach stempli. Niespełnienie wymaganego kodu jest marnotrawstwem. Przeróbki w budownictwie są rzadko mierzone.
2 : Nadprodukcja : To marnotrawstwo ma miejsce, gdy produkujemy materiał zbyt wcześnie lub gromadzimy materiał w magazynie lub na miejscu pracy. Szacowanie i licytowanie miejsc pracy, które nie zostały zdobyte, jest formą tego marnotrawstwa. Drukowanie większej liczby planów lub wykonywanie większej liczby kopii raportu niż potrzeba to nadprodukcja.
3: Transport: Odpady te powstają, gdy przemieszczamy materiał po warsztacie, ładujemy go na ciężarówkę lub przyczepę, przewozimy na miejsce pracy, rozładowujemy i przenosimy materiał z miejsca układania lub postoju do miejsca instalacji.
4: Oczekiwanie: Budowa jest pełna tych odpadów, w tym, gdy załoga czeka na instrukcje lub materiały w miejscu pracy, gdy maszyna czeka na załadunek materiału, a nawet wtedy, gdy lista płac czeka na spóźnione arkusze.
5: Nadmierne przetwarzanie : To marnotrawstwo obejmuje nadmierne prace inżynieryjne, wymagające dodatkowych podpisów na zamówieniu, wielokrotną obsługę kart czasu pracy, duplikowanie wpisów na formularzach oraz uzyskiwanie podwójnego i potrójnego szacunku od dostawców.
6 : Ruch : Te "poszukiwania skarbów" mają miejsce, gdy materiał jest przechowywany z dala od miejsca pracy lub gdy pracownicy szukają narzędzi, materiałów lub informacji. Odpady te występują również w przyczepie biurowej lub na placu budowy, gdy szukamy plików, raportów, informatorów, rysunków, umów, lub katalogi dostawców.
7 : Zapasy : Obejmuje materiały niecięte, produkcję w toku i gotowe wyroby. Niektórzy podwykonawcy twierdzą, że nie mają zapasów, ponieważ kosztują cały materiał. Chociaż może to działać w przypadku księgowości, jeśli materiał nie został jeszcze zainstalowany i nie jest używany przez klienta, jest on uważany za odpad. Odpady te obejmują części zamienne, nieużywane narzędzia, materiały eksploatacyjne, formularze i kopie, skrytki pracowników i osobiste zapasy. Można argumentować, że niedokończony obiekt jest uważany za inwentarz i jest traktowany jako odpad do momentu uruchomienia.
8 : Człowiek : Ten rodzaj marnotrawstwa pojawi się, gdy liczba osób, które wykonują pracę, jest większa niż wymagana dla danej pracy.
Korzyści z odchudzonej konstrukcji
Niezawodne zwalnianie pracy pomiędzy specjalistami w zakresie projektowania, dostaw i montażu zapewnia, że wartość jest dostarczana klientom, a ilość odpadów jest redukowana. Lean construction jest szczególnie przydatne w przypadku złożonych, niepewnych i szybkich projektów. Podważa przekonanie, że zawsze musi istnieć wymiana między czasem, kosztami i jakością. Istnieje kilka zalet lub korzyści z zastosowania koncepcji lean w budownictwie:
• Placówka i proces jej dostawy są projektowane razem, aby lepiej ujawniać i wspierać cele klientów. Pozytywna iteracja w procesie jest wspierana, a negatywna iteracja jest redukowana.
• Praca jest ustrukturyzowana w całym procesie, aby zmaksymalizować wartość i zredukować marnotrawstwo na poziomie realizacji projektu.
• Wysiłki zmierzające do zarządzania i poprawy wydajności mają na celu poprawę ogólnej wydajności projektu, ponieważ jest to ważniejsze niż zmniejszenie kosztów lub zwiększenie szybkości jakiejkolwiek czynności.
• "Kontrola" została przedefiniowana z "monitorowania wyników" na "czynienie rzeczy". Wydajność systemów planowania i kontroli jest mierzona i poprawiana.
Lean office
Filozofie, narzędzia i metodologie związane z odchudzoną produkcją są dobrze udokumentowane i są z powodzeniem stosowane w wielu branżach i branżach. Jest to proces, który skupia się na wyeliminowaniu wszystkiego, co nie jest korzystne dla klientów - wszelkiego rodzaju marnotrawstwa i wszelkich elementów, które uniemożliwiają przepływ. Ten proces dotyczy równie dobrze biura. W biurze nacisk kładziony jest na skrócenie czasu cyklu dla wszystkich procesów, szczególnie tych między złożeniem zamówienia a otrzymaniem płatności. Celem jest optymalizacja przepływu informacji i poprawa zdolności firmy do gromadzenia, przenoszenia i przechowywania informacji przy wykorzystaniu absolutnie minimalnych zasobów niezbędnych do spełnienia oczekiwań klientów.
Narzędzia
W tabeli przedstawiono opis siedmiu narzędzi, które można wykorzystać w szczupłym biurze.
Narzędzie: Opis
5S
• Ogólne sprzątanie obszarów biurowych może usunąć bałagan i zwiększyć wydajność.
• Może również wiązać się ze zmianami w układzie biura.
• Celem jest stworzenie określonych miejsc na formularze, dokumenty i sprzęt, aby można je było znaleźć w ciągu 30 sekund.
Kontrola wizualna
• Kodowanie kolorami, tablice stanu i inne narzędzia komunikacyjne.
• Zawiera wszelkie elementy wizualne, które pomogłyby pracownikom zrozumieć lepiej, gdzie rzeczy idą za pierwszym razem.
Redukcja/eliminacja partii
• Przenoszenie mniejszych ilości pracy przez system zwiększy wydajność, skróci czas realizacji i poprawi jakość.
• Tailored Label Products Inc., producent niestandardowych etykiet i wycinanych klejów z Menomonee Falls, odkrywa wąskie gardło na biurku swojego planisty, który otrzymał pracę od czterech lub pięciu przedstawicieli obsługi klienta, którzy grupują swoje prace.
• Eliminacja grupowania wyrównuje obciążenie pracą.
Praca standaryzowana
? Możliwości standaryzacji pracy są często liczne. Formularze a listy kontrolne mogą być zmieniane tak, aby gromadziły wszystkie potrzebne informacje.
? Dopasowana etykieta aktualizuje formularz, który przekazuje informacje o zamówieniu do zakładu tak, aby informacje były uporządkowane według zadań, dzięki czemu pracownicy mogą łatwo znaleźć to, czego potrzebują w jednym miejscu.
? Standaryzacja procesów może być również konieczna, ponieważ różne osoby wykonują tę samą pracę, co powoduje, że ludzie wykonują zadania własnymi metodami.
? Ryzyko to różnica w wynikach. Pracownicy, którzy opracowali standardową procedurę, często dochodzi do konsensusu, że odzwierciedla najlepsze praktyki dla wszystkich, dzięki czemu proces jest równomierny lepiej.
Niwelacja
• Ilość pracy w biurze nie jest stała. Lean office zapewnia proaktywne środki, aby reagować na ruchliwe okresy.
• Na przykład, jeśli zaległość w pracy osiągnie pewien punkt, można poprosić o pomoc osobę mętną.
• Poziomowanie można również wykorzystać do zrównoważenia zadań o wysokim i niskim priorytecie.
• Działania, które ograniczają strumień wartości, można wykonywać w wyznaczonych terminach, aby zapewnić, że wszystkie zadania przykują ich uwagę.
Pociągnij/Kanban
• Korzystając z funkcji ściągania, zadania zstępujące przeciągają się z zadań nadrzędnych, aby wyrównać pojemność i zapotrzebowanie.
• Na przykład w centrum obsługi klienta może wystąpić sytuacja, w której liczba zawieszonych połączeń sygnalizuje, że więcej osób odbiera połączenia.
• Gdy liczba połączeń spadnie poniżej tego punktu, osoby te wracają do innych zadań.
• Kanban to wizualny sygnał wskazujący, kiedy coś jest potrzebne, na przykład karty umieszczone na stojakach na literaturę, aby wskazać, kiedy potrzeba więcej kopii.
Układ biura/komórki robocze/zespoły
• Czasami układ biura wymaga ponownego przemyślenia, nie tylko pod względem lokalizacji drukarek i kopiarek, ale pod względem struktury organizacyjnej.
• Większość biur obsługi klienta jest zorganizowana według funkcji, z działami zakupów, obsługi klienta i inżynierii. To nie jest optymalne, gdy koncentrujesz się na strumieniu wartości.
• Wielofunkcyjne zespoły zorganizowane w komórki robocze mogą znacznie zwiększyć wydajność, ponieważ zespół rozumie cały proces i nie jest skoncentrowany na pojedynczym zadaniu.
Marnotrawstwo
Istnieje osiem typowych odpadów biurowych, jak pokazano w tabeli. W pewnym stopniu przypominają odpady produkcyjne. Te odpady obejmują wady, nadprodukcję, oczekiwanie, przetwarzanie bez wartości dodanej, zmienność, nadmierne zapasy, dodatkowy ruch/transport i niewykorzystanych pracowników.
Rodzaj odpadu : Opis : Przykłady
Wady: awaria lub wada, która może uniemożliwić dotkniętej rzeczy działać prawidłowo:
• Błędy wprowadzania danych
• Błędy cen
• Utracone pliki lub zapisy
• Nieprawidłowe informacje w raporcie lub dokumencie
Nadprodukcja: Produkcja czegoś ponad to, co jest wymagane:
• Drukowanie dokumentów zanim będą potrzebne
• Błędy cen
• Utrata plików lub rekordów
• Zapisywanie prawidłowych informacji w raporcie lub dokumencie
Oczekiwanie : czas spędzony na oczekiwaniu na coś co zdarzyło się lub jest gotowe na coś, co się wydarzy :
• Przestój systemu
• Oczekiwanie na zatwierdzenia
• (Opóźnienia) w otrzymywaniu informacji
• Czekam na zapasy
• Czekam na instrukcje
Przetwarzanie bez wartości dodanej: wysiłek, który nie dodaje wartości do produktu lub usługi z punktu widzenia klienta:
• Ponowne wprowadzanie danych
• Dodatkowe kopie
• Niepotrzebne zgłoszenia
• Nadmierne recenzje
Zmienność: Wiele metod lub narzędzi do wykonywania tej samej czynności:
• Wiele formularzy dla tych samych informacji
• Ta sama czynność wykonywana jest na kilka różnych sposobów
• Czas na wykonanie czynności jest trudny do przewidzenia
Nadmierny zapas : Zapasy, które organizacja posiada pod ręką, wykraczające poza to, co uważa się za konieczne:
• Materiały biurowe
• Literatura sprzedażowa
• Raporty
• Papier firmowy
v
Dodatkowy ruch/transport : Przemieszczanie osób, informacji lub dokumentów, które nie dodają wartości do produktu lub usługi:
• Nadmiar załączników e-mail
• Faks lub kopiarka za daleko
• Wiele przeniesień
• Nieskuteczne zgłoszenie
• Zły układ biura
Niewykorzystani pracownicy: umiejętności ludzi, a nie ich czas, nieskutecznie lub niewłaściwie wykorzystani
• Ograniczone uprawnienia pracowników i odpowiedzialność za podstawowe zadania
• Dowództwo i kontrola zarządzania
• Nieodpowiednie/niedostępność narzędzi biznesowych
Korzyści z lean office
• Lean office przynosi rezultaty
• Skróć czas realizacji
• Zwiększ responsywność klientów
• Popraw terminowość dostaw
• Zrób więcej, korzystając z dostępnych ludzi i sprzętu
• Popraw komunikację, zwiększ morale i produktywność
• Popraw przepływ informacji.
Lean w obsłudze kontra lean w produkcji
Istnieje duże zainteresowanie stosowaniem zasad lean w służbie. Powszechnie uważa się, że te same zasady Lean, które zmieniły produkcję, mogą zrobić to samo dla usług. Tabela 20.11 pokazuje różnicę między lean w usługach a produkcją. Różnice w stosunku do sytuacji produkcyjnej to zapasy pomiędzy poszczególnymi etapami produkcji oraz zapasy wyrobów gotowych, które mogą być zwiększane lub zmniejszane w zależności od wahań popytu. Na przykład trzy etapy są zaangażowane w proces produkcyjny. W pierwszym etapie proces produkcyjny rozpoczyna się od surowca. Półprodukty, które trafiają do zapasów, kończą etap 1. Półprodukty i produkty gotowe mogą znajdować się w zapasach przez znaczną ilość czasu (w większości operacji jednym z aspektów lean jest minimalizacja zapasów). Wystąpiłoby znaczne opóźnienie między czasem produkcji produktu a czasem jego zużycia. W działalności usługowej nie ma opóźnień jak w działalności produkcyjnej. Rzeczywiście, istnieje prawie współtworzenie produktu między producentami a klientem.
Lean w obsłudze: Lean w produkcji
Jednoczesna produkcja i konsumpcja (współtworzenie między producentem a konsumentem): Konsumpcja i produkcja znajdują się na różnych etapach
Wiele krytycznych aspektów jest niematerialnych: Wiele krytycznych aspektów jest namacalnych
Koncepcja inwentarza może nie być materialna, ale może być wirtualna, np. w przypadku wniosków, a w opiece zdrowotnej pacjenci oczekujący na usługę można uznać za rodzaj inwentarza: Może mieć inwentarz i bufory
Znaczna zmienność w świadczeniu usług: niektóre odmiany
Otwarty wszechświat w różnych przypadkach usług: Zamknięty zestaw w różnych produktach w produkcji
Korzyści merytoryczne i peryferyjne : Głównie korzyści merytoryczne produktu
Produkcja odchudzona
Zasada Lean Manufacturing służy do określenia, w jaki sposób można wykorzystać zasadę Lean Transformation. Ta zasada może prowadzić do tworzenia wytycznych dla lean w usługach jako transformacja w lean services. Zasada ta podzielona jest na pięć kategorii. Po pierwsze, zasadnicza wartość precyzyjnie określa wartość produktu lub rodziny. Zasada ta skupia się na każdej analizie lub ulepszeniu tylko produktu lub usługi, które klient procesu określiłby jako wynik danego procesu. Mierzona jest tym, ile klient jest skłonny zapłacić. Druga zasada określa strumień wartości lub strumień wartości dla każdego produktu lub usługi. Tą zasadą jest identyfikowanie sekwencji zadań, które dają wynik, za który klient jest gotów zapłacić. Zasady te nie pokazują kolejności danych. W przeciwnym razie klient generalnie nie jest zainteresowany płaceniem za dane, które wspierają proces. Interesuje ich tylko niepotrzebna obecność, redukcja kosztów, poprawa jakości czy szybkość dostawy. Stosując tę drugą zasadę, wartość dodaną można zidentyfikować w strumieniu procesu, przyjmując rolę klienta. Ta zmiana o wartości dodanej jest zmianą procesu lub zadania, którą klient postrzega jako zmianę, która sprawia, że proces lub proces wyjściowy jest dla niego bardziej wartościowy. Może to być zmiana, o którą prosi klient, która jest wymagana prawnie, lub taka, która jest proponowana przez właściciela procesu, personel lub personel zarządzający. Trzecią zasadą jest przepływ, który można opisać jako przepływ wartości bez żadnych przerw. Ma to na celu zapewnienie nieprzerwanego ruchu produktu przez kolejne etapy procesu i pomiędzy procesami. Ma to na celu zapewnienie, że wszystkie procesy są płynne i przejrzyste dla każdego produktu i każdej zaangażowanej usługi. Czwarta zasada to ściąganie, czyli ściąganie wartości klienta od właściciela procesu. Ta zasada jest sygnałem do zainicjowania procesu, który musi pochodzić z dalszego procesu, a ostatecznie od klienta lub usług. Zgodnie z projektem Lean Performance, członkowie zespołu często opracowują ulepszenia, pracując wstecz lub przeciągając cały proces. Ma to na celu identyfikację wymagań klienta w strumieniu procesu. Ostatnią zasadą jest perfekcja. Celem tej zasady jest utrzymanie i ciągłe doskonalenie elementu czterech poprzednich zasad, a te elementy nazywane są zadaniami procesowymi. Kiedy te pięć zasad zostanie wdrożonych w usługach lean, transformacja może zostać zrealizowana przy użyciu narzędzi lean, takich jak Kanban i Poka Yoke.
Podsumowanie
Jesteśmy w stanie zidentyfikować, a nawet rozróżnić, w jaki sposób lean jest wdrażany w branży usługowej. Co więcej, mamy wgląd w to, w jaki sposób narzędzia lean są korzystne dla branży usługowej. Niemniej jednak, szersza perspektywa jest zaangażowana w to, jak lean może zostać wdrożony i wykorzystany w różnych branżach, takich jak usługi.
Studium przypadku: system zabezpieczający przed kradzieżą paneli słonecznych oparty na integracji systemu śledzenia GPS i rozpoznawania twarzy z wykorzystaniem głębokiego uczenia
System bezpieczeństwa jest ważny dla ochrony obiektów, w tym modułów paneli słonecznych. W niniejszym opracowaniu jako system bezpieczeństwa panelu słonecznego zaproponowano zintegrowany system, który łączy przetwarzanie obrazu i śledzenie obiektów. Rozpoznawanie twarzy za pomocą głębokiego uczenia służy do wykrywania nieznanej twarzy. Następnie skradziony obiekt można śledzić za pomocą Globalnego Systemu Pozycjonowania (GPS), który działa przy użyciu General Packet Radio Service i Global System for Mobile Communication System. Wyniki pokazują, że zintegrowany system bezpieczeństwa jest w stanie znaleźć podejrzanego i śledzić skradziony przedmiot. Korzystając z połączenia FaceNet i sieci głębokich przekonań, nieznaną twarz można rozpoznać z dokładnością 94,4% i 87,5% odpowiednio dla testów offline i online. Tymczasem system śledzenia GPS jest w stanie śledzić współrzędne skradzionego obiektu z błędem 2,5 m, a średni czas wysyłania to 4,64 s. Na czas wysyłania i odbierania danych ma wpływ siła sygnału. Proponowana metoda działa dobrze w czasie rzeczywistym i można je monitorować za pośrednictwem strony internetowej zarówno pod kątem zarejestrowanych nieznanych twarzy, jak i lokalizacji danych współrzędnych.
Wstęp
Elektrownia słoneczna jest jedną z alternatywnych źródeł energii, która jest wykorzystywana w wielu zastosowaniach w naszym codziennym życiu. Niemniej jednak cena panelu słonecznego jest stosunkowo wysoka i dlatego może zostać skradziony. W związku z tym potrzebny jest system bezpieczeństwa dla systemu paneli słonecznych. Większość systemów bezpieczeństwa brała pod uwagę tylko jeden aspekt, taki jak podejrzany lub położenie skradzionego przedmiotu. Jedną z metod wykrycia podejrzanego złodzieja jest zastosowanie przetwarzania obrazu. Rozpoznawanie twarzy jest często stosowane w systemach bezpieczeństwa ze względu na jego wysoką dokładność w porównaniu z innymi danymi biometrycznymi. W ten sposób system nadzoru może być rozwijany z wykorzystaniem systemu bezpieczeństwa opartego na rozpoznawaniu twarzy. Nurhopipah i Harjoko opracowali system monitorowania z wykorzystaniem telewizji przemysłowej (CCTV), który może wykrywać ruch i twarz, a następnie rozpoznawać twarz. W innym badaniu przeprowadzonym przez Wati i Abadianto opracowano system bezpieczeństwa domu oparty na rozpoznawaniu twarzy. Jednak ten system nie mógł działać w czasie rzeczywistym, zwłaszcza w przypadku nieznanej twarzy, która może być podejrzaną osobą. Ponadto system nie posiadał żadnej centralnej pamięci do zapisywania wykrytej twarzy. Innym aspektem systemu bezpieczeństwa jest śledzenie pozycji skradzionego przedmiotu. Przeprowadzono wiele badań dotyczących śledzenia pozycji za pomocą globalnego systemu pozycjonowania (GPS). Moduł GPS i Globalny System Komunikacji Mobilnej (GSM) zostały wykorzystane do śledzenia skradzionego przedmiotu na podstawie badania Liu i Salima oraz Idrees, którzy zaproponowali system bezpieczeństwa oparty na GPS i General Packet Radio Service (GPRS). Singh opracował system śledzenia obiektów przy użyciu GPS z mediami komunikacyjnymi GPRS i SMS-ami, a Shinde i Mane wykorzystali GPRS i GPS do śledzenia lokalizacji obiektu za pośrednictwem strony internetowej lub smartfona. Nie posiadał jednak zapasowego systemu łączności w przypadku braku sygnału GPRS. Z drugiej strony, żadna centralna pamięć nie może pozwolić użytkownikom na ręczne zapisywanie danych wejściowych otrzymanych z GPS. Bazując na wspomnianym wcześniej problemie, ważne jest stworzenie jednego systemu do zabezpieczenia obiektu. Dlatego w badaniu zaproponowano zintegrowany system, który łączy rozpoznawanie twarzy w celu odnalezienia podejrzanego, który ukradł moduł panelu słonecznego, oraz system śledzenia w celu znalezienia aktualnej pozycji skradzionego obiektu.
Metoda
W niniejszym opracowaniu proponowana metoda została zaprojektowana jako połączenie rozpoznawania twarzy i systemu śledzenia. CCTV lub kamera internetowa jest przymocowana blisko panelu słonecznego. Gdy nieznana osoba zbliży się do panelu słonecznego, jej obraz zostanie przechwycony przez CCTV lub kamerę internetową, a obraz ten zostanie rozpoznany za pomocą głębokiego uczenia. Jeśli osoba jest nierozpoznana, obraz zostanie wysłany i zapisany w internetowej bazie danych, która może być wykorzystana do śledzenia tożsamości złodzieja. W międzyczasie pozycja skradzionego panelu słonecznego będzie śledzona za pomocą GPS.
Rozpoznawanie twarzy za pomocą głębokiego uczenia
Twarz nieznanej osoby będzie kluczem w proponowanym systemie bezpieczeństwa w odnalezieniu osoby podejrzanej. Pierwszym etapem jest inicjalizacja, po której następuje detekcja twarzy. Tutaj system wykrywa twarz za pomocą algorytmu Viola Jones. Następnym etapem jest wykrywanie twarzy, które jest wykorzystywane niezależnie od wykrycia twarzy. Jeśli twarz zostanie wykryta, system może przejść do następnego etapu, aby rozpoznać twarz. W tym procesie cecha twarzy jest wyodrębniana za pomocą algorytmu osadzania Facenet, a proces rozpoznawania odbywa się za pomocą głębokiej sieci przekonań (DBN). Rozpoznana twarz zostanie określona na podstawie wartości ufności powyżej 80%. Wartość ufności poniżej 80% jest określana jako nieznana osoba, która zostanie przechwycona i wysłana do bazy danych. Dane wykorzystane w tych badaniach pochodzą z różnych warunków, a mianowicie jasnych i ciemnych. Ponadto przedmiot nie może zakrywać twarzy. Dane wykorzystywane w procesie szkolenia to dwie osoby, zwane dalej operatorem. Te dane szkoleniowe są uzyskiwane z wideo CCTV. Następnie do testowania systemu wykorzystuje się osiem nowych twarzy. W celu uzyskania modelu wykorzystano 4000 obrazów operatorów, gdzie 3000 obrazów do treningu i 1000 obrazów do testowania danych. FaceNet służy do wyodrębniania cech twarzy w celu uzyskania 128 punktów domeny, co nazywa się osadzaniem twarzy. Te pliki osadzania są używane jako dane wejściowe dla DBN. Otrzymany model jest następnie testowany w dwóch warunkach, tj. offline i online. W teście offline system jest testowany pod kątem rozpoznanych i nierozpoznanych . twarze pochodzące z obrazów i filmów. Dziewięć nierozpoznanych twarzy jest używanych do testowania systemu zarówno w jasnych, jak i ciemnych. W teście online system może rozpoznawać twarze w czasie rzeczywistym, a nieznane twarze są wysyłane do bazy danych zarówno jako jasne, jak i ciemne. Pierwszym etapem jest zmiana rozmiaru obrazu do 96 x 96, aby był zgodny z danymi wejściowymi na potrzeby procesu osadzania dla FaceNet. Architektura FaceNet zastosowana w tym opracowaniu to model inception_blocks_v2 w konstrukcji. Zamiast stosowania sztucznej sieci neuronowej (ANN) do etapu klasyfikacji, w niniejszym badaniu wykorzystano generatywny model DBN, który składa się z ograniczonych maszyn Boltzmanna (RBM) [10]. DBN nie ma żadnego połączenia w warstwie intra.
Śledzenie GPS
Rozpoznawanie twarzy może być pomocne w schwytaniu podejrzanego, który ukradł panel słoneczny. W międzyczasie skradziony przedmiot mógł zostać przeniesiony w inne miejsce. Dlatego system bezpieczeństwa integruje system rozpoznawania twarzy ze śledzeniem GPS w celu śledzenia pozycji skradzionego przedmiotu. W tym badaniu proponowane śledzenie GPS wykorzystuje kombinację GPRS i GSM jako system komunikacji do wysyłania lokalizacji skradzionego panelu słonecznego odpowiednio z sieci internetowej i SMS-ów. Ten system bezpieczeństwa działa równolegle z systemem rozpoznawania twarzy. System określi położenie współrzędnych panelu słonecznego za pomocą czujnika GPS, który ma służyć jako odbiornik z satelity GPS do odbioru i przetwarzania danych w celu uzyskania dokładnych współrzędnych. Po uzyskaniu lokalizacji dane o współrzędnych są przesyłane do bazy danych za pomocą GPRS lub GSM za pośrednictwem SMS-a. Lokalizacja i ruch pozycji skradzionego panelu słonecznego będą śledzone w czasie rzeczywistym i pokazywane na stronie internetowej. Ten system bezpieczeństwa ma również stronę internetową i aplikację na Androida jako interfejs do śledzenia pozycji i lokalizacji modułu panelu słonecznego. Podczas wysyłania lokalizacji danych Internet może zostać przerwany i będzie to zależeć od siły sygnału. Dlatego ten proponowany system śledzenia służy również do odczytywania wiadomości SMS wysyłanych do smartfona.
Wyniki i dyskusja
Proponowany system bezpieczeństwa łączy w sobie dwa systemy: rozpoznawanie twarzy w celu uchwycenia podejrzanego oraz śledzenie GPS w celu śledzenia lokalizacji podejrzanego i skradzionego panelu słonecznego. W eksperymencie zbadane zostaną oba systemy.
Model głębokiego uczenia dla systemu rozpoznawania twarzy
Dane wykorzystane do treningu obejmują dwie osoby w dwóch warunkach w ciągu dnia i nocy, jak pokazano na rysunku
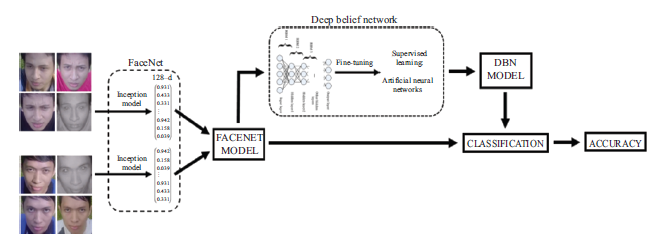
. Łączne dane do treningu i testowania to 4000 obrazów. Po uzyskaniu cechy twarzy za pośrednictwem FaceNet przy użyciu struktury przedstawionej w Tabeli
,

cechy te są używane jako dane wejściowe do DBN. Strukturę parametrów DBN przedstawiono w tabeli
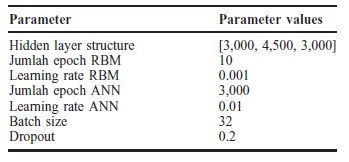
Ponieważ DBN jest kombinacją RBM, takie RBM rekonstruują dane wejściowe i minimalizują błąd rekonstrukcji. Dane wyjściowe pierwszej ukrytej warstwy będą danymi wejściowymi dla widocznej warstwy w drugiej RBM i tak dalej. Wykres błędu rekonstrukcji dla RBM można zobaczyć na rysunku
.
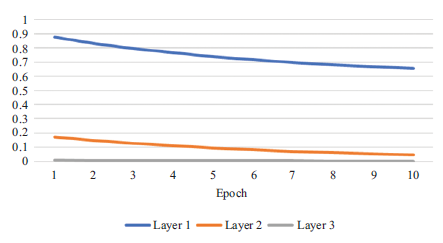
Jak pokazano na rysunku, błąd rekonstrukcji jest mały dla ostatniego RBM. Może to wskazywać, że RBM utworzył model, który może wykryć wzorzec danych. Proces ten odbywa się w sposób nienadzorowany. Kolejny etap procesu treningowego realizowany jest w sposób nadzorowany, analogiczny do SSN , a jego stratę treningową widać na rysunku

Ta strata treningowa zmniejsza się znacząco w 356. epoce, co może wskazywać, że proces treningowy wymaga stosunkowo długiego czasu obliczeniowego. Model ten jest jednak odporny na wykrywanie danych testowych, które nie są uwzględniane w procesie uczenia pochodzącym od operatora.
Test offline
Test offline dzieli się na twarz znaną (operator) i twarz nieznaną (podejrzany). Aby wykryć nieznaną twarz, system musi reprezentować prawdopodobieństwo ufności w oparciu o model FaceNet i DBN, które zostały przeszkolone wcześniej. Tutaj prawdopodobieństwo ufności poniżej 90% może sugerować nieznaną twarz. Wybrano wyższe prawdopodobieństwo ufności, ponieważ cel tego rozpoznawania twarzy jest wykonywany jako system bezpieczeństwa. Dla znanej twarzy system ma dokładność 96,4%. Może rozpoznać 964 obrazy operatorów z 1000 obrazów, które nie są uwzględnione w procesie szkolenia. Wynik ten pokazuje, że system jest wystarczająco dobry, aby rozpoznać znaną twarz. Później system jest testowany przy użyciu nieznanych obrazów, które są zupełnie nowymi danymi. Te obrazy pochodzą od dziewięciu różnych osób, zarówno w przypadku obrazu, jak i wideo. Wyniki badań z wykorzystaniem obrazu można zobaczyć w tabeli
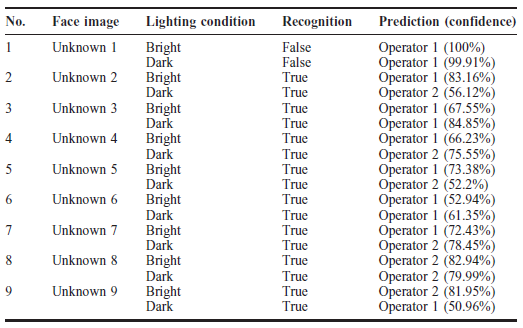
Jak pokazano w tabeli , proponowany system jest w stanie rozpoznać nieznaną twarz dla każdej osoby. Błąd nadal występuje w pierwszym nieznanym obrazie rozpoznanym jako operator. Może być kilka czynników, które ją powodują, takie jak natężenie światła i cecha nieznanej twarzy mogą mieć podobne cechy, jak twarze operatorów wykorzystywane w treningu. Następnie w filmie przeprowadzono również test na nieznane twarze. Filmy dla dziewięciu nieznanych twarzy zostały nagrane za pomocą telewizji przemysłowej i kamery internetowej, aby zobaczyć działanie modelu głębokiego uczenia się w dwóch różnych kamerach. Wyniki można zobaczyć w tabeli .
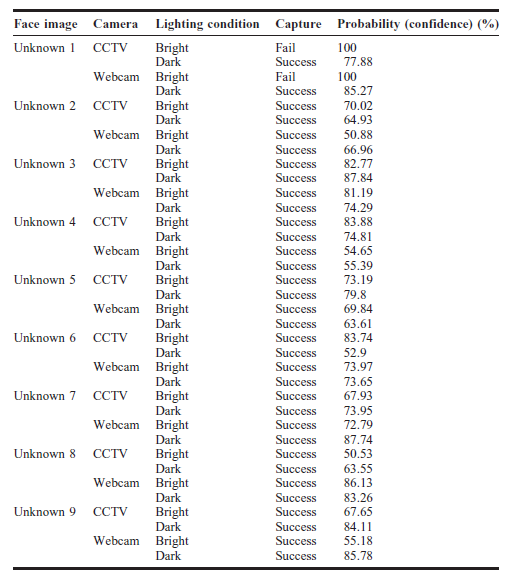
Z tabeli , system może działać dobrze w przypadku ruchomych obrazów (wideo) przy użyciu telewizji przemysłowej i kamery internetowej. Dokładność rozpoznawania nieznanej twarzy dla wideo wynosi 94,44%. Jednak w nocy, gdy oświetlenie jest ograniczone, CCTV zapewnia lepszą dokładność niż ebcam, ponieważ ma podczerwień, która jest pomocna w uchwyceniu twarzy w porównaniu z kamerą internetową
Test online
Ponieważ proponowany system bezpieczeństwa będzie działał w czasie rzeczywistym, należy przeprowadzić test online. Jak pokazano na rysunku , twarz sfotografowana za pomocą telewizji przemysłowej daje lepsze wyniki niż kamera internetowa. Jednak marka CCTB użyta w eksperymencie ma trudności z połączeniem się z Pythonem używanym w systemie rozpoznawania twarzy. Dlatego podczas testu online kamera internetowa jest wykorzystywana do przechwytywania obrazu w formacie wideo. W teście online, wykorzystującym system rozpoznawania twarzy, który został wcześniej przeszkolony przez głębokie uczenie, nieznana wykryta twarz zostanie przechwycona i wysłana na stronę internetową. Tutaj strona internetowa pełni rolę bazy danych prezentującej nieznane twarze przechwycone przez system. System może wykryć nieznaną twarz i przesłać ją do bazy danych. Może to być pomocne dla operatorów w monitorowaniu panelu słonecznego, zwłaszcza w przypadku kradzieży panelu słonecznego. Ten system bezpieczeństwa oparty na rozpoznawaniu twarzy sprawdza się dobrze w dzień, gdy światło jest jasne. Niemniej jednak w nocy system ma trudności z wykryciem i rozpoznaniem twarzy, ponieważ obraz twarzy nie jest wyraźny. Ogólnie rzecz biorąc, proponowany system jest w stanie rozpoznać nieznaną twarz z dokładnością 87,5% dla stanu w czasie rzeczywistym.
Test śledzenia GPS
Jako zintegrowany system bezpieczeństwa, system śledzenia GPS może działać, gdy skradziony panel słoneczny przesunie się z pierwotnej pozycji. Rozpoznawanie twarzy może być pomocne operatorowi w odnalezieniu podejrzanego, który ukradł panel słoneczny. Jednak panel słoneczny, który został skradziony, musi być śledzony, aby można było znaleźć jego pozycję. W pierwszym eksperymencie badającym dokładność systemu GPS panel słoneczny jest umieszczony w pozycji początkowej, a współrzędne dla tej pozycji początkowej można zobaczyć w tabeli 21.6. Jak pokazano w tabeli 21.6, czujnik współrzędnych GPS ma dobrą dokładność, ponieważ różnica między współrzędnymi ze smartfona uzyskanymi z Google Maps wynosi 0,00004 i 0,00003 odpowiednio dla szerokości i długości geograficznej. Następnie skrzynka z modułem paneli słonecznych jest przenoszona w różne miejsca oddalone o 1, 10, 50, 100, 150, 200 m od początkowej lokalizacji. Jak pokazano w tabeli, pierwsze dane mają współrzędne 3,21523° i 104.64860° odpowiednio dla szerokości i długości geograficznej, gdy czujnik GPS zostanie przesunięty o 1 metr. Stąd możemy znaleźć odległość od dwóch współrzędnych korzystając z równania Haversine′a w następujący sposób.
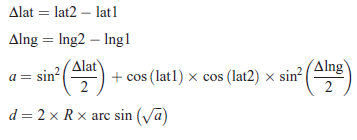
gdzie d to odległość w metrach, R to promień ziemi na równiku, który wynosi 6 378 137 m, a Dlat, Dlng, lat1, lat2, lng1 i lng2 podane są w radianach. Różnica między rzeczywistymi danymi a czujnikiem GPS i smartfonem jest wystarczająco duża dla pierwszych trzech danych. Ta różnica staje się mniejsza dla danych od czwartego do szóstego. Różnica wynosi około 2,53 m, co jest zgodne ze specyfikacją czujnika w tych badaniach z błędem około 2,5 m
Śledzenie GPS: system komunikacji
Proponowany system śledzenia musi mieć dobry system komunikacji. Dlatego ważny jest sukces przesyłania danych i czas podczas przesyłania danych. W niniejszym opracowaniu GPRS zostanie wykorzystany jako system danych komunikacyjnych dla sieci Internet, a GSM jako system zapasowy dla SMS-ów. Początkową pozycję pokazuje czerwony punktor na rysunku
Ten rysunek przedstawia ruchomą linię skrzynki z panelami słonecznymi. Celem jest uzyskanie danych o współrzędnych i czasu na przesłanie danych od pozycji początkowej do aktualnej. Wyniki komunikacji systemu za pomocą GPRS po 16-krotnym przesunięciu obiektu można zobaczyć w tabeli
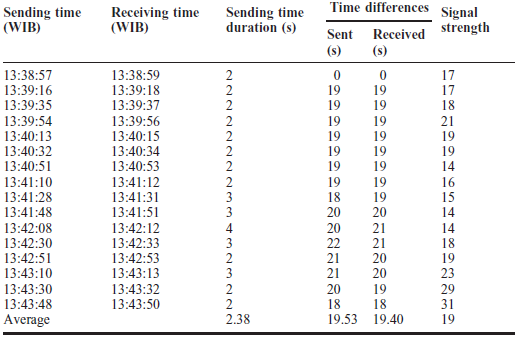
Jak pokazano w tabeli, czas potrzebny na wysłanie i odebranie danych o współrzędnych wynosi około 2-4 s ze średnią 2,38 s. A czas przesłania poruszającego się obiektu z jednego miejsca do drugiego to około 17-22 s. Tymczasem serwer może odebrać dane w około 18-21 s. Średni czas wysyłania i odbierania wynosi odpowiednio 19,53 i 19,40 s. Tabela 21.8 pokazuje również siłę sygnału z jednostką wskaźnika siły odbieranego sygnału (RSSI), gdzie im wyższa, tym lepsza siła sygnału. Ponadto w ramach tego badania przeprowadzono również eksperyment dla różnych prędkości, podczas gdy obiekt przemieszcza się z jednej do drugiej pozycji. Prędkość waha się od 20 do 60 km/h, jak pokazano w tabelach
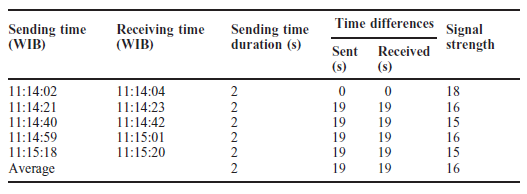
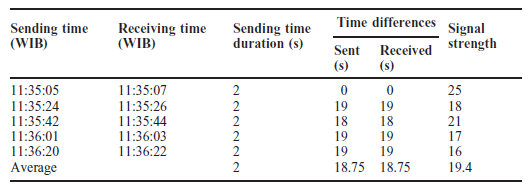
Z drugiej tabeli widać, że czas przesyłania danych jest taki sam jak w tabeli pierwszej, czyli 2 sekundy. Opóźnienie wysyłania i odbierania danych wynosi odpowiednio 19 i 18,75 s. Oznacza to, że prędkość poruszającego się obiektu może nie wpływać na przesyłanie i odbieranie danych przez GPRS. Korzystając z GPRS, system śledzenia potrzebuje 2,38 s na odebranie danych o współrzędnych i 19,4 s na ich odbiór. Ten proces wysyłania i odbierania danych może zależeć od siły sygnału. Ponieważ dane komunikacyjne wykorzystują również GSM, w niniejszym opracowaniu przeprowadza się również testowanie wysyłania i odbierania danych o współrzędnych. Wyniki można zobaczyć w tabeli
.
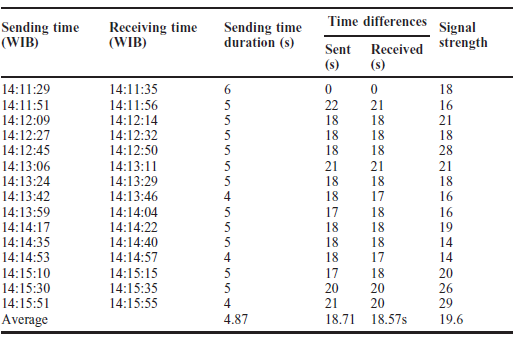
Tabela pokazuje, że czas przesyłania danych przez GSM jest dłuższy niż przez GPRS. Średni czas to 4,87 s, czyli dwa razy więcej niż w GPRS. Może się tak zdarzyć, ponieważ GSM ma dwa etapy wysyłania danych. Najpierw system wysyła dane współrzędne SMS-em na smartfona, a następnie aplikacja w smartfonie odczytuje SMS-a i przesyła współrzędne do bazy danych za pomocą połączenia internetowego. Rysunek
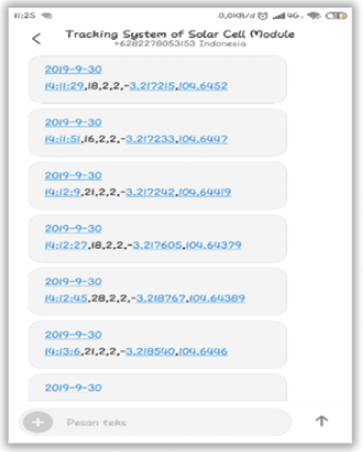
przedstawia SMS wysłany na smartfon. Jak pokazano na rysunku , w tej wiadomości SMS są wysyłane pewne informacje. Informacje o sekwencjach są następujące: czas wysłania, siła sygnału, status, rodzaj komunikacji, szerokość i długość geograficzna. Jak widać w Tabeli powyżej , GSM potrzebuje 18,71 i 18,57 s opóźnienia odpowiednio do wysyłania i odbierania danych o współrzędnych. Może to oznaczać, że na opóźnienie czasowe wysyłania i odbierania może nie mieć wpływu rodzaj danych komunikacyjnych i prędkość poruszającego się obiektu. Może mieć na to wpływ odpowiedź zwrotna udzielona przez SIM808. Z powyższych tabel wynika ,że opóźnienie czasowe wysyłania każdego z danych jest prawie równe około 19 s. W związku z tym komunikacja za pomocą GSM może być wykorzystywana jako system zapasowy, gdy siła sygnału jest niska lub Internet jest niedostępny.
Śledzenie GPS: test systemu w czasie rzeczywistym
Celem śledzenia GPS w systemie bezpieczeństwa panelu słonecznego jest śledzenie pozycji skradzionego pudełka z panelem słonecznym w czasie rzeczywistym. Początkowe współrzędne dla tego testu w czasie rzeczywistym przedstawiono w tabeli.
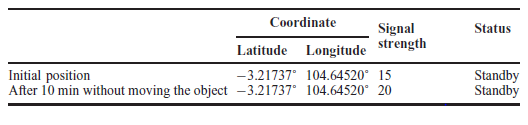
Po zapisaniu pozycji początkowej w bazie danych system automatycznie przejdzie w stan gotowości, jak pokazano na rysunku
Obiekt nie zostanie przesunięty przez 10 minut, aby odróżnić, czy pozycja się porusza, czy nie. Tabela pokazuje, że dane współrzędnych nie zmieniają się przez 10 minut, gdy obiekt się nie porusza. Dzięki temu system jest w stanie rozróżnić tryb czuwania. Później obiekt zostanie przeniesiony do nowej pozycji, jak pokazano na rysunku , a dane współrzędnych można zobaczyć w tabeli .
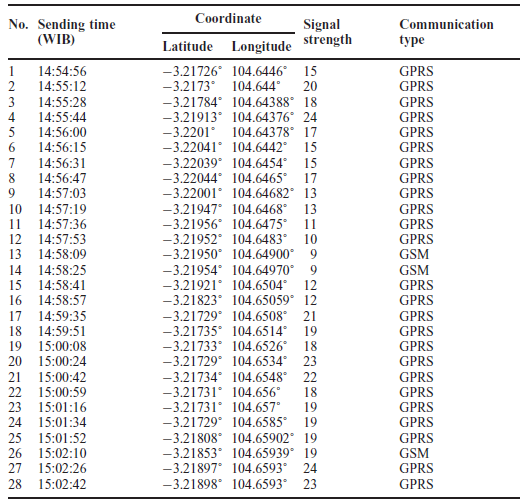
Jak pokazano na rysunku , lokalizacja pinów w kolorze niebieskim reprezentuje początkową pozycję modułu panelu słonecznego, a kolor czerwony reprezentuje jego ostateczną lokalizację. Z tego rysunku widać, że proponowany system może rozpoznać położenie panelu słonecznego od stanu gotowości do ruchu. Rysunek pokazuje również, że system śledzenia jest w stanie narysować pas, który mija skrzynka z panelem słonecznym. W tabeli dane o 28 współrzędnych reprezentują różne systemy komunikacji. Jest w trybie GSM trzy razy (dane 13, 14 i 26). System automatycznie przejdzie do GSM, gdy system nie będzie mógł przesłać danych przez Internet lub wystąpi błąd lub zakłócenie przesyłania danych, co może spowodować awarię. W danych 13 i 14 siła sygnału wynosi 9, co jest uważane za niskie, a zatem system bezpośrednio korzysta z GSM. Tymczasem w 26 danych siła sygnału wynosi 19, co jest wystarczająco dobre, ale może wystąpić awaria lub błąd podczas wysyłania danych. Rysunek przedstawia wizualizację danych współrzędnych
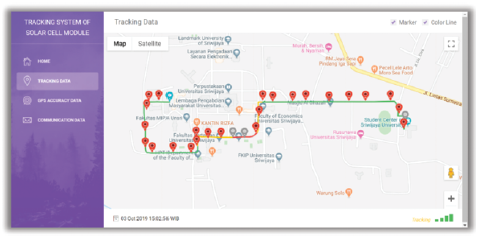
Kolory czerwony i szary reprezentują przesyłanie danych odpowiednio przez GPRS i GSM. Szczegóły dotyczące czasu wysłania można zobaczyć w tabeli.
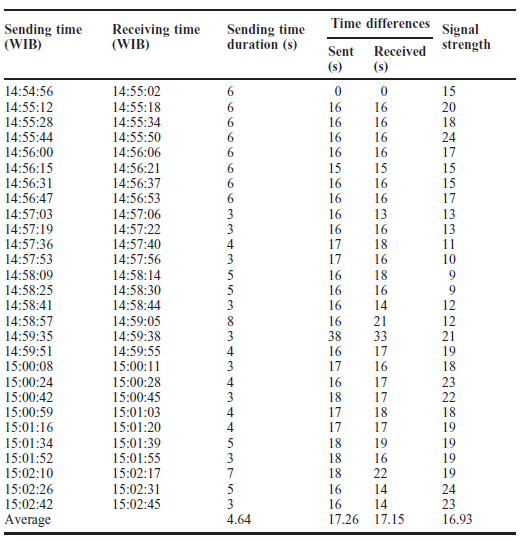
Z tabeli średni czas wysyłania wynosi 4,64 s. Na ten czas może wpływać siła sygnału. W tym eksperymencie siła sygnału wynosi 16,93, więc system potrzebuje mniej czasu na przesłanie danych o współrzędnych. Wreszcie, eksperyment jest również wykonywany dla stanu, w którym system nie może połączyć się z satelitą lub gdy nie ma połączenia GPRS lub GSM. Rysunek przedstawia interfejs, gdy system nie może być połączony z serwerem.
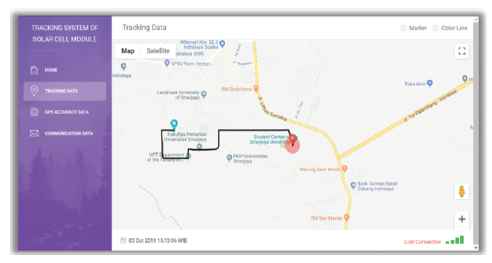
Jak pokazano na rysunku , interfejs jest zupełnie inny niż na rysunku wcześniejszym. System statusu zmienił się na utracone połączenie, a wokół czerwonego pinu znajduje się kółko. Promień reprezentowany przez ten warunek jest ustawiony na 100 m. Może to wskazywać na ostatnią lokalizację skrzynki z panelem słonecznym. Ten stan może wystąpić po 10 minutach, gdy system nie może wysłać danych do serwera. Z wyników i wcześniejszych dyskusji wynika, że system rozpoznawania twarzy i system śledzenia współpracują ze sobą jako zintegrowany system bezpieczeństwa. System bezpieczeństwa jest w stanie uchwycić nieznaną twarz, która może być szkodliwa dla modułu panelu słonecznego. Rozpoznawanie twarzy opracowane przy użyciu głębokiego uczenia potrafi odróżnić znane i nieznane twarze. Z drugiej strony system śledzenia, którego celem jest śledzenie pozycji skradzionej skrzynki z panelem słonecznym, działa dobrze z wykorzystaniem technologii GPS opartej na GPRS i GSM. System śledzenia może rozpoznać pozycję modułu panelu słonecznego, niezależnie od tego, czy pozostaje nieruchomy, czy przenosi się w nowe miejsce. Zarówno rozpoznawanie twarzy, jak i system śledzenia można monitorować za pomocą interfejsu opartego na stronie internetowej. W ten sposób ten system bezpieczeństwa może być stosowany w warunkach czasu rzeczywistego. Ponadto system śledzenia jest w stanie zarządzać statusem utraconego połączenia, podając informacje o ostatniej lokalizacji w promieniu 100 m po 10 minutach, gdy system nie może wysłać nowych danych o współrzędnych.
Wniosek
W ramach tego badania zaproponowano zintegrowany system systemu bezpieczeństwa do wyszukiwania i śledzenia skradzionego towaru. Pierwszym poziomem systemu bezpieczeństwa jest system rozpoznawania twarzy, który może rozpoznać nieznaną twarz za pomocą FaceNet jako ekstrakcji cech i DBN dla klasyfikatora. System ten jest zintegrowany z bazą danych. Z eksperymentu przeprowadzonego w trybie offline i online system jest w stanie rozpoznać nieznaną twarz z dokładnością 94,4% w trybie offline i 87,5% w trybie online lub w czasie rzeczywistym. Nieznana twarz rozpoznana przez system zostaje przechwycona i przesłana do bazy danych może być pomocna w odnalezieniu podejrzanego, który ukradł przedmiot. Tymczasem pozycja skradzionego przedmiotu musi być śledzona. To śledzenie jest wykonywane na drugim poziomie systemu bezpieczeństwa po kradzieży obiektu. System śledzenia wykorzystuje GPS zintegrowany z bazą danych za pomocą GPRS i GSM jako system komunikacji. Błąd czujnika GPS wynosi około 2,5m przy czasie wysyłania 4,64s. System może również dobrze śledzić położenie współrzędnych za pomocą zarówno GPRS, jak i GSM, na co wpływa siła sygnału. Proponowany system bezpieczeństwa może być przydatny dla systemu bezpieczeństwa, ponieważ łączy technologię rozpoznawania twarzy i śledzenia GPS.
Projekt Ważka
Projekt Dragonfly to rozwiązanie typu "dwa w jednym" do monitorowania toksyczności ścieków przemysłowych i powietrza, które jest przyjazne dla środowiska, nieinwazyjne i opłacalne. Nazwa sugeruje biomimikrę, w której dron w projekcie potrafi latać, zmieniać wysokość, poruszać się do przodu i do tyłu z relatywnie dużą i małą prędkością, zmieniać kierunek, spontanicznie zatrzymywać się i zawisać, a także wykonywać charakterystyczny akt zanurzenia powierzchnia wody, przypominająca naturę ważki. Projekt wykorzystuje platformę Microsoft Azure wraz z zastrzeżonymi produktami i usługami chmurowymi Microsoft oraz aplikacją mobilną na Androida dla komponentów oprogramowania i bazy danych: Lolin D32 Pro, NeffosY5i, wiele czujników i quadrocopter (quadkopter) należą do jego głównych komponentów sprzętowych. Czujniki są pakowane w dwie jednostki funkcjonalne: jednostkę monitorowania powietrza (AMU) i jednostkę monitorowania wody (WMU).
Wprowadzenie
Przegląd
W ostatnich latach technologia szybko ewoluowała. Prowadzi to do powstawania nowych obszarów działalności biznesowej i rozwoju przemysłowego oraz ekspansji, np. w kierunku Przemysłu 4.0. Niemniej jednak zanieczyszczenia stały się poważnym problemem w nowoczesnych metropoliach z powodu emisji przemysłowych i rosnącej urbanizacji. Obowiązkiem fabryk byłaby kontrola emisji zanieczyszczeń do powietrza i/lub wody. Projekt ma niezwykłe znaczenie, gdy regulacja emisji przemysłowych staje się kluczowa. Możliwy byłby dostęp do obszarów niedostępnych w inny sposób. Co więcej, ze względów bezpieczeństwa znacznie bardziej pożądane jest używanie drona do monitorowania poziomu zanieczyszczeń. Przede wszystkim dla organu regulacyjnego, organu zarządzającego i instytucji naukowych monitorowanie jakości wody i toksyczności powietrza może być prowadzone systematycznie i okresowo, przy minimalnym wysiłku człowieka, jeśli istnieje dobrze rozwinięty system, który wykorzystuje również słynny Internet Rzeczy koncepcja (IoT). Uzyskane informacje mogłyby zostać wykorzystane przez organy ścigania do karania firm naruszających ustalone standardy. Głównym celem projektu jest zaprojektowanie i stworzenie systemu monitoringu środowiska, który jest niezawodny, połączony z siecią WWW (WWW), przyjazny dla użytkownika, przyjazny dla środowiska i opłacalny.
Jakość powietrza
Emisje gazów podczas działalności przemysłowej mogą być szkodliwe dla ludzi, zwierząt i/lub roślin, prowadząc do toksyczności powietrza . Projekt ten dotyczy kilku znaczących zanieczyszczeń powietrza, jak podkreślono w wytycznych dotyczących jakości powietrza Światowej Organizacji Zdrowia (WHO). Uwzględniane są również gazy cieplarniane, takie jak dwutlenek węgla (CO2) i metan (CH4). Ogólnie rzecz biorąc, w celu monitorowania jakości powietrza, projekt koncentruje się na stężeniach dwutlenku azotu (NO2), amoniaku (NH3), tlenku węgla (CO), dwutlenku węgla (CO2) i metanu (CH4), oprócz parametrów pomocniczych, takich jak jak temperatura otoczenia i wilgotność. Gazy są wykrywane za pomocą czujników gazu typu metal-tlenek-półprzewodnik (MOS).
Jakość wody
Przepisy dotyczące ochrony środowiska regulują oczyszczanie ścieków przemysłowych, w których określona materia organiczna, substancje nieorganiczne, patogeny i składniki odżywcze muszą zostać usunięte, zanim woda zostanie uznana za oczyszczoną, a następnie odprowadzoną do zbiorników wodnych. Typowe metody oczyszczania ścieków to usuwanie ciał stałych, olejów i smarów, usuwanie biodegradowalnych substancji organicznych, proces osadu czynnego, obróbka kwasów i zasad oraz obróbka materiałów toksycznych, zgodnie z wykazem International Water Association. Ogólnie rzecz biorąc, ścieki byłyby wstępnie oczyszczane w fabrykach, minimalizując w ten sposób ładunek zanieczyszczeń, przed odprowadzeniem do zbiorników wodnych. Jednak, zwłaszcza w krajach rozwijających się, czasami ścieki przemysłowe są odprowadzane bez procesu oczyszczania . Dlatego kluczowy jest skuteczny system monitorowania jakości wody. W projekcie uważa się, że wartości zmętnienia i przewodności elektrycznej (EC) dają obraz jakości wody w określonym miejscu.
Powiązane badania
Koncepcja Internetu Rzeczy
IoT odnosi się do sieci fizycznych urządzeń lub obiektów, które są połączone z Internetem i mają zdolność identyfikacji (UID), a także komunikowania się ze sobą za pośrednictwem sieci. Umożliwia dostęp do połączonych urządzeń z dowolnego miejsca przez Internet i może być zdalnie monitorowany i kontrolowany. Na podstawie raportu Cisco VNI stwierdza się, że produkcja urządzeń IoT ma wzrosnąć do 10 miliardów do 2020 r. i 22 miliardów do 2025 r. Nie ma więc wątpliwości, że IoT odgrywa w przyszłości niezbędną rolę. Procesy i systemy biznesowe prawdopodobnie będą zawierać element IoT w nadchodzących latach [5]. Zastosowania inteligentnych technologii znacząco wpłynęły na każdy aspekt ludzkiego życia, zapewniając lepszą jakość życia, a także utrzymywania łączności z technologiami. Zapewnienie ujednoliconego mechanizmu dostępu jest podstawową koncepcją w IoT. Dzięki lepszej sterowalności i konfigurowalności urządzeń elektronicznych w środowisku IoT wiele krajów poszukuje obecnie technologii zorientowanej na IoT, aby pomóc w tworzeniu konformacji pokrewnej dziedziny. Ogólnie rzecz biorąc, architektury IoT składają się z trzech głównych komponentów, a mianowicie sprzętu, oprogramowania pośredniczącego i usług. Komponentami sprzętowymi mogą być dowolne urządzenia, czujniki, a nawet systemy wbudowane, które stanowią podstawowe części inteligentnego systemu. Funkcjonują w celu zbierania danych i przesyłania ich do określonej platformy (takiej jak oprogramowanie pośredniczące) w celu przetworzenia. Oprogramowanie pośredniczące zapewnia funkcjonalność gromadzenia i przetwarzania danych przesyłanych z komponentów sprzętowych oraz przechowywania ich w razie potrzeby. Dzięki ustanowionemu połączeniu sieciowemu może przesyłać te dane do infrastruktur chmurowych online w celu dalszych obliczeń i celów przechowywania. Te przechowywane zasoby mogą być pobierane przez oprogramowanie aplikacyjne, które jest zasadniczo zaprojektowane tak, aby spełniało specyfikacje projektu projektu, a także przedstawiało niezbędne wglądy w informacje zebrane za pomocą graficznego interfejsu użytkownika. Pojawienie się technologii wykrywania IoT uczyniło z niej kluczowy element w zastosowaniach monitorowania i opieki zdrowotnej, zwłaszcza w rolnictwie i przemyśle. Takie zastosowania obejmują automatyczne monitorowanie kondycji roślin, monitorowanie żyzności gleby i erozji, monitorowanie jakości płytek ceramicznych oraz system wykrywania wycieków z rur gazowych. W większości przypadków systemy monitorowania wody IoT mają znormalizowaną strukturę przepływu pracy, w której czujniki wykrywające jakość wody są rozmieszczone w określonych interesujących miejscach w celu sprawdzenia otaczającego stanu fizjologicznego. Jednocześnie zostaną wykonane pomiary danych z czujników i przesłane do dedykowanej platformy chmurowej w celu przetwarzania i przechowywania za pośrednictwem sieci lokalnej. Dla lepszej analizy danych w czasie rzeczywistym i wykrywania zdarzeń kluczowe będzie posiadanie jakiejś formy paradygmatu sprzężenia zwrotnego, mającego na celu dostarczenie kompleksowego przeglądu stanu środowiska. W związku z tym zostanie wdrożona aplikacja współpracująca z serwerem w chmurze, która umożliwi pobieranie i rozpowszechnianie informacji użytkownikom końcowym. Chociaż nad systemem monitoringu jakości wód przeprowadzono wiele badań, sposoby realizacji i wdrażania takiego systemu mogą się nieznacznie różnić w zależności od stosowanych technologii i aplikacji.
Jakość powietrza
Wpływ działalności przemysłowej na jakość powietrza
Rosnąca urbanizacja jest konieczna, aby poradzić sobie ze stale rosnącą liczbą ludności na świecie, która w chwili pisania ma wynosić 7,81 miliarda. Jest więc naturalnie uzasadnione, że w porównaniu z poprzednimi stuleciami miało miejsce więcej działań przemysłowych. Jak podkreślono, branże można klasyfikować według rodzaju. Generalnie istnieją cztery rodzaje branż: pierwotna, wtórna, trzeciorzędowa i czwartorzędowa. Pozyskiwanie surowców, np. górnictwo, rybołówstwo i rolnictwo, zalicza się do przemysłu pierwotnego. Przemysł wtórny obejmuje wszystkie czynności produkcyjne, na przykład wytwarzanie samochodów, komponentów elektronicznych, urządzeń elektrycznych, płytek, stali i tak dalej. Przemysł trzeci oznacza świadczenie lub dostarczanie usług. Przykłady obejmują nauczanie, coaching i pielęgniarstwo. Badania i rozwój należą do przemysłu czwartorzędowego. Działania przemysłowe, które szkodzą środowisku, należą zazwyczaj do kategorii pierwotnych i wtórnych. Przemysł czwartorzędowy rzadko prowadzi do zauważalnych negatywnych skutków dla środowiska, chociaż ma potencjał, jeśli jest prowadzony na dużą skalę. Przemysł usługowy jest najbardziej przyjazny dla środowiska. Wiadomo, że spalanie paliwa emituje gazy, które zanieczyszczają środowisko, na przykład dwutlenek siarki (SO2), tlenki azotu (NOx) i dwutlenek węgla (CO2). W Azji intensywne emisje zaobserwowano w różnych lokalizacjach, zwłaszcza w rejonie Pacyfiku w Japonii, Korei Północnej i Korei Południowej oraz na obszarach przybrzeżnych Tajwanu i Chin. W głębi Chin mierzono wysokie emisje SO2 w kilku sieciach. Dane historyczne wykazały, że emisje NOx w Azji przewyższały emisje w Ameryce Północnej i Europie . Ponadto Fenger wskazał, że fotochemiczne zanieczyszczenie powietrza jest zjawiskiem o dużej skali w północnej części Europy. Stwierdza również Fenger , że gwałtowna urbanizacja często prowadziła do niekontrolowanego wzrostu i pogorszenia stanu środowiska w krajach rozwijających się. Działalność przemysłowa przyczynia się do zanieczyszczenia transgranicznego, powodując wzrost stężeń gazów cieplarnianych w skali globalnej. Łagodzenie zanieczyszczenia powietrza wymaga wysiłków krajów rozwiniętych i rozwijających się.
Zanieczyszczenia powietrza
Wytyczne WHO dotyczące jakości powietrza
Wytyczne WHO dotyczące jakości powietrza zostały po raz pierwszy opublikowane w 1987 r., a następnie zaktualizowane w 1997 r. Później dokonano kilku poprawek. Wytyczne można uznać za najbardziej wiarygodne międzynarodowe wytyczne dotyczące jakości powietrza. Wytyczne są konstruowane w oparciu o oceny ekspertów, przy dostępności najnowszych dowodów naukowych. Od czasu do czasu WHO podejmuje się przeglądu zgromadzonych badań naukowych w dziedzinie jakości powietrza. Opracowane wytyczne mają zastosowanie we wszystkich regionach WHO, w tym w Regionie Afryki, Regionie Ameryk, Regionie Azji Południowo-Wschodniej, Regionie Europejskim, Regionie Wschodniego Morza Śródziemnego oraz Regionie Zachodniego Pacyfiku. Przedstawione tu wytyczne WHO dotyczące jakości powietrza są oparte na globalnej aktualizacji z 2005 r.
Znaczące zanieczyszczenia powietrza
PM2,5 odnosi się do cząstek mniejszych niż 2,5 mm, podczas gdy PM10 odnosi się do cząstek mniejszych niż 10 mm. Zarówno w przypadku krótkotrwałego, jak i długoterminowego narażenia na pyły, negatywne skutki są oczywiste. W widoczny sposób obserwuje się choroby i problemy zdrowotne układu oddechowego i sercowo-naczyniowego. Obecnie bardziej rutynowo prowadzone są pomiary PM10. Pomiary PM10 łącznie obejmują drobne (PM2,5) i grube (PM10) cząstki, które mogą dostać się do dróg oddechowych. Ozon zazwyczaj powstaje w atmosferze w wyniku reakcji fotochemicznych. Obecność światła słonecznego jest obowiązkowa. Wymaga również zanieczyszczeń prekursorowych, na przykład lotnych związków organicznych (LZO) i NOx. Oczekuje się zauważalnych negatywnych skutków zdrowotnych w przypadku stężeń 8-godzinnych, przy wartościach wyższych niż 240 mg/m3. Wskazane w badaniach eksperymentalnych na ludziach i zwierzętach, stężenia przekraczające 200 mg/m3 powodują, że gaz jest toksyczny i w krótkim czasie ma zauważalny wpływ na zdrowie. Niekorzystne skutki wystąpią w przypadku długotrwałej ekspozycji. Duża część NO2 jest początkowo uwalniana jako NO, ale jest szybko utleniana przez O3 do NO2. Ponieważ wytyczna 200 mg/m3 nie została jeszcze zakwestionowana przez ostatnie badania, została zachowana z poprzedniej wersji wytycznych WHO dotyczących jakości powietrza. Narażenie na SO2 jest szkodliwe dla zdrowia ludzkiego. Badania wykazały, że krótkotrwała ekspozycja, nawet 10 minut, może prowadzić do objawów oddechowych i wpływać na czynność płuc. Na podstawie badań przeprowadzonych w Hongkongu zauważono znaczne zmniejszenie skutków zdrowotnych, gdy zawartość siarki została znacznie zmniejszona . W podobny sposób zwiększona śmiertelność jest związana z siarczanem i drobnoziarnistym zanieczyszczeniem powietrza na poziomach powszechnie występujących w miastach USA. Chociaż istnieją dowody wskazujące na skutki zdrowotne powodowane przez SO2, nie nadal kontrowersje, które otaczają tę sprawę. Istnieje możliwość, że niekorzystne skutki zdrowotne są spowodowane przez ultradrobne (UF) cząstki lub inne czynniki, które wciąż są poza zasięgiem aktualnych badań. Niemniej jednak, w oparciu o aktualną literaturę naukową, uzasadnione jest uznanie SO2 za gaz szkodliwy. Przeprowadzono przestrzenną ocenę wzorców jakości powietrza w Malezji. Analiza wielowymiarowa obejmowała kilka metod, w tym hierarchiczną aglomeracyjną analizę skupień (HACA), analizę głównych składowych (PCA) i wielokrotną regresję liniową (MLR) w celu określenia odpowiednio wzorców przestrzennych, głównych źródeł zanieczyszczenia i wkładu zanieczyszczeń powietrza . Z analizy PCA wynika, że przypadki zanieczyszczenia powietrza w Malezji są w dużej mierze spowodowane emisją z przemysłu, pojazdów i stref, w których gęstość zaludnienia jest wysoka. Jest to literatura dowodowa na poparcie hipotezy, zgodnie z którą zanieczyszczenia powietrza są widoczne na obszarach przemysłowych. Z analizy MLR wynika, że zmienność wskaźnika zanieczyszczenia powietrza (API) w stacjach monitorowania powietrza w Malezji wynikała głównie z pyłu zawieszonego, w szczególności PM10. W dalszej analizie wykazano nawet, że wysokie stężenie PM10, w kontekście prowadzonych badań, był spowodowany głównie tlenkiem węgla (CO). W tym przypadku można wnioskować, że procesy spalania, w tym te prowadzone w fabrykach i zakładach przemysłowych, a także w silnikach pojazdów, przyczynią się do zanieczyszczenia powietrza w lokalnym środowisku. Amoniak (NH3) jest również jednym z gazów toksycznych. Jest powszechnie stosowany w produkcji suchych nawozów, przetwórstwie spożywczym, produkcji tworzyw sztucznych, suchych nawozów, tekstyliów, barwników i tak dalej. Gaz amoniakalny może przypadkowo wyciekać ze zbiorników magazynowych, a następnie zanieczyszczać lokalną atmosferę i powodować zagrożenie dla zdrowia. Ponieważ monitorowanie jakości powietrza na terenach przemysłowych jest główną częścią projektu, zdolność systemu do wykrywania wycieków gazów, takich jak amoniak, będzie dodatkową funkcją. Z drugiej strony metan (CH4) jest jednym z głównych gazów zatrzymujących ciepło, które przyczyniają się do tak zwanego "efektu cieplarnianego". Innymi słowy, jest to gaz cieplarniany. Niektóre źródła metanu obejmują rozkład beztlenowy na naturalnych terenach podmokłych i polach ryżowych, emisje z systemów produkcji zwierzęcej, spalanie biomasy i poszukiwanie paliw kopalnych . Poza tym zbiorniki fermentacyjne i laguny oczyszczalni ścieków mogły emitować duże ilości metanu. Nadmierne uwalnianie metanu do atmosfery jest zdecydowanie niepożądane.
Istniejące metody monitorowania jakości powietrza
Istnieją dwie kategorie głównych metod monitorowania jakości powietrza, a mianowicie ręczne pobieranie próbek powietrza i okresowe monitorowanie za pomocą stacji monitorowania jakości powietrza (AQMS).
Ręczne pobieranie próbek powietrza
Szybka analiza na miejscu jest prawdopodobnie najbardziej prymitywna ze wszystkich. Niemniej jednak jego skuteczność jest nie do przecenienia, zwłaszcza w przypadku monitoringu jakości powietrza w miejscach, gdzie nie zainstalowano stacji monitoringu powietrza. Obejmuje pracownika noszącego akcesoria do pobierania próbek powietrza. Pracownik będzie musiał wejść na miejsce monitorowania, które jest prawdopodobnie wypełnione dużą ilością toksycznych zanieczyszczeń powietrza. Do pobierania próbek powietrza w pobliżu strefy oddychania używana jest pompa, a urządzenie do noszenia wykona szybką analizę pobranego powietrza. Aby przeprowadzić bardziej kompleksową analizę, pracownik musi pobrać próbki powietrza i zanieść je z powrotem do laboratorium. Laboratorium SanAir Technologies opisało kilka sposobów osiągnięcia tego celu. Pobieranie próbek całego powietrza jest najłatwiejsze w swoim rodzaju i polega na pobraniu próbek powietrza za pomocą worków Tedlar i kanistrów Summa. Próbki są zapieczętowane. Aktywne pobieranie próbek powietrza jest ogólnie stosowane do zbierania lotnych i pół-LZO. Polega na zastosowaniu tuby wypełnionej stałym materiałem sorbentowym. Za pomocą pompy do pobierania próbek powietrze jest przepuszczane przez rurkę, a zanieczyszczenia są chemicznie pochłaniane przez materiał. Stały materiał sorbentowy stosowany jest również w przypadku pasywnego pobierania próbek powietrza. Różnica polega na tym, że absorpcja zanieczyszczeń zależy od procesu dyfuzji. Pobieranie próbek przez filtr jest idealne do zbierania zanieczyszczeń w postaci pary. Za pomocą pompy powietrze przepuszczane jest przez kasetę filtra. Między filtrem a powietrzem zawierającym zanieczyszczenia zachodzi reakcja chemiczna. Następnie powstaje stabilna pochodna. Rodzaj filtra jest specyficzny dla danego zanieczyszczenia. W próbkowaniu impinger powietrze jest przepuszczane przez roztwór. Roztwór (w postaci płynnej) jest reaktywny. Zanieczyszczenia w powietrzu będą reagować chemicznie z roztworem. Próbkowanie impulsowe jest zwykle stosowane w przypadkach, gdy źródło jest znacznie statyczne, poziom wilgoci jest wysoki, a temperatura otoczenia wysoka.
Korzystanie z AQMS
Proces monitoringu jakości powietrza może odbywać się zdalnie poprzez budowę stałych stacji monitoringu powietrza w stałych lokalizacjach. Zazwyczaj AQMS jest w stanie wykryć co najmniej PM10 (cząstki stałe o średnicy mniejszej niż 10 mm). Nowsze AQMS są w stanie wykryć mniejsze cząstki stałe, czyli PM2,5. Większość AQMS uwzględnia również inne zanieczyszczenia, takie jak ozon (O3), dwutlenek siarki (SO2), tlenek węgla (CO) i dwutlenek azotu (NO2). Niemniej jednak AQMS byłby w stanie podać odczyty jakości powietrza tylko w określonym miejscu, w którym jest zainstalowany. Powszechnie przyjmuje się, że jakość powietrza w tym mieście jest zgodna z tą zmierzoną w miejscu instalacji AQMS. Do ilościowego określenia jakości powietrza w różnych punktach na danym obszarze potrzebna będzie znaczna liczba AQMS. Poza tym AQMS są stosunkowo kosztowne i nieporęczne, a od czasu do czasu wymagają znacznej ilości prac inspekcyjnych i konserwacyjnych.
Wskaźnik jakości wody i zanieczyszczenia
Ogólnie istnieje wiele parametrów, które mogą wpływać na jakość wody. Departament Środowiska (DOE) w Malezji potwierdził niektóre z najwyższych składników, które najlepiej opisują wskaźnik jakości wody (WQI). Obejmuje to biochemiczne zapotrzebowanie na tlen (BZT), pH i chemiczne zapotrzebowanie na tlen (COD). Klasy I-III opisują jakość wody wymaganą do podtrzymania życia wodnego, podczas gdy źródła wody z klasy V są uważane za najmniej korzystne z powodu obecności dużej ilości związków zanieczyszczających. Odwrotnie, źródła wody z klasy I charakteryzują się minimalnym poziomem zanieczyszczenia. Aby zapewnić bezpieczny poziom picia, inne zajęcia nadal wymagają odpowiedniego systemu leczenia. WQI to ogólna definicja oznaczająca czystość wody. Służy do podsumowania dużej ilości danych dotyczących jakości rzeki w prostszy sposób i jest przydatny w przekazywaniu informacji o jakości wody lokalnym społecznościom. Parametry jakości wody można podzielić na trzy właściwości: chemiczną, fizyczną i biologiczną. pH, EC, rozpuszczony tlen, zasolenie i potencjał oksydacyjno-redukcyjny są uważane za część właściwości chemicznych jakości wody. Kwasowość lub zasadowość roztworu zależy od wartości pH, podczas gdy na EC wpływa liczba jonów obecnych w roztworze. Zdolność wody do samodzielnego usuwania zanieczyszczeń jest znana jako potencjał oksydacyjno-redukcyjny. Podobnie wysoka wartość potencjału oksydacyjno-redukcyjnego oznacza dobrą jakość wody. Z drugiej strony fizyczne czynniki jakości wody to mętność i temperatura. Zmętnienie oznacza zmętnienie lub nieprzezroczystość roztworu. Wysoka wartość zmętnienia wskazuje na dużą ilość materiału rozpuszczonego w roztworze (mniejsze zmętnienie). Ilość bakterii, fitoplanktonu, wirusów i glonów stanowi biologiczne czynniki jakości wody. Wszystkie te czynniki są wykorzystywane do oceny jakości wody. Jednak niektóre z nich (glony, wirusy itp.) są nadal niemierzalne przez istniejącą technologię wykrywania i można je zrealizować tylko za pomocą analizy chemicznej.
Istniejące metody monitorowania jakości wody
Zaproponowano kilka metod monitorowania i dostarczania danych w czasie rzeczywistym na temat jakości wody za pomocą czujników. W każdym systemie IoT opartym na monitorowaniu wybór odpowiednich czujników jakości wody jest ważny, ponieważ różne czujniki mogą służyć do różnych celów. Tak więc, aby dostosować się do specyfikacji projektu, należy dokonać doboru odpowiednich czujników w zależności od wydajności czujnika, kosztów i parametrów pomiarowych. Według Radhakrishnana i Wu większość systemów IoT wykorzystuje czujniki dostępne na rynku. Takie czujniki obejmują czujnik mętności DFRobot, czujnik grawitacyjny pH, czujnik grawitacyjny analogowy DO i czujnik temperatury DFRobot. Są to stosunkowo niedrogie czujniki z mechanizmem wykrywania jednego parametru jakości i są powszechnie wykorzystywane w prostych projektach IoT. Madhavireddy i Koteswarrao opublikowali propozycję taniego przenośnego systemu monitorowania wody. Badania te zapewniają bezpieczne zaopatrzenie w wodę pitną. Do wdrożenia systemu wykorzystuje się proste, a jednocześnie niedrogie czujniki, instalowane w sieci wodociągowej. Należą do nich czujnik pH, czujnik temperatury i czujnik SKU:SEN0219 (do wykrywania CO2). Ich odpowiednie parametry będą mierzone i przechowywane na serwerze WWW. W celu skutecznego rozpowszechniania informacji o zanieczyszczeniach Madhavireddy i Koteswarrao opracowali niestandardową stronę internetową, aby ułatwić monitorowanie danych z czujników w czasie rzeczywistym. Do celów produkcyjnych lub zastosowań IoT w szeroko zakrojonych sektorach gospodarki należy zastosować lepszy czujnik z wieloparametrowym mechanizmem detekcji. Przykładem może być Kapta 3000AC4, która jest przeznaczona do pomiaru poziomu chloru, ciśnienia, temperatury i przewodności wody i kosztuje 3200 GBP. Spectro::lyser to kolejny rodzaj czujnika, który mierzy zmętnienie, kolor i zanieczyszczenie wody i kosztuje około 5000 GBP. Podobnie, są to czujniki kompetentne pragmatycznie, ale drogie pod względem kosztów, a zatem niepraktyczne do wdrożenia, zwłaszcza w projekcie z szerokimi miejscami monitorowania (gdzie wymagane są liczne czujniki). Na podstawie badań przeprowadzonych przez Gholizadeha fizyczne pobranie próbki wody jest sporym wyzwaniem, zwłaszcza przy uzyskiwaniu wskaźników jakości w dużej skali. Aby złagodzić te ograniczenia, niektórzy badacze zaproponowali zastosowanie techniki teledetekcji. Zdalny system wykorzystuje widzialne i bliskie podczerwieni pasma promieniowania słonecznego do identyfikacji korelacji między odbiciem wody a poziomem zanieczyszczeń. Technika ta umożliwia natychmiastowy podgląd w czasie parametrów jakości wód powierzchniowych. Według Wanga i Yanga teledetekcja wspomaga ocenę zmian jakości wody (poprzez obserwację koloru i współczynnika załamania światła) oraz wykrywanie zakwitu glonów. Jednak takie wizualne metody wykrywania nie są wystarczająco precyzyjne i niezawodne, ponieważ mogą na nie wpływać złożone optycznie warunki, takie jak spływanie gleby i osady. W rezultacie nawet do tej pory ta technika nie jest powszechnie stosowana. Co więcej, algorytm opracowany dla systemu ma zastosowanie tylko do określonego obszaru, a uzyskane dane jakościowe mogą czasami być błędne z powodu nieprzewidzianych zmian środowiskowych, takich jak burza. Tak więc, jeśli chodzi o dokładność wyników, wskazane byłoby skupienie się na czujnikach fizycznych, które są łatwo dostępne na rynku.
Współczynnik doboru czujnika
Jak wspomnieli Radhakrishnan i Wu, jeśli chodzi o opracowanie infrastruktury monitorowania IoT, może to nie być produktywny sposób uwzględniania każdego pojedynczego parametru jakości, ponieważ wymagałoby dużego nakładu pracy i znacznych zasobów (z udziałem wielu czujników) do realizacji takiego systemu . Tak więc parametry jakości wody, które należy wziąć pod uwagę, powinny opierać się na właściwościach, w których się znajdują i lokalizacji, w której są mierzone. W większości przypadków przy wyborze odpowiednich parametrów jakościowych brane są pod uwagę główne składniki źródła wody w miejscu monitoringu oraz to, w jaki sposób w istotny sposób na nie wpływają czynniki zewnętrzne (takie jak ścieki przemysłowe, zmiany klimatyczne, składowanie odpadów itp.). dla systemu monitorowania IoT. Podobną koncepcję zastosowano w projekcie wykonanym przez Hamunę. Uruchomili bezprzewodową platformę inteligentnej wody do monitorowania jakości oceanów i przybrzeżnych. Ponieważ ich projekt jest poświęcony pomiarom zanieczyszczenia wody morskiej, parametry mierzone przez czujniki dotyczą głównie rozpuszczonych jonów i zasolenia. Należą do nich pH, EC i rozpuszczone jony (takie jak fluorek, azotan, chlorek, lit itp.). Inny przykład można dostrzec w pracy zaproponowanej przez Zakarię i Michaela. Opracowany system to oparta na chmurze bezprzewodowa sieć czujników (WSN) z wbudowanym modułem czujnika i węzłem bramy. Funkcjonuje w celu zbierania danych o jakości wody z odprowadzanych ścieków przemysłowych i przesyłania ich do platformy w chmurze za pośrednictwem modułu komunikacji bezprzewodowej. Ponieważ większość ścieków odprowadzanych przez przemysł zawiera dużą ilość rozpuszczonych jonów i zawieszonych cząstek stałych, proponowana jednostka czujnika będzie zawierać czujniki pH, przewodności i rozpuszczonego tlenu.
Czynnik topologiczny i lokalizacja rozmieszczenia czujnika
Wysokie koszty operacyjne i częste konserwacje to typowe problemy napotykane w większości wodnych systemów IoT. Uważa się, że takie problemy są związane z lokalizacją rozmieszczenia czujnika i warunkami środowiskowymi. W tym zakresie koncepcja rozmieszczenia różnych czujników w różnych lokalizacjach, takich jak rzeka i strumienie, została szeroko przetestowana. W oparciu o projekt prowadzony przez Kruger zainstalowano ponad 220 jednostek czujników monitorujących poziom wody i zawartość zanieczyszczeń. Wdrożony system składa się z modułu czujnika (składającego się z czujników ultradźwiękowych, mętności i temperatury), systemu energii słonecznej (do zasilania czujników) oraz odbiornika GPS. Czujniki ultradźwiękowe w tym przypadku są wykorzystywane jako moduł pomiaru odległości, który szacuje poziom wody i wysyła powiadomienie alarmowe do użytkowników końcowych w przypadku wykrycia jakichkolwiek nieprawidłowości w odczycie, które mogą oznaczać zalanie. Ponieważ most zapewnia solidną platformę montażową, czujniki te zostaną zainstalowane pod nim. Czujniki temperatury i mętności są czujnikami kontaktowymi z wodą, które działają tylko wtedy, gdy ich sekcja wykrywania jest w kontakcie z wodą. W związku z tym wskaźniki pływakowe zostaną połączone z tymi czujnikami, dzięki czemu dane o jakości wody w czasie rzeczywistym mogą być zbierane z czasem. Dodatkowo zainstalowany jest modem komórkowy umożliwiający integrację z siecią komórkową i transmisję danych z czujników do dedykowanej platformy chmurowej. Po aktywacji pomiar czujnika będzie wykonywany okresowo (co 5 minut) i przesyłany przez sieć. Jednak po miesiącach eksploatacji okazało się, że system potencjalnie wymaga wysokiego poziomu konserwacji. W tym okresie wiele czujników kontaktu z wodą uległo uszkodzeniu w wyniku ciągłych zmian warunków środowiskowych. Deszcze i ciała stałe przenoszone przez prądy strumieniowe wydają się stanowić poważne zagrożenie dla tych elementów sprzętowych, wprowadzając do systemu sól i inne zanieczyszczenia, które w dłuższej perspektywie mogą prowadzić do korozji przewodów i niezamierzonych zwarć. Niemniej jednak w tym przypadku nie ma to wpływu na elementy bezkontaktowe, takie jak czujniki ultradźwiękowe, ponieważ nie mają one bezpośredniego kontaktu z wodą. Tym samym praca Krugera dowiodła, że żywotność bezdotykowych systemów sprzętowych jest znacznie lepsza niż tych, które są bezpośrednio wystawione na działanie środowiska. Zaproponowano obrazowy system sygnalizacji powodziowej do stosowania w ostrzeganiu i wykrywaniu katastrof . W tym systemie zdalna kamera byłaby wykorzystywana do monitorowania rzek o wysokim ryzyku powodzi. Dzięki zastosowaniu techniki przetwarzania obrazu krawędzie wody zostaną zidentyfikowane i przekonwertowane na odpowiednią wartość poziomu wody. Pod względem wydajności i elastyczności, Lo twierdził, że system oparty na obrazie jest nadal lepszy niż tradycyjne techniki szacowania poziomu wody, które obejmują instalację czujników na rurach w rzekach i ścianach odpływów. Podejście wykorzystujące tradycyjne metody ogranicza lokalizację, zasięg i gęstość sensorów obserwacji poziomu wody. Co więcej, czujniki zainstalowane na miejscu mogą łatwo ulec uszkodzeniu w wyniku powodzi lub nawet zasypaniu gruzem. W rezultacie doprecyzowano, że czujniki mające bezpośredni kontakt fizyczny z otoczeniem mogą powodować problemy z żywotnością podczas długotrwałej eksploatacji. Jak na razie, w oparciu o istniejące badania i ustalenia, jedynym sposobem rozwiązania tych problemów będzie wdrożenie technologii wykrywania bezkontaktowego. Dla proponowanego rozwiązania tego projektu badawczego zostaną podjęte poważne działania w odniesieniu do tej sprawy.
Metodologia
Przegląd
Operator-człowiek poleciałby Dragonfly w wybrane miejsce. Widok uchwycony przez kamerę drona jest odzwierciedlany w aplikacji wraz z aktualnymi współrzędnymi i wysokością, aby prowadzić pilota podczas manewrowania. W aplikacji wyświetlane są również dane z czujników w czasie rzeczywistym. Następnie, uruchamiając proces monitorowania przez aplikację mobilną, dane byłyby zbierane okresowo. Dostępne są funkcje monitorowania powietrza i wody. Dane są przetwarzane w celu uzyskania odpowiednich wyników, przedstawionych w formie graficznej. Dane historyczne są przechowywane w bazie danych i w razie potrzeby można je pobrać z aplikacji mobilnej. Monitorowanie środowiska in-situ jest znacznie wydajne, ponieważ personel nie musi już znajdować się na dokładnych współrzędnych lub bardzo blisko niego, aby zebrać próbki, ponieważ do obszaru inspekcji ma dostęp tylko dron. Zmniejsza to ryzyko narażenia ludzi na szkodliwe zanieczyszczenia powietrza, a jednocześnie eliminuje żmudne podróże, jakie muszą pokonywać pracownicy, aby dostać się do miejsc monitorowania. Dodatkowo, za pomocą drona można dostać się do takich miejsc jak środkowy bieg rzeki i obszary nad kominami o dużych wysokościach. Przypadek, w którym wiele zestawów czujników jest zainstalowanych na stałe w różnych stacjach monitorowania na tym samym akwenie/obszarze przemysłowym będzie raczej przestarzały, ponieważ dron z zaledwie jednym zestawem czujników jest w stanie podróżować do różnych punktów na określonym obszarze i mieć proces monitorowania odbywa się sprawnie. Co więcej, konserwacja jest konieczna tylko dla Dragonfly, w przeciwieństwie do wymagających regularnych przeglądów i konserwacji, które znowu wiążą się z dość wyczerpującą podróżą dla pracowników, jeśli zestawy czujników są na stałe zainstalowane w miejscach. To powiedziawszy, koszty instalacji, eksploatacji i konserwacji są ograniczone do minimum, jeśli projekt Dragonfly zostanie wdrożony. Opcjonalnie konfiguracja systemu może być skalowana w górę, aby uwzględnić wiele ważek, jeśli ma być zmapowany profil środowiskowy znacznie większego obszaru.
Ustawienia systemu
Wdrażając zasady projektowania modułowego, niezbędne operacje są pogrupowane w pojedyncze bloki (jednostki). System składa się z komponentów sprzętowych i programowych. Sprzęt to Dragonfly, który zawiera jednostkę monitorującą powietrze (AMU), jednostkę monitorującą wodę (WMU) i jednostkę komunikacyjną (CU). Komponenty oprogramowania obejmują Microsoft Azure oraz autorskie produkty i usługi chmurowe Microsoft, zgrupowane jako Cloud, uzupełnione o aplikację mobilną na Androida.
Quadkopter
Zasadniczo wszystkie czujniki zostaną zapakowane w kompaktowy sposób i zamontowane na dronie. Pośrednio masa startowa zostanie zwiększona. Dlatego dron musi być w stanie pomieścić dużą ładowność. Wybrany model drona to KaiDeng K70C, który jest w stanie obsłużyć do 0,5 kg ładunku. Do podwozia przymocowane jest urządzenie wspomagające wyporność, aby umożliwić dronowi unoszenie się na wodzie.
Moduły sprzętowe
Jednostka monitorowania powietrza
Parametry monitorowania jakości powietrza obejmują dwutlenek azotu (NO2), tlenek węgla (CO), ekwiwalent dwutlenku węgla (CO2-eq), amoniak (NH3) i metan (CH4). Stężenia tych gazów są monitorowane przy użyciu technologii wykrywania gazów tlenków metali. Poza tym istnieją parametry pomocnicze, takie jak temperatura otoczenia, ciśnienie (do określenia wysokości) i wilgotność. Dwa komponenty zawarte w AMU to Grove-Multichannel Gas Sensor (MiCS-6814) i SparkFun Environmental Combo Breakout (CCS811/BME280). Czujniki wykorzystują interfejs z układem scalonym (I2C). W UAM znajduje się również mikrokontroler Lolin D32 Pro.
Jednostka monitorująca wodę
Miarą stopnia utraty przezroczystości wody z powodu obecności zawieszonych cząstek jest zmętnienie. Czujnik mętności zaimplementowany w projekcie to grawitacyjny DFRobot - analogowy czujnik mętności. Poza tym EC mierzy się za pomocą specjalnie skonstruowanej sondy EC. Dwa czujniki są zainstalowane na "ogonie"
Dragonfly, która jest automatycznie opuszczana grawitacyjnie podczas startu i ponownie chowana podczas przyziemienia na twardej powierzchni. Po opuszczeniu ogon jest utrzymywany w 30-odchylnym położeniu od normalnego, aby umożliwić zanurzenie urządzenia czujnikowego, a także zminimalizować wpływ na moduł podczas przyziemienia na twardej powierzchni.
Jednostka komunikacyjna
Smartfon ANeffosY5i jest mocno osadzony na dronie. Powodem instalacji smartfona na Dragonfly jest to, że nawiązana jest szerokopasmowa łączność komórkowa (technologia 4G). Dzięki temu dane mogą być przesyłane do serwera szybko i niezawodnie. Poza tym kamera w smartfonie służy do wyświetlania widoku z pierwszej osoby (FPV) drona w aplikacji mobilnej, która może działać dość daleko. Ponadto wysokościomierz i antena GPS w smartfonie są wykorzystywane do dostarczania danych o wysokości, długości i szerokości geograficznej. Z drugiej strony bateria smartfona zasila AMU i WMU.
Usługa Azure Cloud
Usługa Azure Cloud Service zapewnia nierozerwalne połączenie między IoT a chmurą. Oferuje produkty i usługi oparte na IoT, aby umożliwić urządzeniom z mikrokontrolerem, takim jak Arduino, tworzenie aplikacji IoT oraz komunikację między urządzeniami i zarządzanie nieprzetworzonymi danymi na otwartej i elastycznej platformie w chmurze. W kolejnych częściach usługi Microsoft Azure, które składają się na cały system bazodanowy i serwerowy w chmurze, zostaną omówione w zakresie jego wykorzystania i funkcji.
Centrum IoT
Platforma Azure zapewnia wygodne usługi, takie jak IoT Hub, aby uprościć urządzenie - przesyłanie wiadomości w chmurze i routing danych. W tym projekcie Azure IoT Hub zostanie wykorzystany jako chmura pośrednicząca do komunikacji między Arduino Nano a bazą danych. Domyślnie dane telemetryczne wysyłane z mikrokontrolera do IoT Hub są kierowane do magazynu Microsoft Azure jako końcowego punktu końcowego. Ze względu na trudności w dostępie i modyfikacji danych przechowywanych na Azure Magazyn, punkt końcowy zostanie ustawiony na bazę danych Azure. W związku z tym nie trzeba wykonywać dodatkowego przepływu pracy, ponieważ dane są automatycznie kierowane do wybranej bazy danych. Szczegóły routingu są dokładniej wyjaśnione w dalszej części.
Azure Cosmos DB
Cosmos DB będzie bazą danych telemetrii dla IoT Hub, podczas gdy aplikacja Azure Function App jest używana jako router danych telemetrycznych. Cosmos DB to baza danych typu NoSQL. Jednym z powodów wyboru tej architektury bazy danych jest jej wysoka skalowalność i zdolność do obsługi i odpytywania dużych ilości surowych danych z większą szybkością w porównaniu z innymi bazami danych, takimi jak MySQL, PostgreSQL itp. Zostało to już udowodnione w sekcji Przegląd literatury. W związku z tym bardziej praktyczne będzie wykorzystanie systemu tej bazy danych do zarządzania nieustrukturyzowanymi danymi generowanymi z aplikacji/urządzeń IoT.
Azure Function App
Function App to wygodna platforma, która wykonuje kody w środowisku bezserwerowym w przypadku wystąpienia zdarzenia. Ułatwia integrację z innymi produktami i usługami platformy Azure, po prostu łącząc dane wejściowe i wyjściowe. W przypadku tego projektu zostanie skonfigurowany do uruchamiania za każdym razem, gdy IoT Hub otrzyma dane telemetryczne z zarejestrowanego urządzenia z mikrokontrolerem. Po wyzwoleniu przekieruje nieprzetworzone dane bezpośrednio do Azure Cosmos DB. W ten sposób połączenie IoT Hub z aplikacją Function i Cosmos DB stworzyło kompletny system routingu i przechowywania danych.
Azure Web App i protokół komunikacyjny serwera.
Posiadanie zwykłej komunikacji między urządzeniami a chmurą nie wystarczy, ponieważ nadal istnieje zapotrzebowanie na serwer, aby umożliwić interakcję mobilnego backendu z danymi przechowywanymi w bazie danych. Aby zrealizować taki schemat, jako serwer zaplecza tego projektu zostanie wykorzystana aplikacja Azure Web App. Celem tego serwera jest umożliwienie pobierania i modyfikowania danych z czujników przechowywanych w bazie danych Cosmos DB. Node JS zostanie wybrany jako środowisko wykonawcze serwera. Zostanie wykonana aplikacja na Androida, która będzie łączyć się z serwerem przez MQTT. MQTT jest ogólnie ulepszoną wersją WebSocket z obsługiwanymi opcjami awaryjnymi i funkcją rozgłaszania. Jak stwierdzono w dziale Przegląd Literatury, MQTT jest idealnym kandydatem do zastosowań IoT, a co za tym idzie serwer zostanie zbudowany w oparciu o ten algorytm. Po połączeniu z serwerem urządzenie mobilne będzie mogło pobierać i monitorować dane z czujników z serwera w czasie rzeczywistym. Poza tym serwer będzie również odpowiedzialny za obsługę uwierzytelniania użytkowników i zarządzania logowaniem, w którym użytkownicy będą mogli logować się na własne konta, a nawet rejestrować nowe konto za pomocą niestandardowej aplikacji na Androida. Wszystkie te poświadczenia użytkownika będą przechowywane w bazie danych Azure MySQL.
Aplikacja Azure Logic
W przeciwieństwie do aplikacji funkcji Azure, która jest wyzwalana kodem podczas wystąpienia zdarzenia, aplikacja logiki ma strukturę wyzwalaną przez przepływ pracy. Te przepływy pracy są tworzone za pomocą prostego interfejsu wizualnego połączonego z prostym językiem definicji przepływu pracy w widoku kodu. Oferuje dużą dostępną elastyczność, zwłaszcza w przypadku łączenia się z aplikacjami Software jako usługa (SaaS) i mediami społecznościowymi oraz zapewnia funkcjonalność mailingową. W przypadku tego projektu aplikacja Logic będzie zarządzać wysyłaniem wiadomości e-mail do nowo zarejestrowanych użytkowników w celu weryfikacji własności poczty e-mail. Żądanie wysłania wiadomości aktywacyjnej zostanie poproszone przez serwer aplikacji sieci Web podczas rejestracji nowego użytkownika poprzez wysłanie żądania HTTP POST na adres URL aplikacji Logic. Unikalny niestandardowy link zostanie osadzony w wiadomości aktywacyjnej. Po uzyskaniu dostępu serwer aplikacji internetowej będzie mógł odszyfrować adres URL i aktywować konto użytkownika.
Mobilna aplikacja
Przyjazna dla użytkownika aplikacja mobilna ma kluczowe znaczenie dla doskonałego doświadczenia użytkownika. W tym projekcie do opracowania aplikacji mobilnej wykorzystano Android Studio. Android Studio to profesjonalne oprogramowanie do tworzenia aplikacji. Jest to oficjalne zintegrowane środowisko programistyczne dla systemu operacyjnego Android firmy Google. Czynności zawarte w aplikacji mobilnej zostały odpowiednio zaplanowane przed przystąpieniem do kodowania. Aplikacja mobilna komunikuje się z serwerem poprzez Node.js. Format JavaScript Object Notation (JSON) służy do wysyłania i odbierania danych. Aby osiągnąć FPV, używany jest WebRTC. WebRTC jest powszechnie używany do aplikacji wideo do przesyłania strumieniowego między urządzeniami. W takim przypadku FPV z kamery na dronie zostanie wyświetlony w aplikacji mobilnej.
Wyniki
Produktem finalnym jest system monitorowania środowiska, który składa się co najmniej z oprogramowania Dragonfly i Project Dragonfly. Można go rozszerzyć na sieć ważek, aby skutecznie monitorować na dużym obszarze.
Ważka
Oprogramowanie projektu Dragonfly
Aplikacja mobilna jest połączona z MicrosoftAzure i oferuje weryfikację użytkownika, skanowanie kodów QR, dane w czasie rzeczywistym, FPV, ponowne połączenie z siecią, dane historyczne i integrację map. Korzystanie z aplikacji mobilnej zostało opisane w następujący sposób.
Weryfikacja użytkownika
Do korzystania z aplikacji mobilnej wymagane jest zalogowanie się użytkownika. Dla pierwszego użytkownika konto można zarejestrować, klikając "Zarejestruj się tutaj". Walidacja danych zostanie przeprowadzona na wszystkich polach w aplikacji. Do rejestracji firmy wymagana jest nazwa firmy. Dodatkowo pojawi się wyskakujące okno dialogowe z prośbą o podanie hasła firmy w celu zweryfikowania tożsamości użytkownika. Jeśli nazwa firmy nie istnieje w bazie danych, w oknie dialogowym pojawi się pytanie o nowe hasło firmy. Po rejestracji wyskakująca wiadomość informuje użytkownika, że proces się powiódł. Następnie użytkownik może przejść do logowania. W przypadku wprowadzenia nieprawidłowych danych uwierzytelniających, użytkownik zostanie o tym powiadomiony wyskakującym komunikatem. Po pomyślnym zalogowaniu pojawia się komunikat powitalny, a użytkownik może wybrać jeden z dwóch trybów: Kokpit i Wyniki
Kabina pilota
Ten tryb służy do pilotowania drona i uzyskiwania danych w czasie rzeczywistym. FPV z kamery pokładowej jest transmitowany na żywo. Informacje o locie obejmują aktualną długość i szerokość geograficzną oraz wysokość. Stężenia zanieczyszczeń powietrza w czasie rzeczywistym są wyświetlane w aplikacji. Jeśli określony parametr przekroczy zdefiniowany próg, pojawi się na czerwono, sygnalizując alert. Za każdym razem, gdy zostanie naciśnięty przycisk "Aktywuj", wszystkie dane, w tym data i godzina, zostaną przesłane na serwer ze stałą szybkością. Na przykład stałą stawkę można ustawić na jeden wpis na 5 s. Jeśli użytkownik naciśnie przycisk pokazujący "Powietrze", tryb podrzędny zostanie zmieniony, czyli w tym przypadku na podtryb monitorowania wody. W podtrybie monitorowania wody wyświetlane są wartości EC i mętności wody.
Wyniki monitorowania
W przypadku wybrania trybu wyników użytkownik zostanie poproszony o wybranie między wynikami monitorowania powietrza a wynikami monitorowania wody. W obu przypadkach zostaną pokazane interaktywne wykresy zmieniające się w czasie, z graficzną prezentacją nasilenia zanieczyszczeń w skali kolorów. Istnieją również widoki map, które pokazują punkty geograficzne, w których dokonano odczytów wraz z odpowiednimi odczytami. Użytkownik może usunąć wynik, dotykając czerwonego przycisku usuwania
Wniosek
Projekt Dragonfly jest dobrodziejstwem dla prac związanych z monitoringiem środowiska. Oferuje tanią, bezpieczną i wygodną metodę monitorowania jakości powietrza i wody.
Ulepszenie round-robin poprzez algorytm dostosowany do obciążenia i informujący o obciążeniu w równoległej aplikacji serwera bazy danych
Przemysł 4.0 stał się ostatnio ważnym tematem w kontekście tworzenia oprogramowania. Ta oparta na standardach strategia integruje systemy fizyczne, Internet Rzeczy i Internet Usług w celu rozszerzenia możliwości procesu tworzenia oprogramowania. Chociaż wielu ekspertów ds. rozwoju oprogramowania przedstawiło zalety różnych modeli i podejść do tworzenia oprogramowania, tworzenie oprogramowania odnosi się do architektury, która pozwala na prawidłową implementację aplikacji Przemysłu 4.0 przy użyciu modelu podejścia równoważenia obciążenia (LBAM 4.0). Niniejsze badanie ujawnia podstawowe cechy, które umożliwiają modernizację oprogramowania, aby stało się aplikacjami Przemysłu 4.0. W szczególności opracowano i wdrożono inteligentny system oprogramowania oparty na podejściu równoważenia obciążenia przy użyciu równych i nierównych możliwości przetwarzania klastrów. Aby ocenić wydajność LBAM 4.0, implementację przeprowadzono na klastrze z równymi i nierównymi węzłami przy użyciu algorytmu round-robin. Odkryto, że działanie algorytmu jest dość dobre, gdy węzły mają równe pojemności, ale bardzo słabe, gdy pojemności węzłów nie są równe. Algorytm dostosowany do obciążenia i informowany o obciążeniu został wykorzystany do poprawy najgorszego przypadku algorytmu round-robin, aby zapobiec najgorszym sytuacjom używania węzłów o różnych pojemnościach, których wyniki wykazały znaczną poprawę.
Wstęp
Przemysł 4.0 to intensywna pod względem informacyjnym transformacja produkcji (i powiązanych branż) w połączonym środowisku danych, ludzi, procesów, usług, systemów, aktywów przemysłowych obsługujących Internet rzeczy (IoT) z generowaniem, wykorzystaniem i wykorzystaniem praktycznych dane i informacje jako sposób i środek realizacji inteligentnego przemysłu, ekosystemów innowacji przemysłowych i współpracy. Aby zrozumieć Przemysł 4.0, konieczne jest zobaczenie pełnego łańcucha wartości, który obejmuje dostawców oraz pochodzenie materiałów i komponentów potrzebnych do różnych form rozwoju oprogramowania. Przemysł 4.0 jest obecnie uważany za kluczowy element łańcucha wartości i kluczowy element rozwoju technologicznego, tworzenia miejsc pracy i stabilności gospodarczej kraju. Tradycyjne kraje uprzemysłowione przyjęły wiodącą rolę w czwartej rewolucji przemysłowej i przyjęły Przemysł 4.0 jako strategię sprostania nowym wymaganiom na światowym rynku i pozycjonować się bardziej konkurencyjnie w stosunku do łączących się krajów. Strategia ta została zaplanowana, aby zaoferować nowy potencjał branży produkcyjnej, taki jak spełnienie indywidualnych wymagań klientów, optymalizacja podejmowania decyzji i dodanie nowych mocy produkcyjnych. Dobrze uzasadnioną definicję Przemysłu 4.0 przedstawia Juan jako "Przemysł 4.0 to zbiorcze określenie technologii i koncepcji organizacji łańcucha wartości. W ramach modułowych inteligentnych fabryk przemysłu 4.0 systemy cyberfizyczne (CPS) monitorują procesy fizyczne, tworzą wirtualną kopię świata fizycznego i podejmują zdecentralizowane decyzje. W Internecie Rzeczy CPS komunikuje się i współpracuje ze sobą i ludźmi w czasie rzeczywistym. Poprzez IoS (Internet of Services) zarówno wewnętrzne, jak i międzyorganizacyjne są oferowane i wykorzystywane przez uczestników łańcucha wartości." Zgodnie z przedstawioną definicją na tym tle powstały podstawowe technologie Przemysłu 4.0 i opracowano model równoważenia obciążenia (LBAM 4.0) w celu realizacji nowych usług i wydajnych modeli biznesowych w tworzeniu oprogramowania.
Zastosowanie LBAM 4.0
Jednym z problemów związanych z możliwościami klastrowania w MySQL jest to, że nie zapewnia on żadnych środków do dystrybucji obciążenia zapytań/transakcji w klastrze. Prowadzi to do skrócenia czasu odpowiedzi na zapytania wielu użytkowników. Dlatego obecne bazy danych muszą obsługiwać duże obciążenia przy jednoczesnym zapewnieniu wysokiej dostępności. Często stosowanym rozwiązaniem do sprostania tym wymaganiom jest klaster. Równoważenie obciążenia to technika (zazwyczaj wykonywana przez systemy równoważenia obciążenia) w celu rozłożenia pracy między co najmniej dwa komputery, łącza sieciowe, procesor, dyski twarde lub inne zasoby w celu uzyskania optymalnego wykorzystania zasobów, przepustowości lub czasu odpowiedzi. Używanie wielu komponentów z równoważeniem obciążenia zamiast pojedynczego komponentu może zwiększyć niezawodność. Usługa równoważenia w ostatnich dniach jest zwykle świadczona przez dedykowane urządzenie sprzętowe (takie jak przełącznik wielowarstwowy). Technika ta jest powszechnie stosowana do pośredniczenia w komunikacji wewnętrznej w klastrach komputerowych, zwłaszcza klastrach o wysokiej dostępności. Schneider i Dewitt stwierdzili, że dystrybucja obciążenia jest zwykle obsługiwana przez load balancer. Load balancer wybiera konkretny węzeł, dla którego ma zostać wykonane zadanie. Celem modułu równoważenia obciążenia jest wyrównanie obciążenia na wszystkich węzłach, aby uniknąć wąskich gardeł i osiągnąć maksymalną przepustowość. Niektóre systemy równoważenia obciążenia ślepo podążają za określonym wzorcem, aby osiągnąć ten cel, a inne oceniają informacje uzyskane z węzłów i na tym opierają swoją decyzję. To badanie koncentruje się na opracowaniu systemu równoważenia obciążenia do dystrybucji obciążeń. Celem naszego algorytmu równoważenia obciążenia jest zmniejszenie całkowitej liczby ciężkich węzłów w systemie poprzez rozłożenie obciążenia między węzły. Aby ocenić wydajność naszego systemu równoważenia obciążenia, wykonaliśmy implementację na równych i nierównych węzłach przy użyciu algorytmu round-robin. Odkryto, że wydajność algorytmu jest dość dobra, gdy węzły mają jednakową pojemność, ale bardzo słabą przy nierównych pojemnościach. Aby poprawić najgorszy przypadek roundrobin, algorytm dostosowany do obciążenia - poinformowany o obciążeniu został połączony jako środek zapobiegający najgorszym sytuacjom korzystania z węzłów o różnych przepustowościach. Na podstawie wyników ten cel został w dużej mierze osiągnięty. Jądro Linuksa udostępnia sposoby wykrywania bieżącego obciążenia procesora w węźle za pomocą pliku/proc/loadavg. Podczas korzystania z LAMP dane są przechwytywane przez ekran. Podczas korzystania z WAMP za pośrednictwem MySQL dane są pobierane za pomocą "Pokaż polecenie listy procesów". W tej pracy obie platformy zostały użyte zamiennie.
System baz danych klastrów
Klaster to grupa wysoce połączonych ze sobą serwerów sprzętowych, w których znajdują się bazy danych. Historycznie serwer w klastrze nazywany jest węzłem. Klastry zapewniają wysoką dostępność, umożliwiając przejrzyste przełączanie awaryjne w przypadku awarii węzła. Klastry zapewniają również sposób dystrybucji obciążenia, ponieważ żądania mogą być obsługiwane w dowolnym z węzłów klastra. Shivaratri argumentował, że praca jest pracą, którą należy wykonać na klastrze. W kontekście baz danych jest to zapytanie/transakcja. Zadanie jest generowane na komputerze klienckim i wysyłane przez sieć do węzła, który przetwarza zadanie. Węzeł następnie zwraca wynik do klienta po wykonaniu zadania. W bazach danych komunikacja między węzłem a klientem odbywa się zwykle za pośrednictwem połączenia TCP. TCP to protokół, w którym wiadomości są dostarczane w porządku i bez utraty danych. Aby tak się stało, dwa końce komunikacji muszą przejść przez fazę konfiguracji. Z tego powodu połączenie TCP jest zawsze między maszynami (tzw. unicast). Innym szczegółem jest to, że TCP nie jest zorientowany na pakiety. Casavant stwierdził, że niektóre algorytmy planowania wymagają informacji o poszczególnych węzłach. Informacje muszą ostatecznie pochodzić z każdego węzła w klastrze. Również informacje muszą być transportowane z węzłów do algorytmu szeregowania. Można założyć, że klaster i klienci komunikują się poprzez sieć IP. Ponadto można również założyć, że węzły znajdują się w tej samej sieci fizycznej, ale niekoniecznie jest to prawdą w przypadku klientów.
Metodologia
W celu wdrożenia LBAM 4.0 poprzez koncepcję Przemysłu 4.0 w procesie tworzenia oprogramowania, zaprojektowano materiały szkoleniowe. Projektowanie kursów internetowych to nie tylko pisanie serii stron, łączenie ich ze sobą i prezentowanie jako kursu. Należało opracować dobrą i wydajną strategię projektowania, tak aby uczestnicy uzyskali jak największe korzyści z instrukcji przy pomocy technologii. Przed faktycznym rozwojem modułu, najpierw stworzono ogólną strukturę modułu. Kluczowe tematy zostały zidentyfikowane z uwzględnieniem wymagań kursu, ucznia i nauczyciela . Projekt oprogramowania szkoleniowego systemu wirtualnego uczenia się został oparty na wewnętrznym projekcie oprogramowania szkoleniowego. Keane i Monaghan zasugerowali, że wewnętrzny projekt oprogramowania szkoleniowego składa się z
1. Doboru strategii instruktażowej w celu instruowania ucznia w zdobywaniu określonej wiedzy i umiejętności.
2. Umożliwienie konserwacji, rozbudowy i ponownego wykorzystania oprogramowania szkoleniowego. Ta sekcja wykorzystuje techniki projektowania oprogramowania do projektowania proponowanego oprogramowania szkoleniowego. Zaprojektowana technika została oparta na metodzie Object Oriented Analysis and Design oraz Rational Unified Process (RUP), które są drogowskazami do tworzenia aplikacji przy użyciu narzędzi Unified Modeling Language (UML). Wykorzystano narzędzia UML do uchwycenia wymagań użytkownika dotyczących oprogramowania szkoleniowego, projektowania logicznego i koncepcyjnego oraz implementacji oprogramowania szkoleniowego. Diagram klas w przedstawia podstawowe komponenty i ich interakcje do realizacji wirtualnego systemu uczenia się.
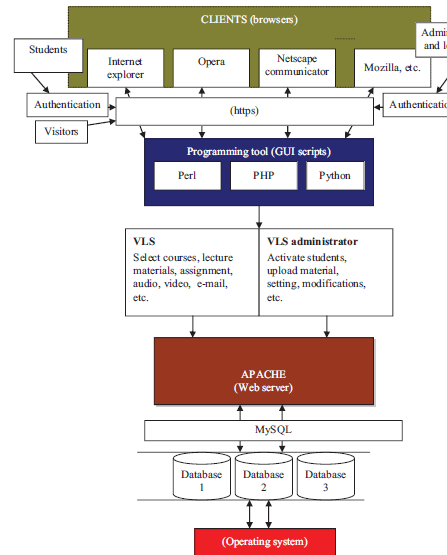
Te podstawowe elementy to:
• Warstwa klienta
• Skrypty PHP implementujące warstwę wirtualnego systemu nauczania (oprogramowania pośredniczącego)
• Warstwa serwera WWW przy użyciu Apache
• Warstwa relacyjnej bazy danych przy użyciu MySQL
• Warstwa systemu operacyjnego w systemie Linux.
Warstwa klienta: Aplikacja napisana z użyciem MySQL i PHP wykorzystuje przeglądarkę internetową jako interfejs dla klienta. Klienci mają swobodę korzystania z różnych przeglądarek w celu uzyskania dostępu do systemu. W systemie wirtualnego uczenia się wszystkie żądania są renderowane w przeglądarce przez klientów w warstwie klienta. Gdy takie żądania są renderowane, przechodzi do następnej warstwy przetwarzania w systemie wirtualnego uczenia się poprzez przechwycenie skryptów PHP.
Skrypty PHP implementujące warstwę wirtualnego systemu uczenia się (middleware): Skrypty PHP należą do klasy języków znanych jako middleware. Skrypty te ściśle współpracują z przeglądarką (warstwą klienta) i są przetwarzane na serwerze sieciowym (warstwie) w celu ustanowienia połączenia między nimi. Interpretują żądania wysyłane od klientów za pośrednictwem sieci lokalnej (LAN) lub World Wide Web (WWW), przetwarzają te żądania, a następnie wskazują warstwie serwera WWW dokładnie, co ma służyć przeglądarce klienta. W aplikacji systemu wirtualnego uczenia się, po wyrenderowaniu żądania do przeglądarki, oprogramowanie iddleware uruchamiające aplikację (skrypty PHP) wykonuje pewien poziom uwierzytelnienia, jak pokazano na rysunku 23.5 (schemat aktywności), aby określić, czy klient jest administratorem, czy zwykłym użytkownikiem zanim takie żądania będą mogły uzyskać dostęp do serwera WWW.
Warstwa serwera WWW korzystająca z Apache: Serwer WWW ma dość prostą pracę. Znajduje się tam, działa na wierzchu systemu operacyjnego i nawiązuje połączenie z relacyjną warstwą bazy danych, nasłuchuje żądań, które ktoś w przeglądarce internetowej może wysyłać za pośrednictwem warstwy oprogramowania pośredniczącego, odpowiada na te żądania i podaje odpowiednie zdigitalizowane materiały, które zostały zapisane w racjonalna baza danych (MySQL) poprzez odpowiednie strony internetowe. Apache w tym przypadku służy jako serwerowe narzędzie do tworzenia aplikacji dla wirtualnego systemu nauczania. Wykonuje pracę komunikacji przeglądarki i odpowiada na te żądania potrzebne z narzędzia aplikacji bazy danych (MySQL).
Warstwa relacyjnej bazy danych wykorzystująca MySQL: Relacyjna baza danych przechowuje wszelkie informacje wymagane przez aplikację. MySQL zapewnia świetny sposób przechowywania i uzyskiwania dostępu do złożonych informacji w relacyjnej bazie danych. W systemie wirtualnego uczenia się zdigitalizowane materiały szkoleniowe są przechowywane w relacyjnej bazie danych MySQL, która współdziała z serwerem WWW aplikacji, aby umożliwić serwerowi odpowiadanie na te żądania i serwowanie odpowiednich stron internetowych na żądanie klienta.
Warstwa systemu operacyjnego przy użyciu Linuksa: W systemie wirtualnego uczenia się wszystkie aplikacje działają na wierzchu systemu operacyjnego (Linux), aby obsłużyć i wykonać pewną integrację między językiem programowania a serwerem WWW. Rysunek przedstawia schemat blokowy konfiguracji wirtualnego systemu nauczania.
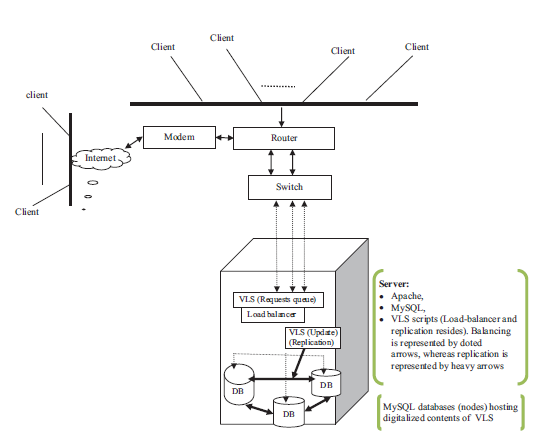
Strukturę systemu podsumowują następujące warstwy opisowe:
1. Warstwa klienta: Można to nazwać warstwą interfejsu użytkownika. Klienci uzyskują dostęp do wirtualnego systemu uczenia się za pośrednictwem tej warstwy za pomocą odpowiednich przeglądarek. Wszyscy klienci wysyłają żądania transakcji zapytania, które mogą być wczytane do aplikacji systemowej na tym poziomie za pośrednictwem sieci LAN lub WWW.
2. Warstwa transmisyjna: Warstwa transmisyjna odpowiada za komunikację. Przekazuje różne żądania transakcji składane przez klientów w warstwie klienta do warstwy maszyny serwera WWW. Wszystkie żądania transakcji klientów są przechwytywane przez aplikację i przekazywane do warstwy maszyny serwera WWW w celu przetworzenia przez skrypty wdrażające system wirtualnej nauki, a także dostarczające klientom informacje zwrotne na temat żądań. Komponenty warstwy transmisyjnej obejmują modem, router, przełącznik i system okablowania.
3. Warstwa komputera serwera sieci Web: Można to nazwać warstwą aplikacji domeny. Służy to jako skrzynka logiczna, w której wszystkie przesłane żądania klientów otrzymują racjonalną decyzję. Warstwa ta jest domeną, w której działa system wirtualnego uczenia się oraz zarządzania trwałymi danymi, globalnym przepływem kontroli, polityką kontroli dostępu i obsługą warunków. Maszyna serwera WWW obsługuje skrypty Apache, MySQL, VLS (zamieszkuje system równoważenia obciążenia i replikację). Równoważenie jest reprezentowane przez strzałki z kropką, podczas gdy replikacja jest reprezentowana przez ciężkie strzały.
Eksperymentowanie
Wymagania sprzętowe i programowe dla modelu podejścia równoważenia obciążenia. Istnieje wiele możliwych środowisk, w których można przetestować system. System został przetestowany w dwóch różnych środowiskach. System został przetestowany w środowisku, w którym możliwości serwerów są
1. Równe węzły lub ściśle powiązane możliwościami
2. Nierówne możliwości węzłów.
1. Równe możliwości węzłów
Wymagania sprzętowe: Pierwszym z nich jest sytuacja, w której dwa węzły są ściśle powiązane pod względem możliwości. Konfiguracja ma dwa 400 GHz Pentium III i 126 MB pamięci RAM. Każdy klient używał podwójnego Pentium IV z pamięcią 2,0 GHz i 1 G z interfejsem sieciowym 1 Gbit. Cała konfiguracja jest połączona za pośrednictwem 8-portowego przełącznika 10/100 Mb/s.
Wymagania programowe: Mamy również Apache/2.2.4 (win32)-serwer WWW 5.2.3, MySQL 5.0.41, Phpmyadmin 2.10.1. Serwer proxy, procesor HP Intel Pentium 4 3,4 MHz - z systemem Linux.
2. Nierówne możliwości węzłów
Druga konfiguracja została połączona z pierwszą konfiguracją podcz
as eksperymentu. Węzeł to Pentium III 700 MHz z 256 Mb pamięci.
Opis algorytmu
Każdy algorytm planowania ma swoje zalety i wady. To, który z nich działa najlepiej, zależy od wielu czynników. Round-robin i ważone round-robin są świetne, gdy zapytania są podobne pod względem złożoności . Dennis i Klaus wykorzystali C++ do demonstracji swojego algorytmu i opracowanych założeń. W tym badaniu eksperymentowaliśmy roundrobin w środowisku aplikacji internetowych przy użyciu translacji i implementacji algorytmu PHP. Zaobserwowaliśmy wydajność wirtualnego systemu uczenia się pod względem równoważenia żądań w klastrze, gdy przemieszcza się on wokół klastra.
Algorytm round-robin
Równoważenie obciążenia w C++
v
1: Input: A list of nodes (nodes)
2: Iterator into nodes (next_node)
3: Output: The node to use
4: GETNEXTNODE()
5: Node *result = next_node;
6: next_node??;
7: if (next_node ?? nodes.end()) {
8: next_node ? nodes.begin();
9: }
10: Return result;
Tłumaczenie algorytmu round-robin na algorytm PHP
< ?php
1: Input: Lista węzłów (węzłów) //Wiersze 1, 2, 3 to komentarze lub uwagi, które mogą być użyte do wyjaśnienia pewnych pojęć w treści programu. Mogą to być opisy zmiennych, sprzątanie, co robi program itp. Jest to bardzo opcjonalne
2: Iterator into nodes (next_node)
3: Output : węzeł do użycia
4: function getNextNode() // to jest funkcja, która nawiązuje połączenie z dostępnym węzłem
5: $next_node = $node * $result; // zmienna "result" jest deklaracją wskaźnika typu "Node", inicjowaną do "next_node"
6: $next_node++; // Węzeł jest zwiększany, gdy wskaźnik przesuwa się do następnego węzła
7: if ($next_node = = $node.end()) // To jest test sprawdzający, czy jest dostępny węzeł do przejęcia lub czy osiągnął on koniec
8: $next_node==$node.reset(); // Oznacza to z interpretacji powyższego warunku, jeśli osiągnął koniec, ustaw wskaźnik na początek{
9: }
10: echo $result; // pokaż lub wypisz ostateczną liczbę wszystkich węzłów użytych w operacji, jest to opcjonalne
• >
Implementacja (PHP, który jest wyciągiem z aplikacji i programu bazowego serwera WWW)
• Przekrocz wszystkie węzły z ustawionymi parametrami w określonym czasie
• < ?php
• /*
• Funkcja do obsługi połączenia
• */
• function Connect_server()
• {
• $node1 ? "122.10.1.2"; //Node 1 ip address
• $username1 ? "username";
• $password1 ? "password";
• //Node 2
• $node2 ? "122.10.1.3"; //Node 2 ip address
• $username2 ? "username2";
• $password2 ? "password2";
• //Node 3
• $node3 = "122.10.1.4"; //Node 3 ip address
• $username3 = "username3";
• $password3 = "password3";
• // connection timeout
• $timeout ? 5; // timeout in seconds
• }
• .
• .
• .
• .
• ? ? >
Ten algorytm jest bardzo prosty. Jednak, jak widać na poniższej wydajności, algorytm może być skuteczny tylko wtedy, gdy:
1. Węzły mają identyczną pojemność. W przeciwnym razie wydajność spadnie do szybkości najwolniejszego węzła w klastrze.
2. Co najmniej dwa połączenia klientów nie mogą być uruchamiane w tym samym czasie. Jeśli tak, wybrany węzeł będzie taki sam, ponieważ kolejność węzłów pobranych z klastra jest za każdym razem taka sama.
3. Zadania muszą być podobne, aby osiągnąć optymalny rozkład obciążenia między węzłami. Jeśli pojedynczy węzeł jest bardziej obciążony niż pozostałe, stanie się wąskim gardłem systemu. To w dużym stopniu potwierdza założenie Dennisa (2003).
Teraz myślimy o równoważeniu węzła o nierównej przepustowości poprzez wprowadzenie dostosowanego obciążenia - algorytm informujący o obciążeniu, że byliśmy w stanie opracować algorytm round-robin do dystrybucji obciążeń między węzłami, ale z wyjątkiem węzłów o równej przepustowości. Sposobem na rozwiązanie problemu byłby losowy wybór pomiędzy węzłami o najmniejszym lub najmniejszym obciążeniu. W ten sposób zadania zostaną równomiernie rozłożone między najmniej obciążone węzły. Implementacja tej pracy polega na tym, że równoważnik okresowo sonduje węzły w miarę napływania zapytań lub wykonuje operację wyszukiwania, aby znaleźć węzeł, który jest ciężki lub lekki, a następnie transfer może mieć miejsce między dwoma węzłami.
Algorytm poinformowany o obciążeniu dostosowanym do obciążenia
Obciążenie poinformowane w C++ przejęte z Job Informed
1: Input: A list of nodes (orig_nodes)
2: ONLOADUPDATE()
3: token_tot = 0;
4: active_jobs_tot = 0;
5: for (iterator it = orig_nodes.begin();
It ! = orig_nodes.end(); ??it) {
6: token_tot ?? it.original_token_count;
7: active_jobs_tot += it.active_jobs;
8: }
9: nodes_expired.clear();
10: nodes.clear();
11: for (iterator it = orig_nodes.begin();
it != orig_nodes.end(); ??it) {
12: it.tokens =floor((it.original_token_count/token_tot -
it.active_jobs/active_jobs_tot) * active_jobs_tot);
13: if (it.tokens <= 0) {
14: it.tokens += it.original_token_count;
15: if (it.tokens <=0) {
16: it.tokens = 1
17: }
18: nodes_expired.push_back(it);
19: } else {
20: nodes.push_back(it);
21: }
22: }
23: GETNEXTNODE()
24: Return weightedRoundRobin.GetNextNode();
Tłumaczenie algorytmu informującego o dopasowanym obciążeniu na algorytm PHP
< ?php
1: INPUT: lista węzłów (orig_nodes) // Lista węzłów w klastrze
2: ONLOADUPDATE() // funkcja onloadUpdate()
3: $token_tot=0; // zapytania są pobierane jako dane wejściowe i rozdzielane na części i przechowywane w tej zmiennej
4: $active_jobs_tot=0; // aktywne zapytania są pobierane jako dane wejściowe i rozdzielane na części i przechowywane w tej zmiennej. W pierwszej instancji inicjowane jest zero
5: for ($It=$orig_nodes.reset(); $It!=$orig_nodes.end(); $It++){// ciało pętli ustawiające licznik "it" typu iterator, aby zaczynał się od orig_nodes.begin. // Kontynuuj wykonywanie, dopóki nie jest równe orig_nodes.end() i kroku 1. // Iterator zadeklarowany jako ?¨t jest jak wskaźnik, lokalizujący jeden element w kontenerze (węźle) podczas przechodzenia
6: $token_tot += $original_token_count; // odpowiednik zwiększenia oryginalnej zmiennej o oryginalną lub bieżącą zawartość. // Ta instrukcja gromadzi wszystkie tokeny wykonane w każdym węźle
7: $active_jobs_tot += $active_jobs; // odpowiednik zwiększenia oryginalnej zmiennej o oryginalną lub bieżącą zawartość. // ta instrukcja gromadzi wszystkie aktywne tokeny aktualnie wykonywane w każdym węźle
8: }
9: unset($node_expired); // wywołanie metody "clear" wygaśnie węzeł. // wywołanie metody "wyczyść" obiekt węzła. Wyczyść lub usuń całą zawartość pamięci w gotowości
10: unset($nodes); // wywołanie metody "clear" wygaśnie węzeł. // wywołanie metody "wyczyść" obiekt węzła. Wyczyść pamięć w gotowości do działania
11: for ($It=orig_nodes.reset(); $It!=orig_nodes.end(); $It++){ // treść pętli, ustawianie licznika "it" typu iterator, aby zaczynał się od orig_nodes.begin(). // Kontynuuj wykonywanie, dopóki nie jest równe orig_nodes.end() i kroku 1. Iterator przechodzi przez węzły od pierwszego węzła do końca klastra. Musi być zadeklarowana w "pętli for"
12: $tokens=$floor(($original_token_count/$token_tot - $active_jobs/$active_ jobs_tot) * $active_jobs_tot); //. Jest to wyrażenie arytmetyczne obliczające pojemność zadania, gdy iterator odwiedza każdy węzeł, ma możliwość określenia, czy w bieżącej pozycji węzła iteratora rzeczywiście znajdują się elementy, a następnie decydowania o statusie węzła za pomocą wyrażenia arytmetycznego, aby wiedzieć, czy węzeł jest przeładowany. Wyrażenie "podłoga" oznacza, że weź najniższą zwróconą wartość z obliczeń i zapisz ją w zmiennej it.token
13: if ($tokens<=0) { // instrukcja warunkowa, testowanie if "token"< = 0. // Test, czy wartość tokena iteratora jest mniejsza lub równa 0
14: $tokens +=original_token_count; // dodaj original_token_count do tokenów akumulatywnie ze wszystkimi zapytaniami aktualnie uruchomionymi w trybie do zmiennej Iteratora
15: if ($tokens<=0){// przetestuj ponownie, aby sprawdzić, czy "token" jest < = 0. Przetestuj ponownie, aby sprawdzić, czy wartość tokena iteratora jest nadal mniejsza lub równa zero 0
16: it.token = 1; : nodes.reset();}//Utrzymaj połączenie i przekaż żądanie
17: }
18: $nodes_expired.reset(); // oznacza to, że węzeł w klastrze jest przeładowany lub zajęty. Zabij połączenie lub kość połączenia, jeśli to prawda; oznacza to, że węzeł jest przeciążony, spróbuj następnego połączenia
19: } else {
20: $nodes_push_back() // kontynuacja połączenia
21: }
22: }
23: GETNEXTNODE() // GetNextConnection w klastrze. To jest następny
połączenie, które jest wywoływane, jeśli którykolwiek węzeł wygasł lub jest przeciążony
? >
Również w algorytmie C++ obliczenie Zt.original_token_count/token_tot - it.active_jobs/active_jobs_tot to procent pojemności węzła w klastrze minus procent obciążenia węzła. Wynikiem jest odległość od optymalnego obciążenia dla węzła. Mnożąc odległość przez liczbę aktywnych zadań, otrzymujemy odległość w zadaniach. Jeśli wynikowa liczba jest ujemna, węzeł jest bardziej obciążony niż średni węzeł
Implementacja (wyciąg programu PHP)
Ta funkcja obsłuży połączenia, ponieważ PHP nie może "rozmawiać" bezpośrednio z procesorami, jak C/C++. Musimy sprawdzić połączenia z każdym z WĘZŁÓW MySQL, a jeśli nie zostanie zwrócone żadne połączenie, oznacza to, że serwer jest zajęty, nie działa lub ma problem.
< ?php
• /*
• Function to Handle connection
• */
• function Connect_server()
• {
• $node1 ? "122.10.1.2"; //Node 1 ip address
• $username1 = "username";
• $password1 = "password";
• //Node 2
• $node2 ="122.10.1.3"; //Node 2 ip address
• $username2 ="username2";
• $password2 = "password2";
• //Node 3
• $node3 ? "122.10.1.4"; //Node 3 ip address
• $username3 = "username3";
• $password3 = "password3";
• // connection timeout
• $timeout = 15; // timeout in seconds
• if($fp = fsockopen($node1, 3306, &$errno, &$errstr, $timeout)){
• fclose($fp);
• return $link ? mysql_connect($node1, $username1, $password1);
• }
• //check server 2
• if($fp = fsockopen($node2, 3306, &$errno, &$errstr, $timeout)){
• fclose($fp);
• return $link = mysql_connect($snode2, $username2, $password2);
• }
• //check server 3
• if($fp = fsockopen($node3, 3306, &$errno, &$errstr, $timeout)){
• fclose($fp);
• return $link ? mysql_connect($node3, $username3, $password3);
• }
• }
• ? >
Przykładowe dane do systemu równoważenia obciążenia typu round-robin to liczba zapytań przesłanych przez klientów jako żądanie do bazy danych. Wdrożenie było ściśle oparte na zapytaniach wejściowych klientów. Do oceny wydajności systemu równoważenia obciążenia okrężnego wykorzystano liczbę zapytań w przedziale czasu. Celem całego naszego algorytmu równoważenia obciążenia jest zmniejszenie całkowitej liczby ciężkich węzłów w systemie poprzez rozłożenie obciążeń między węzły. Dane wyjściowe modułu równoważenia obciążenia przy użyciu metody round-robin: Aby ocenić wydajność naszego modułu równoważenia obciążenia, wykonaliśmy implementację na równych i nierównych węzłach przy użyciu algorytmu round-robin. Odkryliśmy, że wydajność algorytmu jest całkiem dobra, gdy węzły mają jednakową pojemność, ale bardzo słabą przy nierównych pojemnościach. Aby poprawić najgorszy przypadek algorytmu round-robin, połączono algorytm informowany o obciążeniu i obciążeniu, aby zapobiec najgorszym sytuacjom używania węzłów o różnych przepustowościach. Częścią celu tego badania było ulepszenie algorytmu round-robin, tak aby zrównoważył nierówne przepustowości węzłów. Dlatego, aby to osiągnąć, algorytm informujący o dopasowanym obciążeniu został zintegrowany z algorytmem round-robin. Oznacza to, że system równoważenia okresowo sonduje węzły w miarę napływania zapytań lub wykonywania operacji wyszukiwania, aby znaleźć węzeł, który jest ciężki lub lekki, a następnie transfer może mieć miejsce między dwoma lub większą liczbą węzłów w klastrze. Problem można rozwiązać, wyświetlając liczbę aktywnych zadań na obciążeniu węzła. Przykładowe dane do systemu równoważenia obciążenia: Przykładowe dane do systemu równoważenia obciążenia to liczba zapytań przesłanych przez klientów jako żądanie do bazy danych. Celem całego algorytmu równoważenia obciążenia było zmniejszenie całkowitej liczby ciężkich węzłów w systemie poprzez rozłożenie obciążeń między węzły
Zalecenia
1. Dlatego zaleca się, aby pomysł polegania na wyższych możliwościach systemu lub dużym wyrafinowaniu sprzętu do równoważenia obciążenia został całkowicie wprowadzony w krajach rozwijających się, jeśli możemy zainwestować w inicjatywy dotyczące oprogramowania open source poprzez koncepcję technologii Przemysłu 4.0. Twórcy oprogramowania i badacze powinni uwzględnić koncepcję Przemysłu 4.0 w procesie rozwoju, aby zwiększyć elastyczność, solidność, niezawodność i kompatybilność oprogramowania.
2. Wdrożenie i osiągnięcie tego celu poprzez koncepcję Przemysłu 4.0 przeszło długą drogę w osiągnięciu celu obniżenia kosztów w naszym sprzęcie ICT, szczególnie w krajach o niskich dochodach. Dlatego kraje rozwijające się powinny inwestować w technologię Przemysłu 4.0 we wszystkich sektorach swojej gospodarki.
Wniosek
Jednym z głównych problemów związanych z możliwościami klastrowania w MySQL jest to, że nie zapewnia on żadnych środków na dystrybucję obciążeń transakcyjnych do węzłów. W tej chwili uzyskanie oprogramowania do równoważenia jest bardzo drogie; w większości przypadków organizacje korzystają ze sprzętu, który jest bardzo kosztowny. W ramach tej pracy zbadano istniejące algorytmy równoważenia obciążenia i przełożono je na kod oprogramowania dzięki koncepcji technologii Przemysłu 4.0, która została zintegrowana z systemem wirtualnego uczenia się, aby wspierać dystrybucję transakcji do różnych węzłów podczas operacji.
Przegląd sieci 5G i wyzwania
Sieć 5G staje się rzeczywistością i oczekuje się, że przyniesie mnóstwo nowych możliwości w różnych branżach wertykalnych. Operatorzy domagają się technologii sieciowych 5G. Powodem jest to, że usługi sieci 4G stają się nasycone, a przychody co roku spadają lub spadają. Oczekuje się, że 5G umożliwi dalszy wzrost gospodarczy i wszechobecną cyfryzację hiperpołączonego społeczeństwa, w którym wszyscy ludzie i urządzenia/rzeczy są wirtualnie połączone z siecią. 5G zapewni przedsiębiorstwom i konsumentom wiele nowych zastosowań, w tym aplikację wirtualnej rzeczywistości (VR), telemedycynę z wykorzystaniem ultra niezawodnej komunikacji oraz wielkoskalowy Internet rzeczy (IoT), taki jak inteligentne miasta. Dzięki rewolucji technologii 5G jest w stanie zapewnić niskie opóźnienia, dużą przepustowość, wysoką niezawodność i pojemność, a także zapewnia lepsze wrażenia użytkownika. Operator musi rozwinąć nową infrastrukturę sieciową (5G New Radio) lub zrestrukturyzować obecną infrastrukturę sieciową 4G w celu przyjęcia systemu 5G. Dlatego w tym rozdziale szczegółowo opisano podstawy sieci 5G pod względem kluczowych możliwości, przypadków użycia i struktury sieci. Ponadto w tym rozdziale omówiono również wdrożenie sieci 5Gnetwork, które ujawnia opcję wdrożenia dla architektur sieci niesamodzielnych (NSA) i autonomicznych (SA), specyfikację widma i kluczowe technologie 5G, takie jak MassiveMultiple Input Multiple Output (MIMO) oraz uplink i downlink Mechanizmy odsprzęgające (UL/DL). W tym rozdziale zawarto również kluczowe wyzwania sieci 5G, przed którymi stoją operatorzy na całym świecie. Przyszły cel komunikacji w sieci komórkowej 5G podczas przeprowadzki jest możliwy, co zapewnia cyfryzację każdej osobie, domu i organizacji, zapewniając w pełni połączony, inteligentny świat.
Przegląd sieci 5G
W ostatnich dziesięcioleciach całkowita liczba użytkowników Internetu dramatycznie wzrosła i osiągnęła 4,54 miliarda ponad 7,75 miliarda populacji ludzkiej w 2020 roku. Jednak technologie bezprzewodowe 4G nie są w stanie zapewnić wsparcia w przyszłości. Ruch danych w Internecie był wybuchowy. Poza tym istniejąca sieć 4G nie może również zapewnić natychmiastowych usług w chmurze, Internetu rzeczy (IoT) , ulepszonego Vehicle-to-Everything (eV2X) i dotykowego Internetu [3,4], biorąc pod uwagę jakość doświadczenia (QoE) użytkownicy mobilni. Te cechy stały się niezbędne dla przyszłych usług. Rozpoczęła się czwarta rewolucja przemysłowa (4IR) oparta na rewolucji cyfrowej, a piąta generacja komunikacji mobilnej (5G) stała się centralnym punktem badań i rozwoju w celu przezwyciężenia problemów 4G. Międzynarodowy Związek Telekomunikacyjny-Sektor komunikacji radiowej (ITU-R), Sojusz Sieci Mobilnych Nowej Generacji (NGMN) i Projekt Partnerski Trzeciej Generacji (3GPP) skoncentrowały swoje badania na usługach 5G i standaryzują wymagania techniczne. W Grupie Roboczej ITU-R (WP) 5D 5G określa się mianem International Mobile Telecommunications 2020 (IMT-2020). Sieć 5G, która jest w stanie zapewnić ogromną poprawę szybkości, zasięgu, efektywności energetycznej i niezawodności, całkowicie zastąpi obecną technologię 4G. Ogólne cele IMT-2020 zostały ustalone za pośrednictwem ITU-R M.2083. Tabela 24.1 pokazuje osiem parametrów, które są uważane za kluczowe możliwości IMT-2020. Oczekuje się, że szczytowa szybkość IMT-2020 dla ulepszonych mobilnych usług szerokopasmowych osiągnie 10 Gbit/s, aw pewnych warunkach i scenariuszach będzie obsługiwała do 20 Gbit/s, jak pokazano na Rysunku 24.1. IMT-2020 będzie obsługiwał różne szybkości przesyłania danych doświadczanych przez użytkownika, 100 Mbit/s jako minimalne wymaganie dla przypadków o dużym zasięgu, a w przypadku hotspotów szybkość przesyłania danych przez użytkownika może osiągnąć wyższe wartości około 1 Gbit/s. Jeśli chodzi o wydajność widma, oczekuje się, że IMT-2020 będzie trzykrotnie wyższy w porównaniu z zaawansowanym IMT. Gdy wydajność widma staje się wyższa, oczekuje się, że przepustowość obszaru osiągnie 10 Mbit/s/m2. IMT-2020 byłby w stanie zapewnić 1 ms opóźnienia bezprzewodowego i wysoką mobilność do 500 km/h przy akceptowalnej jakości usług (QoS) i obsługiwać gęstość połączeń do 106 na km2. Efektywność energetyczna sieci może poprawić się 100 razy w miarę wzrostu przewidywanej przepustowości.
Przypadki użycia sieci 5G
Szeroka gama możliwości byłaby ściśle powiązana z zamierzonymi różnymi scenariuszami użytkowania i aplikacjami dla IMT-2020. Różne kluczowe możliwości są uwzględniane w oparciu o scenariusze aplikacji 5G i wpływają na wydajność. Scenariusze użycia dla IMT-2020 można podzielić na trzy kategorie, którymi są:
• Ulepszone mobilne połączenie szerokopasmowe (eMBB)
- W scenariuszu eMBB, szczytowa szybkość transmisji danych, szybkość transmisji danych doświadczana przez użytkownika, efektywność energetyczna, przepustowość obszaru, mobilność i wydajność widma mają duże znaczenie dla poprawy postrzeganych doświadczeń użytkownika.
• Niezawodna komunikacja z małymi opóźnieniami (uRLLC)
- Opóźnienia i niezawodność mają największe znaczenie, ponieważ wszystko, co jest silnie ze sobą połączone, IoT i inne branże wertykalne spowodują powstanie dużej liczby bezprzewodowych sieci czujnikowych (WSN), stawiających wysokie wymagania dotyczące ilości dostępu do sieci i wydajności zużycia energii.
- Masywna komunikacja typu maszyny (mMTC)
- Wysoka gęstość połączeń i efektywność energetyczna sieci są potrzebne do obsługi ogromnej liczby urządzeń w sieci.
- Zautomatyzowane prowadzenie pojazdów, telemedycyna, inteligentne sieci i inne branże pionowe wymagają wysokiej niezawodności i niskich opóźnień.
Architektura sieci 5G
Globalna organizacja standardów komunikacji mobilnej 3GPP definiuje nową sieć rdzeniową, określaną jako 5G Core (5GC), a także nową technologię dostępu radiowego o nazwie 5G "New Radio" (NR). 3GPP podzieliło sieć 5G na dwie ścieżki, które są niesamodzielne (NSA) i samodzielne (SA). Operator telekomunikacyjny może zdecydować się na wdrożenie pełnej 5G SA, która zapewnia kompleksowe (E2E) doświadczenie 5G, lub na wdrożenie sieci 5G NSA, która może być uzupełniona i obsługiwana przez sieć 4G. W początkowej fazie 5G NSA wdraża komórki 5G ze wsparciem istniejącej sieci 4G. Architektura 5G NSA działa w strukturze master-slave, gdzie węzeł dostępowy 4G jest nadrzędnym, a węzeł dostępowy 5G jest podrzędnym. Komórki NR są łączone z komórkami radiowymi LTE przy użyciu podwójnej łączności (DC) w celu zapewnienia dostępu radiowego, a sieć rdzeniowa może być siecią 5GC lub Evolved Packet Core (EPC) w zależności od wyboru operatora. Operator, który chce wykorzystać istniejące wdrożenie 4G, będzie celował w ten scenariusz, który będzie w stanie połączyć zasoby radiowe NR i LTE z istniejącymi EPC i/lub umożliwi nowemu 5GC dostarczanie usług mobilnych 5G. Scenariusz NSA wymaga ścisłej współpracy z siecią dostępu radiowego LTE (RAN), a wrażenia użytkownika końcowego będą zależeć od zastosowanych technologii dostępu radiowego. Ze względu na strukturę master-slave, NSA jest bardziej ekonomiczny w porównaniu do sieci 5G SA. Jednak w końcowym stanie sieci wszyscy operatorzy będą dążyć do sieci 5G SA. Innymi słowy, operator w końcu przeniesie się do sieci w pełni 5G SA, chociaż jako punkt wyjścia wybierze opcję NSA. Sieć 5G SA odnosi się do posiadania niezależnej sieci 5G z nowym interfejsem lotniczym 5G, NR i 5GC. Oznacza to, że komórki radiowe NR lub rozwinięte LTE (eLTE) są wykorzystywane zarówno do płaszczyzn sterowania, jak i użytkownika. Niemniej jednak sieć SA będzie nadal współpracować z istniejącą siecią 4G/LTE, aby zapewnić ciągłość usług pomiędzy dwiema generacjami sieci. Opcja SA wdraża niezależną sieć przy użyciu normalnego przełączania międzypokoleniowego między 4G i 5G w celu zapewnienia ciągłości usług.
Wdrożenie sieci 5G
Opcje wdrażania dla NSA i SA
W przypadku scenariuszy SA i NSA 3GPP definiuje trzy warianty dla każdego scenariusza. Sieci EPC i 5GC zostały wprowadzone i zdefiniowane w 3GPP dla opcji wdrażania 5G dla NSA lub SA. SA obejmuje Opcję 1 wykorzystującą dostęp EPC i LTE eNB, Opcję 2 wykorzystującą dostęp 5GC i NR gNB oraz Opcję 5 wykorzystującą dostęp 5GC i LTE ng-eNB. NSA obejmuje Opcję 3 wykorzystującą EPC i LTE eNB działający jako master i NR en-gNB działający jako drugorzędny, Opcję 4 wykorzystującą 5GC i NR gNB działający jako master i LTE ng-eNB działający jako drugorzędny oraz Opcję 7 używającą 5GC i LTE ng-eNB działający jako główny i NR gNB działający jako drugorzędny. Wczesne opcje wdrażania 5G przyjmą opcję 3 NSA lub opcję 2 SA, ponieważ standaryzacja tych dwóch opcji została zakończona. Bezpośrednią ścieżką do 5G jest wdrożenie 5G NR przy użyciu 5GC w trybie SA, co jest pokazane jako Opcja 2. Sieć RAN składa się tylko z gNB (gNode B) i łączy się z 5GC. Opcja SA 2 nie ma wpływu na radio LTE, możliwości 5G może w pełni wykorzystać, co jest w stanie obsługiwać w różnych scenariuszach użytkowania dla eMBB, uRLLC i mMTC przez umożliwienie podziału sieci poprzez natywną architekturę opartą na usługach (SBA). SBA jest zaproponowany w 5GC, zdolny do zapewnienia sieci bezprecedensowej wydajności i elastyczności. SBA to system architektoniczny dla budownictwa oparty na drobnoziarnistej, interakcji luźno powiązanych i autonomicznych komponentów zwanych usługami. Kluczową funkcją sieciową (NF) SBA jest funkcja repozytorium sieciowego (NRF), która zapewnia rejestrację i wykrywanie usług NF, umożliwiając NF identyfikowanie odpowiednich usług w sobie nawzajem. Zasady SBA mają zastosowanie tylko do interfejsów między funkcjami Control Plane (CP) w ramach 5GC. Oddzielenie płaszczyzny sterowania i płaszczyzny użytkownika, oprócz dodania elastyczności w łączeniu użytkowników, ułatwia obsługę wielu technologii dostępowych, lepszą obsługę podziału sieci i przetwarzania brzegowego. 5GC oferuje również doskonałe funkcje dzielenia sieci E2E i QoS. Inną ścieżką do 5G w trybie NSA jest użycie EPC, w którym komórki radiowe NR są połączone z komórkami radiowymi LTE przy użyciu DC w celu zapewnienia dostępu radiowego, co jest pokazane jako Opcja 3 . EPC jest podstawowym elementem sieci 4G, który składa się z jednostki zarządzania mobilnością (MME), serwera abonenta domowego (HSC), bramy servingowej (S-GW), bramy PDN (P-GW) oraz funkcji zasad i zasad ładowania (PCRF). S-GW i P-GW obsługują zarówno płaszczyzny sterowania, jak i użytkownika, podczas gdy MME obsługuje tylko płaszczyznę sterowania. PCRF zapewnia zasady polityki i opłat. Control and User Plane Separation (CUPS), nowa funkcja, została wprowadzona w 3GPP Release 14. EPC jest w stanie zająć się limitami opóźnień, jeśli CUPS jest wdrożony, ale nie w inny sposób. CUPS obsługuje elastyczne wdrażanie płaszczyzny użytkownika bez rozszerzania lub ulepszania płaszczyzny sterowania. W przypadku chmury natywnej można osiągnąć prostszą konfigurację i prace konserwacyjne węzłów płaszczyzny użytkownika. Po wprowadzeniu Opcji 2 w trybie SA z wykorzystaniem 5GC i Opcji 3 w trybie NSA z wykorzystaniem EPC, porównanie opcji 5G NSA i SA.
Widmo sieci 5G
Większa przepustowość widma będzie obowiązkowa w celu wdrożenia sieci 5G (niż 4G) w celu spełnienia wymagań dotyczących dużej przepustowości, która jest w stanie zapewnić szybsze przesyłanie danych i lepsze wrażenia użytkownika. Sektor Standaryzacji ITU (ITU-T) odgrywa kluczową rolę w tworzeniu standardów technologii i architektur elementów przewodowych systemów 5G. Przeznaczono nowe, szersze pasma 5G, które obsługują rozmiary kanałów od 5 do 100 MHz w pasmach poniżej 6 GHz oraz rozmiary kanałów od 50 do 400 MHz w pasmach powyżej 24 GHz [9]. Pełne możliwości 5G będą realizowane poprzez szersze rozmiary kanałów w nowych pasmach 5G. W 3GPP zdefiniowano dwa rodzaje zakresów częstotliwości, przy czym zakres poniżej 6 GHz nazywa się FR1, a fala milimetrowa (mmWave) nazywa się FR2. Istnieją dwa oddzielne podejścia do wdrażania setek MHz nowego widma dla sieci 5G. Pierwsze podejście, określane jako pasmo poniżej 6 GHz, koncentruje się na widmie elektromagnetycznym (EM) poniżej 6 GHz, które znajduje się głównie w pasmach 3 i 4 GHz. Drugie podejście, określane jako mmWave, skupia się na części widma między 24 a 52,6 GHz. Przydział widma ma kluczowe znaczenie dla sukcesu 5G, ponieważ wybrane pasmo widma, czy to poniżej 6 GHz, czy mmWave, ma wpływ na prawie każdy inny aspekt rozwoju 5G. Rysunek
przedstawia pełny dostęp 5G. Na podstawie rysunku dostęp do pełnego spektrum 5G można podzielić na pasma podstawowe 5G i pasma uzupełniające 5G. Podstawowe pasma 5G, które przydzielają poniżej 6 GHz, mają kluczowe znaczenie dla obsługi większości scenariuszy użytkowania 5G na dużym obszarze. Pasmo podstawowe 5G można podzielić na dwie kategorie makro: niskie częstotliwości (poniżej 2 GHz) i średnie częstotliwości (2-6 GHz). Aby zapewnić dobry zasięg 5G NR, operatorzy będą musieli mieć pasmo widma w zakresie poniżej 6 GHz, aby wykorzystać jego właściwości propagacji sygnału na tych częstotliwościach, aby umożliwić 5G tworzenie bardzo dużych obszarów zasięgu i głęboką penetrację budynku . Niskie częstotliwości (poniżej 2 GHz) będą nadal niezbędne do rozszerzenia mobilnej łączności szerokopasmowej 5G na rozległe obszary i głębokie środowiska wewnętrzne; Scenariusze użycia mMTC i URLLC również znacznie skorzystają na rozszerzonym zasięgu niskich częstotliwości. Dostępne pasma niskich częstotliwości (np. 700, 800, 900, 1800 i 2100 MHz) mogą być wykorzystywane do współdzielenia widma łącza uplink (UL) LTE/NR w połączeniu z NR w paśmie C, aby umożliwić operatorom szybsze i oszczędniejsze wdrożenie pasma C. Średnie częstotliwości o zakresach 3300-4200 i 4400-5000 MHz (określane jako pasmo C) są odpowiednie, aby zapewnić najlepszy kompromis między pokryciem dużego obszaru a dobrą przepustowością. Zgodnie z planami uwolnienia z wielu krajów, pasmo 3300-3800 MHz będzie głównym pasmem 5G o największym potencjale globalnej harmonizacji w czasie. We wczesnym wdrażaniu 5G, co najmniej 100 MHz ciągłej przepustowości widma powinno być przypisane do każdej sieci 5G, aby obsługiwać doświadczoną przez użytkownika szybkość transmisji danych wynoszącą 100 Mb/s. Jeśli pasmo poniżej 6 GHz jest niedostępne, operatorzy będą musieli polegać na pasmach komplementarnych 5G powyżej 6 GHz. Wysokie częstotliwości (powyżej 6 GHz) okażą się niezbędne do zapewnienia dodatkowej pojemności i dostarczenia niezwykle wysokich szybkości transmisji danych, aby umożliwić zastosowania 5G eMBB. Pasma 24,25-27,5 i 37-43,5 GHz (nazywane pasmem mmWave) są traktowane priorytetowo w ramach trwających prac ITU-R w ramach przygotowań do Światowej Konferencji Radiokomunikacyjnej 2019 (WRC-19). Zaleca się, aby wszystkie kraje i regiony wspierały identyfikację tych dwóch pasm dla IMT podczas WRC-19. Powinna dążyć do ujednolicenia warunków technicznych wykorzystania tych częstotliwości w 5G. Na przykład pasmo 28 GHz to pasmo używane w wielu testach stacjonarnego dostępu bezprzewodowego (FWA) i wprowadzaniu na rynek komercyjny. Komórki radiowe działające w mmWave nadają się do tworzenia grubej warstwy pojemności tam, gdzie jest to potrzebne (hotspoty), a także do wielu scenariuszy korporacyjnych. We wczesnym wdrażaniu 5G zalecane jest co najmniej 800 MHz na sieć o ciągłym paśmie widma z wysokich częstotliwości. Jednak pasma mmWave nie nadają się do szerokiego pokrycia ze względu na słabą charakterystykę propagacji. Jakoś jest to dobra opcja dla hotspotu i lokalnego zasięgu 5G NR, a także oferuje dużą przepustowość sieci. Rysunek pokazuje szczegóły podejście częstotliwościowe dla widma 5G.

Technologia 5G i przepisy techniczne
Sieci i urządzenia 5G będą zawierać wiele nowych funkcji, wykorzystując najnowsze innowacje techniczne. Ogromne mechanizmy separacji wielu wejść i wielu wyjść (MIMO) i UL/downlink (DL) są w stanie zapewnić regulatorom możliwość dostosowania przepisów w celu bardziej wydajnego i elastycznego wykorzystania widma.
Massive MIMO
Massive MIMO to rozszerzenie MIMO. Wykracza poza dotychczasowe systemy, dodając liczne anteny do stacji bazowej (BS). Massive MIMO to kluczowa funkcja 5G, która implikuje MIMO i jest używana przez kombinacje wielu nadajników/odbiorników lub anten po obu stronach cyfrowych systemów komunikacyjnych. Wraz ze wzrostem liczby anten, zarówno sieć, jak i urządzenia mobilne wdrażają bardziej złożone projekty koordynujące operacje MIMO. Systemy MIMO wykorzystują trzy kluczowe koncepcje, które obejmują różnorodność przestrzenną, multipleksację przestrzenną i formowanie wiązki. Jedną z podstawowych zalet technologii MIMO jest różnorodność przestrzenna. Różnorodność ma na celu poprawę niezawodności systemu poprzez wysyłanie tych samych danych w różnych propagacjach, zarówno przestrzennych, jak i po ścieżkach. Multipleksowanie przestrzenne ma na celu jednoczesne przesyłanie wielu wiadomości bez komunikowania się ze sobą. Masywne MIMO wykorzystuje technikę kształtowania wiązki, aby skupić sygnały na każdym użytkowniku, zwiększając w ten sposób szybkość transmisji danych i zmniejszając opóźnienia. Beamforming to kolejna kluczowa technika bezprzewodowa, która wykorzystuje zaawansowane technologie antenowe zarówno na urządzeniach mobilnych, jak i na BS sieci w celu skupienia sygnału bezprzewodowego w określonym kierunku, zamiast nadawania na rozległy obszar. Formowanie wiązki 3D można utworzyć za pomocą ogromnej liczby elementów antenowych w massive MIMO system. Formowanie wiązki 3D wykorzystuje macierze antenowe na dużą skalę, które mogą kontrolować szerokość i pochylenie, zarówno pionowe, jak i poziome wiązki skierowane do użytkowników, zwiększając szybkość transmisji danych i pojemność dla wszystkich użytkowników. Massive MIMO jest kluczowym czynnikiem umożliwiającym niezwykle szybkie przesyłanie danych w sieci 5G i obiecuje podnieść potencjał sieci 5G na nowy poziom. Podstawowe korzyści płynące z ogromnego MIMO dla sieci i użytkowników końcowych można podsumować jako:
• Zwiększona przepustowość sieci
- Massive MIMO przyczynia się do zwiększenia przepustowości, po pierwsze, umożliwiając wdrożenie 5G NR w wyższym zakresie częstotliwości w zakresie poniżej 6 GHz (np. 3,5 GHz), a po drugie, stosując MU-MIMO, w którym wielu użytkowników jest obsługiwanych z tym samym czasem i zasobami częstotliwości.
• Lepszy zasięg
- Dzięki ogromnej technologii MIMO użytkownicy cieszą się bardziej jednolitym doświadczeniem w całej sieci, nawet na obrzeżach komórki. W związku z tym użytkownicy mogą spodziewać się usług o wysokiej szybkości transmisji danych niemal wszędzie. Co więcej, kształtowanie wiązki 3D umożliwia dynamiczne pokrycie wymagane dla poruszających się użytkowników (np. użytkowników podróżujących samochodami lub podłączonymi samochodami) i dostosowuje pokrycie do lokalizacji użytkownika, nawet w miejscach, słaby zasięg sieci.
Chociaż Massive MIMO zapewnia wiele korzyści dla sieci 5G, wdrożenie Massive MIMO nadal musi uwzględniać aspekty wymagań dotyczących wydajności, wymagań instalacyjnych i oszczędności całkowitych kosztów posiadania (TCO). Najbardziej opłacalna konfiguracja, 64T, 32T lub 16T, może być różna dla różnych scenariuszy wdrażania, odpowiednio ze względu na różne korzyści w zakresie wydajności w scenariuszach. W gęsto zabudowanych scenariuszach wieżowców 64T lub 32T mogą mieć przewagę pod względem wydajności, ponieważ formowanie wiązki 2D przyniesie korzyści w porównaniu z formowaniem wiązki 1D, a zatem może być bardziej opłacalne. W obszarach miejskich i podmiejskich rozproszenie użytkownika w wymiarze pionowym jest zwykle tak małe, że pionowe formowanie wiązki nie przyniesie żadnych istotnych korzyści. Dlatego 16T będzie miał podobną wydajność jak 64T lub 32T w wielu takich scenariuszach. Poza tym rozwiązanie 2T2R/4T4R/8T8R można również uznać za podstawową konfigurację do wdrożenia 5G. Wdrożenie 16T16R/32T32R/64T64R spełni wymagania dotyczące pojemności w tych lokalizacjach, które wymagają zwiększenia pojemności, są mocno obciążone.
Mechanizmy zwiększania zasięgu
Obecnie pasmo C jest podstawowym pasmem dla sieci 5G, gdzie jeden operator sieci może uzyskać pasmo 100 MHz lub więcej, a dupleks z podziałem czasu (TDD) jest wykorzystywany do ułatwienia korzystania z zaawansowanych technologii Massive MIMO. W porównaniu z pasmami o niższych częstotliwościach, które są szeroko stosowane w systemach LTE, pasmo C charakteryzuje się większą utratą ścieżki i utratą penetracji. Ten problem jest jeszcze bardziej dotkliwy dla UL ze względu na wyższą częstotliwość i mniejszą część alokacji zasobów UL. Kształtowanie wiązki i sygnał referencyjny specyficzny dla komórki (CRS) zmniejszają zakłócenia DL i zwiększają różnicę między zasięgiem UL i DL w paśmie C. Jako przykład, biorąc DL 10 Mb/s a UL 1 Mb/s, zasięg UL w paśmie C jest do 15,4 dB mniejszy niż w przypadku DL. Pasmo C DL może osiągnąć podobny zasięg jak LTE 1800 MHz, ale istnieje ograniczenie zasięgu UL i staje się wąskim gardłem we wdrażaniu 5G, co wpłynie na wrażenia użytkownika. Różnica między zasięgiem pasma C i LTE 1800 MHz UL wynosi 7,7 dB dla 2R i 10,7 dB dla 4R. Ta luka w zasięgu UL-DL w dużym stopniu ograniczy zasięg komórki. Spowoduje to zwiększenie liczby lokalizacji stacji bazowych w celu pokrycia tego samego obszaru geograficznego i spowoduje wyższe koszty wdrożenia dla operatorów. Dlatego 3GPP Wydanie 15 wprowadza dwa mechanizmy, a mianowicie agregację nośnych NR (CA) i dodatkowe łącze uplink (SUL), do obsługi ograniczonego pokrycia UL na wyższych pasmach. Wdrażając te mechanizmy, mogą one skutecznie wykorzystywać nieaktywne zasoby pasma poniżej 3 GHz, poprawiać pokrycie pasma C przez UL i umożliwiać świadczenie usług 5G na szerszym obszarze. W przypadku obu mechanizmów NR CA i SUL oferują transport danych użytkownika UL przy użyciu zasobów radiowych NR w paśmie poniżej 3 GHz. NR CA zapewnia dodatkową korzyść, a także zapewnia obsługę danych użytkownika DL poniżej 3 GHz. W oparciu o SUL, funkcja odsprzęgania UL i DL definiuje nowe sparowane widma, w których pasmo C jest używane dla DL, a pasmo poniżej 3 GHz (np. 1,8 GHz) dla UL. Dzięki rozdzieleniu UL/DL są one w stanie rozwiązać problem luki w zasięgu UL-DL, a jednocześnie umożliwiają operatorom ponowne wykorzystanie istniejących lokalizacji LTE BS, poprawiając w ten sposób zasięg UL. Tradycyjna komórka zawierała tylko jedną nośną UL i jedną nośną DL, podczas gdy rozdzielenie UL/DL dla 5G-NR proponuje użycie dodatkowej nośnej 5G-NR UL w celu uzupełnienia nośnej 5G-NR TDD. Dodatkowa nośna UL i nośna TDD działają w różnych pasmach częstotliwości. Na przykład dodatkowa nośna UL działa w paśmie 1,8 GHz, a nośna TDD działa w paśmie 3,5 GHz. W związku z tym w tej samej komórce będzie jedna nośna DL i dwie nośne UL, w której każda z nośnych UL może być używana z nośną DL. Normalna nośna TDD będzie działać, gdy sprzęt użytkownika (UE) znajduje się w centrum komórki, gdzie jakość kanału jest dobra. Dodatkowy UL, który nazywa się 9SUL, będzie działał, gdy UE znajduje się na krawędzi komórki, gdzie pokrycie UL nie jest gwarantowane. Dzięki tej metodzie rozdzielenie UL/DL może zwiększyć pokrycie UL komórki 5G-NR.
Kluczowe wyzwania sieci 5G
Po dyskusji na temat architektury 5G, opcji wdrożenia, przypadków użycia, kluczowych technologii i regulacji technicznych, operator odkrył wiele kluczowych wyzwań, aby spełnić wymagania przypadków użycia eMBB, uRLLC i mMTC. Kluczowe wyzwania stojące przed operatorem telekomunikacyjnym to wdrażanie małych komórek ze względu na przepisy krajowe i politykę władz lokalnych, wdrażanie sieci światłowodowej dosyłowej oraz bezpieczeństwo i prywatność.
Wyzwania związane z wdrażaniem małych komórek
Polityka i regulacje władz lokalnych spowolniły rozwój małych komórek poprzez nadmierne obciążenia administracyjne i finansowe operatorów. W związku z tym inwestycje w 5G w niektórych krajach zostały zablokowane z powodu tych problemów. Zagadnienia te zostały opisane bardziej szczegółowo w następujący sposób:
1. Lokalne procesy wydawania pozwoleń i planowania
- Przedłużone procesy wydawania pozwoleń poprzez zatwierdzenie wniosku o planowanie mogą trwać od początku do końca od 18 do 24 miesięcy, głównie ze względu na konieczność uzyskania lokalnych pozwoleń na instalację urządzeń.
2. Długi czas trwania zaangażowania i zamówienia
- Władze lokalne stosują przedłużone procedury udzielania zamówień, trwające od 6 do 18 miesięcy, aby przyznać dostawcom sieci bezprzewodowych wyłączne prawa do umieszczania małych urządzeń komórkowych na meblach miejskich.
3. Wysokie opłaty i prowizje za dostęp do małej architektury
- Władze lokalne pobierają obecnie wysokie opłaty za dostęp do małej architektury. Na przykład, według US Consumer Institute, opłata za zgłoszenie w wysokości 30 000 USD jest pobierana za przymocowanie małego sprzętu komórkowego do słupa, podczas gdy w innej miejscowości nakładana jest opłata w wysokości 45 000 USD. W związku z tym operator telekomunikacyjny musi zainwestować do 75 000 USD na wdrożenie małych komórek w jednym mieście.
Wspomniane wcześniej problemy uniemożliwiają szybkie i opłacalne wdrażanie małych komórek w centrach miast, gdzie początkowo oczekuje się największego popytu na 5G. Decydenci, którzy zapewniają uproszczone i elastyczne procesy regulacyjne, najwięcej skorzystają z innowacji i wzrostu gospodarczego, jakie przyniesie 5G. W celu rozwiązania problemów związanych z wdrażaniem małych komórek sugeruje się, aby rządy współpracowały z lokalnymi władzami społeczności, aby zapewnić, że rozsądne opłaty są pobierane podczas rozmieszczania małych urządzeń radiowych na elementach małej architektury. Władze lokalne zasugerowały rozważenie poprawy dostępu poprzez wdrożenie technologii 5G w rządowych meblach miejskich i usprawnienie procesów zaangażowania jako alternatywę dla długotrwałych działań związanych z zamówieniami. Nowe przepisy mogą być egzekwowane w celu ujednolicenia wdrażania małych komórek w całym kraju lub stanie. Rachunki powinny zawierać:
• Przyznawanie usługodawcom, którzy mają rację i nie dyskryminują własności publicznej
• Umożliwienie samorządom pobierania opłat za zezwolenia, które są rozsądne, uczciwe i oparte na kosztach
• Ograniczenie kosztów nakładanych przez samorządy na instalację lub mocowanie sprzętu
• Powstrzymanie samorządów, które narzucają nieuzasadniony czas na uzyskanie zezwolenia dostawcom usług telekomunikacyjnych.
Wyzwania związane z wdrażaniem światłowodowej sieci dosyłowej
Z drugiej strony wprowadzenie małych komórek ma wpływ na część sieci określaną jako backhaul. Backhaul jest odpowiedzialny za zbieranie ruchu danych z BS i przesyłanie go do sieci agregacji głównie pod względem liczby wymaganych połączeń backhaul. W rzeczywistości do agregowania ruchu danych pochodzących z każdej małej komórki, każdej z nich potrzebna jest duża liczba łączy pracuje w szczytowej szybkości kilkudziesięciu Mb/s. Starsza infrastruktura oparta na miedzi nie może zagwarantować szczytowej stawki, zmuszając operatorów telekomunikacyjnych do modernizacji sieci dosyłowych w celu uniknięcia potencjalnych wąskich gardeł. Dlatego wdrożenie światłowodowych sieci dosyłowych dla małych komórek może obsługiwać wysokie szybkości transmisji danych i niskie opóźnienia, aby spełnić większość wymagań dotyczących przypadków użycia 5G. Jednak niektóre miasta, w których brakuje światłowodowej sieci dosyłowej, stały się jednym z największych wyzwań, przed którymi stoją operatorzy telekomunikacyjni. Operatorzy powinni rozważyć technologie bezprzewodowej sieci dosyłowej, w tym mmWave i satelitę, do wdrażania światłowodowych sieci dosyłowych. Złożony proces opuszczania drogi jest jedną z barier we wdrażaniu światłowodowej sieci dosyłowej. Umowy Wayleave umożliwiają operatorom instalację infrastruktury telekomunikacyjnej na gruntach publicznych lub prywatnych. Korzystanie z dróg na zamówienie jest drogie, a właściciele gruntów, którzy wykorzystują proces zamówień, aby zapewnić dodatkowe ryzyko, czas i wydatki w procesie. Ponadto brak wcześniejszego zaangażowania operatorów i władz lokalnych może skutkować odmową wydania pozwolenia na budowę. Polityka władz lokalnych dotycząca lokalizacji i estetyki szafek ulicznych może również zwiększyć koszty i opóźnienia, podczas gdy poszukiwane są alternatywne rozwiązania. Problemy z dosyłem światłowodowym można rozwiązać, jeśli decydenci lub rząd rozważą usunięcie obciążeń podatkowych, pomagając w ten sposób obniżyć koszty inwestycji. Może to ułatwić wdrażanie sieci 5G. Z drugiej strony władze lokalne mogą rozważyć uzgodnienie znormalizowanych umów o odejściu w celu zmniejszenia kosztów i czasu wdrażania sieci światłowodowych. Rządy muszą rozważyć stymulowanie inwestycji w sieci światłowodowe i aktywa pasywne poprzez tworzenie partnerstw publiczno-prywatnych (PPP), funduszy inwestycyjnych i oferowanie funduszy dotacyjnych i wielu innych. Tworzenie przemysłu włókienniczego może wymagać ogromnych inwestycji. Niestety, firmy o ugruntowanej pozycji mogą nie być zainteresowane angażowaniem się w nowe branże lub być może istnieje branża monopolistyczna, w której ceny są bardzo wysokie. Sugeruje się zatem, że rząd może udzielić pożyczki przy niskim zainteresowaniu zakładaniem przemysłu włókienniczego. Oczekuje się, że w ten sposób powstanie wiele firm, które mogą mieć ze sobą konkurentów. Pośrednio mogą one obniżyć koszt włókna. Ponadto dostępność urządzeń jest również jednym z problemów związanych z wdrażaniem sieci światłowodowych. Urządzenie, które musi działać w sieci implementującej opcję NSA/SA, będzie obsługiwać wszystkie protokoły wymagane przez implementację NSA/SA i może obsługiwać wszystkie protokoły wymagane przez implementację SA/NSA. Różne pasma częstotliwości, takie jak sub-6 GHz i mmWave, wymagają różnych zestawów urządzeń łączonych. Jednak pasmo poniżej 6 GHz nie jest zoptymalizowane pod kątem nowych zastosowań 5G, z wyjątkiem mobilnej łączności szerokopasmowej i fal milimetrowych, które mogą powodować szybkie tłumienie sygnału radiowego. Problemy z dostępnością urządzeń można rozwiązać, ponieważ producenci opracowują obecnie technologię, która osadza 5G, 4G, 3G i 2G na jednym chipie i oczekuje się, że będzie dostępna do sprzedaży w 2020 r. dla globalnie zharmonizowanych standardów.
Wyzwania dotyczące prywatności użytkowników 5G
W tradycyjnych sieciach telefonii komórkowej użytkownicy komunikują się za pomocą SMS-ów lub połączeń głosowych/wideo, surfują po Internecie lub uzyskują dostęp do usług aplikacji za pomocą smartfonów. Niemniej jednak sieć 5G nie ogranicza się już do klientów indywidualnych, ale obsługuje także branże wertykalne, z których będą się wywodzić różne nowe usługi. Dlatego informacje o prywatności użytkowników muszą być bezpiecznie chronione w sieci 5G. Sieci komórkowe 5G przenoszą dane i sygnalizację, które zawierają wiele informacji osobistych, takich jak tożsamość, pozycja i prywatne treści. Oparte na sieci podejście do zabezpieczeń typu hopby-hop, które jest używane w tradycyjnych sieciach komunikacji mobilnej, może nie być wystarczająco wydajne, aby zbudować zróżnicowane zabezpieczenia E2E dla różnych usług. Aby oferować zróżnicowaną jakość usług, sieci mogą potrzebować wyczuć, z jakiego typu usługi korzysta użytkownik. Wykrywanie typu usługi może wiązać się z prywatnością użytkownika. Alternatywnie, eksploracja danych może również łatwo uzyskać informacje o prywatności użytkownika dzięki zaawansowanym technologiom. Dlatego ochrona prywatności w 5G jest trudniejsza. Aby chronić prywatność użytkowników, dostawcy usług muszą ujawnić swoje mechanizmy bezpieczeństwa 5G. Może to zapobiec wyciekowi informacji o prywatności, gdy użytkownicy i branże branżowe korzystają z sieci 5G. Mechanizm bezpieczeństwa 5G obejmuje:
• Zarządzanie wykorzystaniem informacji o prywatności
Sieć 5G zapewnia użytkownikom spersonalizowane usługi sieciowe, wykrywając ich cechy usług. Jednak informacje o prywatności, takie jak lokalizacja użytkownika, informacje o stanie zdrowia i dane osobowe, mogą być wykorzystywane w procesie wykrywania typu usługi. Dla sieci 5G musi być jasno zdefiniowana reguła wykrywania usług, aby rozwiać obawy użytkowników dotyczące prywatności. Metoda musi określać sposób zachowania prywatności. informacje są wykorzystywane i jak są obsługiwane po użyciu. Na przykład polityka prywatności i umowa użytkownika muszą zostać wydane przez użytkownika, zanim strona trzecia zacznie kontynuować lub uzyskać dostęp do prywatnych danych użytkownika.
• Szyfrowanie 5G E2E
Dzięki technologiom eksploracji danych strona trzecia lub haker może być w stanie uzyskać szczegółowe informacje o prywatności użytkownika. Ryzyko wycieku informacji zmniejsza się, gdy sieci telekomunikacyjne zapewniają szyfrowanie 5G E2E, które obejmuje:
1. Wzajemne uwierzytelnianie
Użytkownicy końcowi systemu 5G są uwierzytelniani w celu obsługi pobierania opłat za dostęp do sieci, rozliczalności (np. który użytkownik miał jaki adres IP i kiedy) oraz zgodnego z prawem przechwycenia. Sieć jest również uwierzytelniana wobec użytkowników końcowych, aby użytkownicy końcowi wiedzieli, że są połączeni z legalną siecią.
2. Implementacja algorytmu i protokołów bezpieczeństwa
System 5G wymaga wsparcia grupy ekspertów ds. algorytmów bezpieczeństwa Europejskiego Instytutu Norm Telekomunikacyjnych (ETSI), a konkretnie Grupy Ekspertów ds. Algorytmów Bezpieczeństwa (SAGE). W przypadku warstwy IP i wcześniejszych zaleca się zaimplementowanie sprawdzonych protokołów bezpieczeństwa IETF. W rezultacie system 5G jest w stanie zapewnić niezawodność i odporność na niezłośliwe sytuacje niedostępności, na przykład błędy, które pojawiają się z powodu nietypowych, ale oczekiwanych złych warunków radiowych i zerwanych łączy.
Streszczenie
Sieć 5G wprowadza rewolucyjną nową technologię, która stworzy nowe możliwości biznesowe i zmieni dynamikę rynku. Platforma 5G rozszerzy ekosystem sieci, wprowadzając nowych interesariuszy, inwestorów i partnerów na rynek dostawców usług. Oprócz organów standardowych i innych, które pomagają zdefiniować i zaprojektować 5G, dostawcy usług lub operatorzy pracują nad różnymi podejściami i technologiami, aby ułatwić ewolucję od 4G LTE do 5G. Pełny system 5G obejmuje eMBB, uRLLC i mMTC, które zapewniają większą przepustowość danych, bardzo niezawodne opóźnienie E2E 1 ms przy ogromnej liczbie urządzeń IoT. Jednak wysokie nakłady inwestycyjne (CAPEX) i operacyjne (OPEX), słaba sieć dosyłowa i niezabezpieczone kwestie prywatności użytkowników stają się kluczowymi wyzwaniami dla rozwoju sieci 5G. Zaproponowano kilka rozwiązań, aby przezwyciężyć wyzwania związane z 5G i usprawnić wdrażanie sieci 5G
Przemysł 4.0 i MŚP
Małe i średnie przedsiębiorstwa (MŚP) mają największy udział w gospodarce wytwórczej w Wielkiej Brytanii i Europie. Jednak w przeciwieństwie do dużych firm międzynarodowych mają one zwykle ograniczone zasoby i zwykle nie mają możliwości inwestowania w nowe i powstające technologie. Badania wskazują, że branże brytyjskie, zwłaszcza MŚP, stoją przed wyzwaniami, a także szansami w dążeniu do przyjęcia technologii prowadzących do czwartej rewolucji przemysłowej, Przemysłu 4.0. Aby brytyjski przemysł wytwórczy pozostał konkurencyjny, konieczne jest, aby MŚP poważnie wykorzystały potencjał Przemysłu 4.0 w zakresie wzrostu i zwiększonej produktywności. Ponieważ tempo przyjmowania nowych technologii przyspiesza, brytyjskie MŚP nie mogą sobie pozwolić na utratę przewagi konkurencyjnej na rzecz bardziej zaawansowanych konkurentów. Wielka Brytania ma już wysokowydajne sektory produkcyjne w zastosowaniu cyfryzacji, co oznacza, że ma potencjał, aby być liderem w Europie w produkcji cyfrowej. Na przykład Wielka Brytania ma najsilniejszy rynek sztucznej inteligencji i uczenia maszynowego w Europie, z ponad 200 MŚP w tej dziedzinie [Made Smarter Review (2017), Departament strategii biznesowej, energetycznej i przemysłowej, dostępny pod adresem https://www.gov. uk/government/publications/made-smarter-review]. Dlatego istnieje silna potrzeba opracowania inteligentnych metod i narzędzi, które mogłyby wspierać MŚP w ich transformacji w kierunku Przemysłu 4.0. W tym rozdziale omówiono możliwości i wyzwania, przed którymi stoją MŚP w związku z przyjęciem Przemysłu 4.0, oraz ich gotowość do tego przemysłu czwartej generacji. Zwrócono również uwagę na niektóre potencjalne narzędzia, które mogłyby pomóc MŚP w przejściu do Przemysłu 4.0.
Wstęp
Przemysł wytwórczy przeszedł liczne zmiany w ciągu ostatnich dwóch stuleci, z których każda radykalnie zmieniła charakter i możliwości przemysłu wytwórczego, jednocześnie ogólnie dostarczając lepsze produkty i prowadząc do bardziej wydajnych procesów produkcyjnych i bardziej produktywnej produkcji. Po pierwszych trzech rewolucjach obejmujących odpowiednio energię parową, masową produkcję z elektrycznością i komputerem oraz automatyzację, czwarta rewolucja wiąże się z powszechnym wykorzystaniem danych i uczenia maszynowego w celu dalszej automatyzacji i digitalizacji procesów. Przemysł 4.0 wykorzystuje dziesięciolecia cyfryzacji i wdrażania zautomatyzowanych procesów produkcyjnych w przemyśle, zwiększa ich możliwości dzięki integracji systemów cyberfizycznych (CPS), takich jak Internet rzeczy (IoT), Big Data, symulacja i integracja systemów cyfrowych oraz poprawia procesów dzięki uczeniu maszynowemu opartemu na danych. Wdrażanie tych technologii w sektorze produkcyjnym jest już w toku, a duże korporacje wykorzystują moc analityki opartej na danych i uczenia maszynowego w celu poprawy wydajności produkcji. Organizacje nie korzystające z tych technologii będą narażone na utratę przewagi konkurencyjnej na rzecz bardziej zaawansowanych konkurentów. W przeciwieństwie do dużych korporacji, MŚP często nie mają funduszy ani możliwości inwestowania w technologie zanurzeniowe, przez co grozi im utrata udziału w rynku. Produkcja wnosi ponad 6,7 bilionów funtów do światowej gospodarki i wnosi znaczący wkład do UK PLC. Produkcja brytyjska stanowi 9,8% brytyjskiej gospodarki (162 mld funtów wartości dodanej brutto w 2015 r.), a Wielka Brytania nadal znajduje się w pierwszej dziesiątce największych krajów produkcyjnych (dziewiąty w latach 2016/2017) i czwarty co do wielkości w UE. Zatrudnia 2,6 miliona osób, a prawdopodobnie 5,1 miliona osób w całym łańcuchu wartości produkcji. Brytyjski eksport towarów wyprodukowanych przez sektor produkcyjny wyniósł 257 miliardów funtów w 2015 roku i stanowił 50% całego eksportu Wielkiej Brytanii. Stanowi 70% wydatków biznesowych na badania i rozwój oraz 14% inwestycji biznesowych. Według Cordes i Stacey oraz UK Industrial Digitization Review uznano, że dzięki wiodącej cyfryzacji przemysłu Wielka Brytania ma potencjał osiągnięcia wzrostu wydajności przemysłowej nawet o 25%, wzrostu sektora produkcyjnego o 1,5-3% i zapewnienia rocznego wzrostu ~0,5% PKB. MŚP stanowią zdecydowaną większość firm w Wielkiej Brytanii i wnoszą znaczący wkład w brytyjską gospodarkę. Przewiduje się, że wkład MŚP może osiągnąć 217 miliardów funtów do 2020 roku i wynieść 70% całego zatrudnienia w Wielkiej Brytanii. Biorąc pod uwagę ich znaczenie dla gospodarki Wielkiej Brytanii, konieczne jest, aby MŚP pracowały nad przyjęciem Przemysłu 4.0 wcześniej niż później, jeśli mają utrzymać swoją przewagę konkurencyjną w kraju i na arenie międzynarodowej.
Szanse i wyzwania związane z przyjęciem Przemysłu 4.0 przez MŚP
Przyjęcie Przemysłu 4.0 stwarza możliwości i wyzwania dla MŚP w Wielkiej Brytanii, które mogą mieć charakter wewnętrzny lub zewnętrzny. W tej sekcji omówiono niektóre z typowych wyzwań i możliwości.
Możliwości
W brytyjskim raporcie okresowym dotyczącym przeglądu cyfryzacji przemysłu podkreślono, że szybsze przyjęcie przemysłowych technologii cyfrowych (IDT) może stać się kluczowym motorem poprawy produktywności, globalnej konkurencyjności i zwiększonego eksportu. Badanie wykazało, że dzięki pełnemu zastosowaniu tych technologii w ciągu następnej dekady produkcja przemysłowa w Wielkiej Brytanii byłaby nawet o 30% szybsza i o 25% bardziej wydajna. Siła w obszarach takich jak sztuczna inteligencja, blockchain, wirtualna rzeczywistość i uczenie maszynowe stwarza szansę Wielkiej Brytanii na bycie liderem w rozwoju technologii cyfrowych. Dzięki szybkiemu i znacznemu postępowi w technologiach związanych z IT, koszt komponentów takich jak czujniki i infrastruktura chmurowa znacznie spadł w ciągu ostatnich kilku lat. Stworzyło to środowisko, w którym zaawansowane technologie można zintegrować z przemysłem wytwórczym po rozsądnych kosztach. W ostatnich latach udało się zminiaturyzować systemy wbudowane i umieścić je w chipie. Znacznie poprawiła się ich wydajność, mogą być wyposażone w adres IP i nowoczesne interfejsy komunikacyjne, zintegrowane z Internetem i stać się częścią CPS. Ogromna ilość danych generowanych każdego dnia przez zakłady produkcyjne i analitykę rynkową utrudnia liderom MŚP dokładne ich śledzenie i wykorzystywanie danych do podejmowania najbardziej dochodowych decyzji. Wdrażając Przemysł 4.0, MŚP mogą usprawnić swoje procesy produkcyjne i pozytywnie wpłynąć na marże zysku. Ponadto wykorzystanie technologii Przemysłu 4.0 ułatwiłoby MŚP dokładniejsze monitorowanie linii produkcyjnych i utrzymanie ich jakości. Patrząc na zmieniające się potrzeby rynku, dostrzega się rosnące zapotrzebowanie na personalizację/customizację produktów. Technologie takie jak wytwarzanie addytywne zasadniczo zmieniają łańcuch dostaw, w którym korzyści wynikające z dużych ilości i niskich kosztów pracy są zastępowane przez bliskość rynku i możliwości tworzenia unikalnych produktów dla każdego klienta. Co więcej, inteligentna automatyzacja może to osiągnąć dzięki cyfrowo połączonym fabrykom, które mogą dostarczać klientom duże zróżnicowanie, wciąż w rozsądnych ilościach, przy jednoczesnym zwiększeniu prędkości i zmniejszeniu ilości odpadów. Technologie Przemysłu 4.0 mogą zapewnić optymalizację wydajności, która może przynieść ogromne korzyści MŚP. Dzięki połączeniu cyfrowemu wszystkie procesy są stale monitorowane, a widoczne problemy i nadmiary mogą być szybko usuwane z procesu produkcyjnego. Dodatkowo wykorzystanie IoT do komunikacji między działami firmy produkcyjnej jest szczególnie pomocne w przyspieszeniu podejmowania decyzji w procesie produkcyjnym. Znaczące wsparcie nadchodzi od organizacji rządowych i brytyjskich, ze szczególnym uwzględnieniem MŚP. Na przykład Innovate UK i jej partnerzy, do których należą Sieć Transferu Wiedzy (KTN), Europejska Sieć Przedsiębiorczości (EEN), Rady ds. Badań Naukowych (RC) i Digital Catapult (DC), należą do wiodących organizacji w Wielkiej Brytanii, które wspierają MŚP w przyjęciu Przemysłu 4.0. W lipcu 2019 r. rząd ogłosił konkurs badawczo-rozwojowy o wartości 30 mln GBP na projekty mające na celu radykalne zwiększenie produktywności i elastyczności brytyjskiej produkcji dzięki technologiom cyfrowym. W ciągu 3 lat poprzedzających 2017 r. firma Innovate UK zainwestowała ponad 200 milionów funtów w przełomowe technologie cyfrowe, takie jak produkcja addytywna, robotyka i systemy autonomiczne, modelowanie i symulacja, rzeczywistość rozszerzona i wirtualna, analiza danych i sztuczna inteligencja (AI).
Wyzwania
MŚP działające w sektorze wytwórczym stanowią największy przemysł w Wielkiej Brytanii. Jednak tylko około 10% tych firm wykorzystywało standardowe wyposażenie Przemysłu 4.0 w swoich maszynach i systemach inżynierskich. Badania wykazały, że istnieje znaczny związek między wielkością firmy a jej szansami na przyjęcie technologii Przemysłu 4.0. MŚP są mniej skłonne do integrowania pojawiających się technologii w wyrafinowany sposób w swoich zakładach produkcyjnych i systemach informatycznych. Niektóre przyczyny omówiono w następujący sposób. Brak odpowiedniej strategii cyfrowej przyjęcia Przemysłu 4.0 przez MŚP jest jednym z wiodących wyzwań. MŚP musiałyby opracować strategie opracowania analizy kosztów i korzyści wymaganych technologii w celu przeprowadzenia wykonalności w ich organizacji. Nie ma odpowiedniego krajobrazu wsparcia biznesowego ze ścieżką dostępu do pomocy i wskazówek dotyczących najlepszych praktyk w zakresie wdrażania technologii Przemysłu 4.0. Wielka Brytania jest liderem w dziedzinie badań i innowacji i zaczęła tworzyć sprzyjającą infrastrukturę wspierającą rozwój i komercjalizację technologii. Jednak te innowacyjne aktywa są niedostatecznie lewarowane i niewystarczająco skoncentrowane na wspieraniu startupów IDT, co oznacza, że Wielka Brytania pozostaje w tyle pod względem tworzenia nowych innowacyjnych firm i branż. Pomimo całego postępu, jaki oferują technologie Przemysłu 4.0, MŚP nadal dość ostrożnie podchodzą do wdrażania ich w swoich obiektach. Można to przypisać kilku obawom zainteresowanych stron, z których główną jest brak standardów bezpieczeństwa leżących u podstaw technologii, co może w konsekwencji narazić na szwank dużą ilość danych. Brakuje standardów cyfrowych leżących u podstaw technologii cyfrowej i sieci. Obecnie MŚP w większości dostosowują się do zestawu protokołów i standardów stosowanych przez ich większe przedsiębiorstwa, którym dostarczają produkty, aby zwiększyć kompatybilność swoich systemów i ułatwić płynną wymianę danych i informacji. Jednak brak wspólnych standardów i norm utrudnia MŚP przyjmowanie technologii, które mogą nie być kompatybilne z innymi firmami stosującymi różne zestawy norm. Oprócz ustanowienia standardowych protokołów i praktyk, nie ma odpowiednich środków bezpieczeństwa cybernetycznego do ochrony danych używanych w systemie Przemysłu 4.0. Kluczowe dane firmy, takie jak dane operacyjne, procedury tworzenia opatentowanych produktów i poufne zasady firmy, mogą być narażone na ataki, jeśli odpowiedni system bezpieczeństwa nie jest zainstalowany. Dlatego nie można przecenić potrzeby opracowania wspólnego zestawu standardów i protokołów bezpieczeństwa, z których będą korzystać organizacje wdrażające Przemysł 4.0. MŚP zazwyczaj zatrudniają mniej osób i prawdopodobnie odczuwają lukę w umiejętnościach. Brakuje dostępu do osób z odpowiednimi umiejętnościami, które byłyby w stanie podołać szybko postępującym zmianom technologicznym. Jest to szczególnie widoczne w MŚP, które mają mniejsze doświadczenie techniczne i wiedzę, ponieważ większość z nich nie ma odpowiedniego, dedykowanego działu IT. Model biznesowy jest jednym z kluczowych elementów procesów biznesowych, zapewniających czerpanie odpowiedniej ilości inspiracji z reprezentowania kreatywnej koncepcji firmy. Aby utrzymać konkurencyjny charakter, firmy muszą rozważyć innowacje w modelu biznesowym (BMI) jako część swojej kluczowej działalności. Inne wyzwania to wysokie koszty inwestycji związanych z przyjęciem technologii oraz brak środków finansowych na inwestycje w badania i rozwój związane z przyjęciem Przemysłu 4.0.
Gotowość MŚP do przyjęcia Przemysłu 4.0
Raport Federacji Pracodawców Inżynierii (obecnie znanej jako "Make UK") na temat czwartej rewolucji przemysłowej - podstawy dla produkcji, wykazał, że podczas gdy 42% brytyjskich producentów dobrze orientuje się, co pociągnie za sobą Przemysł 4.0, tylko 11% uważamy, że Wielka Brytania jest przygotowana na tę kluczową kolejną epokę przemysłową. Sugeruje to, że jeśli chodzi o gotowość na Przemysł 4.0, jest jeszcze wiele do zrobienia. Dodaje, biorąc pod uwagę, że MŚP stanowią połowę mocy produkcyjnych w Wielkiej Brytanii, niezwykle ważne jest, aby przyjęły Przemysł 4.0, jeśli ma on zostać pomyślnie wdrożony. Dostępnych jest kilka narzędzi, które mogą pomóc firmom ocenić ich gotowość do Przemysłu 4.0. W tej sekcji zostaną omówione trzy najważniejsze narzędzia: narzędzie samooceny PwC Industry 4.0, Region of Smart Factory (RoSF) oraz narzędzie oceny gotowości WMG Industry 4.0. Jeszcze jedno narzędzie oceny, które jest specjalnie dostosowane do MŚP, zostanie omówione w następnej sekcji.
Narzędzie samooceny PwC Industry 4.0
To narzędzie do samooceny zostało opracowane przez firmę Price waterhouse Coopers (PwC) i jest dostępne online pod adresem i40-self-assessment.pwc.de. Opiera się na ankiecie przeprowadzonej wśród ponad 2000 firm z 26 krajów i ma na celu zapewnienie firmom zrozumienia ich pozycji w odniesieniu do Przemysłu 4.0 poprzez pomiar ich dojrzałości w siedmiu wymiarach, tym samym identyfikując potrzeby działania i klasyfikując obecną dojrzałość. Poziom dojrzałości pozwoli firmom porównać swoją pozycję z konkurencją w swoim sektorze. Narzędzie do oceny online zapewnia kierowany zestaw pytań i ostatecznie wyświetla poziom dojrzałości firmy w formie wykresów i komentarzy. Poziomy dojrzałości są krótko opisane w następujący sposób.
Cyfrowy nowicjusz: Na tym poziomie dojrzałości osiągnięto pewną wstępną cyfryzację w dziale, a także w produktach i usługach, ale działania nie są dobrze skoordynowane i ukierunkowane na przyszłość. Portfolio jest zazwyczaj zdominowane przez produkty fizyczne, a integracja w ramach pionowych i poziomych łańcuchów wartości jest ograniczona. Ryzyka cyfrowe nie są systematycznie rejestrowane, podobnie jak zgodność gwarantowana we wszystkich obszarach.
Integrator pionowy: Firmy na tym poziomie dojrzałości nadały już swoim produktom i usługom funkcje cyfrowe. Procesy operacyjne i część procesów administracyjnych są zdigitalizowane. Na przykład dane z rozwoju produktu są dostępne dla fizycznej produkcji, logistyki i systemów w firmie.
Współpracownik poziomy: Tutaj współpracownicy integrują swoje łańcuchy wartości z klientami i partnerami. Portfolio produktów i usług jest powiązane z zewnętrznymi partnerami w łańcuchu wartości w takim stopniu, że klientom oferowane są kompleksowe rozwiązania na kilku etapach łańcucha wartości. Innowacyjne koncepcje optymalizują komunikację z klientami, a informacje o klientach są zapisywane i analizowane w celu zapewnienia optymalnej komunikacji. Ryzyka cyfrowe są zarządzane za pomocą ustandaryzowanej i wydajnej metody, a zgodność jest utrzymywana dla wszystkich funkcji w firmie.
Cyfrowy mistrz: Cyfrowy mistrz połączył swoje procesy operacyjne i administracyjne w skali globalnej, a także zwirtualizuje procesy w głównych obszarach. Koncentruje się na kluczowych obszarach i współpracuje z globalną siecią partnerów. Kluczowe procesy administracyjne są zdigitalizowane i zoptymalizowane globalnie według kryteriów kosztów i kontroli. Następnie można przeprowadzić porównanie firmy z innymi firmami w ich sektorze.
Narzędzie oceny RoSF Smart Factory
Narzędzie to zostało opracowane przez RoSFs uruchomione przez Uniwersytet w Groningen w Holandii i jest dostępne online pod adresem http://www.smartfactoryassessment.com/assessment/#/en. Narzędzie do oceny Inteligentnej Fabryki ma na celu umożliwienie firmom produkcyjnym oceny własnego stanowiska w kwestii tego, jak inteligentna jest ich fabryka. Chociaż są to ogólne ramy, które należy dostosować do poszczególnych firm, powszechnie uznaje się je za bardzo przydatne wskazówki dla MŚP w ich transformacji w kierunku inteligentnej fabryki. To narzędzie online zawiera pięć pytań/stwierdzeń dotyczących każdej kompetencji, z których firma może wybrać dwa (gdzie obecnie się znajduje i gdzie chce być). Po wybraniu wszystkich kompetencji firma ma możliwość wskazania, w jakim stopniu każda kompetencja jest dla niej istotna. Następnie system wygeneruje profil uszeregowany według istotności dla firmy w postaci zaznaczonej tabeli.
Narzędzie oceny WMG Industry 4.0
To narzędzie do oceny gotowości na Przemysł 4.0 zostało opracowane przez WarwickManufacturing Group (WMG) we współpracy z jej współpracownikami przemysłowymi. Opiera się na ankiecie z 53 odpowiedziami z 22 krajów i jest dostępny online. Jej celem jest zapewnienie firmom prostego i intuicyjnego sposobu na rozpoczęcie oceny ich gotowości i przyszłych ambicji wykorzystania potencjału ery cyberfizycznej. Jest bardziej wszechstronny niż narzędzie PwC i Smart Factory przygląda się sześciu podstawowym wymiarom z 37 podpodziałami, które oceniałyby gotowość Przemysłu 4.0. Podstawowe wymiary obejmują
• Produkty i usługi
• Produkcja i operacje
• Strategia i organizacja
• Łańcuch dostaw
• Model biznesowy
• Względy prawne.
Ocena w każdym wymiarze jest zaprojektowana wokół czterech poziomów dojrzałości: początkujący, średniozaawansowany, doświadczony i ekspert. Podobnie jak w przypadku poprzednich narzędzi, każdy wymiar podstawowy składa się z zestawu kompetencji. Dla celów ilustracyjnych, dwa z podstawowych wymiarów wraz z ich kompetencjami, wyciągnięte z. Wynik oceny, w postaci spersonalizowanego raportu gotowości, zostanie następnie przedstawiony na wykresie wyraźnie pokazującym, gdzie stan firmy jest porównywany ze stanem Przemysłu 4.0. Na przykład typowy raport dla wymiaru Produkty i usługi zawierałby ogólny wykres słupkowy i pozycję indywidualną na wykresie pajęczyny porównawczej, jak pokazano na rysunku 25.8. Pełny opis narzędzia oceny WMG wraz z instrukcjami można znaleźć na stronie https://i4ready.co.uk/. Trzy omówione wcześniej narzędzia oceny gotowości do Przemysłu 4.0 mogą jedynie pomóc firmom określić ich pozycję w porównaniu ze standardem Przemysłu 4.0, ale nie pomagają firmom w wypełnianiu luki. Ponadto, choć są one ważne, mogą być zaprojektowane i napisane w oparciu głównie o duże branże, które mogły nie koncentrować się na MŚP.
Pomaganie MŚP we wdrażaniu Przemysłu 4.0
Przemysł 4.0 ma potencjał tworzenia imponujących, nowych, a czasem niewyobrażalnych możliwości biznesowych dla tych, którzy są innowacyjni i zwinni, ale MŚP potrzebują znacznego wsparcia ze strony organizacji rządowych i instytucji wiedzy, aby to zrealizować. Oprócz wsparcia dostępnego od organizacji, takich jak Innovate UK i jej partnerów, wiele projektów krajowych i europejskich działa również na rzecz wspierania MŚP w ich dążeniu do Przemysłu 4.0. Jednym z godnych uwagi międzyregionalnych projektów europejskich poświęconych wspieraniu MŚP w regionie Morza Północnego (NSR) jest GrowIn 4.0. Celem GrowIn 4.0 jest w szczególności pomoc MŚP w ich transformacji w kierunku Przemysłu 4.0
Rozwijaj się w wersji 4.0
Projekt Interreg NSR, GrowIn 4.0, ma na celu zbudowanie silnych kompetencji i narzędzi w uczestniczących regionach Morza Północnego z korzyścią dla MŚP produkcyjnych. Ogólnym celem jest podniesienie poziomu innowacyjności i większy wzrost w produkcyjnych MŚP, które zmierzają w kierunku Przemysłu 4.0. Komisja Europejska obawia się, że europejskie MŚP pozostają w tyle za swoimi amerykańskimi odpowiednikami we wdrażaniu Przemysłu 4.0. Projekt GrowIn działa w ramach trzech pakietów roboczych: Nowe modele biznesowe i rozwój strategii: Celem tego pakietu roboczego jest wzmocnienie strategii biznesowych i modeli biznesowych MŚP produkcyjnych w kontekście możliwości i wyzwań związanych z Przemysłem 4.0. To jest ważny prekursor, który umożliwi MŚP ocenę, poprawę i dostosowanie ich strategii innowacyjnej. Pomoże im również zrozumieć, jak dostosować swoje możliwości do otoczenia rynkowego i które aspekty Przemysłu 4.0 będą ważne dla utrzymania ich przewagi konkurencyjnej. Lepsze wykorzystanie technologii i rozwój produktów: Ten pakiet roboczy koncentruje się w szczególności na transferze wiedzy za pomocą technologii Przemysłu 4.0 między instytucjami wiedzy a MŚP. Jest to konieczne pod wieloma względami. W przypadku MŚP ryzyko związane z korzystaniem z nowych technologii bez żadnego doświadczenia z nimi jest szczególnie wysokie. Z drugiej strony niezbędne jest, aby zawodnik utrzymywał się technologicznie na progresywnym poziomie. Szkolenia, edukacja i rekrutacja wykwalifikowanej kadry Przemysłu 4.0. Celem tego pakietu roboczego jest podniesienie poziomu umiejętności i wiedzy potrzebnych do wdrożenia Przemysłu 4.0 w MŚP. Technologie związane z Przemysłem 4.0, takie jak Big Data, IoT, Robotics, Additive Manufacturing, oferują wiele możliwości dla produkcyjnych MŚP. Szczególny nacisk kładzie się na to, jak pomóc MŚP w rozwijaniu wymaganego kapitału ludzkiego: pracowników z odpowiednią wiedzą i kompetencjami do stosowania technologii Przemysłu 4.0. Podsumowując, NSR współpracujący w tym projekcie chcą opracować regionalne podejście, aby pomóc swoim poszczególnym MŚP, ich właścicielom, ich pracownikom i całej gospodarce regionalnej w reagowaniu na zmieniające się możliwości i wspólnym czerpaniu korzyści ekonomicznych i związanych z zatrudnieniem. Opracowuje się i projektuje około 14 narzędzi specjalnie w celu wspierania MŚP w ich dążeniu do Przemysłu 4.0. Większość narzędzi jest nadal w fazie rozwoju i zostaną udostępnione MŚP pod koniec projektu w 2021 r. Krótkie spojrzenie na dwa narzędzia, które wciąż znajdują się w końcowej fazie rozwoju - narzędzie gotowości/świadomości Przemysłu 4.0 oraz narzędzie identyfikacji korzyści - zostanie tutaj wyróżnione. Oczekuje się, że gotowość/świadomość pozwoli ocenić gotowość MŚP na Przemysł 4.0 i zidentyfikować główne obszary, nad którymi należy pracować, podczas gdy narzędzie identyfikacji korzyści pomogłoby MŚP w ustaleniu, jak uświadomić sobie korzyści płynące z inwestycji w nowe technologie.
Narzędzie gotowości/świadomości Przemysłu 4.0
To narzędzie jest podobne do trzech narzędzi oceny gotowości omówionych wcześniej i wykorzystuje narzędzia PwC i WMG jako główne źródła. Nie jest on jednak tak kompleksowy jak niektóre z nich i został zaprojektowany z myślą o MŚP ze względu na swoją prostotę, czas potrzebny na wypełnienie kwestionariusza i trafność. Nadal jest w fazie rozwoju, ale przeszedł pierwszą fazę testów. Obejmuje aspekty cyfryzacji, kwestie regulacyjne i gotowość firmy. Jest on podzielony na pięć kategorii (wymiarów): modele biznesowe i produkty, dostęp do rynku i klientów, łańcuchy wartości i procesy, kwestie prawne oraz bezpieczeństwo cybernetyczne/IT oraz strategia i doświadczenie w zakresie Przemysłu 4.0. Zawiera zestaw pytań dla każdej kategorii (łącznie 23 pytania) z trzema możliwymi odpowiedziami na każde pytanie, a także możliwością wybrania przycisku pomiędzy, gdy ich pozycja jest gdzieś pomiędzy nimi. Przedsiębiorstwo wskazuje również, jak istotne jest dla niego pytanie, wybierając je z rozwijanej listy istotności. Po udzieleniu odpowiedzi na wszystkie pytania wyniki podsumowujące dla wszystkich kategorii zostaną wyświetlone w formie wykresu. Pierwsza faza testów przydatności narzędzia jest przeprowadzana na dziesięciu MŚP wraz z bezpośrednimi dyskusjami. Wyniki, w oparciu o 1 jako najmniej korzystne i 10 jako najbardziej korzystne. Były też darmowe komentarze tekstowe od firm, które podkreślały pewne wspierające opinie i obszary do pracy. Ogólnie rzecz biorąc, wszystkie MŚP uczestniczące w badaniu stwierdziły, że są zadowolone z ogólnej treści kwestionariusza, jego rozmiaru i prostoty oraz uznały to narzędzie za bardzo przydatne. Narzędzie będzie dalej rozwijane po pierwszym teście i ponownie testowane przez większą liczbę MŚP w najbliższej przyszłości. Ostateczna wersja zostanie następnie udostępniona MŚP pod koniec projektu GrowIn w 2021 r
Identyfikacja korzyści
Narzędzie gotowości/oceny mogłoby jedynie pomóc MŚP w zrozumieniu, gdzie obecnie znajdują się w stosunku do Przemysłu 4.0, a także w określeniu obszarów, nad którymi muszą pracować, aby przejść do Przemysłu 4.0. Ale nie dają odpowiedzi, jak się tam dostać. Wśród zestawu narzędzi rozwijanych w ramach projektu GrowIn znajduje się identyfikacja korzyści. Ponieważ jest jeszcze w fazie rozwoju, tutaj zostanie wyróżniona tylko krótka relacja. Zostanie on udostępniony publicznie w całości pod koniec projektu GrowIn.
Oczekuje się, że narzędzie to pomoże MŚP w podejmowaniu decyzji o przyjęciu technologii, analizując korzyści i potencjalne zagrożenia. Będzie to wymagało warsztatów, bezpośredniego zaangażowania, mapowania korzyści i strat oraz powiązania wyborów technologicznych z celami strategicznymi. Identyfikacja korzyści, jako proces formalny, jest nowym dodatkiem do zestawu narzędzi do zarządzania projektami i może być centralną częścią zarówno decyzji o przyjęciu nowych technologii, jak i zarządzania wdrożeniem tych technologii w firmie. W projekcie GrowIn jest to dostosowane specjalnie dla firm produkcyjnych MŚP. Jego podejście jest podzielone na dwa odrębne etapy:
• Identyfikacja konkretnych korzyści, jakie poszczególne technologie mogą wnieść do funkcjonowania firmy, ze szczególnym uwzględnieniem efektywności operacyjnej.
• Określenie, jakie zmiany organizacyjne należy wprowadzić, aby uzyskać dostęp do tych potencjalnych korzyści.
Organizując proces, proces identyfikacji (i realizacji) korzyści można postrzegać jako trzy odrębne czynności, które można powtarzać w różnych fazach. Po zidentyfikowaniu interesujących technologii korzyści, które firma powinna wykorzystać, zostaną określone podczas warsztatów. Warsztaty powinny zapewnić wystarczający wkład i wizualizację wyników w postaci widocznej mapy w czasie rzeczywistym. Później można je przełożyć na rejestry świadczeń i narzędzia do śledzenia świadczeń. Podczas prowadzenia produktywnego warsztatu bardzo ważne jest pełne zaangażowanie kadry kierowniczej wyższego szczebla i specjalistów, aby upewnić się, że projekty są ukierunkowane na potrzeby. Wskazane jest, aby sesje warsztatowe obejmowały pracowników od hali produkcyjnej po kierowników wyższego szczebla, którzy mogliby zaoferować strategiczny lub związany z pracą wgląd w to, w jaki sposób technologie przyniosą firmie korzyści. Taka różnorodność poglądów jest o tyle ważna, że wiele powiązanych ze sobą, choć nieuchwytnych czynników często decyduje o poziomie i rodzaju korzyści, jakie mogą przynieść nowe technologie. Informacje zebrane na każdym etapie procesu identyfikacji/realizacji korzyści zostaną zmapowane, tak aby można było łatwiej zidentyfikować wszelkie relacje między informacjami na różnych etapach. Proces mapowania przebiegałby zgodnie z podstawową strukturą liniową - funkcje technologiczne, potencjalne korzyści, potrzebne zmiany biznesowe, wady i korzyści strategiczne. Każdy z nich jest wypełniany, a pojawiające się relacje i interakcje są omawiane etapami. Ponieważ mapa rozwija się w różnych fazach, powinna stymulować dalszą dyskusję i wkład. Pod koniec ścieżka powinna ostatecznie łączyć produkty ze strategicznymi celami firmy. Należy zauważyć, że wcześniej omówiono tylko pokrótce narzędzie do identyfikacji korzyści. Jak wspomniano wcześniej, pełne szczegóły narzędzia dostosowanego do MŚP przechodzących na Przemysł 4.0 zostaną udostępnione pod koniec projektu GrowIn w 2021 r.
Streszczenie
Znaczenie wkładu MŚP z sektora produkcyjnego w brytyjską gospodarkę jest wysoko cenione, ale zaledwie 10% z nich korzysta ze standardowych obiektów Przemysłu 4.0. Przyjęcie Przemysłu 4.0 niesie ze sobą możliwości i wyzwania dla MŚP, ale aby zachować przewagę konkurencyjną, muszą one wykazywać większą gotowość i ściśle współpracować z organami wspierającymi rząd i instytucjami wiedzy. Szanse dla MŚP na przyjęcie Przemysłu 4.0 obejmują obniżone koszty technologii związanych z IT, łatwość dostępu do danych i podejmowanie opłacalnych decyzji, zaspokojenie rosnącego zapotrzebowania klientów na spersonalizowane produkty, dobre środowisko do optymalizacji wydajności oraz pojawiające się wsparcie ze strony rządu Wielkiej Brytanii -powiązane organizacje, takie jak Innovate UK i jej partnerzy. MŚP również stoją przed pewnymi wyzwaniami, takimi jak brak odpowiedniej strategii i biznesplanu, brak wsparcia, luka w umiejętnościach, obawy związane z bezpieczeństwem cybernetycznym i brak środków finansowych. Badania wykazały również, że istnieje potrzeba opracowania ram protokołów i infrastruktury sieciowej, aby pomóc w stworzeniu wspólnego, ale bezpiecznego środowiska dla kompatybilnej pionowej i poziomej integracji cyfrowej. Aby MŚP mogły wykorzystać możliwości i stawić czoła wyzwaniom, organizacje rządowe, twórcy technologii, organizacje zawodowe i instytucje wiedzy powinny współpracować i stworzyć środowisko dla bezpiecznych, ustandaryzowanych systemów technologicznych i zmniejszyć lukę w umiejętnościach zgodnie z wymaganiami transformacji Przemysłu 4.0. Przydatne byłoby, aby MŚP miały dobre wytyczne i środowisko demonstracyjne na poziomie krajowym oraz łatwiejszy dostęp do informacji w celu stymulowania transferu technologii. Istnieje wiele narzędzi do samooceny, które firmy mogą wykorzystać do oceny swojej gotowości na Przemysł 4.0. Trzy z istniejących narzędzi online to narzędzie oceny PwC Industry 4.0, RoSF Smart factory i narzędzie oceny WMG Industry 4.0. Narzędzia te zostały opracowane na podstawie ankiet przeprowadzonych w wielu firmach i krajach i są odpowiednie dla wszystkich rodzajów przemysłu wytwórczego. Chociaż ich koncentracja mogła nie koncentrować się głównie na MŚP, nadal są one przydatnymi narzędziami do szybkiego testu gotowości. GrowIn 4.0 to jeden z europejskich projektów mających na celu budowanie silnych kompetencji i narzędzi w regionach skandynawskich na rzecz MŚP zmierzających w kierunku Przemysłu 4.0. W tym kontekście koncentruje się na nowych modelach biznesowych i rozwoju strategii, wykorzystaniu standardowej technologii Przemysłu 4.0 i rozwoju produktów oraz przezwyciężaniu luki w umiejętnościach poprzez szkolenia i edukację. Starając się to osiągnąć, pracuje nad rozwojem kilku narzędzi specjalnie przeznaczonych aby pomóc MŚP w ich transformacji w kierunku Przemysłu 4.0. Większość narzędzi jest nadal w fazie rozwoju, ale jako przykłady w tym rozdziale omówiono dwa narzędzia - narzędzie gotowości/świadomości Przemysłu 4.0 oraz narzędzie do identyfikacji korzyści. Narzędzie gotowości/świadomości oceniałoby gotowość MŚP i wskazywałoby obszary, nad którymi MŚP musi pracować, aby osiągnąć Przemysł 4.0. Narzędzia takie jak narzędzie do identyfikacji korzyści przejęłyby wtedy kontrolę i pomogłyby MŚP w realizacji wdrożenia nowych technologii dla Przemysłu 4.0.